Exploring Textual Similarities InUser-Generated
Content Across Multiple Online Social Networks:
A Text Mining Approach
Deepesh Kumar Srivastava, Basav Roychoudhury
Abstract: In the era of social media, User-generated content (UGC) alludes to anydigital content that is generated or shared byusers of online social networks (OSNs).With the help of natural language processing and text mining techniques, this study explores the textual similarities exist in user-generated contents on OSNs. For this study, publically available profile’s posts were collected from a total of 226 identical user’s pairs from Facebook and Twitter.Based on experiments with ground truth Facebook-Twitter real datasets, the findings show that there exist textual similarities in user-generated contain like the use of words and types of word’s associations.The results of this study provide certain theoretical and practical implications for data mining researchers and social media analysts.
Keywords: Data mining,natural language processing, online social networks, text mining, user-generated content.
I. INTRODUCTION
In the most recent decade, various popular online social networks (OSNs) have developed, and the number of monthly dynamicusers has also increased. These OSNs have changed how we interact with one another and make it less difficult to remain associated with companions.Different OSNs employ various means to engage individuals and satisfy their consumers' requirements [11]. For instance, individuals use Facebook to form a network of their connections, LinkedIn for extending their professional relations and networks, and Twitter to share information. These networks capture information about individuals' online activities wherein the individuals chat, talk, and respond on a plethora of subjects and issues [5].
On these OSNs of interest, an individual registers her/his online identity, which includes a set of attributes that describe her/him distinctively within the given network, distinct from the other users. Such online identity comprises the user‟s profile information like name, location, gender, etc., user‟s network information containing the links to people s/he is connected to, and user-generated content.User-generated content (UGC) is any form of content, such as text, video, chat,blogs,posts, digital images, and other forms of media, that have been posted by individuals on social network platforms. For example, an
Revised Manuscript Received on June 05, 2019
Deepesh Kumar Srivastava, Department of Information Systems, Indian Institute of Management, Shillong, India.
Basav Roychoudhury, Department of Information Systems, Indian Institute of Management, Shillong, India.
individual who capturesa photograph and posting it on her/hisFacebook profile, and tagging a brand or using a hashtag is creating user-generated content.UGCs are utilized for an extensive range of applications, including problem handling, news, publicity, entertainment, research, and gossip. The distribution of UGCs across the web-based networks offers a gigantic wellspring of rich psychological information, with enormous potential if appropriately complied, and alsouseful in improving the involvements of end users. Social science research can benefit from having access to the opinions of a population of users, and utilize this information to generate inferences about their characteristics. Applications in information technology try to mine end user information to help and improve machine-based procedures, for example, information retrieval and various types ofrecommendation systems.
There has been a lot of interest amongst the research community as well as the industry on the potential benefits of user‟s online information. However, most of the studies and research are focused mainly on profile attributes information (username, name, education, location, etc.) of users, and most overlook the content information. This being the motivation, the current study explores the textual similarities and patterns exist between content information of a user‟s profiles from Facebook and Twitter and presents a methodology wherein extracted words and their associations with other words in user-generated content are successfully used to find the similarities amongst the profiles. The paper thus contributes to the existing literature by introducing the use of natural language processing and text mining techniques to explore the similar patterns exist in user-generated content between profiles from two popular social networks.
The rest of this paper is organized as follows: related work from the literature is presented in section 2, while the description of the datasets is explained in section 3. Section 4 elucidates the methodology and the proposed algorithm. Results are discussed in section 5, while section 6 concludes the paper.
II. LITERATURE REVIEW
An expanding segment of information on the web is becoming user-generated. It is considered as a publicspot to seek user-generated data on any subject of enthusiasm on the Internet, which is progressively turning into the repository for global information[12].The content generated by online users is a type of published digital content that is “generated or shared outside of professional schedules and procedures." This kind of contents may be independently or jointlygenerated, shared,adapted and consumed, and “can be realized as the addition of allhow individuals make use of OSNs,” [4].
Previous studies showed that OSNs are used asa self-presentation platform by individuals and information generated by these practices is a significant part of UGCs [7,8].Few studiesdescribe Twitter as a social network that is used for posting of individuals‟everydayevents[8]. Other studies showed that the transient nature and culture of websitesadditionally drivesindividuals topromotediscussion rather than self-presentation [6]. Facebook allows the practices of self-presentation throughindividuals‟ profiles and user-generated content.
This study focuses on content generated by online users from the two most popular OSNs: Twitter and Facebook. Facebook is anOSN that was established in2004. Users of Facebook can form profiles by providing personal information, photos, interests, and also can create a network of friends[11]. Each user on Facebook can also take part in various types of activities such as commenting on links, writing on friends‟ walls, etc. [5] Facebook permitsindividuals to construct or sustain social capital, interconnect with others via text and messages and find outgossip and rumours.Twitter is a micro-blogging site that was established in 2006. It permitsindividuals to write a tweet and retweets to express their opinions and views which cannot exceed more than 140-characters in length. Tweets usually contain shared information, opinions, news, complaints, or information about everyday events.These user-generated posts, tweets, and retweets are publically available, and many researchers are using for predictive modelling[1,13]. Use of text analytics and natural language processing is gaining popularity as a technique to rapidly transform the critical content in text documents into quantitative, actionable insights [3,9]. Word cloud analysis provides useful information about a corpus [10].Word clouds are graphical representations of word‟sfrequency that give greater prominence to wordsthat appear more frequently in a corpus.The analysis of word association provides useful information about the relationship between terms in a corpus[2]. The aim of finding the word association is to calculatethe resemblance of candidate words in a context document.These techniques can play a significant role in exploring the textual similarity in UGCs.
As this literature depicts, Users of Facebook and Twitter generate different types of contents due to the diverse nature and structure of these OSNs. However, still, it is difficult to find out whether there is any textual similarities or patterns exist in UGCs from these two OSNs. With the help of text mining techniques, this study presents a methodology to capture the textual similarities exist in UGCs.
III. DATASET
In the existing literature, datasets that can be used for investigation of user-generated content amongst unstructured OSNs are limited. Thus to evaluate our proposed method, we collected datasets that consist of users from two OSNs (Twitter and Facebook) with content information. The reason behind collecting the datasets from these two OSNs is their popularity and their catering to a large number of users. All profiles declared as non-English were ignored. The most challenging segment of data collection was to collect coupled profiles or true positive connections between OSNs that belongs to the same individual in real-world.Publically available profile‟s content attributes were extracted using Twitter API and Facebook Graph API during October and December 2018.This dataset consists of a total of 226 profile sets with known profiles that belongs to the same individual (true positive connections) in real-world from two OSNs.
IV. METHODOLOGY
The objective of this proposed method is to find the textual similarities betweencontent information of a user‟s profiles„X' from Facebook and Twitter, assuming that the user „X' has accounts in both the OSNs. Towards this, the method uses words and their correlation with every other word found in the content attributes of the user's profiles (X).
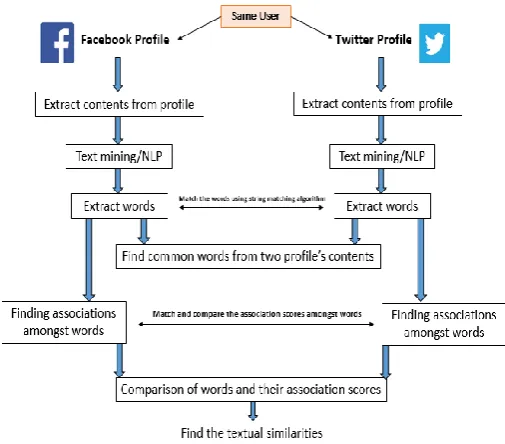
Figure 1 and algorithm illustrate the steps required to find out the textual similarities between content informationof an individual‟s profiles from Facebook and Twitter.
[image:2.595.305.558.438.660.2]Algorithm.Comparison of words and their association scores from user‟s content
Input:(a) Profile of user (𝑋) collected from Twitter (b) Profile of user (𝑋) collected from Facebook Output: Similar words and their association scores 1. Select user X‟s profile from Twitter(𝑃𝑇𝑤𝑖𝑡𝑡𝑒𝑟 ,𝑋)
2. Collect user X‟s content attributes, i.e., the
tweets/retweets from Twitter using the available API
𝐶𝑋(𝑇𝑤𝑖𝑡𝑡𝑒𝑟 ) ← 𝑇𝑤𝑖𝑡𝑡𝑒𝑟_𝐴𝑃𝐼 (𝑃𝑇𝑤𝑖𝑡𝑡𝑒𝑟 ,𝑋)
3. Select user X‟s profile from Facebook(𝑃𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 ,𝑋)
4. Collect user X‟s content attributes, i.e., the posts from Facebook using the available API
𝐶𝑋(𝐹𝑎𝑐𝑒𝑏𝑜 𝑜𝑘 ) ← 𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘_𝐴𝑃𝐼 (𝑃𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 ,𝑋)
5. Create the word cloud for user X‟s Twitter content attributes 𝐶𝑋 𝑇𝑤𝑖𝑡𝑡𝑒𝑟
𝑊𝑋(𝑇𝑤𝑖𝑡𝑡𝑒𝑟 )← 𝑤𝑜𝑟𝑑_𝑐𝑙𝑜𝑢𝑑 (𝐶𝑋 𝑇𝑤𝑖𝑡𝑡𝑒𝑟 )
6. Extract words from word cloud (𝑊𝑋(𝑇𝑤𝑖𝑡𝑡𝑒𝑟 )) of user
X‟s Twitter content 𝐶𝑋 𝑇𝑤𝑖𝑡𝑡𝑒𝑟
𝑊𝑜𝑟𝑑𝑠(𝑇𝑤𝑖𝑡𝑡𝑒𝑟 )← 𝑒𝑥𝑡𝑟𝑎𝑐𝑡_𝑤𝑜𝑟𝑑𝑠(𝑊𝑋 𝑇𝑤𝑖𝑡𝑡𝑒𝑟 )
7. Find the associations amongst words𝑊𝑜𝑟𝑑𝑠(𝑇𝑤𝑖𝑡𝑡𝑒𝑟 )
𝐴𝑠𝑠𝑜𝑐𝑖𝑎𝑡𝑖𝑜𝑛𝑠(𝑇𝑤𝑖𝑡𝑡𝑒𝑟 )← 𝑎𝑠𝑠𝑜𝑐𝑖𝑎𝑡𝑒_𝑤𝑜𝑟𝑑𝑠(𝑊𝑜𝑟𝑑𝑠 𝑇𝑤𝑖𝑡𝑡𝑒𝑟 )
8. Create the word cloud for user X‟s Facebook content attributes 𝐶𝑋 𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘
𝑊𝑋(𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 )← 𝑤𝑜𝑟𝑑_𝑐𝑙𝑜𝑢𝑑 (𝐶𝑋 𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 )
9. Extract words from word cloud(𝑊𝑋(𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 )) of user X‟s Facebook content(𝐶𝑋(𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 ))
𝑊𝑜𝑟𝑑𝑠(𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 )← 𝑒𝑥𝑡𝑟𝑎𝑐𝑡_𝑤𝑜𝑟𝑑𝑠(𝑊𝑋 𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 )
10. Find the associations amongst words𝑊𝑜𝑟𝑑𝑠(𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 )
𝐴𝑠𝑠𝑜𝑐𝑖𝑎𝑡𝑖𝑜𝑛𝑠(𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 )← 𝑎𝑠𝑠𝑜𝑐𝑖𝑎𝑡𝑒_𝑤𝑜𝑟𝑑𝑠(𝑊𝑜𝑟𝑑𝑠 𝐹𝑎𝑐𝑒𝑏𝑜𝑜𝑘 )
11. Compare the words between Twitter and Facebook profiles
12. Compare the pattern of word‟s association between Twitter and Facebook profiles
13.return (𝑠𝑖𝑚𝑖𝑙𝑎𝑟 𝑤𝑜𝑟𝑑𝑠, 𝑝𝑎𝑡𝑡𝑒𝑟𝑛 𝑜𝑓 𝑤𝑜𝑟𝑑′𝑠 𝑎𝑠𝑠𝑜𝑐𝑖𝑎𝑡𝑖𝑜𝑛) 14.End
[image:3.595.311.545.181.393.2]We select a user who has accounts in both the OSNs. Userprofile‟s content information is extracted using Twitter and Facebook Graph API. We used R programming for all pre-processing, natural language processing, and text mining tasks. After pre-processing (ignoring whitespaces, stop words, numbers, punctuations, etc.) of content attributes, we develop a word cloud by using word cloud ( ) function („wordcloud‟ package in R) to identify thecommon words in user‟s profiles from Twitter and Facebook. The words in the cloud are shown by their significance score utilizing different text dimensions, colours schemes, etc. Figure 2 shows the word cloud for the profile's content information of the same individual from Facebook and Twitter.
Figure 2.Wordcloud for profile's content information of the same individual
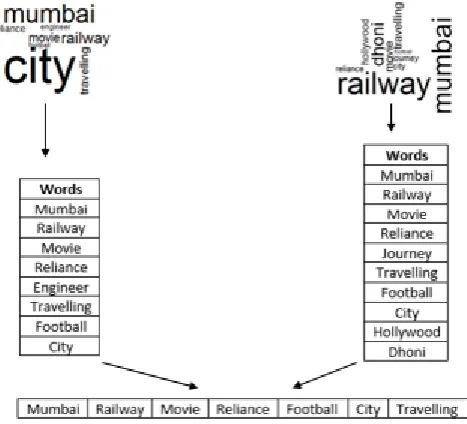
We match eachfrequent words collected from the user‟s content from Facebook and Twitter and find out the common frequent words shared between them by using Jaro-Winkler algorithm in stringdist ( ) function („stringdist‟ package in R). The Jaro–Winkler distance is a string metric forcomputation ofedit distance between two strings where the score is normalized such that 1 indicates to no resemblance and 0 is an exact match [14]. Figure 3 depicts the process of extraction and matching common frequent words.
. Figure 3. Process of extraction and matching the common frequent words
Figure 4. Process of finding the word association.
V. RESULTS AND DISCUSSION
[image:4.595.70.278.48.305.2]With the help of natural language processing and text mining techniques, we explored the textual similarities exist in user‟s generated contents on OSNs. We randomly select 226 users who have both Twitter and Facebook accounts. Figure 5 shows that set of same individual‟s profiles from two OSNs use certain number of similar words in their content and the words‟ association scores are comparable between the similar user‟s profile from Facebook and Twitter OSNs.
Figure 5. Number of similar words and their relative word‟s association scores between similar users‟ profile sets from
[image:4.595.333.519.137.336.2]Facebook and Twitter
Figure 6 shows that set of different individuals‟ profile sets from two OSNs use almost negligible number of similar words in their contents.
Figure 6. Number of similar words and their relative word‟s association scores between different users‟ profile sets from
Facebook and Twitter
The result of this study showed that there exist textual similarities in UGCs across multiple OSNs either in terms of words or pattern of association amongst words.
VI. CONCLUSION AND FUTURE WORK In this paper, we have studied the textual similarities and patterns that exist in user-generated contents across online social networks. As an essential and integral fragment of the social network, the UGCs shared by the similar individual
across social networksgenerallycomprise rich
redundanciesin the information. Weproposed a methodology to measure the textual similarity in user-generated contents on content dimensions. Then we tested our method onFacebook-Twitter ground truth profile datasets. The experiment results show that there is certain textual similarity exist in user‟s content across multiple OSNs. In the future, we will incorporate other OSNs to find the similarities and patterns that exist in user's profiles, and to introduce more sophisticated techniques to measure similarities in user‟s profiles across OSNs. The proposed methodology will also be helpful in identity resolution of online users across multiple OSNs.
REFERENCES
1. Abdelsadek, Y., Chelghoum, K., Herrmann, F., Kacem, I., &Otjacques, B. (2018). Community extraction and visualization in social networks applied to Twitter. Information Sciences, 424, 204-223.
2. Cao, Q., Duan, W., &Gan, Q. (2011). Exploring determinants of voting for the “helpfulness” of
[image:4.595.76.280.473.791.2]3. Gerber, M. S. (2014). Predicting crime using Twitter and kernel density estimation. Decision Support Systems, 61, 115-125. 4. Kaplan, A. M., &Haenlein, M. (2010). Users of the world, unite!
The challenges and opportunities of Social Media. Business horizons, 53(1), 59-68.
5. Kaur, W., Balakrishnan, V., Rana, O., &Sinniah, A. (2018). Liking, Sharing, Commenting and Reacting on Facebook: User behaviors‟ impact on Sentiment Intensity. Telematics and Informatics. 6. Kietzmann, J. H., Hermkens, K., McCarthy, I. P., & Silvestre, B. S.
(2011). Social media? Get serious! Understanding the functional building blocks of social media. Business horizons, 54(3), 241-251. 7. Lange, P. G. (2007). Publicly private and privately public: Social
networking on YouTube. Journal of computer-mediated communication, 13(1), 361-380.
8. Marwick, A. E., & Boyd, D. (2011). I tweet honestly, I tweet passionately: Twitter users, context collapse, and the imagined audience. New media & society, 13(1), 114-133.
9. Müller, O., Junglas, I., Debortoli, S., &vomBrocke, J. (2016). Using text analytics to derive customer service management benefits from unstructured data. MIS Quarterly Executive, 15(4), 243-258. 10. Pröllochs, N., Feuerriegel, S., & Neumann, D. (2016). Negation
scope detection in sentiment analysis: Decision support for news-driven trading. Decision Support Systems, 88, 67-75.
11. Shen, K., &Khalifa, M. (2010). A research framework on social networking sites usage: Critical review and theoretical extension. Software Services for e-World, 173-181.
12. Smith, A. N., Fischer, E., &Yongjian, C. (2012). How does brand-related user-generated content differ across YouTube, Facebook, and Twitter?.Journal of interactive marketing, 26(2), 102-113.
13. Xu, K., Zheng, X., Cai, Y., Min, H., Gao, Z., Zhu, B., .& Wong, T. L. (2018). Improving user recommendation by extracting social topics and interest topics of users in uni-directional social networks. Knowledge-Based Systems, 140, 120-133.
14. Winkler, W. E. (2005). Approximate string comparator search strategies for very large administrative lists. Statistics, 2.
AUTHORS PROFILE
Deepesh Kumar Srivastava is a Research Scholar at Indian Institute of Management Shillong, India. His research focuses on data science, machine learning and social media analysis based on his academic background of computer science and management information systems.