Thesis submitted in accordance with the requirements of the University of Liverpool for the degree of Doctor in Philosophy by
Anton Roscoe Minnion
Preface xi
Abstract xiii
Acknowledgements xv
1 Introduction 1
2 Literature Survey 5
2.1 Preface . . . 5
2.2 Knowledge Engineering . . . 5
2.2.1 Development of Knowledge Engineering . . . 5
2.2.2 Knowledge Engineering Methodologies . . . 7
2.3 Ontology, Ontology Engineering and Ontology Building . . . 9
2.4 Bottlenecks . . . 13
2.4.1 The Knowledge Re-Engineering Bottleneck . . . 13
2.4.2 The Knowledge Acquisition Bottleneck . . . 13
2.5 Addressing the Knowledge Acquisition Bottleneck: Ontology Learning . . 14
2.5.1 Ontology Learning using Text Resources . . . 14
2.5.2 Ontology Learning using Web Resources . . . 16
2.5.3 Shortcomings of Ontology Learning . . . 17
2.6 Addressing the Knowledge Acquisition Bottleneck through the use of Con-trolled Natural Language . . . 18
2.7 Addressing the Knowledge Acquisition Bottleneck through the use of Templates . . . 19
2.8 Addressing the Knowledge Acquisition Bottleneck: Collaborative Ontol-ogy Development . . . 19
2.9 Broadening the Semantic Web . . . 20
2.9.1 Linked Data . . . 20
2.10 Knowledge Acquisition through Crowdsourcing . . . 22
2.11 Crowdsourcing . . . 22
2.11.1 Motivating Crowds to Perform Tasks . . . 23
2.12 Using Crowdsourcing for Ontology Engineering . . . 23
2.12.1 Crowdsourcing for Ontology Alignment . . . 24
2.12.2 Crowdsourcing for Knowledge Acquisition . . . 25
3 A Crowdsourcing Approach to Knowledge Acquisition from Online
Communities 31
3.1 Obtaining Consensual Models from Community Crowds . . . 31
3.1.1 Novel Approach . . . 31
3.1.2 Objective . . . 32
3.1.3 General Design . . . 32
3.1.4 Concept Model Conflicts . . . 34
3.1.5 Mediation of Concepts . . . 35
Stage 1: Formatting . . . 35
Stage 2: Automated Mediation I (Adoption) . . . 36
Stage 3: Automated Mediation II (Pruning) . . . 37
3.1.6 Enhanced Protocols forWordNet Incorporation . . . 44
3.2 Method Evaluation . . . 45
3.2.1 CTF and CTF1 . . . 48
3.3 Qualitative Evaluation . . . 49
3.4 Object Properties . . . 50
3.4.1 Automated Mediation . . . 50
3.4.2 Automated Mediation . . . 51
3.4.3 Semi-Automated Mediation . . . 52
3.4.4 Evaluation using CDRF . . . 52
3.5 Summary . . . 53
4 Experiment 1: Building a Consensual Model from Task-Aware Crowds 55 4.1 Description . . . 55
4.2 Objective . . . 55
4.3 Method . . . 57
4.3.1 Obtaining Competency Questions and Initial Ontology structures . 59 4.3.2 Mediation Results . . . 62
Formatting . . . 62
4.3.3 Automated Mediation . . . 63
Thresholds . . . 63
Automated Mediation Overview . . . 63
Semi-Automated Mediation . . . 65
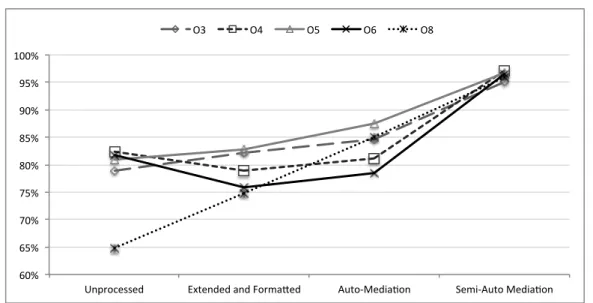
4.4 Results . . . 67
Unprocessed . . . 67
After Extension and Formatting . . . 67
Automated Mediation . . . 70
Semi-Automated Mediation . . . 71
4.4.1 Convergence toward Consensus . . . 72
4.4.2 Object Properties . . . 74
4.5 Summary . . . 75
5 Experiment 2: Eliciting Concept Hierarchies from a Task-Aware crowd withWordNet support 77 5.1 Description . . . 77
5.3.1 Challenges of Scale . . . 79
5.3.2 Using WordNet to Reduce Mediation Cases . . . 80
5.3.3 UsingWordNet to identify Synonyms . . . 81
5.3.4 Obtaining Competency Questions and Initial Ontology structures . . . 82
5.4 Results . . . 82
Formatting . . . 82
5.4.1 Automated Mediation . . . 83
Thresholds . . . 83
Filtering Pruning Cases Using WordNet . . . 83
Automated Mediation Overview . . . 88
Note on thresholds . . . 90
5.4.2 Semi-Automated Mediation . . . 91
WordNet Equivalency . . . 91
5.4.3 Convergence toward Consensus . . . 93
5.5 Summary . . . 95
6 Experiment 3: Building a Consensual Models from Task-Unaware Crowds 99 6.1 Description . . . 99
6.2 Objective . . . 100
6.3 Method . . . 100
6.4 Experimental Conditions . . . 103
6.4.1 User Interface . . . 104
6.4.2 User Experience . . . 104
6.5 Results: Part 1 . . . 108
6.5.1 Concept Elicitation from the Crowd . . . 108
6.5.2 Convergence towards consensus achieved through Automated Me-diation . . . 108
6.6 Choice of Ontology Set for Semi-Automated Mediation . . . 111
6.7 Results: Part II . . . 111
6.7.1 Results: Pre Mediation . . . 111
6.7.2 Results: Automated Mediation . . . 113
6.7.3 Results: Semi-Automated Mediation . . . 114
6.7.4 Automated Mediation of Shallow Ontology Set . . . 115
6.7.5 Convergence towards consensus achieved through Mediation . . . . 118
6.8 Summary . . . 119
7 Discussion 121 7.1 Quality of Knowledge Acquisition . . . 121
7.1.1 Quality of Acquired Knowledge from Experiment 1 . . . 121
7.1.2 Quality of Acquired Knowledge from Experiment 2 . . . 126
7.1.3 Quality of Acquired Knowledge from Experiment 3 . . . 128
7.2 Future Work . . . 130
7.2.1 Retaining additional knowledge from the crowd . . . 130
7.2.4 Too many reinstate / mediation questions? . . . 132
7.3 Summary . . . 132
8 Conclusion 135 A Acquired Ontologies 137 A.1 Unprocessed Ontologies acquired from Experiment 1 . . . 137
A.2 Mediated Ontologies from Experiment 1 . . . 152
A.3 Unprocessed Ontologies acquired from Experiment 2 . . . 162
A.4 Mediated Ontologies from Experiment 2 . . . 177
B Lab Instruction for Students (Experiment 1) 191 B.1 Experiment 1 . . . 191
B.2 Experiment 2 . . . 195
C CampusMap instructions 199
Bibliography 203
List of Figures
2.1 Basic RDF structure describing ’Eric Miller’ from the RDF Primer [70] . . . 21
3.1 General Overview of Crowsourcing Mechanism . . . 33
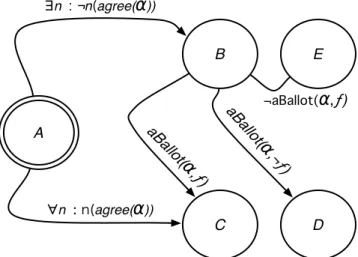
3.2 Example of concept model conflict . . . 34
3.3 Automatic Concept Mediation Protocol . . . 36
3.4 Mediation example: concept hierarchies pre-mediation . . . 38
3.5 Reinstate Protocol . . . 39
3.6 Minority Adoption Cases . . . 41
3.7 Mediation example: concept hierarchies pre-mediation . . . 42
3.8 Mediation example: post semi-automated mediation . . . 43
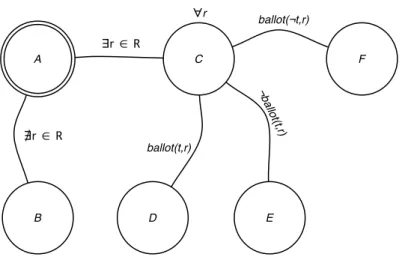
3.9 Example ontology structure (adapted from Dellschaft and Staab [22]) . . . . 46
3.10 Example of a object property conflict . . . 51
3.11 Removal of Redundant Properties . . . 52
4.1 Experiment 1: convergence towards consensus . . . 72
4.2 Convergence towards consensus by Ontology (CTF) . . . 73
5.1 Experiment 2: convergence towards consensus . . . 93
5.2 Comparison of CTF convergence . . . 96
5.3 Comparison of CTF1 convergence . . . 96
6.1 Parallel Motivations Chart . . . 102
6.2 Seed Ontology Structures . . . 104
6.3 Screenshot: Entity Creation . . . 105
6.4 Screenshot: Classifying . . . 106
6.5 Technology Outline . . . 107
6.6 Mediation of Shallow Set . . . 108
6.7 Mediation of Intermediate Set . . . 109
6.8 Mediation of Deep Set . . . 109
6.9 Mediation Effect on CTF . . . 110
6.10 Effect of Mediation on Lexical Precision and Recall . . . 115
6.11 Average convergence towards consensus (CTF)(II) . . . 118
6.12 Convergence towards consensus by Ontology (CTF)(II) . . . 118
7.1 Experiment 1: Consensual Model Concept Hierarchy . . . 122
7.2 Experiment 3: Consensual Model Concept Hierarchy . . . 129
7.3 Concept Granularity . . . 131
B.1 Lab Example 1 . . . 197
2.1 Results from the OntoGame prototype experiment . . . 26
2.2 Results table from Good and Wilkinson . . . 27
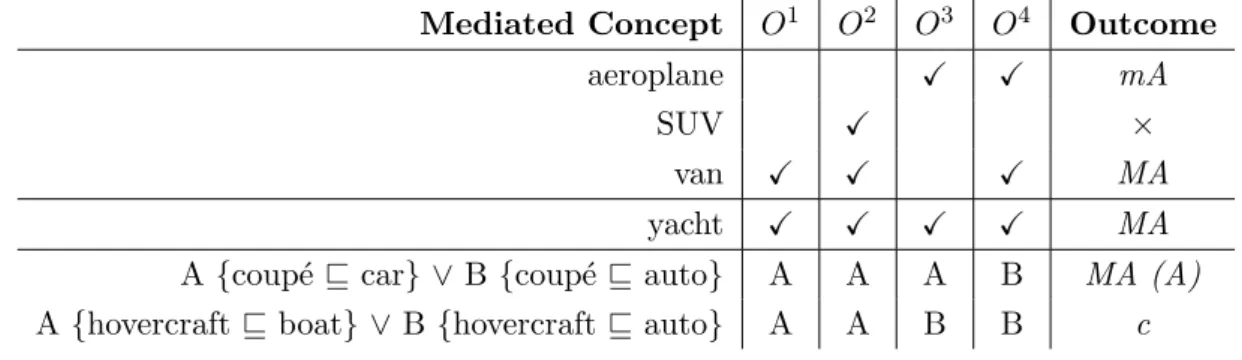
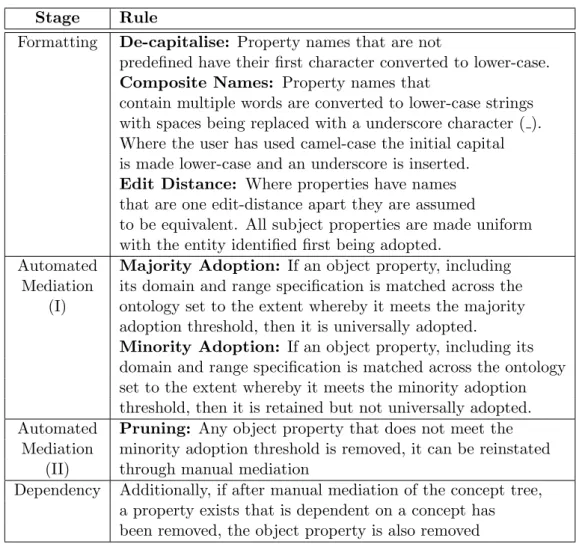
3.1 Rules for automated mediation of concepts . . . 35
3.2 Label Mismatch Error Examples . . . 36
3.3 Example manual mediation ballot . . . 42
3.4 Semantic cotopies derived from figure 3.9(from Dellschaft and Staab [22]) . . 46
3.5 Rules for automated mediation of Object Properties . . . 50
3.6 Domain and range as derived from figure 3.9 . . . 53
4.1 Unprocessed competency questions obtained from participants. . . 61
4.3 Summary of concepts and properties obtained from combined competency question list. . . 61
4.2 Competency questions filtered according to stated criteria. Entries empha-sised were removed from consideration from second stage refinement . . . 62
4.4 Formatting Edits . . . 62
4.5 Adoption Thresholds for Experiment 1 . . . 63
4.6 Overview of Automated Mediation for Concepts . . . 64
4.7 Overview of Automated Mediation for Properties . . . 65
4.8 Semi-Automated Mediation: Reinstate Questions . . . 66
4.9 Automated Mediation: Minority to Majority Adopt Questions . . . 66
4.10 Unprocessed: O3 . . . 67
4.11 Unprocessed: O4 . . . 67
4.12 Unprocessed: O5 . . . 67
4.13 Unprocessed: O6 . . . 68
4.14 Unprocessed: O8 . . . 68
4.15 Extended and Formatted: O3 . . . 68
4.16 Extended and Formatted: O4 . . . 68
4.17 Extended and Formatted: O5 . . . 68
4.18 Extended and Formatted: O6 . . . 69
4.19 Extended and Formatted: O8 . . . 69
4.20 Automated Mediation: O3 . . . 70
4.21 Automated Mediation: O4 . . . 70
4.22 Automated Mediation: O5 . . . 70
4.23 Automated Mediation: O6 . . . 70
4.24 Automated Mediation: O8 . . . 70
4.25 Semi-Automated Mediation: O3 . . . 71
4.26 Semi-Automated Mediation: O4 . . . 71
4.27 Semi-Automated Mediation: O5 . . . 71
4.28 Semi-Automated Mediation: O6 . . . 71
4.31 Vs. Gold Standard: Automatic Mediation . . . 74
4.32 Vs. Gold Standard: Semi-Automatic Mediation . . . 74
4.33 Effect of Mediation on Object Properties . . . 74
5.1 Types of invalid concept labels . . . 80
5.2 Example Equivalence Cases . . . 82
5.3 Formatting Edits . . . 83
5.4 Adoption Thresholds for Experiment 2 . . . 83
5.5 Entities removed through WordNet filter . . . 88
5.6 Automated Mediation Overview . . . 90
5.7 Experiment 2: Equivalency Question Overview . . . 92
5.8 Semi-Automated Mediation Overview for Experiment 2 - ‘Either / Or’ Ma-jority Adoption Questions . . . 94
5.9 Overview: Reinstate and minority adoption to majority adoption questions . 95 6.1 Summary of Participants . . . 103
6.2 Summary of Submitted Entities . . . 108
6.3 Effect of Automated Mediation on CTF . . . 108
6.4 Pre-Mediation: O1 . . . 111
6.5 Pre-Mediation: O2 . . . 112
6.6 Pre-Mediation: O3 . . . 112
6.7 Pre-Mediation: O4 . . . 112
6.8 Pre-Mediation: O5 . . . 112
6.9 Automated Mediation: O1 . . . 113
6.10 Automated Mediation: O2 . . . 113
6.11 Automated Mediation: O3 . . . 113
6.12 Automated Mediation: O4 . . . 113
6.13 Automated Mediation: O5 . . . 113
6.14 Semi-Automated Mediation: O1 . . . 114
6.15 Semi-Automated Mediation: O2 . . . 114
6.16 Semi-Automated Mediation: O3 . . . 114
6.17 Semi-Automated Mediation: O4 . . . 114
6.18 Semi Automated Mediation: O5 . . . 114
6.19 Summary of Automated Mediation (II) . . . 116
6.20 Semi-Automated Mediation: Reinstate Questions(II) . . . 117
6.21 Semi-Automated Mediation: Majority Adopt Questions(II) . . . 117
7.1 Experiment 1: Mediation Outcomes . . . 122
7.2 Competency Questions answered by submitted models (Pre-Mediation) . . . 124
7.3 Competency Questions answered by submitted models (Post-Mediation) . . . 125
This dissertation is original, unpublished, independent work by the author, Anton R. Minnion.
Finding easier and less resource-intensive ways of building knowledge resources is neces-sary to help broaden the coverage and use of semantic web technologies. Crowdsourcing presents a means through which knowledge can be efficiently acquired to build semantic resources. Crowds can be identified that represent communities whose knowledge could be used to build domain ontologies. This work presents a knowledge acquisition approach aimed at incorporating ontology engineering tasks into community crowd activity. The success of this approach is evaluated by the degree to which a crowd consensus is reached regarding the description of the target domain. Two experiments are described which test the effectiveness of the approach. The first experiment tests the approach by using a crowd that is aware of the knowledge acquisition task. In the second experiment, the crowd is unaware of the knowledge acquisition task and is motivated to contribute through the use of an interactive map. The results of these two experiments show that a similar consensus is reached from both experiments, suggesting that the approach offered provides a valid mechanism for incorporating knowledge acquisition tasks into routine crowd activity.
This work would not be possible without the support and encouragement of my family. In particular my mother Jean, my father John and my step-mother Sandra. Additionally I would like to acknowledge my fellow occupants of Room G22, Martyn Lloyd-Kelly, Matias Garcia, Adam Wyner, Muhammed S. Khan and Luke Riley. I would also like to thank my supervisors Peter McBurney, David Jackson and Valentina Tamma.
I would also like to acknowledge Nick Anning, academic, investigative journalist and colleague who sadly passed away in 2003. Without his advice and support I would never have started my academic career.
Introduction
This research did not start as a semantic web project. It started by looking at ways to make maps smarter so that they could be used to perform more sophisticated tasks. The problem was that traditional digital maps such as GoogleMaps orOpenStreetMap
are built on quantitative data, with all the entities on the map largely defined by their quantitative properties. Map objects were defined as being points, lines or polygons; each rooted to a coordinate system and the distance between objects measured in metres and miles. The problem with this quantitative foundation is that it fails to represent how people view the world. A new way of representing locations on maps was needed, one which could communicate the qualitative properties of that location. So instead of something being ten metres away, it could be described as being nearby. So that an architect can describe a building in the terminology that makes sense to him/her, while a restaurant critic could describe the same building according to the properties of the restaurant it houses. As a result of investigating the idea of building qualitative maps, a solution emerged — ontologies. Ontologies take many forms and can relate to knowledge domains at both higher and lower levels. For the purposes of this thesis, an ontology provides a description of the knowledge needed to describe a particular subject domain. Ontologies usually consist of concepts, which determine what type of objects are being described, and object properties which establish how concepts can be linked. They may also contain the instances of the concepts along with data properties that can be used to link concepts to static data such as strings, integers or even coordinates. Additionally, ontologies embody a logical system that can be understood and used by computers to infer new knowledge and make new connections. If maps were based on ontologies, the kind of qualitative links that are needed to build smarter maps, and more adaptable for specialist groups of users, could be created.
The problem of using ontologies in this way is that they are difficult to make. There is a scarcity of people with the skills needed to build ontologies. In order to bring the power of ontologies to a broader range of applications, less resource-intensive ways of creating ontologies are needed. Some work has already been done which aims to automate the building of ontologies, typically these analyse a body of domain-specific data from which an ontology can be inferred. These techniques can broadly be referred
to as ‘ontology learning’ and are described in more detail in Section 2.5 of this thesis. The problem with existing ontology learning techniques is that they still require human input to make them work. Moreover, the input that is needed has to come from people with specific skills and understanding of ontologies. The approach offered in this thesis aims to reduce the need for expert human input in the ontology learning process by obtaining consensus through crowd mediation.
In recent years, when human-resource issues presents itself in terms of data collection, it is not long before crowdsourcing is mooted as a potential solution. Crowdsourcing seeks to use the interconnectedness of the web to collect data and perform tasks by util-ising human input. Traditionally crowdsourcing has been seen as a way of distributing large tasks so that they can be performed quickly. But another aspect of crowds is that the can be distinguished by the subject or the task that they address. GalaxyZoo1, for example, which looks to harness crowd input to categorize observed galaxies according to their shapes, takes advantage of the potential scale of the crowd to perform a huge task. However, to contribute toGalaxyZooa participant would most likely be motivated by an interest in astronomy and would likely have a level of expertise. Therefore, we can attribute a greater degree of astronomical expertise to the crowd contributing to
GalaxyZoo than would normally be present. Along with the collective knowledge of the crowd, the fact that they are willing to spend time contributing towards such a project indicates a good level of motivation.
Using crowdsourcing to build an ontology may be a trivial task compared with map-ping the shape of billions of galaxies, however it does offer major challenges. While the scale of the crowd is of much less importance, the sophistication of the tasks that need to be performed is much greater. However, if a crowd can be identified whose interests encompass a specific and identifiable knowledge domain, if a consensus over the knowl-edge within the crowd can be reached, and if that crowd can be motivated to perform the tasks required, then it may feasible that ontologies and other semantic resources could be crowdsourced. This is the hypothesis that is addressed in this research.
The research questions being addressed by this work are:
• Can a mechanism be found for eliciting knowledge from the crowd in such a way as to facilitate ontology building?
• Can conflicting crowdsourced knowledge be reconciled to provide a consensual model of a domain?
• Can knowledge that is unable to be reconciled to a consensus be effectively iden-tified so that it can be dealt with manually?
• Can the mechanism be embedded into routine crowd activity so that the ontology building task is hidden?
• To what degree can crowdsourcing produce a consensus over the description of a knowledge domain?
Literature Survey
2.1
Preface
This literature survey will summarise the most relevant and influential work relating to the employment of ontology in knowledge-based systems (KBS) with emphasis on the knowledge acquisition process that communicates human knowledge to electronic form.
Notation
In this and subsequent chapters the term ‘expert’ is used to describe the domain expert, that is to say the person or people who hold the real-world knowledge regarding the domain which is being modelled. Unless otherwise specified, the ‘expert’ will have no or unknown competency in regard to knowledge engineering and ontology engineering processes. ‘Knowledge engineer’ is used as a generic term to describe the person or people who have the required technical skills to implement knowledge engineering and ontology engineering methodologies and to construct KBS and their component parts. The distinction betweenknowledge acquisition andknowledge elicitation should also be made. Knowledge elicitation is the process of obtaining knowledge from the expert through techniques such as interviews and brainstorming [99]. Knowledge acquisition is a broader set of activities, including knowledge elicitation, along with the explication and formalization of that knowledge into a form in which it can be used in KBS [18].
2.2
Knowledge Engineering
2.2.1 Development of Knowledge Engineering
Knowledge engineering has traditionally been defined as the process of developing in-formation systems in which knowledge and reasoning play pivotal roles [99]. Over time these information systems (or KBS) have evolved and been adapted to meet the needs of ever more sophisticated applications which employ increasingly powerful reasoning techniques that rely on knowledge models with greater expressiveness.
Studer et.al. [105] provide an analysis of the general change in thinking among knowl-edge engineers that occurred towards the turn of the last millennium. The changes de-scribed are important as they have led to the development of new ideas and practices which have come to underpin modern knowledge engineering, paving the way for the incorporation of resources such as ontologies that enable sophisticated reasoning tasks. Studer et.al. characterise these changes as being part of a general paradigm shift from a ‘transfer view’ of knowledge engineering, in which KBS presents a direct reproduc-tion of human knowledge, to a ‘model-based’ view where there is more emphasis on the problem-solving dynamic and where knowledge is organised into multiple models that contain only the required knowledge to address particular sets of problems [105]. According to Studer et.al.:
“building a KBS means building a computer model with the aim of realizing problem-solving capabilities comparable to a domain expert” [105].
This statement means that the objective of modern knowledge engineers is to solve problems in a waycomparable to the expert, meaning that there is no need to simulate the cognitive processes associated with human problem-solving, as might be the case in a knowledge transfer approach [105]. According to Studer et.al., one factor leading to this paradigm shift was the identification of problem-solving methods (PSM) that were independent from the human cognitive process but, nonetheless, could be adapted to support the development of more sophisticated knowledge representations that support a similar degree of inference to human-cognitive approaches.
Making problem-solving knowledge explicit and regarding it as an important part of the knowledge contained in KBS, is the rationale that underpinned the increased focus on PSM in the pre-web era [105]. Credit for the identification and early formalisation of PSM is given to Clancey [17] who identified common problem-solving behaviours in early attempts at building KBS, even when the representations produced from these systems differed considerably; and from these generic behaviours he developed a heuristic classification. Studer et.al. break down this heuristic classification into a set of roles and inferences whereby observable knowledge, such as a temperature or a name, can be associated with an abstract, and from that abstract a heuristic match can be made from which a solution can be inferred [105].
is separate from the process of identifying the appropriate PSM. Bylander et.al. intro-duces GT approaches as a way of exploiting the “interaction problem” which states that the representation of knowledge is dictated by the problems which that knowledge is being acquired to solve [11]. GT approaches associate each problem-solving task with a particular knowledge acquisition method [11], meaning that unlike RLM, each task is influenced by the knowledge acquisition process employed. GT approaches require a pre-determined and fixed knowledge structure of the domain to be specified, that pro-vides the knowledge needed to solve a task [105]. This means that multiple PSM can be employed to fit specific problem-solving tasks. While the work presented in this thesis is not directly related to KBS, it is important to provide as broad background as possible so that a greater understanding can be achieved.
2.2.2 Knowledge Engineering Methodologies CommonKADS
The evolution of knowledge engineering described above has helped establish the the-oretical principles that govern modern knowledge engineering practices, particularly in terms of making the distinction between types of knowledge, and in the need to spec-ify problem-solving functionality. From this research, a focus on devising knowledge engineering methodologies emerged with the aim of providing a more controllable devel-opment cycle for building and maintaining KBS.
CommonKADS is a knowledge engineering methodology that, through a long period of development, has emerged as one of the pre-eminent candidates for building KBS. Schreiber et.al. provide a comprehensive description of the CommonKADS methodol-ogy [99]. CommonKADS is a Knowledge Engineering methodolmethodol-ogy that boasts consider-able academic and industrial support, and which is currently used to support numerous projects across a variety of disciplines [109, 118]. The development of CommonKADS arose from the need to build industry-quality knowledge systems on a large scale and in a structured, controllable and repeatable way [99].
While the aim is to provide some flexibility, Schreiber et.al. note that certain knowledge models can be employed across a range of applications to identify a set of task templates to help facilitate the re-use of models [99].
To manage CommonKADS, it is suggested that specific ‘process roles’ be assigned to effectively manage human input and human oversight of the knowledge engineering pro-cess. Of specific relevance to this work is that Schreiber et.al. clearly see the knowledge provider (expert) as having a key role. The expert is independent from the knowledge engineering process, and whose primary role is to provide the requisite information to develop the necessary knowledge models [99].
Schreiber et.al. acknowledge ‘bogus’ or non-useful expertise as an issue and empha-sise the need to consider the nature of the knowledge provider in subsequent knowledge engineering processes. The issues of bias and other human fallibilities are briefly dis-cussed, followed by an analysis of elicitation techniques including interviews, protocol analysis and repertory grids [99]. In the majority of knowledge elicitation the starting point will be an interview. Unstructured interviews can be used, that allow the expert to express themselves without any formal constraints [99]. Essentially unstructured in-terviews are an informal scoping exercise that allow the expert to express the salient features of a given domain in a way that is familiar. A structured interview may also take place at a later stage using leading questions and constrained dialogue techniques. Structured interviews allow for more useful expert input in terms of explication into usable knowledge models, however, this inevitably curtails the freedom of the expert to communicate their knowledge in a way that is natural to them [99].
According to Schreiber et.al., a common problem in interviews is that they fail to capture aspects of the domain which cannot be verbalised. Usually this is because instinctive knowledge is built from a rationalisation that is natural to the expert but difficult to ‘decompile’ in an expressible form [99]. Informal interviews are used in the initial stages of development, while a structured interview is often used to fill in gaps in the knowledge model after a degree of model-building has already been completed. Be-yond interviewing, a further method of knowledge elicitation is protocol, analysis which requires the knowledge engineer to observe the expert at work and establish common decision-making processes from which rules can be derived [99]. While the knowledge elicitation process provides ways to obtain knowledge from a single expert, it fails to address the possibility that knowledge elicitation may be achieved through collaboration between groups of experts.
MIKE
reliable and maintainable KBS [3]. MIKE specifies that, alongside the models that contain the static knowledge of the domain, a model of generic problem solving-methods should also be developed along with the heuristic rules that govern their application to the static knowledge. The division into two types of knowledge model, constitutes an implementation of the distinction between ‘symbol level’ and ‘knowledge level’ as described by Newell [77]. The knowledge level exists above the symbol layer (the static knowledge) and is linked with the idea of rationality, i.e. some form of rationality can be imposed on the symbol level from the knowledge level [77].
In MIKE it is acknowledged that developing a formal specification directly from interviewing the expert is difficult, and therefore it suggests building ‘mediating’ rep-resentations [76] or semi-formal reprep-resentations that can be understood by the expert. This allows them to be part of the modelling process, particularly in terms of evalu-ation [3]. A formal representevalu-ation is then derived that establishes a model for static,
functional anddynamicknowledge representation, these contain, respectively, the static, problem-solving and heuristic knowledge aspects [3]. MIKE uses Knowledge Acquisition and Representation Language (KARL) [33] to build the formal model.
Towards Ontologies
A recurring feature of modern Knowledge Engineering Methodologies is that they rely on multiple models that provide conceptualisations of different knowledge areas. Under-standing what these models are, how they work and how they are devised, provides the flexibility needed for these methodologies to adapt to differing applications. However, the creation of these model-sets (knowledge bases) for each KBS has associated costs in terms of the time, effort and expertise required. These costs have led to an increasing focus on the development of ontologies to describe knowledge domains that can be re-used across multiple applications, or extended to meet new requirements. Indeed, while Schreiber et.al. do not discuss ontology in any great detail, there is an acknowledgement that ontology points the way forward to providing the knowledge base that will underpin the next generation of KBS:
“Ontologies should be seen as a ‘natural next step’ on the road to more expressive information modelling” [99]
2.3
Ontology, Ontology Engineering and
Ontology Building
these instructions [15]. In more precise terms, Gruber [40] describes how ontology, in its modern sense, is used to facilitate knowledge representation and knowledge sharing. Gruber describes ontologies as an explicit specification of a conceptualisation; and a conceptualisation as an abstract, simplified view of the world that we wish to represent for some purpose [40]. Here, ontologies are explicit documents, used to specify the things that exist in a given domain.
According to Gruber, another important aspect of ontology is ontological commit-ment, whereby agents within an ontology are said to commit if all their observable behaviour is consistent with definitions provided by that ontology [40]. Gruber asserts that an ontology should provide a guarantee of behavioural consistency between entities within a given domain[40]. Gruber goes on to state that formal ontologies should be designed according to the following five criteria: clarity of communication, coherency, extendibility, minimal encoding bias and minimal ontological commitment [40]. Coding bias occurs when design choices are made only for the purpose of efficient implemen-tation and should be avoided when possible. Avoiding ontological commitment where it is unnecessary is important because unnecessary commitments may reduce interoper-ability with other ontologies. Gruber aims to provide a a set of design principles with the objective of improving interoperability between ontologies, it does not provide any explicit methods to actually design and build ontologies.
To see how ontologies are actually developed for use in KBS, the development of ontology engineering needs to be discussed.
“Ontology engineering refers to the set of activities that concern the ontology development process, the ontology life-cycle, the methods and methodolo-gies for building ontolomethodolo-gies and the tool suites and languages that support them.” [36]
G´omez-P´erez et.al. provide a comprehensive description of ontology engineering processes and demonstrates how ontology can be incorporated into information systems through ontology engineering [36]. Ontology engineering is concerned with formalising the processes that are required to build a formal ontology. While G´omez-P´erez et.al. provide a comprehensive overview ontology engineering process, it is the chapters re-lating to ontology building that are of most relevance to this work. In Chapter 3 [36] ontology building methods and methodologies are discussed. This discussion uses case-studies to illustrate the ‘classical methodologies and methods’ which have emerged in order to build ontologies [36]. For this review a brief summary of some of the presented case-studies is now provided in order to give general context for the approach offered .
Cyc [63] is an early attempt to build a common-sense knowledge base which con-taining over a million manually entered assertions and for which a bespoke language,
a process for the manual extraction of knowlege; secondly a process for computer-aided extraction; and thirdly a fully computer-managed process for extraction [36]. Cyc can be considered a ontology because it has a communication layer in its design that allows it to be utilised by other intelligence systems [36] that include modules for interaction with database systems, thesauri, agents systems and natural language tools for inter-acting with WWW [36]. However the fact that an argument has to be made that Cyc provides an ontological resource implies that there may be difficulties in conceptually reconciling it with modern ontologies.
G´omez-P´erez et.al. [36] describe the ontology building method initially described in Uschold and King [112] and later extended in Uschold and Gruninger [111] (to include more detail regarding the scoping phase of ontology building and to specify the role of competency questions in the methodology) as the “first method for building ontologies” [36]. Uschold and King provide a ‘skeletal methodology’ for ontology building that has four stages [111], identifying scope and purpose of ontology to be built, the actual building of the ontology, evaluating the ontology and, finally, documenting the ontology. The informal part of the scoping phase consists of brainstorming, followed by grouping concepts into naturally forming categories, with the objective of forming viable definitions [111]. Interestingly, no mention is made of who might be performing the brainstorming and categorising, whether an expert is present and, if so, how they communicate with the ontology engineer. Uschold and Gruninger strongly advocate a middle-out (as opposed to top-down and bottom-up) term acquisition process that requires the user to define the fundamental terms used in the domain before defining any related terms which are either more abstract or more specific [111].
Uschold and Gruninger also discuss the broader need for agreement (or consensus) to be made regarding the concept definitions[111], yet while a solution for dealing with term ambiguity is specified, only a set of guidelines [111] are provided for dealing with general disagreement in definition.
properties of domain-concepts, relationships between these concepts, any logical axioms that have been defined as well as any constants and formulas used [67]. An example of an intermediate representation is presented in L´opez-Fern´andez. et.al. [67]. L´ opez-Fern´andez. et.al. make the claim that the intermediate representations created are understood and validated by the domain expert and the human end-user alike [67].
The knowledge acquisition process employed in the given example of METHON-TOLOGY does not differ hugely from that generally used in knowledge engineering (see section 2.2.2) in employing formal and informal interviewing techniques. Here, the ex-pert is consulted as and when the knowledge engineer feels that elicitation is needed [67]. In the description of the METHONTOLOGY implementation from L´opez-Fern´andez. et.al. the expert is used, not as an integral part of the process, but as a point of ref-erence that can be used to obtain ‘clues as to what [the knowledge engineer] were to look for’ [67]. While this may be appropriate for obtaining knowledge from experts who are reasonably well-versed in the concept of knowledge representation, it may be com-promised if the expert fails to understand the intermediate representation, leading to a flawed validation process. There is also no procedure for using collaborations between groups of experts (unlike the methodology proposed by Uschold and King / Uschold and Gruninger).
The NeOn methodology for ontology engineering, described in Suarez et.al. [106], is an example of a modern approach which puts emphasis on how ontologies are used and reused within the context of an increasingly networked world. So far, there are various instances of successful real-world implementation that have used NeOn [13, 37, 65, 114]. NeOn places much emphasis on defining processes which allow for efficient re-use and interoperability with other ontologies and semantic resources [106]. Perhaps the biggest difference from previous methodologies discussed is that NeOn concentrates on how to build ontologies within the context of the broad networks of interconnected semantic resources in which they will exist. NeOn, like previous ontology engineering approaches, does not define a strict work-flow; instead it defines procedures to follow given partic-ular scenarios. In total there are nine of these scenarios [106] that deal with a range of important and emerging challenges such as re-engineering, ontology merging and the incorporation of ontology design patterns. Only the first of the given scenarios covers the initial specification and modelling that is performed. While it is acknowledged that the ontology specification, which includes the conceptualisation through knowledge ac-quisition, is an essential aspect of any ontology building endeavour, there are no defined processes in this regard and there is no indication as to how knowledge elicitation should be performed.
is not addressed at all. There has been massive progress in improving processes that enhance the way in which ontologies can be used; however, from reading the literature on ontology engineering methodologies, there is little evidence that the way knowledge is acquired from the expert has changed since the establishment of ontology engineering in the 1990s.
2.4
Bottlenecks
For the purpose of this work the two distinct ‘bottlenecks’ are defined, theknowledge re-engineering bottleneck and theknowledge acquisition bottleneck. A bottleneck describes, in broad terms, the major challenges that hinder the adoption, refinement and effec-tiveness of knowledge systems. It should be noted that in some publications these two bottlenecks are considered as a single bottleneck encompassing the challenges present in both [7]. While the re-engineering bottleneck is not directly relevant to this work, in order to illustrate the distinction between the two bottlenecks a brief description is provided.
2.4.1 The Knowledge Re-Engineering Bottleneck
Hoekstra describes the knowledge re-engineering bottleneck as “the general difficulty of [facilitating] the correct and continuous reuse of pre-existing knowledge for a new task” [47]. Looking back at the NeOn methodology we can see that of the nine scenarios, for which solutions are defined, five specify situations in which resources need to be either re-engineered or restructured in order to facilitate reuse [106]. This general difficulty occurs for two reasons: firstly, because the proliferation of semantic resources built in an uncontrolled manner that need to be reconciled to some standard [47]; and secondly, be-cause of the scarcity of skilled knowledge engineers. A broader analysis of the knowledge re-engineering bottleneck and how it is being overcome can be found in Hoekstra [47].
In addition to devising more sophisticated methodologies to facilitate re-engineering processes, there has been a move towards collaborative ontology engineering in order to distribute the process thus reducing development time and improving oversight. This has manifested itself in various efforts to develop software tools to facilitate collaborative ontology development. These include OntoWiki [5], WebProt´eg´e [110] and Moki [25] along with various other projects too numerous to list.
2.4.2 The Knowledge Acquisition Bottleneck
easily expressed by being written down orheuristic meaning that part of knowledge that ‘constitutes the rules of expertise, the rules of good practice, the judgemental rules of the field [and the] rules of plausible thinking’. The problem, as Feigenbaum saw it, was that the acquisition of both forms of knowledge was a “tedious, time-consuming, and expensive procedure” [31]. In more succinct terms KAB can be characterised as “the difficulty to actually model the domain in question”[16].
One solution proposed to deal with KAB is to find ways of automating the construc-tion of ontologies from data-sets. These ontology learning methods are discussed in the next section.
2.5
Addressing the Knowledge Acquisition Bottleneck
through Ontology Learning
2.5.1 Ontology Learning using Text Resources
Ontology learning is the idea that we can develop ontologies from data-sets that are known to encompass the scope of the target knowledge domain. Described another way, ontology learning is a way to automate knowledge acquisition using pre-existing data. Many ontology learning approaches use natural language processing (NLP) techniques to identify patterns which indicate relationships between terms. While most textual re-sources on the web do not have any explicit semantic structure that can be directly used with traditional knowledge acquisition, it is possible to glean some of this knowledge by processing the structure of the language itself. Several approaches exist to convert lexico-syntactic patterns into ontology-friendly structures. Lexico-syntactic patterns aim to reduce term ambiguity within text by specifying more restricted contexts in which the term can be defined. Furthermore, it can facilitate the identification of semantic relationships [69].
Some of the earliest work relating to the identification of patterns for enriching se-mantic content was carried out by Hearst [44] who identified certain textual cues within text (such as Ais a B or A[,]and other B) that indicate a hypernym/hyponym relation-ship. While these rules were a starting point, more sophisticated approaches have been developed to negate the inevitable false-positives and lack of recall produced through the application of Hearst’s rules.
used to identify as yet unknown hypernym/hyponym relationships between noun pairs in new texts. In this approach lexico-syntactic patterns that indicate hypernym/hy-ponym relationships are identified through the learning process and then applied to new text resources [103]. This approach outperformed WordNet’s classification when com-pared to a human-generated list [103] that was used as a gold standard. The approach offered by Snow et.al. has since proved useful when applied to much larger data-sets [72]. Ritter et.al. [95] presented a pattern-based method to find hypernyms within arbi-trary noun phrases. The authors ascribe to the goal of “machine reading”, which aims to extract information from text to support a range of inferencing capabilities [29]. The focus is specifically centred on a process termed ‘ontologizing’, in which arbitrary noun phrases are analysed to discover hypernyms [95] that correspond with the class/subclass relationship present in ontology. Ritter et.al. use a support vector machine classifier to find the correct hypernyms with use of an adapted version of Hearsts patterns which excludes matches made where there is a known to be high frequency of returned error [95]. Maedche and Staab introduce an approach that incorporates NLP-based ontology learning into a broader knowledge acquisition process [68]. Acknowledging that fully automated knowledge acquisition from ontology learning is a distant goal, the authors propose ontology learning as a component part of a broader ontology engineering so-lution where the knowledge engineer plays a supervisory role [68]. With this in mind, a knowledge acquisition architecture is proposed that utilises machine learning to help facilitate the partial extraction of domain ontologies from web resources [68]. The ar-chitecture uses components of theOntoEdit Ontology Engineering Workbench[107, 108] alongside a resource processing and algorithm library [68]. OntoEdit provides the graph-ical interface for the knowledge engineer while the resource processing library provides various tools for manipulating the incoming web-resources, including the indexing of HTML documents, identifying explicit and implicit data-structures, and NLP processes that can be applied to the text such as tokenizing [68]. The algorithm library provides a set of resources that facilitate a ‘multistrategy’ approach in which specific algorithms can be used to acquire the type of knowledge that is required [68]. Using this approach has enabled users to identify likely concepts, cluster concepts hierarchically and deter-mine a set of potential association rules [68].
from text analysis are provided by Ortega-Mendoza et al. [83] and Sang [97].
2.5.2 Ontology Learning using Web Resources
There are also examples of ontology learning that do not rely on natural language pro-cessing [21, 34]. Sabou et.al. [96] developed a framework for ontology learning from Web Services. Web services are considered as self-contained, self-describing, modular appli-cations that can be published, located, and accessed via the Web [92]. The framework for knowledge acquisition offered by Sabou et.al. exploits the fact that these sources are expressed in a specific and logically restrained sub-language, making them amenable to automatic analysis [96]. Inevitably within the structure of a web service, some explicit or implicit reasoning knowledge, beyond that which is expressed in natural language, will exist that can be used for ontology learning.
The web also contains more explicit knowledge structures that can be leveraged to build ontologies. Folksonomies are explicit taxonomic structures generated in a bottom-up manner by encouraging system users to categorise their input through tagging activ-ity. Tags allow users to categorise documents and other entities by associating a symbolic label which can then be reused by other users. Websites such asflickr andDelicious use and generate folksonomies through the tags created by their many users. Folksonomies can be an effective way of mapping users’ cognitive collaborative understanding of a domain[28, 56].
While folksonomies do not necessarily have any heirarchical structure or restrictions, they can be enhanced through the use of rule-sets that allow for the basic modelling of concepts [27]. Folksonomies are dynamic because knowledge representations will change through usage, and the emergence of new knowledge will be captured. Moreover, because folksonomies are created automatically there is less need for specialised skills and they can, therefore, be employed in minority subject-domains which would not necessarily appeal to ontology engineers. Folksonomies can either be broad, where tags are created by a large number of interconnected users, or narrow, where tags are created and intended for idiosyncratic use by a particular group or community [27, 28].
The problem with folksonomies is that they are prone to three basic issues: poly-semy, where a tag can be interpreted in more than one way, leading to misclassification; synonymy, where two or more tags impart identical or very similar meaning; and gran-ularity, where there is great variety in the level of abstraction of tags [28, 35]. Given these problems and the general lack of semantic coherence [35], ways are being sought to incorporate ontological features with folksonomies with the aim of producing adaptable knowledge management systems. These would provide the flexibility, collaboration and information aggregation of folksonomies, with the standardization, automated validation and interoperability of ontologies [27, 28].
In order to build such models, a number of methods have been developed aimed at com-bining folksonomies with ontologies. These range from using ontologies to augment and replace existing tags within to help improve interoperability and reasoning capabilty [1]; to approaches that use algorithmic methods to construct entirely new ontologies from a set of tags so that identical items could be tagged at different levels of specificity [28].
Abbasi et.al. [1] devised a system called T-ORG that automatically organises and categorises tags. This categorisation is done by manually selecting concepts from sin-gle or multiple ontologies related to the domain [1]. Concepts in the ontology that are not required are then removed (pruned), redundant and conflicting concepts are refined and the ontology or ontologies are augmented with missing concepts to fill in the gaps, again, this is a manual process. Then using, lexico-syntactic patterns (discussed earlier) concatenated with the tag names to be organised, a call is made to the Google search API [1]. By finding terms that the patterns frequently match within the text of the returned Google search results, a good guess can be made as to which concept they belong to in the ontology [1].
Allen and Schneider provide a case-study on how a folksontology can be created [2].
Cisco Systems, inc. wanted to create a folksontology to support their internal technical support team. The objective of building such a system was to streamline the response of technicians to incoming support requests by ensuring that these requests were placed correctly in the support infrastructure [2]. An additional goal was to enhance the ability to capture the knowledge from customers and map this knowledge to a pre-existing taxonomic structure so that all support requests could be consolidated into a restricted and standardised vocabulary [2].
Cisco then formed groups of experts for each major technical area, each group being given the ability to manage the tag framework, allowing them to perform tasks including tag removal and augmenting tags with meta-data [2]. Each group would be charged with specifying the set of tags that characterise the content of their area with the assistance of a set of rules to identify good tags to adopt [2]. The tags could then be managed with additional semantic information using a tag management application which used Resource Description Framework(RDF) by specially trained staff [2]. The ontology or ontologies were then pruned and refined so that they could efficiently interoperate.
Acquiring and enriching ontology structures from the analysis of Linked Data (dis-cussed in section 2.9.1) has also been the subject of various research efforts [19, 59, 87, 120].
2.5.3 Shortcomings of Ontology Learning
are constantly changing. In this way ontology learning techniques can be effective in capturing emerging and alternative conceptualisations within a domain [34], especially when used with existing tag-based web resources.
However, ontology learning techniques are limited in what they can do. We see that approaches utilising NLP can be effective in discovering hypernym/hyponym relation-ships; however, ways to identify more nuanced semantic properties are underdeveloped or lacking completely. Those methods which exploit existing web structures clearly require the input of highly trained individuals to act as knowledge engineers. In the case-study offered by Allen and Schneider a ‘taxonomist’ is employed to facilitate the construction of the folksontology, while Abbasi et.al. is reliant on significant manual pre-processing, even if the final stages of classification are automated. Ontology learning, in general, offers much promise, particularly in terms of acquiring new and emerging knowledge, however, it is broadly acknowledged that large quantities of data by itself may not be adequate to build complete ontologies without significant human input [88].
2.6
Addressing the Knowledge Acquisition Bottleneck through
the use of Controlled Natural Language
Denaux et. al. [23] propose an approach to ontology development that seeks to “seam-lessly” integrate the development processes that are used to build the conceptual and the logical aspect of the ontology. To do this, Denaux et. al. advocate a holistic approach involving the use of three components; Kanga a methodology for building do-main ontologies [60]; Rabbit [42, 43] a controlled natural language (CNL) that enables knowledge encoding in human-readable form; and ROO [24], a user-friendly ontology development tool that uses Rabbit. The approach offered by Denaux et. al. puts the domain expert in control of ontology development by making them use a CNL. This allows them to communicate all the information needed to build a domain ontology in a way that can easily be converted into a logical form. This approach is interesting as, by placing the domain expert at the centre of the process, it requires the consideration of wider issues such as interface design, and how language can be used to bridge the gap between knowledge engineers and domain experts.
2.7
Addressing the Knowledge Acquisition Bottleneck through
the use of Templates
Parreiras et. al. [86] suggest that the use of templates could potentially make ontology development easier. Templates are made up of reusable axioms or statements about a domain, produced by a domain expert in an appropriate form (such as a table, a set of rules or some other structured format), that can then be used by an ontology engineer as a building-block for building an ontology. Parreiras et. al. present a standard way to develop such templates. The approach extends existing metamodels, such as OMG OWL [82], using templates allows for greater level of abstraction which is of benefit to both the domain expert and the ontology engineer.
A limitation of using such an approach is that it still relies on domain experts to have some technical expertise. In the case of the approach offered by Parreiras et. al., for example, a requirement is the use of Unified Modelling Language to build the templates needed. This means that some technical expertise is needed on the part of the domain expert.
2.8
Addressing the Knowledge Acquisition Bottleneck
through Collaborative Ontology Development
As mentioned earlier, there are various ways to conduct collaborative ontology engi-neering. There are many tools, including WebProt´eg´e [110] and Moki [25], to facilitate this activity. These can, of course, also be used to address KAB as they facilitate the input of knowledge in a distributed way, potentially speeding up the acquisition process. Holsapple and Joshi provide a description of the benefits and shortcomings of collabo-rative ontology building [48]. Unlike standard ontology development environments, in a collaborative approach the final model of the acquired knowledge can be obtained from a diverse range of sources which are iteratively reconciled until consensus is reached regarding the ontological commitments [48]. Of course this supposes that the collabora-tive dynamic is not undermined by human-behaviours that could affect the oversight of such endeavours. According to Holsapple and Joshi, coordination of the design process may suffer if too many persons are directly involved and to overcome such situations a consensus-building mechanism needs to be employed. [48].
better evaluation techniques.
In general, the tools used to facilitate collaborative ontology development still present a high expertise threshold in terms of their use. If the expert or experts holding the domain knowledge are not well-versed in the fundamental principles of ontology design then they will be unable to use such systems directly, meaning that there would still be a heavy reliance on the knowledge engineer.
2.9
Broadening the Semantic Web
We can see from the discussion on ontology learning that much work has been done to perform automated knowledge acquisition over web resources through either NLP or through the analysis of existing web-resources. However, because of the expert input required, in neither of these cases can the knowledge acquisition bottleneck be said to be fully addressed. Furthermore, all the ontology learning approaches outlined thus far are useless if there is no data-set that encompasses the domain. Because ontology en-gineering is an expensive process, knowledge enen-gineering efforts have been concentrated in a few commercially viable areas. However, if we are to move significantly towards the ‘universality’ goals of the semantic web, where all information on the web can be understood by machines [8], a way of semantically enhancing a greater range of knowl-edge domains needs to be found. But do we really need to create resource intensive ontologies to do this? One approach to enhancing semantics on the web has been to develop Linked Data.
2.9.1 Linked Data
The term Linked Data refers to a set of best practices for publishing and connecting structured data on the Web [9]. Heath and Bizer provide a description of Linked Data, how it works and how it has been adopted [45]. The basic idea of Linked Data is to use the general architecture of the web to facilitate the sharing of structured data on a global scale [45]. By using Universal Resource Identifiers (URIs) to reference not just web pages, but also representations of real-world objects and abstract concepts, Linked Data provides basic semantic resources that can be easily accessed through the HyperText Transfer Protocol (HTTP) [45]. The Resource Description Framework (RDF) [57], a simple graph-based data model, is used to describe these concepts as well as specifying the links between these concepts and annotated web resources. RDF’s core data model is the subject, predicate, object relationship, commonly referred to as triples [45] (See figure 2.1 for an illustrated example of triples in use).
Figure 2.1: Basic RDF structure describing ’Eric Miller’ from the RDF Primer [70]
“Just as hyperlinks in the classic Web connect documents into a single global information space, Linked Data uses hyperlinks to connect disparate data into a single global data space” [45].
RDF provides Linked Data with a simple and unifying data model, while the use of established technological architecture allows for easy access — all of which means that linked data establishes a better platform for data discovery and for self-description than traditional web [45]. Often, but not always, the conceptualisation of Linked Data is provided by an ontology that determines the abstract concepts and properties.
The success of Linked Data can be seen in its widespread adoption both in business and governmental domains. There are numerous examples of Linked Data being used in various contexts [14] and there are now some well-established Linked Data repositories and websites that use Linked Data including DBpedia1 [62], a semantically annotated version of Wikipedia,Geonames2 a geographical database and the BBC website 3 [58]. Many Linked Data resources can be found within a broader network called the Linked Open Data Cloud4. There has also been a concerted effort by government agencies to provide Linked Data. Hendler et.al. are generally positive about governmental uptake of Linked Data claiming that it has been embraced by the US Government and, as such, plays an increasingly important role in government information sharing [46]. Shadbolt and O’Hara provide a more mixed review of the state of Linked Open Data efforts by the UK government [100]. While praising much of the work that provides access to Linked Data, they acknowledge that uptake in some areas is slow due to the ‘complex combination’ of administrative and technical tasks needed to be performed, meaning
1http://dbpedia.org/ 2
http://www.geonames.org
3http://www.bbc.co.uk 4
that Linked Data supports only around 5% of available data on data.gov.uk [100]. Linked Data, no matter how plentiful, or how high the quality, is no substitute for the development of ontologies. Bechofer et.al. looked at how Linked Data is used in research environments in general and concluded that while Linked Data help to publi-cise the results of publication data, it cannot enable reusing, sharing or reproducing of research without the use of additional resources [6]. Jain et.al. goes further by claiming that Linked Data is only of limited value in building the semantic web [51]. The short-comings of Linked Data according to Jain et.al. are that there is a lack of resources that provide a conceptual description, a lack of schema mappings and a general lack of expressivity [51]. Jain et.al. also suggest that the over-reliance of Linked Data libraries on upper-level ontologies like DOLCE [71] and SUMO [78](ontologies that provide the most-abstract conceptualisation), means that the level of conceptualisation may be inap-propriate for making meaningful linkages between data-entities [51]. Moreover, Linked Data emphasises the need to enrich data rather than acquire knowledge. It can’t be used as a means of determining domain knowledge. In fact, to make best use of it, domain knowledge needs to be pre-specified in the form of vocabularies, schemas or on-tologies. While Linked Data has been effective in broadening the availability of semantic resources, the semantic qualities that it communicates are relatively weak.
2.10
Knowledge Acquisition through Crowdsourcing
From the discussion so far, it can be seen that the knowledge acquisition required to build domain ontologies is difficult to achieve without knowledge engineering skills; that ontology learning techniques cannot yet build the fully-functional ontologies required of the semantic web; and that the high-quantity, basic knowledge conceptualisation offered by Linked Data is insufficient in key areas. Therefore, if the KAB is going to be addressed we need a solution that avoids an over-reliance on qualified knowledge engineers, whilst being powerful enough to capture the knowledge required to allow a good level of automated reasoning.
2.11
Crowdsourcing
If we take the example of Wikipedia — by far the most used crowdsourcing platform — we can see that there is a body of research attesting to its accuracy and reliability [10, 26, 54, 64, 75, 117]. Given the scale of Wikipedia, this might seem remarkable; however, the key to the success relies not on the magnitude, but on the motivational dynamics of the crowd, and the mediation mechanisms available to them.
Panciera et.al. analyses the behaviour of contributors to wikipedia and notes that there is a core of users, or ‘Wikipedians’, who contribute, mediate and safeguard against malicious input in the majority of cases [84]. Preidhorsky et.al. notes that if Wikipedians are the contributors who make up the top 10% of users as judged by number of edits, then their contribution is 85% of the total edits[90]. These key contributors take on a group ethos and adopt informal rules and routines that are important in producing a consistent knowledge resource [84]. Further work on the motivational factors is provided by Nov [79], who noted that the leading motivations for these contributors were that they felt an ideological need to contribute, but most of all, because they saw it as fun.
2.11.1 Motivating Crowds to Perform Tasks
The traditional incentive of monetary gain can be used to motivate crowds to perform tasks, a process often referred to as ‘microtasking’. This is seen in Amazon’sMechanical Turk5 service, that allows crowds to perform tasks in return for a small payment. This kind of crowdsourcing, sometimes termed crowd work, is becoming more popular, and is seen by many as a trend that points the way towards how work will undertaken in the future [55].
Building ontologies may not be many people’s idea of fun, it may not even be many knowledge engineers’ idea of fun. However, as Wikipedia has proved, making something fun could be the key to motivating crowds to conduct knowledge acquisition tasks.
In ‘Designing Games with Purpose’, von Ahn and Dubbish introduce the idea that valuable tasks can be performed by crowds as a ‘side-effect’ of the primary activity they are engaged in [115]. The concept of Games With a Purpose (GWAP) is that computation can be a bi-product of gameplay, and it has proved very successful — as demonstrated by the success of reCAPTCHAG. This uses a security form that validates human users to identify a scrambled word along with a word taken from printed copy, thus providing a mechanism for digitising printed copy.
2.12
Using Crowdsourcing for Ontology Engineering
Noy et.al [80] look at the general feasibility of using crowds to perform ontology en-gineering tasks. They evaluate the performance of MTurk crowds, against that of a pool of domain experts in validating the conceptualisation. The evaluation is concerned with validating superclass/subclass relationships; the authors describe this activity as hierarchy-validation.
5
The authors perform this evaluation by repeating an ontology validation experiment from Evermann and Fang [30], where two ontologies were used (SUMO [78] and the Bung-Wand-Weber (BWW) ontology [39]) to extract natural language questions that could be presented to 32 paid student volunteers. In Evermann and Fang, the questions were manually constructed and could be answered with a simple true or false response. The MTurk crowd user had to pass a basic test in order to qualify to participate, requiring correct responses to 8 out of 12 high school-level biology questions. There were also some safeguards against SPAM, a known issue withMTurk; whereby any result-set with 23 identical answers out of 28 was disqualified. Additionally, a bonus was paid to those users who contributed 75% correct answers when compared with a gold standard. The results of the experiment presented by Noy et.al show that theMTurk crowd was less accurate than the domain expert (66.7% compared to 81.2% from the Evermann and Fang experiment). When given term definitions with each question, the crowd performed significantly better with an accuracy of 81.8%, as compared with the experts who returned 88.5% accuracy.
These results would suggest that crowdsourcing is a viable approach to validating ontology hierarchy structures, provided the crowd is given additional context with which to make decisions. Given the speed and availability of the crowd as compared to do-main experts, this approach is attractive to ontology development efforts with limited resources.
2.12.1 Crowdsourcing for Ontology Alignment
Sarasua et.al. introduceCrowdMAP, a model for using ‘microtasking’ input to perform ontology alignment through the use of paid crowds [98]. Ontology Alignment, or On-tology Matching as it is sometimes called, is the process of making corresponding links between concepts across ontologies. The authors argue that there are four key benefits to employing crowds for ontology alignment. Firstly, humans can validate links without having to be provided with much context. Secondly, the task of verification can be broken down into atomic tasks that correspond to individual mappings, making them easier to deal with. Thirdly, even though ontologies can be large, crowdsourcing can cope with the scale of processing that is needed. Finally, ontology alignment is not a process that can be fully automated at present; incorporating crowdsourcing may help augment existing and future machine-driven approaches.
In Sarasua et.al. the research questions being addressed are: 1. Is ontology alignment amenable to microtask crowdsourcing?
2. How does such a human-driven approach compare with automatic (or semi-automatic) methods and techniques, and can it improve their results?
While acknowledging that Games With a Purpose (GWAP) [116] might also be ap-propriate as a motivator, the authors opt to use a crowdtasking platform called crowd-flower6, which presents the mapping tasks to numerous fee-paying crowdtasking services, including MTurk.
The CrowdMAP workflow, in brief, has the following stages. Each concept map-ping is presented to the user (member of the crowd), who can validate the mapmap-pings according to a selection of relationships, namelyequivalency (where the concepts are the same), subsumption (where the concepts have a superclass/subclass relationship) and
merynomy(where the concepts have constituent part-of relationship). Validation occurs for equivalence relationships if the task produces only equivalencies, i.e. if the first three results produced from the microtask are asserted to be equivalent. When other types of relationship are validated, or when there is a mixed response to the task, a greater degree of confidence is required.
Sarasua et.al. evaluate the performance of their approach by comparing the results of the crowdsourcing approach with mappings provided by the Ontology Alignment Evaluation Initiative. From this comparison, a precision and recall can be measured. Where the crowd was presented with a full set of mappings from a known ontology alignment, the approach achieved a 100% recall, indicating that the crowd was able to provide meaningful input for all mappings. This also proves that the crowd could easily deal with the scale of computation required. While the precision was less, the overall results show some promise and compare favourably with other alignment methods.
Ontology alignment is not directly part of the knowledge acquisition process and therefore this approach does not address the Knowledge Acquisition Bottleneck. Nev-ertheless, the value of CrowdMAP for the purpose of this work is that it demonstrates that crowds, with unknown expertise, can effectively make judgements on concept and relationship validity.
2.12.2 Crowdsourcing for Knowledge Acquisition
So far, the examples given show that crowdsourcing can be used for ontology engineering tasks outside of knowledge acquisition. The following examples show approaches that address aspects of the knowledge acquisition process.
Siorpaes and Hepp provide an early attempt to use games to facilitate ontology engineering tasks [102]. The authors present OntoGame, a platform for performing various ontology engineering tasks. OntoGame is intended to address what the authors term “the Incentive Bottleneck” by providing an entertaining and competitive means of validating ontology relationships. With reference to the Ushold and King/Gruninger methodology [111, 112], the tasks where game motivation could be used are identified. These include:
• Collecting named entities to describe a domain
6
![Figure 2.1: Basic RDF structure describing ’Eric Miller’ from the RDF Primer [70]](https://thumb-us.123doks.com/thumbv2/123dok_us/8072812.227202/37.893.297.658.131.416/figure-basic-rdf-structure-describing-eric-miller-primer.webp)