Abstract— Data in educational institutions are developing continuously and rapidly along these lines there is a need of advancement, that this large and excessive amount of data is to be converted into helpful data and need of implementing data mining technique. Educational data mining is concerned with the application of various statistical analysis, data mining technique, machine learning which will be helpful for school, colleges and universities Educational data mining is the zone of science where various kinds of techniques are being created for analysis, looking and investigating data and this will be valuable for better comprehension for the further studies and the settings they learned. As the data is predefined, the classification of object in the view is data mining and information management procedure is utilized as a part of comparable data questions altogether. Decision Tree is a very valuable and well-known classification method that helps in decision making based on the possible consequences, that can be event outcomes, resource costs or utility. It contains conditional control statements. One explanation behind its noticeability comes from the accessibility of existing calculations that can be utilized to assemble decision trees. In this paper we will survey the different ordinarily utilized decision tree calculations which are utilized for classification.One application behind its noticeability comes from the accessibility of existing calculations that can be utilized to assemble decision trees. In this paper we will survey the different ordinarily utilized decision tree calculations which are utilized for classification. We will likewise be thinking about how these decision tree calculations are done and are made appropriate and valuable for educational data mining and which one is ideal.
Index Terms— Educational data mining (EDM), Classification, Dropout Prediction, decision tree, learning management system.
I. INTRODUCTION
Learning management system is designed to train students with specific skills and to identify learning gap, utilizing analytical data and reporting. Students can gain knowledge by the attending the courses and can be analysed with the help of test reports. As researcher concentrates on the new region of research, which is called EDM (Educational Data mining).
Revised Manuscript Received on May 24, 2019.
Devika Radhakrishnan M.Tech CSE Final Year Student, Shri Ramdeobaba college of Engineering & Management, Nagpur.
Dr Shubhangi Neware Assistant Professor Department of Computer
Science, Shri Ramdeobaba college of Engineering & Management, Nagpur.
EDM is the information disclosure in database strategy or the data mining in instruction. There are great cases of how to apply EDM systems to make models that foresee dropping out and understudy disappointment. These works have showed the most promising outcomes related to those sociological, monetary, or educational qualities that might be more relevant in the forecast of students who are low scholars .so the low scholarly execution is checked. The specialist focuses on the improvement of technique to better understand further studies and the settings in which they learn. Students data are collected and report is generated for this process.
display.
The data in any given educational association is growing fast and progressing day by day. There is a need to change this data into helpful data and learning; so further we make utilization of data mining and its technique.
Differentiating data and finding valuable data covered up in fundamental and essential databases is a lot more troublesome task. For creating assurance to answer for accomplishing this goal successfully is utilization and reveal in databases technique or data mining in training is needed to be done. There should be assurance that there is progress made in every in individual based on the reports obtained. [15].
Educational data mining techniques taken from a variety of compositions, including data mining and machine learning, psychometrics and different ranges of measurements, data perception, and computational displaying. Be that as it may consists, a large portion of the examination on the use of EDM to determine the issues of topic which is in study, disappointment and drop-outs has been connected principally to the particular instance of advanced education and all the more particularly to on the web or separation instruction. There is almost no or Less data about particular research on educational and LMS has been found. The data that has been found or discovered, it uses just some limited strategies, not DM methods. Various other methods have been implemented except DM.
It introduces the most of the majority of the procedures was produced for the educational data mining, which further see the disappointment and
dropout understudies or predict the failure rate.so,
based on the report
improvement can be done.
An Experimental Analysis of Various
Algorithms for Classification in Educational
Data Mining with the help of LMS
As we are doing research over the new territory or new kind of topic of center for the specialists is EDM.
Lms completely helps with the analysis of the report. It can be considered or depicted that Classification as a continuous, regulated learning calculation in the machine learning process. It lowers down class marks of students to data objects in light of previous data of class which the data records have a place. In classification a given arrangement of data records is divided and classified into sets. The approvement model is then used to order and further see the new arrangement of data records that is not the similar as both the data sets i.e preparation and test data sets. The tree structure is utilized as a part of arranging different kind of data records. There are two steps in which Decision tree classification system is performed these are tree building and tree pruning. The first is created as preparing sets and other is tests data sets. The preparation data set is considered as a part of forming the classification display, whereas the test data record is considered as a part of model for improvement. Tree building is done in top-down way in tree pruning. The tree is recursively transferred till every one of the data things have same class name and are in same place. Tree pruning is done is a base up. Tree pruning is utilized in order to enhance the forecast and classification exactly of the calculation by limiting over-fitting. This is because of the reason that at this stage the data set is filtered just once. Methods that again and again segments a data set of records utilizing profundity first voracious approach or expandability initially approach until the point when every one of the data things have a place with a specific class in this examination, we will audit Decision tree calculations executed, recognize the ordinarily utilized calculations. Over-fitting in decision tree calculation brings about misclassification mistake. In decision tree the calculations can bring mismatch classification because of overfitting’s tree pruning is tested less as in contrast with tree development stage Auditing is done based on the report generated from the LMS system from the specific college students.
II. RELATEDWORK
Decision tree plays an important role in order to develop a strategy for both acceptance research and data mining. Decision tree is basically considered for presenting the classification and expectation. The ID3 classification is very majorly used classification. ID3 calculation is the most technically utilized calculation in the decision tree up until this point. Having an overlook in the fundamentals of decision tree concept and outlining on the fundamental thoughts of decision tree in data mining. He worked on various kinds of concepts. It is utilized to build a decision tree by testing every hub's trait of tree in top-down manner. The calculations in Id3 performs property choice. The calculations of ID3 is a far better of C4.5 calculation and it was created by a data mining software engineering scientist Ross Quinlan in 1983.Ross Quinlan was very famous scientist in the field of EDM.In this concept like component utilizing Entropy and Information Gain idea is there. Essential method for data mining and synthetical
realizing, which is generally used to frame classifiers and expectation models is done in decision tree [2].
Decision Tree is a helpful and relevant classification process that inductively takes in a model from a given arrangement of data. It takes all the data and classification is performed.C4.5 is a best amongst the most exemplary classification calculations on data mining. One explanation behind its prominence emerge from the accessibility of existing relevant calculations that can be utilized to manufacture decision trees [3].
Ramaswamy et al. [4] presented a method research topic information which has 33 highlights including class mark of 6 include determination procedures were connected on the informational index, for choosing the pertinent properties. The ballot was casted observation demonstrated the most noteworthy prescient exactness of 89% and various observations were made. These properties have an applicable incentive to the case studies under research result. Diverse order calculations were utilized.
Adhatrao, et al. [5] began with an ID3 and C4.5 Decision tree method on instructive information mining. First-year many studies and researches were made and information was gathered. The research further was carried to second year. The thoughts and framework were utilized to predict the consequence of same research studies in the second year. The value was exactly of the ID3 calculation is 75.145% and that of C4.5 is 75.145%. They were very closed investigation can be utilized to predict the further studies outcome that was dependent on past semester marks of the students.
Z. J. Kovacic et al. [6] presented a very contextual matter after various investigations and research work on instruction- based information mining to recognize up to what degree list information can be utilized to present research prosperity. They considered two kind of trees namely CART and CHAID choice trees basically. Based on the research the precision of classifiers received was 59.4 and 60.5 individually.
Bharadwaj, et al. [7] materialized an ID3 choice tree learning calculation with the assistance of the past model which incorporated the preparation set. They found out the importance of the choice tree, its use and the reason why it should be used for making decisions. In their investigation, they find out the explanations behind utilizing choice tree calculations. With the help of choice tree and along these lines, there is a need to present Educational data mining system that is achievable for rudimentary and optional instruction. At this important decision-making point, they chose or selected the root hub as a quality which consist of the most upraised data
increase and discovered which characteristic was the
following choice. The
they made was based on hub until they came up short on traits. Finally, their ID3 arrangement calculation has produced the choice tree for climate informational collection. . Their final choice was ID3arrangement. They determined the entropy esteems for each quality in the informational collection. They afterward determined data gain for each property.
Acharya et al. [8] tried out the connected element determination procedures. And, also information mining calculations under his research work. The information was collected from the engineering college. The information has been gathered from St Xavier's College, Kolkata. Various and diverse kind of component determination procedures were attached to the information for removing the significant traits and disposing of excess characteristics. They got 79% precision. That was the closest prediction.
In this paper concept of C5.0 decision tree was used. Also, C5.0 calculation takes after the principle of calculation that is the large decision tree can see as an arrangement of guidelines which is straightforward. This process of calculation gives the recognize on grammar, errors and missing data. As compared to CART technique, this technique overcomes the issue of over fitting and mistake pruning is tackled by this method calculation. In classification procedure the C5 classifier can checks out which properties are important and which are not applicable in classification, when we compare them with each other. [5]
In this paper the process implemented is named as CHAID, it is a kind of decision tree method. The tree balancing is the main concept in this paper. It depends on balanced hugeness testing. It is a comparable form to relapse examination. This process was previously known as CHAID being initially known as XAID. Its importance and value for classification and for recognition of connection between factors was very known. This procedure was produced in South Africa. [11].
The most important and fundamental variation between CART, ID3 and C4.5 is the way by which the transferring of data is performed. Truck utilizes the Gini list to choose the part quality, though ID3 and C4.5 utilize an estimation of data pick up and the data pick up proportion. The classification of data was done.
The paper presented the concept of SLIQ named as Supervised Learning in Ques approach. It was highlighted by Mehta et al in 1996.This was very fast and adaptable decision tree. It is quick, adaptable decision tree. The calculation that can be executed in serial and parallel example. This method does not depend on Hunt's calculation for decision tree classification. It differentiates large amount of data. It divides a preparation data set recursively. It utilizes expansiveness first voracious procedure. This method is coordinated with pre-sorting method consisting with the tree building stage [17].
Cart is relapse tree. CART is Classification trees. Researcher worked on this. It was presented by scientist Breiman in 1984. It invents the two classifications and regressions trees. These two types of trees were used. With the help of CART, the classification tree was developed. It
depends on these pairs part of the characteristics. This was added executed serially by Breiman et al. It utilizes Gini record part measure for choosing the part quality. By utilizing a segment of the data prepared of data set. Pruning is finished by utilizing a segment of the preparation data set in truck. It is additionally in view of Hunt's model of decision tree development. This method utilizes both numeric and clear-cut properties for building the decision tree. It also consists of in- constructed highlights that arrangement with missing qualities of data. These approaches were having their own importance in classification process. [16].
Shafer produced the concept of Dash is Scalable Parallelizable Induction of decision Tree calculation. This process is very fast. It was presented by Shafer et al. It is a quick and adaptable decision tree classifier. This method was completely unlike with other methods. Like SLIQ it utilizes one-time kind of the data things. It has no limitation on the info data estimate. This method was very effective when compared with other because of its data estimation process. [18].
The present decision tree calculations likewise contrast in their capacity to deal with various sorts of data, and by a wide margin the most exceptional calculation of the gathering is C4.5. The structure of a decision tree gives thinking to each statement of class esteem, and it is trusted that this thinking is anything but difficult to understand.
Quinlan’s prior work was ID3 based on the same concept was C4.5 and is equipped for taking care of large amount of ceaseless data, data that is incomplete or data with missing esteems, and even has worked in ventures for repeatedly arranging the resultant decision tree.
C4.5 was considered more appropriate as considered with ID3. The classifier is tried first to group undistinguished data and for this reason coming about decision tree is utilized. C4.5 calculation takes after the standards of ID3 calculation.
III. PROPOSEDWORKSYSTEM
As we know LMS is very vast and important concept in present day situation. As researchers concentrate on the new area of research, with advanced features which is EDM (Educational Data mining). It is the learning disclosure in database method or the data mining in instruction. The concept should be advanced and technically strong in the field of EDM. The researchers focus on the advancement of
technique to better cope up with the present studies going on in the present scenarios and the settings in which they learn There are great cases of how to apply EDM methods to make models that anticipate dropping out and understudy disappointment. Based on the report generated the comparison will be performed.
In this venture data mining methods are connected to future research in the field of
EDM and dropout in
prediction in Campus Selections. We will perform research to find out the details of failure ratio of students in the campus placements. At this point the pre-processing and data mining techniques system is connected on the gathered under research data for removing of undesirable highlights. By utilizing every single accessible element, the trials are directed for enhancing the exactness to anticipate which understudy has GOOD or AVERAGE in the examination, by utilizing every individual accessible element. Likelihood ratios are foreseen together.
In view of the classification rules understudy dropout and disappointment is being anticipated. These works have demonstrated promising outcomes as for those sociological, financial, or educational qualities that might be more significant in the forecast of low scholastic execution.
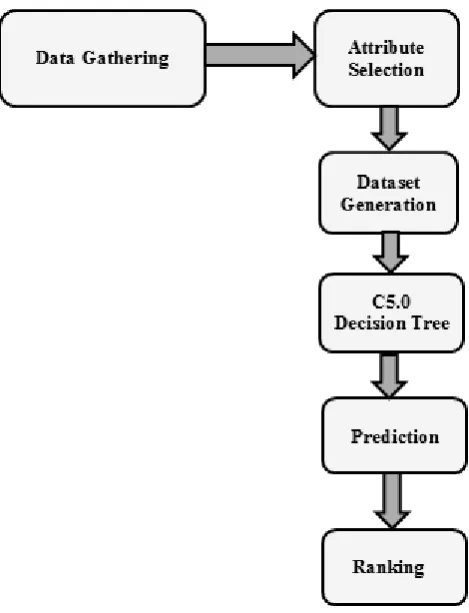
[image:4.595.52.287.356.663.2]In this framework C4.5 decision tree calculation is proposed for expectation of research process execution. C4.5 is the prominent decision tree classifier in data mining. After tree fabricating the tree pruning is connected to enhance the exactness of classifier and to diminish the extent of the tree. At last the regular examples are created by utilizing FP development calculation to anticipate the likelihood of dropout.
Figure 1: System Architecture
IV. DATASET DESCRIPTION
A. Data Collection
The information has been gathered from Engineering College from the research of software engineering and Engineering. At first, the information estimate is 47
records X 12 characteristics. Alms reports are created data records are collected of the students of engineering college.
B. Data Preparation
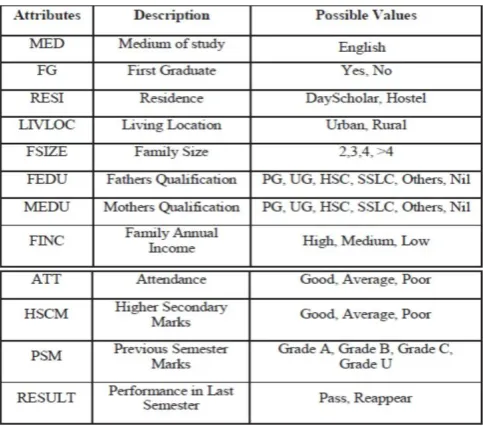
The research information is gathered from a review. Various individual data are collected. The qualities are MED (Medium of Study), FG (First Graduate), RESI (Residence), LIVLOC (Living Location), FSIZE (Family Size), FEDU (Fathers Qualification), MEDU (Mothers Qualification), FINC (Family Annual Income), ATT (Attendance), HSCM (Higher Secondary Marks) and PSM (Previous Semester Marks). RESULT is the reliant variable. Properties utilized in this examination are depicted in Table I. Data preparation is most important process as based on the prepared, data analysis is done and the output is obtained. Data preparation is one of the essential and most important tool of data preprocessing.
Data is gathered in order to access the hidden pattern in the educational field with the help of data mining and to identify the flaws in the performance of the students. In this we will try to inculcate good practices and obtain the better performance by students. Based on the above characteristic studies are done and we will reach to a final conclusion based on output.
(FINC - Family Annual Income): It will be arranged into 3 classes: High - above 100000 Rs, Medium- 30000 Rs to 99999Rs Low – beneath 29999Rs every month.
(ATT - Students Attendance): It is part into 3 classes, that is, Good – over 95, Average 80 – 94, Poor beneath 80.
(HSCM - Higher Secondary Marks): Based on their imprints, it will be sorted into 3 gatherings, for example, Good – Above 60, Average 40 – 59, Poor – beneath 40.
(PSM - Previous Semester Marks/Grade): It is
Taken from MCA course. It is part into four class esteems: Grade A - Above 80, Grade B – 65-79, Grade C – 51-64, Grade U - Below 50.
Here, all factors are as straight out qualities. The Result is the needy variable and every single other variable are the indicator factors. Data sets are framed together.
C . Preprocessing
The research information has been made for the preprocessing stride the most important step of all. Instead preprocessing every single individual table are consolidated into a single table framed with every single adequate datum and furthermore missing qualities are likewise overlooked. Later FINC, ATT, HSC, and PSM were arranged utilizing If Then Rules. Preprocessing can build the arrangement precision. The proposed arrangement of Pre-handling contains two stages.
[image:5.595.53.295.48.261.2]Stage 1: Removing Missing Values Step2: Categorization
TABLE II SAMPLE DATA SET-1.1
In light of the Pass and Reappear classification the outcome will be anticipated. In the wake of taking out the missing qualities and mistakes, the measure of the information is 44 records with 12 traits. Test informational index 1 and 1.1 are depicted in Table II and Table III
TA BLE III. SAMPLE DATA SET-1.1
IV.MATHEMATICAL
FORMULATION Mathematical Formulation
M= (Q, W, P, q0, F) where, Q is the set of States
W is the set of inputs
P State Transition table q0 is the initial stage F is the final Stage
1. Q: S1, S2, S3, S4, S5
Where,
S1: Get testing input.
S2: Prototype calculation using hierarchical. S3: KNN Classification.
S4: Global Fusion using the threshold value and the fusion rule.
S5: Credal
classification. 2. W: W1, W2, W3
Where
W1: Incomplete Pattern. W2: Edited pattern.
W3: Meta Class. W4: Fusion Data. 3. q0=S1
IV. CONCLUSIONS
This paper is a review of the best in class regarding EDM. In which data has been prepared with the help of learning management system. Reports are generated and output is depicted. Review are done from the most applicable work around there to date. It would be exceptionally hard to physically experience the vast arrangement of scholarly records to distinguish the research patterns and conduct and the example in which they learn. Comparisons are done and reached to final decision about the various EDM process involved from different papers. Record is maintained of poor scholar students. Rather, if client makes utilization of data mining strategies on the expansive measure of scholastic record, he/she can without much of a stretch gathering the understudies, distinguish shrouded designs about their learning styles, discover unfortunate understudy conduct and perform understudy profiling. In this way, data mining can unquestionably be a vital apparatus and part of mechanically progressed educational systems.
REFERENCES
[1] Carlos Márquez-Vera, Cristóbal Romero Morales, and Sebastián Ventura Soto, “Predicting School Failure and Dropout by Using Data Mining Techniques”, Ieee Journal Of Latin-American Learning Technologies, Vol. 8, No. 1, February 2013 IEEE.
[2] IU Qin, “Data Mining Method Based on Computer Forensics-based ID3 Algorithm”, 978-1-4244-5265- 1/10/$26.00©2010IEEE [3] Rong Cao, Lizhen Xu, “Improved C4.5 Algorithm for the Analysis of
Sales”, Sixth Web Information Systems and Applications Conference, 978-0-7695-3874-7/09
$25.00 DOI 10.1109/WISA36, © 2009 IEEE
[4] Ramaswamy, M., and Baskaran, R. 2009. A study on feature selection techniques in educational data mining. arrive preprint arXiv:0912.3924
[5] Adhatrao, K., Gaykar, A., Dhawan, A., Jha, R., and Honrao, V, "Predicting Students' Performance Using ID3 and C4.5 Classification [6] Algorithms." arXiv preprint arXiv, Vol.3, No.5,
September 2013, pp.39-52
[7] Baradwaj, B. K., and Pal, S. 2012. Mining educational data to analyse students' performance. arXiv preprint arXiv:1201.3417.
[8] Acharya, A., & Mukherjee, S. "Modeling Value Chain Analysis of Distance Education using UML." International Conference on Modeling, Optimization, and Computing. Vol.1298. No. 1. AIP Publishing, 2012.
[9] Alana M. de, Morais and Joseana M. F. R. Araújo, Evandro B. Costa, “Monitoring Student Performance Using Data Clustering and Predictive Modelling”, 978- 1-4799-3922-0/14/$31.00 ©2014 IEEE.
[10] Mehta, M., Agrawal, R., and Raisanen, J. (1996). SLIQ: A fast scalable classifier for data mining. In EDBT 96,
Avignon, France
[11] Mishra, T., Kumar, D. Gupta, S.,” Mining Students' Data for Prediction Performance”, Advanced Computing & Communication Technologies (ACCT), 2014 Fourth International Conference on 8-9 Feb. 2014.
[12] B.K.Bhardwaj and S.Paul, “Mining Educational Data to Analyze Students Performance”, International Journal Advanced Computer Science and application Vol. 2 No. 6, 2011. Kovacic, Z. "Early prediction of student success: Mining students' enrolment data." [13] Yohannes Kurniawan, Erwin Halim, “Use Data Warehouse and
Data Mining to Predict Student Academic performance in Schools: A Case Study (Perspective Application and Benefits)”.
[14] B.K.Bhardwaj and S.Paul, “Mining Educational Data to Analyze Students Performance”, International Journal Advanced Computer
Science and application Vol. 2 No. 6, 2011.
[15] Lewis, R.J. (200). An Introduction to Classification and Regression Tree (CART) Analysis. 2000 Annual Meeting of the Society for Academic Emergency Medicine, Francisco, California.
[16] Kin Fun Li, David Rusk and Fred Song, “Predicting Student Academic Performance”, 2013 Seventh International Conference on Complex, Intelligent, and Software Intensive Systems.
[17] Shafer, J., Agrawal, R., and Mehta, M. (1996). Sprint: A scalable parallel classifier for data mining. Proceedings of the 22nd international conference on very large data base.
AUTHORSPROFILE
Devika Radhakrishnan received bachelor of engineering degree in Computer science and engineering from S.B Jain Institute of Technology Mnaagement & Research, Nagpur University.Currently pursuing M.tech from Shri Ramdeobaba College Of Engineering And Management, Nagpur in computer science branch and research paper work focuses on Educational data mining.
Dr. Shubhangi Neware completed her bachelors degree