Abstract: Speech Recognition of native language is the process of recognizing the language of a client dependent on the speech or content writing in another language. This article proposes the utilization of spectrogram as well as on cochleagram-oriented concepts separated from extremely short speech expressions (0.8 s by and large) to deduce the local language of the speaking person. The bidirectional long short-term memory (BLSTM) neural systems are received to classify the expressions between the local dialects. A lot of analyses is completed for the system engineering look and the framework's precision is assessed on the approval informational index. By and large precision is accomplished utilizing the Mel-recurrence Cepstral coefficients (MRCC) and Gammatone Recurrence Cepstral Coefficients (GRCC), separately. In addition, the advanced MFCC oriented BLSTM system and GFCC based BLSTM systems are combined to make use of their features. The examinations demonstrate that the execution of the combined system outperforms the individual BLSTM systems and precision of 75.69% is accomplished on the assessment information.
Keywords: Native language identification, bidirectional-long and short-term storage, Melrecurrencecepstral-coefficients.
I. INTRODUCTION
S
peech Recognition of native language is the undertaking and distinguishing the client dependent on their discourse or written content in a Targeted language. Local language detection at discourse information moderately novel section to do research restricted on the issue. For literary information of NLI, nonetheless, various methodologies have been investigated utilizing lexical and auxiliary highlights, for example, character, word, grammatical form, reliance relations. Typically, multilingual speakers need careful, bringing about normal ancient rarities, for example, certain articulation contrasts and particular remote accents [4]. Exact location of local language are valuable for various human-machine voice interface functions, for example, PC helped language learning (CALL) framework, robotized discourse evaluation framework, speaker crime scene investigation and adjustment in mechanized discourse acknowledgment (ASR) frameworks.NLI can likewise encourage a verbally expressed discourse
Revised Manuscript Received on December 05, 2019. * Correspondence Author
Kadam Sarika Shamrao*, Research Scholar, Department of Computer Applications, BIHER - Bharath Institute of Higher Education and Research, Chennai, India.
A Muthukumaravel, Dean, Arts & Science, BIHER - Bharath Institute of Higher Education and Research, Chennai, India.
framework by proposing a client's social foundation. Dominant part of the examination in the territory of Speech Recognition of language is centered around distinguishing the local language with the speakers practicing englishias a next language. Notwithstanding, distributed undertaking of 21th century reference supported enthusiasm for the zone by creating access to expansive amount of non-local English [7] for open use. This common errand was centered around language Speech Recognition utilizing literary data covering 11 local dialects. In NLI distributed errand of exact location of local language are valuable for various human-machine voice interface functions, for example, PC helped language learning framework, robotized discourse evaluation framework, speaker crime scene investigation and adjustment in mechanized discourse acknowledgment frameworks. In addition, Norwegian NLI is investigated by utilizing literary data of students of Norwegian language.
In content oriented language recognition, highlights broadly utilized. Oriented highlights utilized for removing data, while, grammatical feature labels and reliance are utilized for extricate data composed content. Highlights displays utilizing distinctive of an author. Grammatical feature labels for language recognition. SVM is utilized to classify L1 dialects. Projected method is assessed on mass of non-local English [7] and more precisions accomplished. This framework best executed in 2013 language Speech Recognition distributed assignment. The suggested strategy is assessed on TOFEL11 body [7] and greatest precision is accomplished. Bin Liu and Jianhua Tao [9] utilized classifier loading method for example sentence stage classification forecast are utilized in record stage classification. Calculated relapse demonstrate prepared on elaborate, A neural system with a single concealed layer can estimate any capacity when prepared on a sufficient measure of information [6]. In any case, a broadly wide system may finish up retaining the relating yield esteem which isn't helpful for handy applications on the grounds that each info esteem may not be a piece of the preparation information. Various shrouded layers are good since they studies progressive, increasingly complicated inside portrayals. Hence, various analyses are directed to find out the ideal profundity for example number of shrouded layers.
Capacity when prepared on a sufficient measure of information [6]. In any case, a broadly wide system may finish up retaining the relating yield esteem which isn't helpful for handy applications on the
grounds that each info esteem may not be a piece of the
Native Language Recognition using
Bidirectional Long Short-Term Memory
Network
preparation information. Various shrouded layers are good since they studies progressive, increasingly complicated inside portrayals. Hence, various analyses are directed to find out the ideal profundity for example number of shrouded layers.
designs, which moderately dif clique to get for grown-ups. In writing, both segmental and supra-segmental highlights are investigated for language recognition. Mel-recurrence cepstral coefficients (MFCC), perceptual direct forecast (PLP) and Gamma-tone recurrence cepstral coefficients (GRCC) are generally utilized acoustic-oriented NLI highlights.
In an investigation by Chin-Hui Lee et al. [10], both otherworldly and source-oriented highlights are utilized to recognize A neural system with a single concealed layer can estimate any capacity when prepared on a sufficient measure of information [6]. In any case, a broadly wide system may finish up retaining the relating yield esteem which isn't helpful for handy applications on the grounds that each info esteem may not be a piece of the preparation information. Hence, various analyses are directed to find out the ideal profundity for example number of shrouded layers. In any case, a broadly wide system may finish up retaining the relating yield esteem which isn't helpful for handy applications on the grounds that each info esteem may not be a piece of the preparation information. Various shrouded layers are good since they studies progressive, increasingly complicated inside portrayals.
Speech Recognition local communication at discourse expression like speaking person, highlight vernacular Speech Recognition undertakings. Hence, comparative highlights procedures are utilized for these undertakings. Best in class identification frameworks depend on the abuse of acoustic [6] [8], phono-strategy [9], [10] and prosodic [1], [2] highlights. Acoustic element based methodologies investigates the sounds; phonotactic highlight oriented methodologies [10] use possible telephone mixes of every language to gather the language from a discourse expression; and prosodic component put together procedures center with respect to inflection designs. For discourse expression classification, Gaussian blend models with all inclusive foundation display (GMM-UBM) [3], joint factor investigation (JFA) [4] and I-vector [2] structure are generally utilized.
The examination demonstrated that for 3-second long expressions, LSTM out-played out the I-vector framework by up to 25%. What's more, the impact of the test articulation length is additionally investigated on the restricted span test information. The framework's exactness weakens information length diminishes a general precision accomplished at lengthy expressions. For the most part, a blend of vary different highlights or methodologies will in general give better exactness of the framework [8]. In an investigation by [9], notwithstanding DNNs, RNNs are likewise investigated for highlight Speech Recognition and a combination of DNNs and RNNs is tested. Combination of systems is assessed utilizing the NLSC body on test information with 45-second expressions. It is seen that a mix of systems executed improved when contrasted with individual systems.
This article is organized as per the following. Segment 2 discusses the information highlights of the NLI framework.
Segment 3 talks about the condition of-workmanship I-vector framework while yield esteem which isn't helpful for handy applications on the grounds that each info esteem may not be a piece of the preparation information. Various shrouded layers are good since they studies progressive, increasingly complicated inside portrayals. Hence, various analyses are directed to find out the ideal profundity for example number of shrouded layers. When prepared on a sufficient measure of information. In any case, a broadly wide system may finish up retaining the relating yield esteem which isn't helpful for handy applications.
II. FEATURES OF LANGUAGE RECOGNITION
Acoustic qualities of talk portions are utilized as commitment to the language affirmation structures. on this test, spectrogram-fundamentally based features for instance Mel rehash cepstral coefficients (MRCC) and cochleagram-based absolutely works for instance Gammatone rehash cepstral coefficients (GRCC) are utilized to address the acoustic attributes of convey. MRCC and GRCC highlights are completely utilized in selective talk taking care of uses for example changed convey certification (ASR) [5], boggling talk divulgence [6], speaker, language and close-by language recognizing verification, and numerous others. The imperative capability among spectrogram and cochleagram is that spectrogram highlights depend on Mel scale and cochlea-gram scale have very great focuses at low frequencies. instance stacked understanding of delta coefficients in additional of more than one edges. SDCs are utilized to improve the accuracy of speaker attestation, language confirmation and adjacent language divulgence frameworks. For cepstral work vector, SDC are overseen by utilizing interfacing k squares of delta coefficients as affirmed up in Equation 1.
SDC highlights are regularly composed as N-d-P-k where: N: quantity of cepstral coefficients in each edge
d: time advance and deferral for delta calculation P: time move among continuous casings
K: number of casings to be connected.
When prepared on a sufficient measure of information as shown in Equation 2.
Total channel remuneration existutilizing the Equation 3.
Gaussian appropriation coming about into comparable performance capacity or rate of rot. The factor b is defined as:
III. I VECTOR MODEL
Over one another subsequent in a deep neural network system. The input values of the
contribution from both in reverse and forward layers. Packs are frequently exceeded on to improve execution and openness over that of a lone laptop, even as commonly being altogether extra canny than unmarried desktops of proportional speed or availability. One of the difficulties inside the usage of a pc organization is the rate of administrating it which could sometimes be as excessive because the expense of administrating N unfastened machines, if the bunch has N language identification. Now and again this gives a favorable role to imparted memory fashions to convey down enterprise charges. This has likewise made virtual machines outstanding, due to the simplicity of corporation. . The starting value of accessible frames to be transfer data and basic of the specification requirements of the structure, and it should be organized once the structure is started. In command to compress the largest nodes of sending, the access method has to be allocated in a method that all the data items in the access are placed by the language identifies in the network structure reliving no presence for commands free time intervals. In pros, at the starting of the structure functions, the nodes of the access scheme should be given equally to the accessible and nodes to get smaller the nodes. After receiving the command nodes response, the sender notes the total interval pleased by each node in a processor slot that determines the access scheme. This processor slot controls the structure and defines the functions numbers of the access scheme.
(5)
Here H1 refers to the speculation that the I-vector has a place with a similar language and H0 signifies the theory that they don't.
Fig.1 LSTM cell
IV. TWO-DIRECTIONAL DUMB NEURAL SYSTEM
MODEL
LSTM create is a remarkable sort of dumb neural system (RNN) with the capacity of altering entire arrangement conditions. Each LSTM cell has information assets, yields and a way of activity of gating gadgets to show the records development. Interior kingdom unit (ct) is the significant thing bit of the cell phone that is facilitated by the multiplicative gadgets referred to as doors for instance input passage (it), yield gateway (ot) and brush aside portal (feet). A square outline of a LSTM cell is affirmed up in Fig. 1. circumstance 10 tends to the LSTM rectangular
measurements [7]. Conditions of LSTM inputs, yields, kingdom unit and passages are given in Equations 6, 7, eight and 9, freely, more subtleties of which may be showed up in [5].
(6)
(7)
(8)
(9)
(10)
(11) Where is the calculated sigmoid capacity, it , ot , f t , and ct are the information, yield, overlook entryway and cell inward, separately. So find all b inclination and R repetitive grids. xt-information grids, digression initiation work component insightful result.
Examination, system is utilized to used and setting of a voice signal. Bidirectional LSTM has two separate concealed layers switched duplicate of the succession.
Numerous over one another subsequent in a deep neural network system. The input values of the next layer is the output value of the previous layer, guaranteeing that the following layer gets contribution from both in reverse and forward layers.
Design of BLSTM organize appeared is utilized to create framework having input as FM. Thus, parameters NLI framework additionally created by utilizing include FG quantity of layers which is streamlined tentatively every framework. Likewise, a few tests are done to enhance number of concealed units and regularization strategies. Subtleties of these analyses are given in resulting segments.
A. QUANTITIES OF HIDDEN LAYERS
A neural system with a single concealed layer can estimate any capacity when prepared on a sufficient measure of information. In any case, a broadly wide system may finish up retaining the relating yield esteem which isn't helpful for handy applications on the grounds that each info esteem may not be a piece of the preparation information. Various shrouded layers are good since they studies progressive, increasingly complicated inside portrayals. Hence, various analyses are directed to find out the ideal profundity for example number of shrouded layers.
B. NON VISIBLE LAYERS SIZE
Quantity system dominates execution extensively Less produce under fitting producing high blunders on training and approval information. Then again, an expansive quantity over fitting blunders. Ideal quantities necessary limit impact under fitting and over fitting. Distinctive examinations have been done to and the different guidelines for the assurance of ideal quantity of units of the diverse system [7]. Network system. The input values of the next
that the following layer gets contribution from both in layers.
C. REGULARIZATION METHODS
Normalization strategies useful diminish show unpredictability limiting loads points, little qualities produces in soft theory methods. In this investigation, two normalization techniques are utilized: dropout [9] for example regularization connected include association all the unit at all the layer system. Distinctive mixes considered additionally utilizing matrix pursuit to find the ideal composition. Distinctive blends are attempted and show performance is assessed on approval information.
V. JOINED MODEL OF RNN
Assortment properties accessible various qualities, shortcomings. mixture a few distinct properties as a contribution to the single framework may result in progressively exact outcomes. Distinctive methodologies can be utilized to concatenate the highlights, (1) link of figured highlights from information discourse, (2) connection of organized highlights by applying diverse discourse handling and machine learning strategies on registered crude highlights. Wei Li and Chen [10] consolidated direct expectation create collective highlights decreased mistake considerably. Additionally, an examination by Zhijie et al. [1] demonstrated connected highlights executes improved when contrasted with CNN with the list of capabilities. Roy et al. [2] utilized a mix of contrast different highlights, straight recurrence for speech acknowledgment seen joined capabilities produces lower rise to mistake rate (EER). These examinations demonstrate the blend of capabilities executes improved. What’s more, mix of prepared list of capabilities (with the assistance of AI calculation) improves framework execution significantly when contrasted with the framework having consolidated list of capabilities straightforwardly. Consequently, in this examination a NLI framework is additionally created in which include sets are processing .
This design has two autonomous last yield successions for example hM and hG, subsequently dropping the transient measurement (for example changing over the info arrangement into a solitary vector). These two vectors are connected utilizing the recipe given here:
(12)
HF’s list of capabilities having linked hM and hG, for example
Esteem may not be a piece of the preparation information. Various shrouded layers are good since they studies progressive, increasingly complicated inside portrayals. Hence, various analyses are directed to find out the ideal profundity for example number of shrouded layers.
Like the enhancement of autonomous BLSTM networks, quantities of examinations are done to identify the ideal quantity of completely associated layers for example N and layers size for combined BLSTM RNN model.
VI. RESULTS AND DISCUSSION
[image:4.595.305.549.142.310.2]Various trials are completed iIvector demonstrate, display utilizing approval information is determined. Furthermore, arrange design look is likewise implemented for consolidated BLSTM networks. Subtleties of investigations are present in resulting segments.
Fig.2 Statics Potential speech recognition
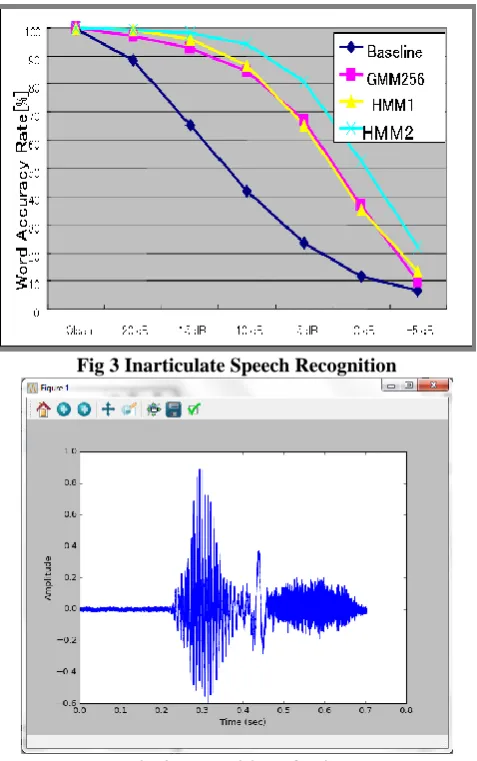
[image:4.595.308.547.335.716.2]Fig 3 Inarticulate Speech Recognition
VII. CONCLUSION
This article explored utilizing picture and cochlea-gram properties for local language notoriety from brief talk articulations (zero.8s by means of and enormous) for Urdu (L2) sound framework. BLSTM models ar grasped to address this flighty trouble of language acknowledgment for unnatural time span talk insights. A few arrangements of BLSTM styles are examined and looked at. This examination exhibits that MRCC features are extra ground-breaking than GRCC features for talk information recorded in various real innovation matters, with totally remarkable fine mobile phones and framework chiefs. Results of BLSTM show ar differentiated and attractive at school I-vector model and it's noticeable that BLSTM show executes shrewd once diverged from the I-vector show. BLSTM models arranged using MRCC and GRCC features are what's more blended to utilize the abilities. We tend to establish that the blending models approach beats each model. Later on, it will be profitable to investigate discourse houses to broaden the execution of the system. Several degree type are consistently gained to at first set up together dialects into family social affairs what's more as thereafter produce top of the line grained among them.
REFERENCES
1. ShaofeiXue ; Zhijie Yan, "Improving latency-controlled BLSTM acoustic models for online speech recognition",2017.
2. Youssouf Chherawala ; ParthaPratim Roy ; Mohamed Chenet, "Context-dependent blstm models. Application to offline handwriting recognition", 2014.
3. YishuangNing ; Zhiyong Wu ; Runnan Li ; JiaJia ; Mingxing Xu ; Helen Meng ; LianhongCai,"Learning cross-lingual knowledge with multilingual BLSTM for emphasis detection with limited training data", 2017.
4. Maximilian Strake ; Pascal Behr ; TimoLohrenz ; Tim Fingscheidt," Densenet Blstm for Acoustic Modeling in Robust ASR", 2018. 5. ZhiyingHuang ; ShaofeiXue ; Zhijie Yan ; Lirong Dai, "Unsupervised
speaker adaptation of BLSTM-RNN for LVCSR based on speaker code",2016.
6. ZhiyingHuang ; Jian Tang ; ShaofeiXue ; Lirong Dai, "Speaker adaptation OF RNN-BLSTM for speech Speech Recognition based on speaker code", 2016.
7. Martin Karáfidt ; Murali Karthick Baskar ; Karel Veselý ; František Grézl ; Lukáš Burget ; Jan Černocký, "Analysis of Multilingual Blstm Acoustic Model on Low and High Resource Languages",2018.
8. FazaThirafi ; DessiPuji Lestari," Hybrid HMM-BLSTM-Based Acoustic Modeling for Automatic Speech Speech Recognition on Quran Recitation", 2018.
9. Bin Liu ; Jianhua Tao ; Dawei Zhang ; Yibin Zheng, "A novel pitch extraction based on jointly trained deep BLSTM Recurrent Neural Networks with bottleneck features", 2017.