International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
Abstract: Increasing social media used by different peoples express their opinions and feelings in the form sentences and text messages. So that extracting the information from message i.e which consists different issues in text and identifying anxiety depression of individuals and measuring well-being or mood of a community. This is because of its significance in a wide scope of fields, for example, business and governmental issues. Individuals express assessments about explicit themes or elements with various qualities and powers, where these estimations are firmly identified with their own sentiments and feelings. Various techniques and lexical assets have been proposed to break down feeling from normal language writings, tending to various assessment measurements. In this article, we propose a novel inference methodology for quantifying and inferring the Twitters users’ conclusion grouping utilizing distinctive notion measurements as meta-level highlights. We consolidate angles, for example, assessment quality, feeling and extremity markers, created by existing estimation investigation strategies and assets. Our exploration demonstrates that the mix of assumption measurements gives critical improvement in Twitter feeling characterization errands, for example, extremity and subjectivity.
Index Terms: Twitter, Information extraction, social media, machine learning, assessment, sentiment analysis.
I. INTRODUCTION
Highlight Internet-based life has taken over in this day and age, a large portion of the techniques we use to associate and impart are utilizing informal communities, and Twitter is one of the real places where we express our feelings about a particular theme or an idea. Twitter fills in as a mean for people to express their musings or emotions about various subjects. [1] These feelings are utilized in the different investigation for better comprehension of people.
Computational slant examination strategies endeavor to quantify diverse assessment measurements. Various techniques for extremity estimation have been proposed. By changing extremity estimation into a grouping issue with three extremity classes - positive, negative and impartial regulated and unsupervised methodologies have been investigated to satisfy this assignment. On account of the unsupervised methodologies, various vocabulary assets with positive and negative scores for words have been discharged. Another related undertaking is the location of subjectivity, which is the particular assignment of isolating accurate from obstinate
Revised Manuscript Received on August 05, 2019.
G.SRINIVASA RAJU, C.S.E, S.R.K.R. Engineering College, Bhimavaram, INDIA.
M.AJAY DILIP KUMAR, C.S.E, S.R.K.R. Engineering College, Bhimavaram, INDIA.
S.SURYANARAYANA RAJU, C.S.E, S.R.K.R. Engineering College, Bhimavaram, INDIA.
content. This issue has additionally been tended to by utilizing directed methodologies. Supposition powers (qualities) have additionally been estimated. From a quality scored technique, Senti-Strength can evaluate positive and negative quality scores at the sentence level. At long last, feeling estimation has likewise been tended to by creating vocabularies. The Plutchik's wheel of feelings was proposed. The wheel is made by four sets out of inverse feeling states delight trust, bitterness outrage, shock dread, and expectation nauseate. Mohammad et.al named various words as per Plutchik enthusiastic classes, building up the NRC word emotion affiliation dictionary. As per the past passages, we can see that notion examination devices center around various degrees inside assessments. In spite of the fact that these extensions are hard to arrange expressly, we propose the accompanying classifications:
1. Extremity: These strategies and assets point towards extricating extremity data from a section. Extremity arranged qualities are certain, negative and nonpartisan. Then again, extremity situated lexical assets are made by records out of positive and negative words.
2. Feeling: Methods and assets concentrated on removing feeling or disposition states from a contest entry. A feeling focused strategy ought to arrange the message to an enthusiastic class, for example, trouble, bliss, shock, among others. Feeling focused lexical assets ought to give a rundown of words or articulations set apart as per diverse feeling states. 3. Quality: These strategies and assets give force levels as per a specific assumption measurement, which can have an extremity or an enthusiastic extension. Quality arranged strategies return diverse numerical scores showing the power or the quality of a sentiment measurement communicated in a content section. For example, numerical scores showing the degree of inspiration, cynicism or another passionate measurement. Quality arranged lexical assets furnish arrangements of conclusion words together with power scores in regards to an assessment measurement.
Based on above classification, efficient approach is required to explore and classify the different issues. So that in this paper, we propose a novel inference model to classify and quantifying and learning tweets relates to different users and describe classification accuracy with different synthetic twitter data sets. Our approach also performs efficient calculation relates to different tweets presented and posted on twitter with tweets and re-tweet communications in social networks.
Quantifying Inference Learning Model to
Explore Twitter User Emotions
II. REVIEWOFLITERATURE
This section describes about authors opinion regarding data retrieval relates to different sentiment analysis from users posts on social media for social media related applications. Since the Advent of the Internet, people have utilized it as a specialized device as instant messages and these days video and sound streams and as we increment our reliance on innovation it turns out to be progressively imperative to more readily measure human estimations communicated with the assistance of innovation. Be that as it may, in this literary correspondence information, we lose the entrance to slants or the feelings passed on behind a sentence, as we frequently utilize our hands and outward appearances to express our aim behind the announcement. From this literary information, we can pick up bits of knowledge into the person. Experiences, which can be, utilized for various uses, for example, content suggestion dependent on current state of mind, showcase division examination and mental investigation in people. By this way different authors discuss about different procedures with different implementations applied in sentiment analysis in social networks.
III. TWITTERSENTIMENTANALYSIS Twitter clients will in general post suppositions about items or administrations. Tweets are the point messages with shirt and normal client post communications, by this way, tweets are triggering with examination supposition with different parameters. Normal errands of conclusion mining that can be connected to Twitter information are supposition order what's more, assessment ID. As Twitter messages are all things considered, 140-characters in length, a sentence-level characterization approach can be received, accepting that tweets express sentiments around one single substance. Moreover, recovering messages from Twitter is a clear task, using the Twitter API.
Feeling Lexical assets were utilized as highlights in an administered characterization plot in [10, 9] among different works. In [10] a managed methodology for Twitter slant grouping in light of etymological highlights was proposed. Also of utilizing n-grams and grammatical form labels as highlights, the creators utilized estimation lexical assets and perspectives specific from micro-blogging stages, for example, the nearness of emojis, condensing and intensifiers. A correlation of the various sorts of highlights was conveyed out, appearing despite the fact that highlights made from the
supposition vocabulary are significant,
micro-blogging-focused highlights are the most valuable. As of late, The Semantic Evaluation (SemEval) workshop has sorted out a Sentiment Analysis in the Twitter task (SemEval-2013)2. This undertaking gives preparing and testing datasets to twitter conclusion characterization at both articulation and message levels.
IV. INFERENCEMETHODOLOGYFOR
QUATIFYINGPOLITICALTWEETS
[image:2.595.320.536.61.139.2]This section describes the procedure relates to quantifying and inferring the user’s tweets in social media. To implement our approach as using re-tweets for learning political assessment. In our approach, we present highlighted existence features. For different data sets, 2014 presidential elections, major residential sources
Fig. 1: Negative co-related twitter tweets in patterns on twitter media political learning.
In figure 1, we plot their re-tweet reputation (their columns in matrix a) throughout the 12 activities in the dataset. We observe poor correlation (= −0. 246) between the 2 sources’ patterns of being re-tweeted, mainly throughout events 6 and seven. Three this can be defined by democrat/republican supporters enthusiastically re-tweeting Rahul/ Narendra Modi- tweets published by different users during the relation with corresponding features. We describe the quantity of re-tweets throughout the social communication with political learning. In consecutively, political tweets sent by different user’s relates to positive and negative present in election event. Incorporates with user’s re-tweets implicit sentiment analysis with different social networks.
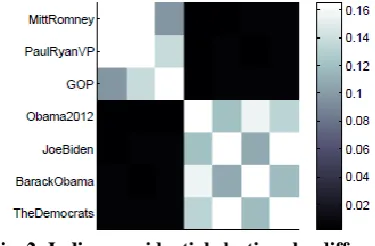
Fig. 2: Indian presidential elections by different candidates based on twitter information.
In figure 2, it exploits the representation of matrix with delight different attributes relates to human consistency. Dark representation gives better analysis of twitter data with respect to different low to high score based on user tweets with respect to other user’s re-tweets.
A. Description
For example, consider the real time data sets relation political parties of Indian election. Throughout the election campaign, there were different peoples performs different attractive communication between different users on interest to Twitter. We are interest to classify tweets in quantifying consecutive learning of prominent re-tweet resources.
Let us consider, Ui be the set of combined users who
discussed about political event and Tui be the combination of
tweets sent by the user u belongs to Ui discussed about the
tweet. Also describe each user tweet carriers a
score
s
t
[ 1,1]
, if score is 1 then user tweet is support for one candidate in election, if -1 then full support to another candidate then user approval score is|
|
iu t
t T iu
s
T
Tweet leaning by average yi
[image:2.595.340.528.322.445.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
1
|
|
i iu|
|
t i
u U t T
i iu
s
y
U
T
For source j, quantifying the learning of political awareness as
j
x
¡
, interpreted average approval shown when some user re-tweet against from other user tweet j.Let Vi be the combination of users re-tweeted by any one of
other N users during election event i,
R
uj( )i be the number of re-tweets by other users from source event j. Then re-tweetapproval score for each user
u
V
i from all sources re-tweeted as ( ) ( ) 1 1 i N uj j N i j uk kR
x
R
Average re-tweet leaning process for overall users u
1 N ij j j
A x
Aij is inner summation representation for augmented matrix A
with different elements to be interrupted as re-tweet matrix for respective feature related users in Twitter.
B. Regularization
In statistical inference model, different issues with undesirable rule solutions are introduced to correct the understandable problems. In these situations, regularization based inference method can change the characteristics relates
to objective functions
(
ax
y to ax
)
2(
y
)
2
f x
( )
with <0 regularization factors and quantifies the fiteness function with higher desirable variables for least square functions from f(x)=k(x)2. Based on these parameters, it describes political learning with different assignments xi with respect to similar re-tweets of other users.wij be the weight relates to regularization with attribute
sources i and j such that
w
ij
0 &
w
ij
w
ji, further implementation w be the load matrix which elements like ij. We set the following relations2
1 1
( )
(
)
N N
ij i j
i j
f x
W x
x
in order that if wij is massive (assets i and j are comparable), then xi ought to be near xj to decrease wij(xi − xj)2. Word that f(x) can be rewritten in terms of a graph laplacian. Let d = [dij] be defined as
1
0
N ik k ijW
i
j
D
otherwise
and l be the graph Laplacian defined as l = d−w. Then it can be proven that
2
1 1
(
)
2
N N
T
ij i j
i j
W x
x
Lx
basic implementation of account implementation gives better evaluation based on present similar re-tweets of different users, it consists different steps, in first step w construct similar matrix
s
[
s
ij]
which captures the assets relates to similar parameters whose relates to users re-tweets. ui and ujunits for re-tweets tweeted by different users with sources i and j respectively. Then similar measures are:
|
|
Cos
::
|
| . |
|
|
|
:
|
|
i j ij i j i j ij i jU
U
ine
Similarity
S
U
U
U
U
Jaccard
Co
efficient S
U
U
Based on regularization individuality, regularization is greater and critical issue with insufficient facts to be implemented from frequently generated re-tweets with corresponding similar small and large parameters sum, p,j aji,
refers inferring score based on mistake (ax-y)2. These representations are suffers from static issues. Based on closest matrix generated with updated results equal constraints with different relational attributes as follows:
0 , 1
min
log
N ij ij wi j ij
W
W
S
It is the optimized matrix representation with respect to different parameters.
If you wish, you may write in the first person singular or plural and use the active voice (“I observed that ...” or “We observed that ...” instead of “It was observed that ...”). Remember to check spelling. If your native language is not English, please get a native English-speaking colleague to proofread your paper.
V. EXPERIMENTALEVALUATION
This section describes experimental evaluation of proposed approach with different political related data sets.
A. Data set Description: To develop our application, use different data sets relates to political learning with different attributes. Data sets from 2014 year with different keywords like Narendra, Rahul, Sonia, Jagan and other parameters Election event analyzing different data sets with time results tables shown in data sets. We defined the dates of an occasion as follows:
B. Results: Describes experimental results with above data sets.
• Eigenvector: We have taken latency of the data sets relates to Eigenvector E with calculation of cosine similarity and Jacquard co-efficient with storage of details in Jacquard matrix & spectral attribute representation with standard data relates to user’s tweets and re-tweets taken from political learning 2014 election events. x is computed with corresponding optimization attributes. Minimized xLx subject with different kxk-2 i.e 1
• Sentiment analysis: we have a tendency to take xi because the average sentiment of the tweets printed by supply i, victimization identical methodology in computes y. This can be used as baseline tweets relates to different user’s. • Hash based SVM: For every implementation of different data sets with latency to compute all the features and arrange them in a specific vector with different sources contain 24568 hash tags employed with
Use SVM classification with standard features with highest labeled sources which are present in users tweet text with better opinion mining relates to different user’s political awareness in twitter data streams.
• Network analysis with user’s re-tweets: Construct rudeness graph partition with 5000 twitter user’s data and their activity between different users with number of times re-tweeted because of others. Based on majority voting of different users with different initial conditions from data Eigen vector for matrix maximization performed on different data streams.. Given matrix modularity approach used in analogous to higher Eigen vector base matrix representation. Based on political learning performance with respect to soft label propagation in [4] and then explored with matrix formation with higher results.
I. Performance of proposed inference model highlighted in bold
[image:4.595.56.284.257.320.2]The above table shows the performance evaluation of proposed approach with different cosine similarity related approaches in terms of accuracy precision, recall and other communication parameters.
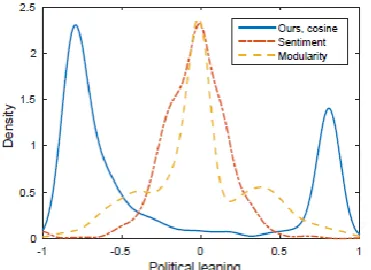
Fig.3: Density kernel parameters with political learning for different parameters.
Figure 3 shows performance evaluation of political learning with different parameters for social media. Finally our approach gives better performance with respect to different parameters in social related applications.
An excellent style manual and source of information for science writers is [9].
VI. CONCLUSION
In this paper, we present a novel inference model to quantifying and inferring the user’s tweets in social networks. We describe the emotions of different user’s and their opinions to explore election events. Also describe tweet and e-tweet user’s communication, twitter users send set of other user’s opinion to optimize the users political learning methodology. This technique is very sufficient to intuitive to take different user’s relations in political data sets. Our method worked on large data sets relates to Indian election committee over one year. Outcomes relates to proposed approach gives better and efficient results with respect to
process and explore the classification accuracy in quantifying tweets relates to social networks.
REFERENCES
1. Shaunak Joshi, Deepali Deshpande, "Twitter Sentiment Analysis System", International Journal of Computer Applications (0975 – 8887) Volume 180 – No.47, June 2018.
2. Felipe Bravo-Marquez, Marcelo Mendoza, "Combining Strengths, Emotions and Polarities for Boosting Twitter Sentiment Analysis", WISDOM’13, August 11 2013, Chicago, IL, USA Copyright 2013 ACM 978-1-4503-2332-1/13/08 ...$15.00.
3. Bradley, M. M., and Lang, P. J. Affective Norms for English Words (ANEW) Instruction Manual and Affective Ratings. Technical Report C-1, The Center for Research in Psychophysiology University of Florida, 2009.
4. Cambria, E., Speer R., Havasi C., and Hussain A. SenticNet 2: A Semantic and Affective Resource for Opinion Mining and Sentiment Analysis. In FLAIRS Conference, pages 202–207, 2012.
5. Carvalho, P., Sarmento, L., Silva, M. J., and de Oliveira, E. Clues for detecting irony in user-generated contents: oh...!! it’s "so easy" ;-). In Proceeding of the 1st international CIKM workshop on Topic-sentiment analysis for mass opinion Hong Kong, China, 2009. 6. Esuli, A., and Sebastiani, F. Sentiwordnet: A publicly available lexical
resource for opinion mining. In In Proceedings of the 5th Conference on Language Resources and Evaluation, 2006.
7. Go, A., Bhayani, R., and Huang, L. Twitter sentiment classification using distant supervision. Technical report Stanford University, 2010. 8. Felix Ming Fai Wong, Chee Wei Tan, "Quantifying Political Leaning from Tweets, Retweets, and Retweeters", IEEE Transactions on Knowledge and Data Engineering 1041-4347 (c) 2015.
9. P. Barber´a, “Birds of the same feather tweet together: Bayesian ideal point estimation using Twitter data,” Political Analysis, 2014. 10. R. Cohen and D. Ruths, “Classifying political orientation on Twitter:
It’s not easy!” in Proc. ICWSM, 2013.
11. J. Grimmer and B. M. Stewart, “Text as data: The promise and pitfalls of automatic content analysis methods for political texts,” Political Analysis, 2013.
12. M. D. Conover, B. Gonc¸alves, J. Ratkiewicz, A. Flammini, and F. Menczer, “Predicting the political alignment of Twitter users,” in Proc. IEEE SocialCom, 2011.
13. M. D. Conover, J. Ratkiewicz, M. Francisco, B. Gonc¸alves, A. Flammini, and F. Menczer, “Political polarization on Twitter,” in Proc. ICWSM, 2011.
14. CVX Research, Inc., “CVX: Matlab software for disciplined convex programming, version 2.0 beta,” http://cvxr.com/cvx, Sep. 2012. 15. unpublished M. Fiedler, “A property of eigenvectors of nonnegative
symmetric matrices and its application to graph theory,” Czechoslovak Mathematical Journal, vol. 25, no. 4, pp. 619– 633, 1975.
16. S. Finn, E. Mustafaraj, and P. T. Metaxas, “The coretweeted network and its applications for measuring the perceived political polarization,” in Proc. WEBIST, 2014.
17. J. L. Fleiss, “Measuring nominal scale agreement among many raters,” Psychological Bulletin, vol. 76, no. 5, pp. 378– 382, 1971.
18. M. Gabielkov, A. Rao, and A. Legout, “Studying social networks at scale: Macroscopic anatomy of the Twitter social graph,” in Proc. SIGMETRICS, 2014.
19. D. Gayo-Avello, “All liaisons are dangerous when all your friends are known to us,” in Proc. HT, 2011.
20. M. Gentzkow and J. M. Shapiro, “What drives media slant? Evidence from U.S. daily newspapers,” Econometrica, vol. 78, no. 1, pp. 35–71, January 2010.
21. S. Gerrish and D. Blei, “How the vote: Issue-adjusted models of legislative behavior,” in Proc. NIPS, 2012.
[image:4.595.76.262.381.516.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
Photo
Author-2 Photo
AUTHORSPROFILE
G.SRINIVASA RAJU completed B.Tech in Computer Science and Engineering in SRKR Engineering college, India. He is currently pursuing M.Tech in Computer Science and Engineering from Jawaharlal Nehru Technological University Kakinada, India.
M. AJAYDILIP KUMAR is an assistant professor in the Department of computer science and engineering. He pursued M.Tech from Andhra University in 2014, B.Tech from Andhra University in 2009.
![AENG100Z Introduction to Analytical Writing [Open to Freshman and Sophomores Only]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)