International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7, May, 2019
Abstract: Besides, the large overall firms over the globe have down to earth involvement in crucial city assurance and rational utilization of imperativeness. Need the essential of abuse imperativeness in a very practical methodology is that the need for making countries like the Asian nation and China. The improvement of reasonable structure metersgave North American nation access to a no small measure of imperativeness usage learning. This data given by reasonable meters may be used quickly to supply encounters into imperativeness conservation measures and exercises. Different imperativeness spread firms harness this learning and procure surprising results concerning the customer’s usage plan. They then when acting examination envisions the solicitation and use of customers. This examination causes them to settle on a decision the duty at the sole inspiration driving your time. The associations endeavor to beat the bottleneck in capital hypothesis cost of learning. Further, handle extensive data for layout time, and examination may be a moderate methodology and is not adequately quick to reinforce period picking. Our venture shows a ’Business Intelligence mechanical assembly’s that use Apache Hadoop to manage the regular issues rapidly. Taking the advantages t of this gadget, imperativeness scattering firms will reduce the endeavor by abuse bunch hardware that runs R Tool. The usage of appropriated preparing gadgets conjointly reduces the time break broadly to change time allotment discernment and to pick. This gadget also will reduce carbon impression and unmistakably related issues in imperativeness flow together with loses and wrongdoing. Later on, this equivalent examination may be done on different utility resources like gas and courses utilized in calming organization time impediments.
Index Terms: Power, Consumption, SAX Algorithm, Time Series
I. INTRODUCTION
Examination of imperativeness use data to achieve encounters into client use precedents is what control wholesalers endeavor to accomplish for some logical applications like, time-of usage obligation, demand response organization and asking precision. This reasonable meter assembles adapting each minute which ends up in delivering a fantastic course of action of learning of information through the current mechanical meter accumulates data by hourly or month to month. These extraordinary figuring out how to reserve capacities and therefore the idea of information process learning change altogether with unique applications. Old-fashioned RDBMS of utility firms may be a bottleneck in beating this methodology. Along these lines, for the business to have the benefit of the reasonable grid hypothesis, it is indispensable that the extraordinary measure of information influenced conceivable by useful meters to be dealt with rapidly in accomplice dealt with how that helps arrange overseers make favorable judgments to work structure safely, monetarily and reliable. Apache Hadoop is that the goals conceivable to deal with over issues that continue running on antique machines only. It has coursed
figuring gadget that has Goliath amassing moreover as procedure capacity. We watch out for an area unit abuse Apache Hadoop framework that enables for the scattered method of long learning sets across over gatherings of PCs. Hadoop Map Reduce may be a structure for data treatment of substantial learning sets. Outdated RDBMS or alternative applications zone unit plenteous slower and inefficient in dealing with enormous learning made by reasonable meters when diverged from the Hadoop framework. As such for the business and customers to achieve edges like asking accuracy, imperativeness taking area, separating client use precedents and solicitation response organization, etc. it is endless valuable to use Hadoop that continues running on negligible exertion trinket gear. With the advancement of reasonable meters for the reasonable course and preservationist usage of essentialness, control, the made control ought to be utilized suitably with genuine economy increments to traders and along these lines the customers. This way with this centralization of essentialness allotment inside the zone of imperativeness use, which can provoke to the diminishment of carbon prints, the examination for the information got from the reasonable meters ought to be done. This enormous size of examination can need mammoth computation which may be done the assistance of flowed process framework, Hadoop. The framework’s usage can give viable, profitable yields that include requesting exactness, time-from use demand organizes, etc. this way this idea, reasonable meter learning examination, is maintained with a scrutinized of future use.
II. BACKGROUND
The proposed framework is to diminish vitality utilization use in a local private buyer. The target of the proposed strategy is to give different administrations which will give occasional vitality use of equipment’s, vitality use of the period and give instant messages. The alarm message administration incorporates the usage of unit implication in a period, control shutdown insinuation and charging data to the purchaser. The framework got productive vitality utilization related data through the shrewd meter. The vitality utilization data is broke down utilizing a choice tree calculation which creates cutting-edge data. That data will lessen cost just as vitality. The advantages of proposed frameworks are, to anticipate vitality utilization, to give month to month charging data and graphical.It changes a period arrangement X of length ‘n’ into the string of self-assertive length! where! «n! «n, utilizing a letter in order an of size a > 2.
Examining Domestic Power
Consumption using SAX Algorithm
This calculation comprises of 2 stages: It changes over the first run through arrangement into the PAA portrayal, and it transforms the PAA information into a strong portrayal. The utilization of PAA advantages of a first and proficient dimensional decrease other than giving the important lower bouncing property. The particular transformation of PAA coefficients into letters by alluding to a query table is likewise computing the down to earth, and Lineal demonstrated the preventative property of emblematic separation. Thediscretization of the PAA portrayal of a period arrangement into SAX is finished by creating images identified with the time-arrangement highlights with equal likelihood. The full and thorough investigation of different time-arrangement informational indexes accessible to the first calculation has anticipated the estimations of z-standardized time-arrangement which accomplish Normal dispersion, with its properties, it is anything but painful to pick an equivalent measured territory under the Normal bend alluding query tables in regards to breaking coordinate’s, separating under-the-Gaussian-bend zone.
III. MODEL
A. SAX Algorithm:
The ’x’ coordinates of these lines are called breakpoints either cuts, in the SAX context. The list B= β1, β2, . . ., βa−1B= β1, β2,. . . ., βa−1, that βi−1< βi βi−1< βi and β0=−!∞1β 0=−1, βa=1 βa=1 divides the area under N (0,1) into an equal area. By assigning a corresponding alpha-beta symbol alphajalphaj to each interval [ βj−1, βj)[ βj−1, βj), the conversion of the vectors of
PAAcoefficients C¯into the string C^ implemented as follows: c^⇤i=alpha⇤j, iif,c¯⇤i2[ βj−1, βj)c^⇤i=alpha⇤j,iif,c¯⇤i2[ βj−1,
βj)arrangementQ^, and C^ is characterized as
SAX exhibits new estimations for evaluating the partition among strings by widening Euclidean and PAA divisions. This limit reestablishes the irrelevant partition between two stringdepictions of the main go through arrangement Q^, and C^ is characterizedas cell_(r,c)={0,if|r−c|1βmax(r,c)−1−βmin(r,c)−1,otherwise
[image:2.595.308.538.54.256.2]cell_(r,c)={0,if|r−c| 1 βmax(r,c)−1−βmin(r,c)−1, otherwise
TABLE I
THE LOOKUP TABLE FOR 4-LETTER ALPHABET
a b c d
A 0 0 0.67 1.37
B 0 0 0 0.67
C 0.67 0 0 0
D 1.34 0.67 0 0
As presented by Li et al., thisPSAX distance metrics lower- bounds the PAA distance, i.e.
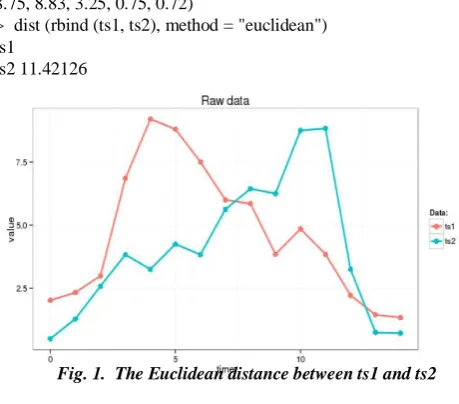
i=1n(qici)2n(Q C )2n(dist(Q^,C^))2Pi=1n(qi−ci)2≥n(Q¯−C¯ )2≥n (dist (Q^, C^))2. Digital examined the SAX lower bound in detail and observed to be better in accuracy than the phantom disintegration techniques on burst (non-occasional) informational collections.We use following time series for this example (the Euclidean distance between ts1 and ts2 is 11.4):
> ts1=c (2.02, 2.33, 2.99, 6.85, 9.20, 8.80, 7.50, 6.00, 5.85, 3.85, 4.85, 3.85, 2.22, 1.45, 1.34)
> ts2=c (0.50, 1.29, 2.58, 3.83, 3.25, 4.25, 3.83, 5.63, 6.44, 6.25,
8.75, 8.83, 3.25, 0.75, 0.72)
> dist (rbind (ts1, ts2), method = "euclidean") ts1
ts2 11.42126
Fig. 1. The Euclidean distance between ts1 and ts2
B. Information Pre-handling Module:
In this module we should make Data set for Electricity Consumption it contains a set of tables to such an extent that client subtleties, charging subtleties and installment subtleties for most recent four years .and this information initially give in MySQL database the assistance of this informational index we examination this project.R is a vernacular and condition for exact handling.
• To predict energy usage.
• To provide monthly billing information and graphical report.
• To provide an individual home appliance unit graphical description.
• Alert message service for the consumer. •
It is a GNU venture which is like the S dialect and background which was produced at Bell laboratories by john chambers and colleagues presented by Li et al., this SAX distance metrics lower-
P
Fig. 2. Data pre-processing model
IV. THE BASIC CONCEPT OF TIME-SERIES OF DATA MINING
[image:2.595.368.493.524.644.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7, May, 2019
By expansion, the expanded period and utilization of time-arrangement information have brought about a noteworthy arrangement advancement in enormous information mining. Each time-arrangement database comprises of a succession of qualities or occasions acquired over rehashed estimations of time. Time-arrangement information is broad, just as numerical and persistent, which requires consistent refreshing. Mörchen (2006) has distinguished two primary research- related objectives of time arrangement investigation—to recognize designs that characterized by the grouping of perceptions and to foresee future estimations of the time-arrangement Information—the two of which require the acknowledgment Of examples of time-arrangement information to empower the translating and coordinating of models relatively to that of different information. Kitagawa arranged time-arrangement examination into four classifications: portrayal as displaying, expectation, and flag extraction. Initially, the report alludes to strategies that viably express or outlines the attributes of time-arrangement and could include drawing figures of time- arrangement or processing essential engaging measurements (e.g., test auto relationship capacities, test auto co fluctuation capacities). Second, displaying requires the decision of a legitimate model class to appraise parameters in the model and by and large relying on the qualities of the time-arrangement and the goal of its examination. Third, expectation empowers checking of things to come example of a period arrangement by extricating different present and past data to computerelationships after some time and among the factors. Fourth and finally, flag extraction includes evacuating basic signs or valuable data from time-arrangement as indicated by the target of investigation assignments. In a comparable jackpot, Sakurai, Yamamuro, and Faloutsos (2015) have given a diagram of basic subjects identified with the time-arrangement examination: likewise, hunt and example disclosure, straight demonstrating and outline, nonlinear displaying and to estimate, and the degree of time-arrangement mining and tensor investigation. In our examination, we centeron the first, i.e., closeness pursuit and example revelation. Vikhorev, Greenough, and Brown (2013) had proposed a structure for vitality checking and the executives in the plant. The structure fuses models for vitality information trade, online vitality information investigation, execution estimation, and show of vitality use. These two methodological methodologies were received in their examination; that is activity explore (AR) system, and contextual investigation inquires about. The AR can guarantee a successive research procedure and its persistent improvement. The examination is led on the official contextual investigation by conveying the structure employing a model data framework in a machine line of critical makers. The three operational states were identified by the assembling execution framework (MES) and assessed their vitality use designs with a related envisioned interface. Le et al. (2012) have proposed a two-organize structure to distinguish six operational conditions of machines dependent on an ongoing vitality utilization design. This exploration embraces a limited state machine (FSM) to demonstrate the advanced procedures of six operational states that are, to turn off, to heat up, and to sit, syphoning and warming, start-up,
model for identifying machines’ operational states, investigatingvitalityutilizationexamples,andexecutingvitality the executives. and creation. The proposed system can be assessed on two modern infusion shaping machines in this manner utilizing Savizky– Golay sifted for coordinated flag preparing of vitality estimation information and neural systems for the characterization of vitality utilization designs. The exploratory outcomes delineate that it can accomplish 95.85% in distinguishing machine operational states and could recognize irregular vitality designs. Popeanga˘(2015) has suggested that vitality creation and utilization information recorded over a period at fixed interims is an ideal time (i.e., ordered) arrangement information mining issues. The whole procedure include five stages: gathering information from different sources (e.g., the Internet, content, databases, information distribution centers, sensors, and brilliant gadgets); directing information filtration by wiping out mistakes or sending an information stockroom to make the procedure of extraction, change, and stacking (ETL) techniques ahead of time, choosing key ascribes to be utilized in information digging for further breaking down. Recognizingandinvestigatingnewinformation,andimagining, approving,andassessingresults.Thetestofpowerutilization investigation is breaking down many time-arrangement todiscovercomparativeorcustomaryexamplesandpatterns withaquickorevencontinuousreaction.Thus,thetime
McLoughlin, Duffy, and Conlon (2015) embrace three grouping strategies—k-implies, k-medoid, and Self Original Map(SOM)—toinvestigatehouseholdpowerloadProfile Classes(PC)fordistinguishingdifferentbasicexamplesof homepoweruse.ADavies–Bouldin(DB)legitimacylistwas utilized to decide the most suitable bunching technique and the number of groups.Oh, multi-ostensiblestrategicrelapse was connected to every PC to look at the impact of familyunit qualities on power utilization. The above examinations give helpful bits of knowledge into structure vitalityinvestigation and the board systems by information stream examination dependent on the vitality load documents. At that point, the information mining related strategies can help build up the
V. INFORMATION COMPARABILITY
MEASURES FOR TIMEARRANGEMENT INFORMATION
Liu, and Yu, 2007). We have received the instinctive technique for PAA and discretized the PAA speaking to a period arrangement into emblematic portrayal strategy SAX calculation. SAX changes time-arrangement into a token string, which is the primary portrayal strategy for dimensional decrease and ordering with lower-bouncing separation measure. The calculation request two essential advances: changing the first run through arrangement into the PAA portrayal, the second one is to change over the PAA information into a string.
Another fundamental issue in the time-arrangement information mining is to decide the closeness or separation between the time-arrangement information. Note that the homogeneity and range are two related ideas; be that as it may, the length must be non-negative. There are parcel of separation measures to compute the likeness of time-arrangement information in the abstract writings, e.g., Euclidean separation (ED) (Faloutsos et al., 1994), Dynamic Time Warping (DTW) (Berndt andClifford, 1994), remove dependent on the Longest Com- mon Subsequence (LCSS) (Vlachos, Kollios, and Gunopulos, 2002), Editing Distance on Real succession (EDR) (Chen, Özsu, and Oria, 2005), Editing Distance with Real Penalty (ERP) (Chen and Ng, 2004), Spatial Assembling of Distance (SpADe) (Chen, Nascimento, Ooi, and Tung, 2007) and com- parability look dependent on Threshold Queries (TQuEST) (Aßfalg et al., 2006). Ding et al. (2008) further sorted likeness measures as lockstep, the flexible, limit based, and design-based measures.
Euclidean separation, one of the lock-step measures, it is the most widely recognized separation estimation for the time- arrangement information and furthermore shockingly aggressive with other sophisticated methodologies, mainly if the extent of the preparation set is generally substantial. Since the mapping among the purposes of two time-arrangement is fixed, these separation estimations are helpless to the clam- our and misalignments in time. Another robust calculation is Dynamic Time Warping (DTW), one of the adaptable measures, can locate an ideal arrangement among two time- subordinate groupings and is a significantly more vigorous separation measure for time-arrangement. Plus, DTW permits the time-arrangement to be extended either packed accurately, to coordinate with another out of the stage. Besides, a few lower jumping estimations that are acquainted with accelerate the comparability look utilizing DTW. Right now, affixed of lower jumping measure (TLB) is widely used to look at the execution of information portrayal strategies that are proportions of the proportion of lower bound separation to the genuine DTW or Euclidean separation. The
Fig.3. electricity consumption data mining frame work
rate is in the range [0, 1]. The higher the rate, the more tightly it gets. In light of past research (around 2008), we embraced
the TLB measure to assess the execution of our equal separation measure utilizing SAX calculation.
This diagram gives an exact view about the work stream of the entire investigation of the obtained informational collection. Everything starts with the information base reflection, which manages the live gushing information and furthermore the produces information.
VI. RELATED WORK
There is an excitement for watching practices of force customers in both the private and business divisions. With the approach of high-assurance time-course of action, control asks for data through advanced metering mining this data could be excessive from the computational point of view. Ramon Granell proposes this, Colin J. Axon on 2015 in ‘Impacts of Raw Data Temporal Resolution Utilizing Selected Clustering Methods on Residential Electricity Load Profiles’. One of the notable frameworks is clustering, however depending upon the computation, their course of action of the data can have a fundamental influence on the ensuing gatherings. This paper exhibits how common assurance of drive demand profile influences the way of the gathering method, the consistency of pack support (patterns indicating near lead), and the efficiency of the gathering methodology. This work uses both rough data from family use data and built profiles. The motivation for this work is to upgrade the gathering of force load profiles to help perceive customer sorts for the collect diagram and trading, fault and blackmail recognizable proof, ask for side organization, and essentials efficiency measures. The critical control for mining extensive enlightening lists is the methods by which little information ought to be used to get a reliable result while keeping up assurance and security.
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7, May, 2019
I
There are a few examples based bunching strategies which are utilize for various applications, for example, design acknowledgment, information mining, and so on. As of late M. K. Sheikh-El-Eslami, and S. M. Bidaki on 2009 said some of these strategies are executed in power framework contemplates, notably to cluster stack bends for planning appropriate duties, request reaction programs determination, and so forth in the paper ‘Improving WFAK-means Technique for Demand Response Programs Applications’. The decision of the best bunching technique for particular application is a standout amongst the most imperative issues which is case subordinate and ought to be considered in utilizing of grouping burden bends. Request reaction projects are broadly used as a part of force framework for various applications, for example, crests cutting, request diminishment, and so on since request reaction projects are highlighted with various attributes. Along these lines, the choice of appropriate plans for different client classes is of extraordinary significance. In this paper, an enhanced weighted fluffy normal (WFA) K-implies with the end goal of interest reaction programs applications is produced. This technique is actualized on 316 load bends of Tehran dispersion arrange, and the outcomes are examined. This paper by Carlos León & RocíoMillán on 2011 proposes a far-reaching system to identify non-specialized misfortunes (NTLs) and recoup electrical vitality (lost by variations from the norm or misrepresentation) by method for an information mining investigation, in the Spanish Power Electric Industry on ‘Variability and Trend-Based Generalized Rule Induction Model to NTL Detection in Power Companies’. It is partitioned into four areas: information determination, information reprocessing, enlightening, and prescient information mining. The creators demand the significance of the learning of the specific qualities of the Power Company client: the primary components accessible in databases are depicted. The paper presents two inventive measurable estimators to append significance to changeabilityand pattern investigation of electric utilization and offers a prescient model, because of the Generalized Rule Induction (GRI) show. This perceptive investigation finds affiliation manages in the information and a twofold Quest tree classification technique supplements it. The nature of this structure is delineated by a contextual inquiry considering a good database, provided by Endues a Company. A keen home is likely sooner rather than later, therefore ‘A Time Based Yi Yang introduced Markov Model for Automatic Position-Dependent Services in Smart Home’6, Zhiliang Wang for a critical fixing in a savvy domain, for example, a house is programmed administrations, which implies home framework itself could know or foresee what the occupant need to do, thus give tenant the administrations naturally. Many inquiries about uncover that the more significant part of the administrations in the savvy home are area subordinate so the programmed administrations must be based on the area mindfulness. In this paper, we display the occupant area design as a period-based Markov show (TMM). The re-enactment result demonstrates that contrasted with alternate models, the TMM has an arrangement of advantages, for example, less time unpredictability, higher forecast exactness and speedier unions rate. These advantages make TMM meets the necessities of programmed
administrations in a bright home.Bunching strategies are progressively being connected to private savvy meter information, which gives various vital open doors for circulation organize administrators (DNOs) toSupervise and organize low-voltage frameworks. The paper titled ’Examination and Clustering of Residential Customers Energy Behavioral Demand Using Smart Meter Data’ by Stephen Haben, Colin Singleton in 2012 tended to this is- sue. Gathering has different potential focal points for DNOs, including the recognizable proof of suitable contender for solicitation response and the difference in essentialness profile showing. Regardless, in view of the high stochastic city and irregularity of family-level solicitation, the formal examination is required to characterize legitimate credits to a cluster. In this paper, we appear all around an examination of customer sharp meter data to more readily fathom the zenith solicitation and genuine wellsprings of variability in their direct. We discover four key times, in which the data should be separated, and use this to shape imperative attributes for our gathering. We show a limited mix exhibit-based grouping, where we discover ten direct bundles depicting customers as a result of their solicitation and their capriciousness. Finally, using a present bootstrap framework, we exhibit that the grouping is trustworthy. To the makers’ learning, this is the first run through in the power structures composing that the model quality of the bundling has been attempted.
VI. EXPERIMENTAL SETUPS
We try different things with our informational index show on the errand of creating a use report. In this segment, we portray the bills utilized for this errand, the pattern techniques we contrast and, and usage subtleties of our methodology.
A. Language set up
B. R environment
It is coordinated bundle of programming offices for information control, figuring and graphical showcase. It additionally incorporatesa compellinginformation dealing with and storage, a suite of administrators for math tasks on ex- habits, grids, A broad, legitimate, coordinated accumulation of average devices for information analysis, graphical offices for information investigation and show either on-screen or on printed version, a very much created, basic and viable programming language which holds conditionals, circles, client characterized recursive capacities and as regular in and yield offices. The expression "condition" is expected to portray it as an altogether arranged and reasonable framework, as opposed to a steady gradual addition of exact and resolute instruments, as is regularly the situation with other information investigation programming.
R, similar to S, is structured around a genuine language, and it empowers clients to utilize usefulness by characterizing new capacities. A significant part of the framework is itself was written in the R tongue of S, which makes it simple for clients to coexist with algorithmicselect made. For computational handling undertakings, C, C++ and Fortran code can be connected and called around runtime. Many consider R an insights framework; we favor it as a situation inside which factual procedures can be actualized. R can be broadened (by means of bundles effectively. There are around eight bundles provided alongside the R dissemination, and a lot more are accessible on the CRAN group of Internet locales covering a broad scope of present-day insights. R has its Latex-like documentation design, which is utilized to supply far reaching documentation, both online in certain structures and printed version. Proposed idea manages giving a database by utilizing Hadoop instrument we can dissect no constraint of information and add a few machines to the group, and we get results with less time, high throughput and kept up expense is extremely less, and we are R Tool. Emblematic blend estimation SAX is the principal emblem- atic portrayal for time arrangement that takes into consider- action dimensionality decrease through and ordering with a lower-bouncing separation measure. In standard information mining assignments, for example, the grouping, characterize- tion, record, and so forth.The SAX is comparable to standard depictions, for instance, the Discrete Wavelet Transform (DWT) and Discrete Fourier Transform (DFT), while requiring a low proportion of additional room. Fur- the more, the depiction empowers authorities to profit of the wealth of data structures which are accessible and calculations in bio informatics or content mining and furnishes answers for some difficulties related with current information mining as- segments. One model is theme revelation, an issue which we have characterized for time arrangement information. There is an astounding potential for broadening and applying the discrete portrayal on a full class of information mining errands.
VIII. IMPLEMENTATION
Examine the data record and proceed to the ’Data Cleaning Step’, which is finished by changing the date configuration, changing the timestamp arrangement and read only the
subset of the data asked in the endeavor moreover check if NA is accessible in the unrefined enlightening accumulation. If all of the sections are showing up, no NA’s are accessible in the subset which is cross-checked by isolating the instructive record utilizing rundown () and plot this as well. Nextly change the date structure yet again, change the timestamp position read only the subset of the data asked in the assignment check if NA is accessible in the raw_data set. All fragments that are showing up, no NA’s in the raw_data set. All sections that are appearing, no NA’s are available in the subset. Check the informational collection utilizing synopsis () and make the plot.png. Proceed to the central part of the proce- dure i.e SAX algorithm prepare data set to
mergewithDT,loadall .csv files
’setwd("D:\\Sax\\EDAelectricpower\\all- data\\csv\\")’, prepare meta_data and extract possible interesting features from ID and merge to aggregate by sub_industry by ’end_point’, now consider the Regression lines SQ_M vs Median Load, by importing the library(MASS) and set up all the data set format form, i.e. to a line the width, columns and load the median of all the domestic data. This is performed in a cycle mode. Then plot the complete acquired results with specific representation. Transform characters to classical Date and Date &Time format (POSIX), extract ID with a whole length (105408) where the aggregate consumption to 48 measurements per day (every half hour), due to the reduction of dimensional - 48/per day is a good compromise. Some examples of consumers are Primary/Secondary School, and Plot typical represents of 4 groups of industries which consist of aggregate consumption of all consumers (43). Median for the daily profile of aggregate consumption with MAD (median absolute deviation). A median weekly profile of aggregate consumption with MAD (median absolute deviation) is created which is a forecast model for different days during the week. We added corresponding weekdays to date for data sets DT_48 and DT_agg, and now we have data sets with all needed features to build a model for different days. This procedure is a mixture of STL + ARIMA and STL + EXP besides these there are other Optional other methods like HW and naive that consists of Holt-Winters ES, through which the Seasonal naive forecast is possible too. We incorporate the function to return forecast of length one week which is clean Absolute Percentage Error and then plot forecast for one week. We can use too new, or that is.but slow (complex computation) and not as accurate as my solution. This is the end of the SAX algorithm procedure. Finally, we generate the aggregates of size 12 and alphabet of size ten smoothed time series by SMA visualize smoothed time series compute FeaTrend representation.
IX. CONCLUSION
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7, May, 2019
Therefore, we looked at the aftereffects of 2D decrease systems with different information reprocessing philosophy to foresee the condition of tempering procedure that objectives heater. We primer affirmed that PAA with information anomaly evacuation and information standardization preparing (i.e., mixture one) could accomplish somewhat superior outcomes over the FFP strategy. Given the findings with PAA, we incline toward explored different avenues regarding the SAX calculation to symbolize the power load profiling (dynamic examinations) and to assess the equal separation measure by TLB values. We utilized genuine cases to exhibit this utilization of the related techniques. Later on, we try to limit the RMSE results forecast by refining the method received in this work and apply bunching way to deal with separate typical, strange electric examples—that is, to electronic gathering designs for further expository and expectation assignments. Likewise, we will finish every one of the modules referenced in the system and lead the slip by of analyses to affirm the adequacy of the proposed structure and methodologies exhaustively. The objective of our examination is to help the co-working modern plant to settle on vitality streamlining choices, continuous bases.
REFERENCES
1. G. O. Young, “Synthetic structure of industrial plastics (Book style with paper title and editor),” in Plastics, 2nd ed. vol. 3, J. Peters, Ed. New York: McGraw-Hill, 1964, pp. 15–64.
2. W.-K. Chen, Linear Networks and Systems (Book style). Belmont, CA: Wadsworth, 1993, pp. 123–135.
3. H. Poor, An Introduction to Signal Detection and Estimation. New York: Springer-Verlag, 1985, ch. 4.
4. B. Smith, “An approach to graphs of linear forms (Unpublished work style),” unpublished.
5. E. H. Miller, “A note on reflector arrays (Periodical style—Accepted for publication),” IEEE Trans. Antennas Propagat., to be published. 6. J. Wang, “Fundamentals of erbium-doped fiber amplifiers arrays
(Periodical style—Submitted for publication),” IEEE J. Quantum Electron., submitted for publication.
7. C. J. Kaufman, Rocky Mountain Research Lab., Boulder, CO, private communication, May 1995.
8. Y. Yorozu, M. Hirano, K. Oka, and Y. Tagawa, “Electron spectroscopy studies on magneto-optical media and plastic substrate interfaces (Translation Journals style),” IEEE Transl. J. Magn.Jpn., vol. 2, Aug. 1987, pp. 740–741 [Dig. 9th Annu. Conf. Magnetics Japan, 1982, p. 301].
9. M. Young, The Techincal Writers Handbook. Mill Valley, CA: University Science, 1989.
10. (Basic Book/Monograph Online Sources) J. K. Author. (year, month, day). Title (edition) [Type of medium]. Volume(issue). Available:
http://www.(URL)
11. J. Jones. (1991, May 10). Networks (2nd ed.) [Online]. Available:
http://www.atm.com
12. (Journal Online Sources style) K. Author. (year, month). Title. Journal [Type of medium]. Volume(issue), paging if given. Available:
http://www.(URL)
13. R. J. Vidmar. (1992, August). On the use of atmospheric plasmas as electromagnetic reflectors. IEEE Trans. Plasma Sci. [Online]. 21(3). pp.
876—880. Available:
http://www.halcyon.com/pub/journals/21ps03-vidmar
AUTHORSPROFILE
Ravinder N, M.tech, Assit.Professor in the department of computer science engineering at KLEF, working in the area of knowledge engineering research group, guided this project.
Smruthi.D, student from computer science engineering branch (2015-19) KLEF, worked in knowledge engineering research group.
Sivaji Pasupuletistudent from computer science engineering branch (2015-19) KLEF, worked in knowledge engineering research group.