0022-538X/84/120984-04$02.00/0
Copyright
©1984, American Society for
Microbiology
Reovirus Type 3
Genome Segment S4: Nucleotide Sequence of the
Gene
Encoding
a
Major Virion Surface Protein
MICHAEL GIANTINI,* LAURIE S. SELIGER, YASUHIRO FURUICHI, ANDAARON J. SHATKIN
Roche Institute
of
MolecularBiology,
RocheResearch Center, Nutley, New Jersey 07110
Received 18July 1984/Accepted 2 September 1984
A
full-length cDNA
copyof reovirus double-stranded RNA
genome segmentS4
which codesfor
amajor
virion structural
polypeptide, r3, has been completely
sequenced.The 1,196-nucleotide cDNA
containsasinglelongopenreading
frame
in
the plus strand extending1,095
nucleotidesfrom
the5'-proximal A-T-G
toasinglestop
codon. This
corresponds
totranslation of
92%of the
S4
gene.The inferred
a3
polypeptideis
hydrophilic
and consists of
365 amino
acids, totalling 41,164 daltons.
Human reovirus
type3
is the
prototypeof animal and
plant viruses that contain segmented, double-stranded RNA
genomes
(12). One of the
tenreovirus
genomesegments,S4,
codes for viral
polypeptide c3
(21, 22), which is the
mostabundant
protein in virions and
amajor constituent of the
outer
capsid shell (31). An important structural feature of
reovirions is the
presenceof
asecond, inner capsid. It
consists of several
polypeptides,
including RNA polymerase
and
capping
enzymes,that enclose the double-stranded
RNAs
toform
astable, protease-resistant
core(7, 30). In
contrast to
the inner
capsid, reovirus
outershell
polypep-tides, notably cr3,
arehighly susceptible
tochymotrypsin
digestion (11, 29). Although the polymerase and capping
enzymesarepresent
in
intact virions in
anactive
configura-mRNA
translation
atlate times after infection
(18). Another
3
amongthe reovirus
polypeptides is its double-stranded
RNA
binding activity, suggestive of
arole in virus
morpho-genesis (9). The S4
genealso influences initiation of reovirus
persistent infections in tissue culture cells (1). To gain
insight into the multifunctional role of cr3 in the reovirus
replicative cycle and
toinvestigate the basis for its
chymo-trypsin sensitivity,
wehave deduced the amino
acid
se-quence
of
polypeptide cr3 by determining the complete
nucleotide
sequenceof
genomesegmentS4.
A
cDNA
copyof the S4 double-stranded RNA
wascloned
by insertion into the PstI site of pBR322 and transfection of
Escherichia coli RR1
cells essentially
asdescribed
previ-ously (10). Plasmid DNA
wasamplified, purified, digested
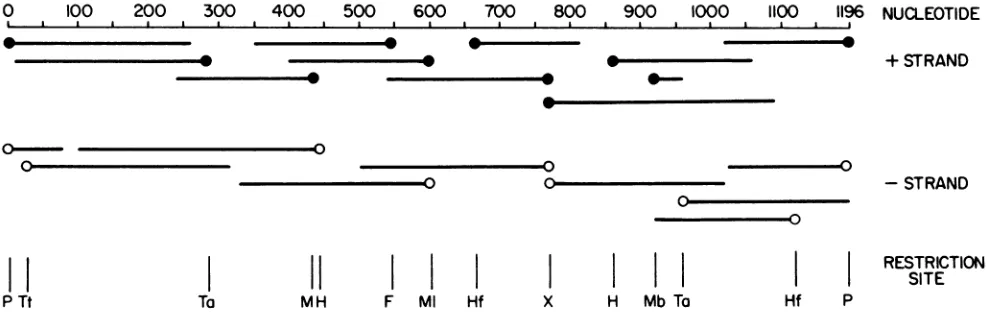
0 100 200 300
400
500 600 700 800 900 1000 1100 1196 NUCLEOTIDEa I I I a a a a a I I I a a a I I a a I a I I I i
0-
o---0
+ STRAND
-STRAND
II I I
~~~~~~~~~~~~~~~~~~~RESTRICTION
Illl l l l l
~~~~~~~~~~~~SITE
PTt Ta MH F MI Hf X H MbTa Hf P
FIG. 1. Strategy for sequencingreovirusgenomesegment S4 cDNA. Closed circlesonthe left andrightof restrictionfragments represent the 32P-labeled 5' and 3'ends,respectively,thatwereused forsequencingtheplusstrand(oppositeorientation for the open circles and minus strand). Restriction sites usedwere: P, PstI; Tt, TthIIItype I;Ta, TaqI; M, MspI; H, HincII; F, FokI; Ml,
M1lu;
Hf,Hinfl; X, XhoI;and Mb, MboI. In additiontoendlabelingwithpolynucleotide kinase andby repair synthesis (19),PstIendswerealso3' labeledbyincubation with [ot-32P]ddATP and terminal transferase (32).tion
(33),
only after proteolytic removal of c3 does the
core-associated RNA
polymerase synthesize full-length viral
mRNAs.
Apparently the
outershell
polypeptides impose
structural constraints that
preventelongation of
nascenttranscripts by the virion-associated
RNApolymerase (3).
In
addition
toits
role
as astructural
polypeptide, cr3
inhibits host protein synthesis in
infected
mouseLcells (27)
and
maybe
involved in
switching from cellular
toviral
*Corresponding author.
with PstI, and
analyzed by
agarosegel
electrophoresis
to obtain thefull-length
S4 insert for DNAsequencing.
Restric-tionfragments
were 32P-labeled at the 5' and3'
endsby
kinase and
repair reactions, respectively (19). Both strands
were
sequenced in their
entirety by using the
strategy detailed inFig.
1.The
plus (mRNA sense)
strand and the inferred amino acid sequence ofpolypeptide
cr3 are shown inFig.
2. TheDNA sequence agrees
completely
with the 5'-terminal 54 residues determinedpreviously
for reovirus s4 mRNA(28)
984
on November 10, 2019 by guest
http://jvi.asm.org/
Downloaded from
on November 10, 2019 by guest
http://jvi.asm.org/
Downloaded from
on November 10, 2019 by guest
http://jvi.asm.org/
[image:1.612.71.564.411.569.2]NOTES 985
10 20 30 47 62 77 92
GCTATTTTTG CCTCTTCCCA GACGTTGTCG CA ATG GAG GTG TGC TTG CCC AAC GGT CAT CAG GTC GTG GAC TTG ATT MC MC GCT TTT GMGGT CGT GTA TCA MET Glu ValCys Leu Pro Asn Gly His Gln ValVa1 Asp Lou Ile AsnAsn Ala PheGlu Gly Arg Vas Sor
107 122 137 152 167 182 197
ATC TAC AGC GCG CM GAG GGA TGG GAC AM ACA ATC TCA GCA CAG CCA GAT ATG ATG GTA TGT GGT GGC GCC GTC GTT TGC ATG CAT TGT CTA GGT GTT IleTyr Ser AlaGln Glu Gly Trp Asp Lys Thr IleSer Ala Gln Pro Asp MET MET ValCys Gly Gly Ala Va1Vas Cys MET His Cys Leu Gly Va1
212 227 242 257 272 287 302
GTT GGA TCT CTA CMCGC MGCTG MGCAT TTG CCTCAC CAT AGA TGT MT CMCAG ATC CGT CAT CAG GAT TAC GTC GATGTA CAG TTC GCAGAC CGT Vsi Gly Ser Leu Gln Arg Lys Lou Lys His Lou Pro His His Arg Cys Asn Gln Gln IleArg His Gln Asp Tyr Vsi AspVal Gln PheAisAsp Arg
317 332 347 362 377 392
GTT ACT GCT CAC TGG MGCGGGGT ATG CTG TCC TTC GTT GCG CAG ATG CAC GAG ATGATG MT GAC GTG TCG CCA GAT GAC CTG GAT CGT GTG CGT ACT
Vsl Thr Ala His Trp Lys Arg Gly MET Lou Ser Phe ValAlaGln MET His Glu METMET Asn Asp Vsi Ser Pro Asp Asp Lou Asp Arg Vsi Arg Thr
407 422 437 452 467 482 497
GAG GGA GGT TCA CTA GTG GAG CTG MC CGGCTT CAG GTT GAC CCA MT TCA ATG TTT AGA TCA ATA CAC TCA AGT TGG ACA GAT CCT TTG CAGGTGGTG
Glu Gly Gly Ser Lou Vas Glu Lou Asn Arg Lou Gln Vsa Asp Pro Asn Sor MET PheArg Ser IleHis Ser Ser Trp Thr Asp Pro Leu Gln Vsl Vsi
512 527 542 557 572 587
GAC GAC CTT GAC ACT MG CTG GAT CAG TAC TGGACA GCC TTA AAC CTG ATGATC GAC TCA TCC GAC TTG ATA CCC MC TTT ATG ATG AGA GAC CCATCA
Asp Asp Leu Asp Thr Lys Leu Asp Gln Tyr Trp Thr slaLeu Asn Leu MET IleAsp Ser Ser Asp Lou IlePro Asn Ph. NET MET Arg Asp Pro Ser
602 617 632 647 662 677 692
CAC GCG TTC MAT GOT GTGAM CTG GAG GGA GAT GCT CGT CAAACC CMTTC TCC AGGACT TTT GAT TCGAGA TCG AGTTTGGMTGG GGT GTG ATG GTT
His Ala Phe Asn Gly Val Lys Leu Glu Gly AspAlaArg Gln Thr Gin Phe Ser Arg Thr PheAsp Ser Arg Ser Sor Leu Glu Trp Gly Vsl MET Val
707 722 737 752 767 782 797
TAT GAT TAC TCT GAG CTG GAG CAT GAT CCA TCG MG GGC CGT GCT TAC AGA MG GOA TTG GTG ACG CCA GCT CGA GAT TTC GGT CAC TTT GGATTA TCC
Tyr Asp Tyr Ser Glu Leu Glu His Asp Pro Ser Lys Gly Arg Ala Tyr Arg Lys Glu Leu Vas Thr Pro Ais Arg Asp Phe Gly His Phe Gly Leu Ser
812 827 842 857 872 887
CAT TAT TCT AGGGCG ACT ACC CCA ATC CTT GGA MGATG CCG GCC GTA TTC TCA GGA ATGTTG ACT GGG MCTGT AM ATGTATCCA TTC ATT MA GGA His Tyr Ser Arg Ais Thr Thr Pro IleLou Gly Lys MET Pro AlaVsl Phe Ser Gly MET Lou Thr Gly Asn Cys Lys NET Tyr Pro PheIle Lys Gly
902 917 932 947 962 977 992
ACG GCT MG CTG MG ACA GTG CGC MG CTA GTG GAG GCA GTC MT CAT GCT TGG GGT GTC GAG MG ATT AGA TAT GCT CTT GGG CCA GGT GGC ATG ACG
Thr Msa Lys Leu Lys Thr Vas Arg Lys Leu Vsl Glu Ais ValAsn His AlaTrp Gly Vas Glu Lys IleArg Tyr AlsLou Gly Pro Gly Gly NET Thr
1007 1022 1037 1052 1067 1082
GGA TGG TAC MT AGG ACT ATG CM CAG GCC CCC ATT GTG CTA ACT CCT GCT GCT CTC ACAATGTTC CCA GAT ACC ATC MGTTT GGGGAT TTG MT TAT Gly Trp Tyr Asn Arg Thr NET Gin Gln Ala Pro Ile Val Lou Thr Pro Ais Ais Lou Thr NET Phe Pro Asp Thr Ile Lys Phe Gly Asp Lou Asn Tyr
1097 1112 1127 1140 1150 1160 1170 1180 1190 1196
CCA GTG ATG ATT GGC GAT CCG ATG ATT CTT GGC TMACACCCCCAT CTTCACAGCG CCGGGCTTGA CCMCCTGGT GTGACGTGGG ACAGGCTTCATTCATC Pro Val NET 11eGly Asp Pro MET Ile Leu Gly
FIG. 2. Nucleotide sequence of genome segment S4
coding
strandandinferred amino acid sequence ofpolypeptide
u3.and also
contains
the
3'-terminal
pentanucleotide
common toreovirus
plus strands
(6)-properties
expected of
the
full-length
clone. The S4 gene
contains
noobvious
TATA
initiation
box
orA-A-U-A-A-A
cleavage signal,
afinding
that
is
consistent with
end-to-end
transcription
without
polyadenylation by
areovirus-specific
RNA
polymerase.
Two
points concerning
the
nucleotide sequence data
arenoteworthy.
First,
the
TaqI
recognition
sequence
TCGA
atpositions
553
to556
apparently
is
modified
since
mapping
and
radiolabeling experiments
showed
noTaqI cleavage
atthis
site.
Areasonable
explanation
for this enzyme
resist-ance
is
N6-methylation
of
anadenine in the
TaqI
site.
Probably this
occurs atnucleotide 553 in the
complementary
strand because the
TaqI
recognition
sequence
overlaps
aGATC sequence
atpositions
551
to554
which is
recognized
for adenine N6
methylation by
E.coli dam
methylase (8).
Second,
the
sequencing
data
document the presence of four
EcoRII restriction sites
(CCAGG)
located
atnucleotides
383,
652,
981
and 1165.
Except for
position 981,
the
internal
+
STRAND
G G/A C T/C
- STRAND
3 3 G G/A CT/C
,G
G
-'0
-T
A----.C~~~~~~~~~~~
.5.
5'5
FIG. 3.
Radioautograph indicating
cytosine methylation
at anEcoRlI recognition
sequence in reovirus S4 cDNA. ATaqI
site(position 280)
in theplus
strand andHincll site(position
440)
in the minus strand were5'-end
labeled.Fragments
were cleaved(19),
electrophoresed
in 7%polyacrylamide sequencing gels,
andauto-radiographed
withoutintensifying
screen.Both sequencesread5'to 3' fromthebottom ofthe film.VOL. 52,1984
on November 10, 2019 by guest
http://jvi.asm.org/
[image:2.612.48.550.64.535.2] [image:2.612.303.549.560.666.2]cytosines in each of
these EcoRII
sites
are not
observed
in
radioautographs
of the
relevant
sequencing
gels
but
are
replaced by
a
blank space, e.g., at position 384
in
the
plus
strand and
386 in the minus strand
(Fig. 3). In
contrast,
the
complementary G residues
present
in the
opposite strand
are
readily evident. Presumably methylation of
the
C residues
at
positions 384,
653,
and
1,166
(386, 655 and
1,168 in the
minus
strand)
prevents
chemical cleavage and results in
one-nucl-eotide
gaps
in the
sequencing gels (23).
Although
there
is
total agreement between the DNA and
mRNA
5'-terminal
sequences,
comparison of the
DNA
sequence
with S4 double-stranded
RNA sequences (2)
re-vealed
differences in both the
3'-
and
5'-terminal regions.
The
nucleotide differences in
the RNA
do
not
affect
the
longest translational reading frame,
but the
absence of
a
codon, AAC
at
positions
78 to
80,
results
in loss
of
one
of
a
pair
of asparagine residues
at
positions
78 to
83
(Fig.
2).
The
differences between the S4 cDNA
and
genomic
RNA
se-quences may
be
due to
variability
among
virus isolates.
However,
differences which
we
have
found with both
the
sequences
of Antczak
et
al.
(2) and
McCrae
(20) are
in
the
last
few
RNA
residues
sequenced and may
reflect
difficulties
in
interpreting bands in
the
upper
part
of autoradiographs.
Ribosome protection studies of reovirus
s4
viral
mRNA
have already indicated
that the
initiator
codon
for
a3 is the
5'-proximal A-U-G
(14).
This
triplet lies in
a
consensus
sequence,
i.e., Pur-X-X-A-U-G-G, considered favorable for
initiation of protein synthesis
(13). The DNA sequence
reported here reveals that
this initiator codon is followed
by
an
open
reading frame extending 1,095 nucleotides
to a
stop
codon
at
position 1,128 (Fig. 2). Examination of
all
other
phases in both the minus
and
plus strands revealed
no
additional
open
reading frames capable of
yielding
a
polypep-tide
greater
than
40
amino acids.
The
single
open
reading
frame found in the S4
genes contrasts
with the reovirus
Si
gene
which codes for the
crl
protein
but
also contains
a
second
out-of-phase, overlapping reading frame
(R.
Bassel-Duby,
A.
Jayasuriya,
and B.
Fields, unpublished data).
Recent
studies demonstrate
that
both
frames in the
sl
mRNA are
translated
(5;
H. Ernst
and
A.
J.
Shatkin,
unpub-lished
data).
The
S4
gene
is similar
to
the reovirus
S3 RNA segment
(25) in that
92%
of each is
apparently translated. However,
the
longest open reading frame reported for
segment
S2
corresponds
to
only
75% of the total
gene (4). Assuming
that
translation of s4 mRNA starts
from
nucleotide
33,
polypep-tide a3
consists of 365 amino acids including
40
acidic
and 37
basic
residues,
14
histidines,
and 21
methionines-an
unu-sually high number. The total molecular
weight of
a3 is
41,164, close
to the
value
of
41,500 estimated from
elec-trophoretic migration
in
sodium
dodecyl
sulfate-polyacrylam-ide
gels
(26).
The sequence
-(Val,Val,Leu)-COOH reported
for
a3
purified from
virions
(24)
is not present in
the
inferred
amino acid
sequence
(Fig.
2).
Chymotrypsin
treatment of reovirions results in the
rapid
hydrolysis of
u3, and two
small
polypeptides of
14,000
and
11,500 daltons
are
released after
only
brief
exposure to
the
protease (11).
Fragments of this size
conform
to
the location
of some of
the
chymotryptic
sites in
u3, but
the inferred
polypeptide
sequence
includes
a
total of
14
phenylalanine,
11
tyrosine,
and 7
tryptophan residues in
addition
to
many
other
potential cleavage
sites.
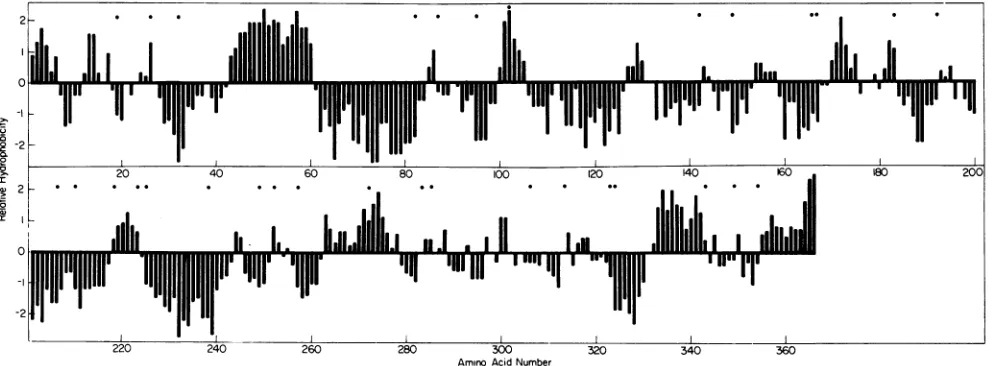
Surprisingly, these potential
chymotryptic sites
are
distributed
throughout
a3,
and many
of
the aromatic residues
are
located in
hydrophilic regions
estimated by
the
procedure
of Kyte
and Doolittle
(16)
(Fig.
4).
Consequently,
the
sequence does not allow
prediction of
primary chymotryptic cleavage site(s)
in the
virion
outer
shell a3
polypeptides.
Other features of a3 include six
cysteine residues:
five
near
the
N
terminus
and one near the
carboxyl end.
There
is
a
single potential
glycosylation site, Asn-Arg-Thr
at
residues
325
to
327,
which
on
the
basis of incorporation of
radiola-beled amino
sugars
is used
ineffectively (17)
or not at
all (15).
A
hydrophilic
region between amino acids
63
and
72
con-tains
seven
positively charged residues
counting histidine
and
may be
related
to
the RNA
binding capacity of a3.
Finally,
comparison of
the
hydropathicity profiles of a3
and
aNS, another RNA-binding
protein (9), shows
two
regions of
strong
similarity in
terms
of
hydrophobic-hydro-philic domains:
a
region from amino acid residues
48 to 88
and
another
from
residue 318
to
the
carboxyl terminus.
In
addition, both of these reovirus polypeptides contain
a
high
proportion
(6%)
of
methionines.
It may
be
possible
to test
whether
these
structural similarities
are
related to RNA
binding
capacity by analyzing site-specific
mutants
gener-ated
by
in
vitro
manipulation of
cDNA
clones.
FIG. 4. Hydropathicity profile of polypeptidecr3 generated bycomputerbytheprocedure of KyteandDoolittle (16). Thelocations of aromatic amino acids correspondingtopotentialchymotrypsin cleavage sitesareindicated
(0).
on November 10, 2019 by guest
http://jvi.asm.org/
[image:3.612.69.567.523.706.2]NOTES 987 Wethank A. R. Bellamy and M.Richardson for technical advice
and for the criticalreading of the manuscript. LITERATURE CITED
1. Ahmed, R., and B. N. Fields. 1982. Role of the S4 gene in the establishment ofpersistent reovirus infection in L cells. Cell 28:605-612.
2. Antczak, J. B.,R. Chmelo, D. J. Pickup, and W. K. Joklik. 1982. Sequencesatbothtermini of thetengenesofreovirus serotype 3(strain Dearing). Virology 121:307-319.
3. Astell, C., S. C. Silverstein, D. H. Levin, and G. Acs. 1972. Regulation of the reovirus RNA transcriptase by a viral capsomereprotein. Virology48:648-654.
4. Cashdollar, L. W., J. Esparza, G. R. Hudson, R. Chmelo, P. W. K. Lee, and W. K. Joklik. 1982. Cloning the double-stranded RNA genes of reovirus: sequence of the cloned S2 gene. Proc. Natl. Acad. Sci. U.S.A. 79:7644-7648.
5. Cenatiempo, Y., T. Twardowski, R. Shoeman, H. Ernst, N. Brot, H. Weissbach, and A. J. Shatkin. 1984. Two initiation sites detectedinthe smallslspecies ofreovirus mRNAbydipeptide synthesisinvitro. Proc. Natl. Acad. Sci. U.S.A. 81:1084-1088. 6. Darzynkiewicz, E., and A. J. Shatkin. 1980. Assignment of reovirus mRNA ribosome binding sites to virion genome
seg-ments by nucleotide sequence analyses. Nucleic Acids Res. 8:337-350.
7. Furuichi, Y., M. Morgan, S.Muthukrishnan, and A. J.Shatkin. 1975.Reovirusmessenger RNAcontainsamethylated. blocked 5'-terminal structure: m7G(5')ppp(5')GmpCp-. Proc. Natl. Acad. Sci. U.S.A. 72:362-366.
8. Geier,G. E., and P. Modrich. 1979.Recognitionsequenceofthe dammethylase of Escherichia coliK12 and mode ofcleavage of Dpn Iendonuclease. J. Biol. Chem.254:1408-1413.
9. Huismans, H., and W. K. Joklik. 1976. Reovirus-coded poly-peptides in infected cells: isolation oftwo native monomeric polypeptides with high affinity for single-stranded and double-strandedRNA,respectively. Virology 70:411-424.
10. Imai, M., M.A. Richardson, N.Ikegami, A. J. Shatkin, and Y. Furuichi. 1983. Molecular cloning of double-stranded RNA virus genomes. Proc. Natl. Acad. Sci. U.S.A. 80:373-377. 11. Joklik, W. K. 1972. Studies on theeffect ofchymotrypsin on
reovirions. Virology49:700-715.
12. Joklik, W. K. 1983. The members ofthe family reoviridae. p. 1-7. In W. K.Joklik (ed.), The reoviridae. Plenum Publishing
Corp.,
New York.13. Kozak, M. 1984. Compilation and analysis of sequences
up-streamfrom the translational start site in eukaryotic mRNAs. Nucleic AcidsRes. 12:857-872.
14. Kozak, M., andA. J. Shatkin. 1977.Sequences and properties of two ribosome binding sites from the small size class of reovirusmessengerRNA. J. Biol. Chem. 252:6895-6908. 15. Krystal, G., J. Perrault, and A. F. Graham. 1976. Evidencefor
aglycoproteininreovirus. Virology 72:308-321.
16. Kyte, J., and R. F. Doolittle. 1982. A simple method for
displaying the hydropathic character of a protein. J. Mol. Biol. 157:105-132.
17. Lee, P. W. K. 1983. Glycosylation of reovirus proteins and the effect of2-doexy-D-glucoseonviralreplication and assembly. p. 193-206. In R. H.Compansand D. H. L. Bishop (ed.). Double-stranded RNA viruses. Elsevier Science Publishing Co.. Inc.. New York.
18. Lemieux, R., H. Zarbl, and S. Millward. 1984. mRNA
discrim-ination in extracts from uninfected and reovirus-infected L-cells. J. Virol. 51:215-222.
19. Maxam,A. M., and W. Gilbert. 1980. Sequencing end-labeled DNA withbase-specific chemical cleavages. Methods Enzymol. 65:499-560.
20. McCrae, M. A. 1981. Terminal structure of reovirus RNAs. J. Gen. Virol.55:393-403.
21. McCrae, M. A., and W. K. Joklik. 1978. The nature of the polypeptide encoded by each of the ten double-stranded RNA segmentsof reovirus type 3. Virology 89:578-593.
22. Mustoe, T. A., R. F. Ramig, A. H. Sharpe, and B. N. Fields. 1978. Genetics of reovirus: identification of the ds RNA seg-ments encoding the polypeptides of the A. and a size classes.
Virology 89:594-604.
23. Ohmori, H., J. Tomizawa, andA.M. Maxam. 1978.Detection of 5-methylcytosine in DNA sequences. Nucleic Acids Res. 5:1479-1485.
24. Pett, D. M., T. C.Vanaman, and W. K. Joklik. 1973. Studies on the amino and carboxyl terminal amino acid sequences of reovirus capsidpolypeptides. Virology 52:174-186.
25. Richardson, M. A., and Y. Furuichi. 1983. Nucleotide sequence of reovirusgenomesegment S3.encodingnon-structural protein sigmaNS. NucleicAcidsRes. 11:6399-6408.
26. Samuel,C. E.1983. Biosynthesisofreovirus-specified polypep-tides. p. 219-230. In R. H. Compans and D. H. L. Bishop(ed.) Double-stranded RNA viruses. Elsevier Science Publishing Co.. Inc.. New York.
27. Sharpe, A. H., and B. N. Fields. 1982. Reovirus inhibition of cellular RNA and protein synthesis: role of the S4 gene. Virology 122:381-391.
28. Shatkin, A. J., and M. Kozak. 1983. Biochemical aspects of reovirus transcription and translation. p. 79-106. In W. K. Joklik (ed.). The reoviridae. Plenum Publishing Corp.. New York.
29. Shatkin, A. J., and A. J. LaFiandra. 1972. Transcription by infectious subviral particles of reovirus. J. Virol. 10:698-706. 30. Shatkin, A. J., and J. D. Sipe. 1968. RNApolymerase activity in
purified reoviruses. Proc. Natl. Acad. Sci.U.S.A.61:1462-1469. 31. Smith, R. E.,H.J.Zweerink,and W. K.Joklik. 1969. Polypep-tide components ofvirions. top component and cores of reo-virus type 3. Virology 39:791-810.
32. Tu, C.-P. D., andS. N. Cohen. 1980. 3'-End labelingof DNA with
[_-32P]cordycepin-5'-triphosphate.
Gene 10:177-183. 33. Yamakawa, M., Y. Furuichi, andA.J. Shatkin. 1982. Reovirustranscriptaseand capping enzymes are active in intact virions. Virology 118:157-168.
VOL.52, 1984
on November 10, 2019 by guest
http://jvi.asm.org/
ERRATUM
Reovirus Type 3 Genome Segment S4: Nucleotide Sequence of the Gene
Encoding
a
Major
Virion
Surface Protein
MICHAEL
GIANTINI, LAURIE S. SELIGER, YASUHIRO FURUICHI, AND AARON J. SHATKIN
Roche InstituteofMolecularBiology,RocheReseacrch Center,Nutley, New Jersey 07110