AFIPS
CONFERENCE
PROCEEDINGS
VOLUME 40
1972
SPRING JOINT
COMPUTER
CONFERENCE
May
16 - 18, 1972
The ideas and opinions expressed herein are solely those of the authors and are not necessarily representative of or endorsed by the 1972 Spring Joint Computer Con-ference Committee or the American Federation of Information Processing Societies, Inc.
Library of Congress Catalog Card Number 55-44701 AFIPS PRESS
210 Summit Avenue Montvale, New Jersey 07645
@1972 by the American Federation of Information Processing Societies, Inc., Montvale, New Jersey 07645. All rights reserved. This book, or parts thereof, may not be reproduced in any form without permission of the publisher.
CONTENTS
IMPLEMENTATION OF PROGRAMMING LANGUAGE PROCESSORS
An appraisal of compiler technology ... . A laboratory for the study of automating programming ... .
Segmentation and optimization of . programs from cyclic structure analysis ... .
FRONTIERS OF LARGE-SCALE SCIENTIFIC COMPUTATION
The interplay of computer science and large-scale scientific calculation. Computer architecture and very large problems ... ; ... . Scientific applications of computers in the 70's ... .
THE COMPUTER AS SUPERTOY-PANEL SESSION
(No papers in this volume)
TRAINING COMMERCIAL PROGRAMMERS AND SYSTEMS ANALYSTS
The functions and elements of a training system ... . Planning data processing education to meet job requirements ... . Modular training-A new emphasis ... . Training techniques today-Tomorrow ... .
SOFTWARE DESIGN FOR THE MINI-COMPUTER
The future of mini-computer programming ... .
The current state of mini-computer software ... . Real-time fault detection for small computers ... .
TECHNIQUES FOR DEVELOPING LARGE PROGRAMMING SYSTEMS
An organization for successful project management ... . Commercial data processing machines in government applications .. . Programming language efficiency in real-time software systems ... .
MATHEMATICAL OPTIMIZATION THEORY AND ALGORITHMS
A review of recursive filtering algorithms ... . On computational methods for dynamic and static optimization .... . Piecewise linear approximations of fewest line segments ... . Experimental results on a new computer method for generating opti-mal policy variables in (s,S) inventory control problem ... .
NEW THEORETICAL FRONTIERS OF COMPUTER SCIENCE
Bounds on multiprocessing anomalies and packing algorithms ... . Computation of recursive programs-Theory vs practice ... . Mathematical concepts in programming language semantics ... . Applications of language theory to compiler design ... .
1
11
23
37 45 51
53 59 69 77
103
111 119
129 141 155
163 181 187
199
205 219 225 235
R. M. McClure T. E. Cheatham, Jr.
B. Wegbreit
J. Baer R. Caughey
K. K. Curtis R. B. Lazarus M. S. Lynn
B. Jones J. O. Hammond R. W. Kleffman G. A. Smith
D. Waks
A. B. Kronenberg J.' Ossanna J. R. Allen S. S. Yau
D. Smith J. D. Aron R. E. Merwin
J. O. Henriksen
B. Friedland D. H. Jacobsen D. G. Wilson
P. E. Valisalo B. D. Sivazlian J. F. Maillot
THE ARPA NETWORK
The terminal IMP for the ARPA computer network ... .
Computer communication network design-Experience with theory and practice ... .
Function-oriented protocols for the ARPA computer network ... .
McROSS-A multi-computer programming system ... .
Extension of packet communication technology to a hand-held per-sonal terminal ... .
PROGRAMMING LANGUAGES FOR SPECIALIZED APPLICATION AREAS
An overview of programming languages for special application areas .. . The future of specialized languages ... .
AMBUSH-A case history in language design ... , .. ;. The data-text system-An application language for the social sciences ... , ... , ... .
NEW TRENDS IN THE ARCHITECTURE OF COMPUTER SYSTEMS
LSI-Implications for future design and architecture ... .
The rationale for logic from semiconductor memory ... . SYMBOL hardware debugging facilities ... . The Rice Research Computer-A tagged architecture ... .
COMPUTERS IN INSTRUCTION-SOME CONSIDERATIONS
A generative CAl tutor for computer science concepts ... . Preliminary thoughts about a UNIversal TEAching Machine ... .
Mainline CAl, necessary but not oppressive ... . Should the computer teach the student or vice versa? ... .
OPERATING SYSTEM DESIGN CONCEPTS
Performance evaluation-A structured approach ... . Protection-Principles and practice ... .
PRIME-An architecture for terminal oriented systems ... .
243
255
271
281
295
299 313
321
333
343
353 359 369
379 391
399 407
411 417
431
S. M. Ornstein F. E. Heart W. R. Crowther H. K. Rising S. B. Russell A. Michel
H. Frank R. E. Kahn L. Kleinrock S. D. Crocker J. Heafner J. Metcalfe J. Postel R. H. Thomas D. A. Henderson, Jr.
L. G. Roberts
J. E. Sammet F. B. Thompson B. H. Dostert S. Warshall
D. J. Armor
S. F. Dennis M. G. Smith W. H. Davidow M. A. Calhoun E. A. Feustel
E. Koffman J. K. Clema R. L. Didday M. Wessler C. V. Bunderson A. W. Luehrmann
S. Kimbleton G. S. Graham P. J. Denning H. B. Baskin
GRAPHIC TERMINALS-PRESENT AND NEXT STATES
Computer graphics terminals-A backward look ... . The future of computer graphics ... .
A versatile computer-driven display system for the classroom ... . GOLD-A graphical on-line design system ... .
FORMAL ANALYSIS OF ALGORITHMS
Establishing lower bounds on algorithms-A survey ... . Analysis of combinatory algorithms-A sampler of current methodology ... . On the complexity of proving and disproving functions ... . On the structure of Blum measure ... .
THE COMPUTER IN GOVERNMENT-A TOOL FOR CHANGE
Management information systems, public policy, and social change ... . Geographic information systems in the U.S.-An overview ... .
UNIMATCH-A computer system for generalized record linkage under conditions of uncertainty ... . New directions in legal information processing ... .
HOMLIST-A computerized real estate information retrieval system ... .
Organization of a natural resources data bank system for government and research ... . The command terminal-A computerized law enforcement tool. .... .
INTERACTIVE SYSTEMS
Experience gained in the development and use of TSS/360 ... . Multics-The first seven years ... .
Organization and features of the Michigan terminal system ... .
DATA COMMUNICATIONS-THE PAST FIVE YEARS AND THE NEXT TEN YEARS
Data communications-The past five years ... . Data communications in 1980-A capital market view ... .
Allocation of copies of a file in an information network ... .
MANPOWER FOR COMPUTERS-HEYDAY OR CUTBACK
Production and utilization of computer manpower in U.S. higher education ... . Sources of trained computer personnel-A quantitative survey ... .
Employment of trained computer personnel-A quantitative survey ...
Sociological analysis of public attitudes toward computers and information files ... .
439 447
453 461
471
483 493 503
507
511
523 531
541
545 553
559 571
585
593 611
617
627 633
641
649
C. Machover R. H. Stotz T. G. Hagan J. W. Will hide L. J. French A. H. Teger
E. Reingold
W. D. Frazer A. N. C. Kang T. S. Chow
A. Gottlieb R. Amsterdam E. Andersen H. Lipton
M. Jaro R. T. Chien P. B. Maggs F. A. Stahl
D. J. Simon B. L. Bateman
A. J. Surkan D. M. Hudak
R. E. Schwemm F. J. Corbat6 C. T. Clingen J. H. Saltzer M. T. Alexander
P. Walker R. E. LaBlanc W. E. Himsworth R. G. Casey
J. W. Hamblen B. Gilchrist R. E. Weber B. Gilchrist R. E. Weber
MICROPROGRAMMING ENTERS A NEW ERA
Microprogrammed significance arithmetic-A perspective and feasi-bility study ... . Architectural considerations of a signal processor under microprogram control ... . A building block approach to multiprocessing ... .
The interpreter-A microprogrammable building block system ... .
PERFORMANCE PREDICTION-MODELING AND MEASUREMENT
Modeling, measurement and computer power ... .
Experiments in page activity determination ... . Validation of a trace-driven CDC 6400 simulation ... .
Instrumentation for the evaluation of a time-sharing, page demand system ... .
LSI PERSPECTIVES-ARCHITECTURE AND COST OF SMALL COMPUTERS
LSI and minicomputer system architecture-Implications for multi-processor systems ... . Approaching the minicomputer on a silicon chip-Progress and expectations for LSI circuits ... . The external access network of a modular computer system ... .
COMPUTER SIMULATION AS A DECISION MAKER'S TOOL
An over-the-shoulder look at discrete simulation languages ... . A specialized language for simulating computer systems ... .
Discrete computer simulation-Technology and applications-The next ten years ... .
THE DILEMMA OF INSTALLATION MANAGEMENT
The emergence of the computer utility ... .
Installation management-The next ten years ... .
PROGRAM DOCUMENTATION-PANEL SESSION
(No papers in this volume)
THE ROLE AND SCOPE OF COMPUTER SYSTEMS DESIGN RESEARCH IN A UNIVERSITY SETTING-PANEL SESSION
(No papers in this volume)
659
675 685
705
725
739 749
759
767
775 783
791 799
815
827
833
C. V. Ramamoorthy M. Tsuchiya
Y.S. Wu R. L. Davis S. Zucker C. M. Campbell E. W. Reigel U. Faber D. Fisher
G. Estrin R. R. Muntz R. Uzgalis J. G. Williams J. D. Noe G. J. Nutt
J. Rodriguez- Rosell J. Dupuy
L. Seligman
H. G. Rudenberg J. T. Quatse P. Gaulene D. Dodge
1. M. Kay P. B. Dewan C. E. Donaghey J. B. Wyatt
J. N. Maguire
AN EVALUATION OF THE STATE OF COMPUTER SCIENCE EDUCATION
A set of goals and approaches for education in computer science ... . Computer science education-The need for interaction ... . Operating systems principles and undergraduate computer science curricula ... . Theory of computing in computer science education ... .
SCIENTIFIC COMPUTATION-THE SOCIAL SCIENCES
Social science computing-1967-1972 ... . PotentiaJ future developments in social science computing ... . A computer model of simple forms of learning in infants ... . An information management system for social gaming ... .
PROGRAMMING· FOR PROCESS CONTROL AND REAL TIl\IE APPLICATIONS
The development of process control software ... . Future trends in software development for real-time industrial automation ... . Scheduling of time critical processes ... .
ACM PRIZE PAPERS IN PROGRAMMING LANGUAGES AND SYSTEMS
A class of allocation strategies inducing bounded delays only ... . On modeling program behavior ... .
A SPECTRUM OF MEMORY STORAGE SYSTEMS, NOW AND IN THE FUTURE
Magnetic disks for bulk storage-Past and future ... .
Ultra-large storage systems using flexible media,' past, present and future ... " ... " ... . New devices for sequential access memory ... .
GRAPHIC SOFTWARE
Two direct methods for reconstructing pictures from their projec-tions-A comparative study ... , ... . PRADIS-An advanced programming system for 3-D-display ... .
MARS-Missouri Automated Radiology System ... .
Sailing-An example of computer animation and iconic communication Computer description and recognition of printed chinese characters ... . Computer diagnosis of radiographs ... .
COMPUTERS IN SECONDARY EDUCATION
The impact of computing on the teaching of mathematics ... . Computing in the high school-Past, present and future-And its unreasonable effectiveness in the teaching of mathematics ... .
841 847
849 857
865 875 885 897
907
915 925
933 937
945
957 969
971 985
999
1005 1015 1027
1043
1051
S. Amarel M. S. Lynn
P. J. Denning p.1 C. Fischer
H. F. Cline G. Sadowsky T. L. Jones R. C. Noel T. Jackson
J. D. Schoeffler
H. E. Pike O. Serlin
E. W. Dijkstra P. J. Denning
J. M. Harker H. Chang
W. A. Gross F. H. Blecher
G. T. Herman J. Encarnacao W. Giloi J. L. Lehr G. S. Lodwick D. J. Manson B. F. Nicholson S. M. Zwarg W. Stallings S. J. Dwyer C. A. Harlow D. A. Ausherman G. S. Lodwick
W. Koetke
LSI PERSPECTIVES-DESIGN AUTOMATION: DESIGN AND SIMULATION
Computer-aided design of MOS/LSI circuits ... . The role of simulation in LSI design ... . Implementation of a transient macro-model in large logic systems .. . Functions for improving diagnostic resolution in an LSI environment ..
DEVELOPMENTS IN BIOMEDICAL COMPUTER TECHNOLOGY
Computer-aided drug dosage ... .
Automated therapy for non-speaking autistic children ... .
An inferential processor for interacting with biomedical data using restricted natural language ... . An information processing approach to theory formation in biomedical research ... .
The clinical significance of simulation and modeling in leukemia chemotherapy ... . Interactive graphics software for remote terminals and their use in radiation treatment planning ... .
Automated information-handling in pharmacology research ... .
THE IMPLEMENTATION GAP IN MANAGEMENT INFORMATION SYSTEMS
Where do we stand in implementing information systems? ... . MIS technology-A view of the future ... . Selective security capabilities in ASAP-A file management system ..
A graphics and information retrieval supervisor for simulators ... . NASDAQ-A user driven, real-time transaction system ... .
LSI PERSPECTIVES-THE BOUNDARIES OF COMPUTER PERFORMANCE
LSI perspectives-The last five years ... . Towards more efficient computer organizations ... .
1059 1065 1071 1079
1093
1101
1107
1125
1139
1145
1157
1167 1173 1181
1187 1197
1207 1211
H. W. vanBeek J. J. Teets N. B. Rabbat M. A. Mehta H. P. Messinger W. B. Smith
L. B. Sheiner B. Rosenberg K. L. Melmon D. C. Smith M. C. Newey K. M. Colby
D. W. Isner
H. Pople G. Werner
T. L. Lincoln
K. H. Ryden C. M. Newton W. Raub
J. C. Emery C. Kriebel R. Conway W. Maxwell H. Morgan J. L. Parker N. Mills
An appraisal of compiler technology
by ROBERT M. McCLURE
Consultant
INTRODUCTION
Although the last decade has seen the implementation of a very large number of compilers for every conceiv-able language, the literature on compiler writing is still unorganized. There are many papers on formal lan-guages, syntactic analysis, graph theoretic register as-signment, and similar topics to be sure. But, they are not very useful in helping the newcomer to the field decide how to design a compiler. Even the recent books in the field are more encyclopedic in nature than instruc-tive. The best single book available is Gries,! which has a good bibliography for further study.
The few open descriptions of compilers that do exist rarely are candid about the mistakes that were made. This is, after all, human nature. lVloreover the nature of scientific publishing is not conducive to papers of an evaluative or subjective nature. The principal reason, therefore, for writing this paper, is not to add to the basic body of scientific knowledge, but rather to provide a few value judgments on how compilers are being writ-ten and should be writwrit-ten. Since subjective statements should always be prefaced with "It is my opinion that", the indulgent reader will understand that this phrase should be applied to the entire paper.
There is an enormous amount of material to be stud-ied in connection with compiler design. lVlost of it is very difficult to read. vVe refer to the listings of the com-pilers themselves and associated internal documenta-tion. At present there is no alternative to obtaining a comprehensive knowledge of the field. Even if one is willing to put forward the effort, however, much of the material is difficult to obtain. The desire of computer manufacturers and software houses to protect their lat-est ideas interferes with a free flow of information. The result of this is the growth of an oral tradition for pass-ing information much like the wanderpass-ing troubadours of yore. Until this changes, there will be hardships worked on those who would like to learn the trade.
In order to reduce this paper to manageable size and
to make generalizations more useful, let it be
under-1
stood that we are mainly talking about so-called "pro-duction" compilers. By this we mean compilers for im-portant languages that are intended for translating pro-grams that are expected to be run extensively. l\Iore-over, we restrict our consideration to compilers for medium and large scale general purpose computers. The subject of compilers for minicomputers and special purpose computers is deserving of considerable study on its own. Also research compilers, "quick and dirty" compilers, and pedagogic compilers will not be con-sidered in this commentary. Finally, it is inevitable that someone's favorite technique will be given a short straw. For this we plead for tolerance.
SYNTACTIC ANALYSIS
In the area of syntactic analysis or parsing, the
neces-sary solutions are clearly at hand. Parsers are now rou-tinely constructed by graduate students as class proj-ects. The literature on the subject is extensive, and new techniques are revealed regularly. Almost all compilers are written using only two of the many available meth-ods however: recursive descent or precedence. Rarely are either used in pure form. Compilers that use both methods intermixed are common. Although both of these methods have their roots in the very earliest com-pilers, they remain the mainstays of the business.
Recursive descent
2 Spring Joint Computer Conference, 1972
6p-<"'"""OiO">-
Ep--<
""'0"'"'>-~-<""'""'"'>--
TF ERROR
Figure I-Recognition routine
recursive. Upon exit from each procedure, either the required syntactic unit has been recognized· and the appropriate actions taken, or an error message has been produced.
Recursive descent analyzers are usually written so that it is never necessary to "back up" the input stream.
If an impasse is reached, an error indication is given, perhaps a correction attempted, and the scan resumed at some readily recognizable token, such as ";". The knowledge of the context at the time an error is dis-covered allows more meaningful diagnostics to be gen-erated than with any other technique.
The use of recursive descent usually requires the re-arrangement of the formal syntax, since left recursions must be removed. Although this is not difficult, it does somewhat spoil the clarity of the approach. For peculiar grammars, it is easier to use recursive descent than to transform the grammar into a form suitable for prece-dence analysis. Although the methodology is basically ad hoc, recursive descent is the most widely used method of syntactic analysis.
Recursive descent has one further advantage for a language with a large number of productions. Prece-dence methods seem to require table sizes proportional to the square of the number of syntactic units, whereas recursive descent recognizers are roughly proportional to the grammar size.
Precedence analysis
The idea that operators have varying degrees of "precedence" or "binding-power" is quite old, and has been used in some of the earliest compilers. The formali-zation of precedence relations between operators ac-tually started with Floyd2 in 1963. Now it is more
customary to define precedence relations between all syntactic units. While very few producti0Ii compilers have used a formal precedence parser yet, the modern implementation of these techniques such as described by lVlcKeeman,3 is clearly destined for wider use.
The fundamental attraction of precedence methods lies in the automatic construction of analyzers from the formal grammar for the language to be analyzed. Parsers
built in this way can be quickly changed to reflect language changes simply by changing the tables without modifying the underlying interpretation algorithm. Furthermore, if the tables are constructed by formal methods, the language accepted is exactly that speci-fied and no other. This considerably simplifies the con-struction of bug-free parsers.
There are some drawbacks to parsers built wholly around precedence methods. For example, many languages in everyday use, such as COBOL and FOR-TRAN can simply not be made into precedence lan-guages. Even PL/I can only be fit into the correct mold with considerable difficulty. 1Vloreover, the tables re-quired can be quite large.
A major problem with precedence parsing methods is the problem of recovery from source program errors and the issuance of good diagnostics for such errors. Several approaches to solving this problem have been tried with only modest success. Various techniques for reducing the size of the tables required, such as the introduction of precedence functions, serve only to complicate this problem.
Nevertheless, there are several conditions that sug-gest strongly that a precedence parser of some variety should be tried. If, for example, a parser must be pro-duced in the shortest possible time. Precedence parsers tend to be easy to debug. A further advantage is gained if the language is being designed at the same time as the compiler, since the language can be made into a prece-dence language. Finally, a preceprece-dence parser is often a most suitable alternative when recursive procedure calls required for recursive descent parsing are either im-possible (as in FORTRAN) or expensive (as in PL/I).
Mixed strategies
INTERNAL REPRESENTATION
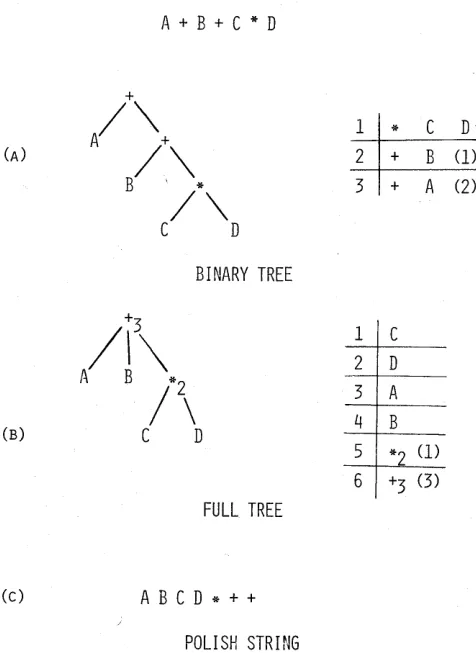
Generation of code occurs simultaneously with syn-tactic analysis only in very small compilers and quick and dirty compilers. In most compilers the results of syntactic analysis are stored for later code generation. A number of ways have been described for the internal representation of the results of parsing, two of which have attained really wide usage: tree structures (most usually a form known as triples) and late operator Polish notation. Figure 2 illustrates several forms of the representation of a simple expression. Form (a) is a binary tree, called triples when recorded in the tabular form shown, since each line consists of an operator and two operands. The result of each operator is known im-plicitly by the line number of the triple. Form (b) is a tree form with variable sized nodes. Form (c) is the Pol-ish form and is actually the string that results from tra-versing the terminal nodes of a parse tree in a prescribed order.
The simpler compilers prefer the Polish representa-tion since subsequent processing usually amounts to simply a linear reading of the text. Fortunately the order in which action is to be taken by the code
genera-A
+B
+C
*D
1
*C D
2 + B (1)
3 + A (2)
BINARY TREE
1 C 2 D 3 A
(B) 4 B
5 *2 (1)
6 +3 (3)
FULL TREE
(c)
[image:11.613.42.280.400.727.2]POll SH STR I NG
Figure 2-Internal representations
Appraisal of Computer Technology 3
tor is very nearly that of tokens in the Polish string any-way. Since this is also the order of generating the Polish string, the only advantage gained from deferred genera-tion is that obtained by a full reading of all of the text, including declarations, implicit as well as explicit. Al-though optimization can be implemented on internal representations in Polish form, tree forms are much easier to work with.
A further advantage of Polish strings is that they may be easily written on and read from sequential data files, are conceptually simple, and require a minimum of ad-ditional space for linkage information. If memory space is at a premium or the simplest representation is pre-ferred, Polish strings are recommended.
Complete representation of the source program in tree form is now growing in popularity, and has ap-peared in quite a number of the more recent compilers.
It is especially prevalent in compilers for major lan-guages for the larger machine in which optimization is important. The ease with which the program can be searched and/or rearranged is the primary motivation for this selection. For building a generation system based upon formal semantics, an internal tree representation is a good choice. Not only does it appear that code gen-eration can be formalized but also that optimization strategies can be formalized utilizing the idea of trans-formation sets defined over trees.
SYlVIBOL TABLES AND DICTIONARIES
Considerable effort has gone into devising symbol table routines that have all of the desirable properties of compactness of storage required, speed of access, and simplicity of construction. The result is that almost all' compilers use some variant of the hash link method. In this method, the symbol to be looked up is first hashed into a reasonably small range such as 31 to 512. This hash index is then used to access the head of a list of symbols with the same hash value. This is shown schematically in Figure 3., This hash chain is frequently ordered, say alphabetically, to reduce further the look-up time.
The dictionary information associated with each sym-bol may either be included directly with the external representation or be contained in a separate table. Since in a multiple pass compiler, the external representation is not required after the lexical analysis is complete, the separation of symbol table and dictionary has be-come customary.
4 Spring Joint Computer Conference, 1972
tive size of these tables could only be statistically
deter-o
mined, unnecessary limitation in the size of programsN-l
HASH TABLE
(CHAIN HEADS)
~
~l
\ " - - - - 1 B EE
tc
SYMBOLS WITH'IDENTICA'-.-
~
[image:12.612.60.302.76.308.2]HASH VALUES
~
Figure 3-Hash chain symbol table
support virtual memory, but does require careful at-tention if it must be strictly software supported. The simplest and usual method is to divide the space re-quired into pages and to address this space through an availability table. This method is used in the IBM PL/I compiler (F-Level) to allow the compilation of very large programs on a relatively small machine. In designing symbol table methods for use with software virtual memory, a premium is placed on minimizing the number of references to different blocks.
Compilers for block structured languages with im-mediate code generation usually allocate new dictionary entries in stack fashion. That is, new entries are placed in first position on the correct hash chain. Searching the hash chain then automatically gives the correct instance of the symbol searched for. At block closure, all the chains are pruned until an enclosing block number is found. The table is then shortened to the level that existed at block entry. In this way, symbol table entries that are no longer needed by the compilation are constantly discarded. Although PL/I is block struc-tured, this very simple approach is not available with-out refinement. In PL/I, declarations may at any point be made in enclosing blocks. For examples, lables on entry statements belong to the immediately enclosing block, implicitly declared variables belong to the outer-most block, and variables declared with the EXTER-N AL attribute are scopeless.
TABLE MANAGEMENT
Early compilers had fixed size tables for storing in-formation needed during compilation. Since the
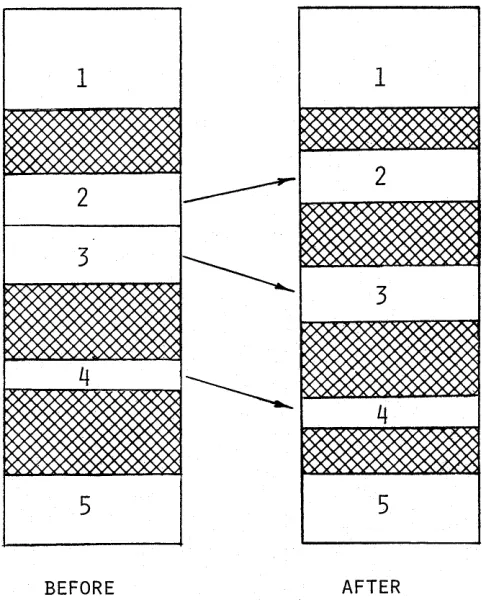
rela-that could be compiled frequently occurred. During the 1960's however, dynamic allocation of storage came into· widespread use. Although many techniques have been invented, only two have proven extremely popu-lar: movable, contiguous tables, and block allocation.
Movable tables
The conceptual simplicity of having tables in con-secutive memory locations is a major reason for adopt-ing the idea of "floatadopt-ing" tables. The additional burden of referencing all entries indirectly through a current table base pointer is a small price to pay for this sim-plicity. First used in compilers by Digitek in a series of minicomputer compilers and by IBM in a COBOL com-piler for the IBlVl 7090 in the early 1960's, the basic ideas have been widely adopted. Modern computer architecture that makes both base addressing and in-dexing simultaneously available makes implementation extremely simple.
Every table is allowed to grow (or shrink) indepen-dently. Before any table expands, a check is made to see if there is available space. If not, space is made available
1
1
~XX
2
3
4
~.I
4
IXXX)(
5
5
BEFORE
AFTER
[image:12.612.324.565.419.719.2]by actually copying the data items in the tables to be moved into another location in memory. Although copy-ing data in memory to reorganize storage seems inef-ficient at first, it turns out to be quite satisfactory in practice since it occurs rarely. Figure 4 shows how tables are rearranged to allow available space for all tables to grow.
The interesting questions about this form of alloca-tion revolve around deciding how much of the available space to allocate to each table. Garwick suggests that space be allocated in proportion to how much each table has grown since the last allocation. CITRUS (the stor-age allocation packstor-age in the IBlVl COBOL compiler) required specification of the desired increment of space. Most common is dividing the remaining space propor-tional to the current size of each table (with some pre-scribed minimum). All methods will run out of space only when there is absolutely no more. This may not be desirable, though, since considerable time will be spent trying to squeeze in the last item before overflow occurs. lVlovable tables seem to work best for relatively small memories, for machines in which internal speeds are fast relative to 1-0 speeds, or for systems in which all avail-able memory is allocated to the compiler at the start of any compilation.
List structures are complicated by the necessity to use relative links rather than absolute addresses and to identify the table pointed to.
B lock allocation
Block allocation methods are the second most popular storage management technique. In this case, tables are not kept in contiguous locations, and information is usually linked together. Each routine that may add data to a table is responsible for requesting a block of suit-able size (sometimes a system fixed size) for the purpose at hand. Usually space is allocated in multiples of the basic element size of the table at hand in order to avoid calling the main allocator too often. Since OS/360 imple-ments this form of allocation as a primitive in the operating system, this form of allocation has been quite widely used on that machine.
This technique does have the principal advantage that since table segments are not moved after alloca-tion, absolute pointers may be used in list structures. It suffers from the drawback that storage fragmentation can occur and may prevent usage of all available flem-ory.
Block allocation is suggested whenever memory is a resource to be shared with other simultaneous users of the machine in a multiprogramming environment. This is because it is desirable to minimize the amount of
Appraisal of Computer Technology ,,)
memory required at any given time, and most main memory allocation algorithms supported by operating systems do not guarantee that additional memory will be allocated contiguously with previously allocated memory.
IMPLEl\1:ENTATION TECHNIQUES
Early compilers were invariably written in assembly language; most still are today. It was originally felt that only assembly language could yield the efficiency that was required in such a widely used program as a compiler, and that the required operations were not well supported by higher level languages. Although it has now been generally recognized that very little of any compiler needs to be "tightly coded" to achieve nearly the same efficiency, the tradition of assembly coding is dying a slow and painful death.
A second reason usually given for writing a compiler in assembly language was to minimize the space that the compiler required for its code. Factors of 1.5 to 3 have been cited. With the growth of main memory sizes avail-able, the almost universal availability of random access secondary storage, and the common use of dynamic loading techniques, the requirement for small code has been considerably reduced in importance.
Advocates of coding in "higher level" languages have not always been completely candid in their arguments either. It is frequently stated that one of the main mo-tives for using a higher level language is the gain in read-ability that occurs. Anyone who has tried to read a compiler written in FORTRAN knows that this simply is not the case. A much stronger case may be made for PL/I or ALGOL. The fluidity of these languages plus the natural benefits of block structuring generally re-sult in code substantially more readable than assembly code.
A major drawback to most higher level languages for coding compilers is that the native data types manipu-lated in these languages are neither those required in either lexical scanning, nor those required for table management. Both of these are vitally important in compiling, and result in the construction of subroutines, frequently in assembly code, to support them. The link-age overhead in using these routines can be substantial.
con-6 Spring Joint Computer Conference, 1972
cise programs will have fewer bugs than verbose pro-grams.
Pops
One approach that has gained a number of particu-larly ardent adherents is that of writing compilers in an interpretive language. This idea seems also to have originated in the early 1960's. Although the COBOL compiler for the IBJVI 1410 was written in interpreted code, the main source of the popularity was the series of (mostly FORTRAN) compilers 'vrit~en by Digitek. A number of syntax directed compilers of the same vintage utilized an internal representation of a similar nature. The increased suitability of current computer instruc-tion sets for compiler writing has caused the technique to largely fall from favor for large machine compilers in recent years. The technique has much to recommend it for some applications, though, and it is worthy of a few comments.
Since there have been no published papers on the Digitek POP system, which appears to be the most highly developed system, we will include here a some-what more complete description than for the other ideas discussed in this paper.
The name POP derives from the Programmed OPera-tors on the SDS 910 for which the first Digitek FOR-TRAN compiler was written. These were a series of un-assigned operation codes that caused a trap to a loca-tion distinct for each such op-code. This enabled the user to define the meaning of each of these op-codes by a subroutine. Subsequently, for other machines which did not have such a feature, a completely interpretive system was substituted.
The POP system consists of a set of operations that resemble single address instructions. The single operand in each POP is either a single data element (usually an integer but perhaps a pointer into a table, etc.), a charac-ter, a string of characters (this is handled indirectly), a table (movable), or a flag. Additional data types are defined as needed. Tables are implemented as contigu-ous, movable tables as previously described. A pointer is defined as having a table number part plus an offset into a table. Pointers are used for forming linked struc-tures and for referencing data in tables if other than the last item is to be referenced. Tables are normally used like stacks. One table is distinguished as the main stack and is often used as an implicit second operand. Another table is distinguished as the stack used to save return addresses in procedure calls. Recursion is therefore quite natural.
To illustrate how this system is used, we will define several of the more common POP's. The first POP is
LDS (Load Stack), and is written as: LDS
LDS A B
This sequence of two POP's is interpreted as follows: ~irst the data item A, a single work item, perhaps an mteger, is placed on the main stack, extending it by one word in the process. Then the item B is added to the stack, extending it once again. At the conclusion the stack appears as in Figure 5. The end of stack
it~m
is referred to as item 0 and the next item (A) is referred to as item 1.The POP STS (Store Stack) is simply the converse. For instance:
STS A STS B
stores the end item of the stack in cell A, and shortens the stack. The second POP stores the new end item in cell B and shortens it once again. The net effect of the four POP's we executed is to exchange cells A and B.
Similarly, the stack may be loaded with the end item on any table by MOF (Move Off) which has as an operand a table number. The effect of this is to lengthen the stack and to shorten the table specified as the operand of the instruction by moving one word of data. This operation is usually defined to set a global flag to FALSE rather than to move an item if the table speci-fied is empty. The companion operation is lVI0N (Move On). Hence to move the contents of one table into another, the four instruction loop suffices:
LA
END OF STACK
MOF BRT lVION BRU
TAB LEI ALLDONE TABLE2 LA
A
B
Figure 5-Picture of end of stack
2
1
The two new instructions above are BRT (Branch True) and BRU (Branch Unconditional).
Character scanning is done with primitives of the form
CRS character
The POP CRS (Character Scan) has as its operand the internal representation of a character. If the specified character is the next in the character input stream, the input scanning pointer is advanced and a global flag set to TRUE. Otherwise the global flag is set to FALSE. Similarly a complete string may be matched with SCN (String Scan), as in
SCN "BEGIN"
Subroutine calling is done with BRS (Branch and Save) which stores the return address in a stack. The natural implementation of recursion leads most POP written compilers to be of the recursive descent variety. For instance the sequence of code required to recognize the syntax SU1VI :: = TERl\1 {+ TERl\/I }
*
is as simple asSUM BRS
CRS BRT RET
TERM
"+"
SUM
The POP system is fleshed out with instructions for packing and unpacking data words, creating instruc-tions, setting and testing flags, and so on almost ad infinitum. In theory, a POP compiler can be moved from one machine to another simply by writing a new interpreter for the next machine. In practice, this is not feasible because the bulk of the work in writing a com-piler is in designing the code generation strategy, which must be rethought for any new machine in any event. POP compilers are considerably more compact in code than machine coded compilers, especially where there is an addressability problem (such as in a mini-computer). Fortunately this is the place that compact-ness is needed most. POP written compilers are, how-ever, slower than machine coded compilers not only be-cause of the interpretive overhead, but also bebe-cause of the redundant work done in moving data through the stack. This problem is masked in minicomputers since their computing power is very high relative to input output speeds of paper tape and teletypes.
The synopsis is that POPs are a fairly good way to write very small compilers for minicomputers and a poor way to write compilers for large machines.
Translator writing systems
As an implementation technique, the use of one of the many extant Translator Writing Systems deserves
Appraisal of Computer Technology 7
at least some mention. The idea of using a TWS is very appealing, but in practice the use of TWS has not proven much of a boon. The reason is quite simple. To date, TWS has done a good job of lexical scan, parsing, and the dictionary parts of a compiler, but has made few inroads into the most difficult parts, namely code gen-eration and optimization. Even if the facilities provided by a TWS are valuable, the penalty of forcing a user into a prescribed mold has been too stiff for most pro-duction compiler writers to bear.
CODE GENERATION
Code generation has traditionally been one of the most ad hoc (and bug-ridden) parts of any compiler. There is some evidence, though, that this is changing rather rapidly. Formally, the generation of code is the attaching of semantics to specific syntactic structures. In the case of immediate generation, of course, op-portunities for substantially altering the source order are minimal and conversion of the parse back into se-quences of instructions proceeds strictly on a local basis. The actual generation of code is accomplished either by open sequences of code that construct the required in-structions or by the equivalent of macro sequences selected by combination of the operator and the as-sociated operand types. In the latter case, the macros are usually described in a format similar to the assembly language of the target machine. Conditional features similar to conditional features in macro assemblers are used to improve on the quality of code generated. Pro-vision is normally made to test the state of the target machine as well as supplementary information about the operands. The macros also update the state of the target machine.
In multipass compilers, there is now a move to sys-tematize code generation by formal tree transforma-tions so that all data conversions, register loadings, and the like, are explicitly recognized in the tree structure. Most of the current work in formal semantics is along this line. Information may be collected during tree traversals which aids considerably in the production of high quality code.
Whether the code is produced by conventional or table driven techniques is far less important that the organization of the generation as a sequence of trans-formations rather than as a complex series of decisions based upon global data left as side effects of prior gen-eration.
OPTIMIZATION
8 Spring Joint Computer Conference, 1972
most production compilers try much harder to generate high quality code even at the expense of considerably slower compiling. This tradition dates from the very first FORTRAN compiler. At that time, it was felt necessary to compete with hand generated code in quality in order to gain acceptance. Since that time much effort has gone into finding ways to improve the quality of code generated by compilers. Unfortunately, the matter is too tightly bound up with the specifics of the language at hand. FORTRAN, for example, is rela-tively easy to optimize. PL/I, on the other hand, is almost impossible due to the significance of side-effects in the language. If, of course, optimization information is supplied by the programmer (which is rarely done), the problem becomes more nearly like that of FOR-TRAN.
After carefully sifting through all of the forms of optimization that have been used however, there are only two areas Qf optimization that have sufficient pay-off to warrant consideration, unless super-optimization is being attempted. That is, there are only two issues in addition to strictly local improvements in generated sequences. These two areas are register assignment and address calculation.
Optimal register assignment
Also dating back to the earliest compilers is the prob-lem of optimal assignment of the registers available in the machine. If a computer has only one register of a given class, or a very large number, the problem is minimal or does not exist. However, for common machines with 3 to 16 registers in a register class, the advantage to finding the correct data items to maintain in registers can be substantial. This is particularly true of values used for array accessing. Although there have been numerous papers on this subject, the general prob-lem is still unsolved. Even the most satisfactory ap-proaches require an excessive amount of computation to find an optimal solution.
The consequence of this dilemma, is that most com-pilers that do not do flow analysis usually simplify the problem by merely keeping a simple record of register contents. Loads and stores are then done on a strictly local basis. This works quite satisfactorily for all except the most demanding requirements.
A ddress calculation
One of the most important forms of non-trivial opti-mization and one that requires at least a modicum of flow analysis is the calculation of subscripts within a
loop by repeated addition of some precalculated value to an address rather than a full recalculation of the ad-dress. This is best shown by the simple loop:
DO K
=
2T099;A(I, J, K)
=
A(I, J, K +1) + A(I,J, K - 1);END;
The address calculations required can be drastically re-duced with only two observations. First, all three array addresses are related to each other with only a constant difference. Second, consecutive executions of the loop body require only that the address be adjusted by a constant amount. The first of these simplifications is called common subexpression elimination. The second is called recursive address calculation. (It has nothing to do with recursion in the programming sense. Here it is really an iteration.)
Gear4 reports on a reasonably straightforward way of
accomplishing this by consecutive passes over the parsed program in alternating directions. Although his tech-nique is applicable without alteration only to explicit loops in the program with no local branching to disturb the movement of code, with more extensive flow analysis this can be generally accomplished.
Although common subexpressions other than sub-script expressions can be located and moved, the bene-fits are not impressive and there are perils. The necessity of avoidance of altering the side effects of the evaluation is often underestimated. For this reason, more general common sub expression detection is not often done.
Since programs that do considerable accessing of multidimensional arrays spend a large part of the time in address calculation, locating common index expres-sions and calculating addresses recursively in loops is recommended as one of the first targets in any compiler intended to produce very high quality code.
SUMMARY
apply the best that is already known is perhaps even greater.
REFERENCES
1 D GRIES
Compiler construction for digital computers
John Wiley 1971 2 R W FLOYD
Appraisal of Computer Technology 9
Syntactic analysis and operator precedence
Journal of the ACM July 1963 p 316 Vol 10 3 W R McKEEMAN J J HORNING
DB WORTMAN
A compiler generator
Prentice Hall 1970 4 C W GEAR
High speed compilation of efficient object code
A laboratory for the study of
automating programming*
by T. E. CHEATHAM, JR. and BEN WEGBREIT
Harvard University
Cambridge, Massachusetts
INTRODUCTION
We are concerned in this paper with facilities, tools, and techniques for automating programming and thus we had best commence with discussing what we mean by
programming. Given a precise specification of some task
to be accomplished or some abstract object to be con-structed, programming is the activity of producing an algorithm or procedure-a program-capable of per-forming the task or constructing a representation of the object on some computing system. The initial specifica-tions and the resulting program are both couched in some (programming) language-perhaps the same language. The process typically involves such activities as: choosing efficient representations for data and al-gorithms, taking advantage of known or deduced con-straints on data and algorithms to permit more efficient computations, verifying (proving) that the task will be accomplished or that the object constructed is, in fact, the one desired, demonstrating that certain performance criteria are met, and so on.
The kind of facility currently available which might be characterized as contributing to automating pro-gramming is usually called a compiler. It typically trans-lates an algorithm from some higher level (program-ming) language to a lower level ("machine") language, attempting to utilize memory and instruction resources effectively and, perhaps, reorganizing the computational steps, as implied by the higher level language repre-sentation, to move invariant computations out of loops, check most likely (or cheapest) arms of conditions first, and so on.
Weare not here concerned with traditional compilers; indeed, we will assume the existence of a good compiler.
* This work was supported in part by the Advanced Research Projects Agency under contract F-19628-68-C-0379 and by the U.S. Air Force Electronics Systems Division under contract F19628-71-6-0173.
11
Weare concerned with facilities at a "higher level": translating specifications which contain much less com-mitment to particular data and algorithmic representa-tions than is usual with higher level programming lan-guages, and performing rather more drastic reorganiza-tion of representareorganiza-tion, implied computareorganiza-tional steps, and even implied method of computation than is done with traditional compilers. We imagine our end product to be programs in a higher level language. On the other hand, we must note that the line between the kind of facility we will describe and a good compiler is very fine indeed and we will suggest that certain kinds of trans-formations sometimes made by conventional compilers might better be approached with the tools and tech-niques described here.
The purpose of this paper is to describe a facility which we characterize as a laboratory for the study of automating programming. We view the laboratory as a pilot model of a facility for practical production pro-gramming. The time and expense invested in program-ming today and the lack of confidence that most pro-grams today actually do what they are intended to do in all cases is surely dramatic evidence of the value of such a facility. The need is particularly acute when the task to be accomplished is complex and the resulting program is necessarily large. Such situations are pre-cisely those encountered in many research areas of com-puter science as well as in many production systems soft-ware projects. Dealing with this kind of complexity, which is to say producing efficient verifiably correct program systems satisfying complex requirements is a significant, decidedly non-trivial problem.
12 Spring Joint Computer Conference, 1972
section discusses, in general terms, a variety of program au tomation techniques to be employed; the sixth section describes the basic components of the initial laboratory ; and the seventh section summarizes what we hope to accomplish with the laboratory and mentions several open problems.
RELATED WORK
There is a considerable body of work and a number of current research areas which are related to program-ming automation. lVlost of this work does not, at present, provide anything like a complete system; much of it does provide components of a system for automating pro-gramming and is thus directly related to and sometimes directly usable in the laboratory we will describe.
We have divided the work to be discussed into seven different areas: automatic program synthesis, mechan-ical theorem proving, automatic program verification, program proof techniques, higher level programming languages, equivalence of program schemata, and sys-tem measurement techniques. In each case we are dis-cussing the "vork of several people; the bibliography cites the recent work we feel is most relevant.
A utomatic program synthesis
The basic idea here is to construct a program to pro-duce certain specified outputs from some specified in-puts, given predicates asserted true of the inputs and the outputs as related to the inputs. The basic technique is to (mechanically) prove the theorem that there exist outputs satisfying the predicate and then to extract a program from the proof for constructing the outputs. It has been suggested that these techniques can also be utilized to transform programs, for example to trans-form a recursive procedure into an equivalent iterative procedure using the two stage process of first deducing a predicate that characterizes the recursive procedure and then synthesizing an equivalent iterative procedure which computes the outputs satisfying the predicate deduced.
We view the work in this area to date as primarily of theoretical interest and contributing to better mechan-ical theorem proving and proof analysis techniques. It is often more convenient to produce an (inefficient) algorithm than it is to produce a predicate; the two stage process proposed for "improvement" of programs is awkward and, we believe, highly inefficient as com-pared with the direct transformation techniques to be discussed below.
111 echanical theorem proving
The heart of any system for automating program-ming will be a facility for mechanical theorem proving. At the present time there are two basically different ap-proaches to mechanical theorem proving and a realiza-tion of both these approaches provide important com-ponents of our laboratory. One approach is to construct a theorem prover which will, given enough resources, prove any true theorem in the first order predicate calcu-lus with un interpreted constants; the other approach is to provide a theorem prover which is subject to con-siderable control (i.e., allO\vs one to employ heuristics to control the strategy of proof) and which utilizes in-terpretations of the constants wherever possible for efficiency. l\Iechanical theorem provers of the first sort are now usually based on the resolution principle. We term those of the second sort "programmable theorem provers".
Resolution theorelll provers
Robinson's 1965 paper introducing the resolution principle has been followed by vigorous activity in implementing mechanical theorem provers based on this principle. lVluch of the activity has been concerned with developing strategies for ordering consideration of resolvents; at the present time the breadth-first, unit-preference, and set-of-support general strategies have been studied and other variations are being considered.
It is clear that a powerful resolution-principle based theorem prover will be an important component of the laboratory.
Prograllllllable theorelll provers
A utomatic program verification
The work in this area is concerned with mechaniza-tion of what we term "flow chart inducmechaniza-tion". Given a representation of some algorithm as a flow chart with as-signments, conditional branching, and looping, one ap-pends to the boxes of the flow chart predicates asserted true of the variables at various points in the computa-tion and, in particular, of the inputs and the outputs. The procedure is then to attempt to mechanically dem-onstrate that the whole is consistent and thus that the program is correct.
Again, we view this work as primarily of theoretical interest. The theorem proving techniques utilized in King's system (see [King]) are particularly interesting, however, as they utilize interpretations of the integers and operations over the integers; while not general, they do provide rather more efficient methods for proofs concerning integers than is presently possible with the more general resolution-type proof methods which do not employ interpretations.
Program proof techniques
A number of workers have been concerned with de-veloping proof techniques which are adapted to obtaing proofs of various properties of programs. These in-clude some new induction methods-structural induc-tion and flow chart inducinduc-tion-simulainduc-tion techniques, and so on. This work provides a very important basis for proving the equivalence of various programs.
Higher Level Programming Languages
A considerable amount of work in the development of higher level programming languages has been concerned with providing languages which are particularly ap-propriate for certain application areas in the sense that they free the programmer from having to concern him-self with the kind of detail which is not relevant to the application area in which he works. For example, APL permits a programmer to deal with arrays and array operations and relieves him of concern with the details of allocation, accessing, and indexing of the array ele-ments. SNOBOL 4 directly supports algorithms which require back tracking, providing the mechanics auto-mati cally and permitting one to write theorem-proving, non-deterministic parsing, and such like algorithms very easily. SETL provides general finite sets as basic data objects plus the usual array of mathematical operations and predicates on sets; it thus permits one to utilize quite succinct statements of a wide variety of
mathe-Laboratory for Study of Automating Programming 13
mati cal algorithms and to considerably ease the problem of proving that the algorithms have certain properties. EeL (which we discuss in some detail in a later section) provides a complete programming system with facilities which permit one to construct extended language facil-ities such as those provided in APL, SNOBOL 4, and SETL, and to carefully provide for efficient data repre-sentation and machine algorithms to host these extended language facilities.
Equivalence of program schemata
There has been considerable interest recently in studying various program schemata and investigating their relative power, developing techniques for proving their equivalence, and so on. Most of the work to date is interpretation independent and while, for example, many transformations from recursive specification to iterative specification of algorithms have been devel-oped, it is clear that many practical transformations cannot be done without employing interpretations.
The most common use of interpretation dependent transformations is in "highly optimizing" compilers. There, a very specific, usually ad hoc set of transforma-tions is employed to gain efficiency. Often the transfor-mations are too ad hoc-under certain conditions they do not preserve functionality (i.e., don't work correctly).
System performance measurement techniques
It is a quite straightforward matter to arrange for various probes, monitors, and the like to permit meas-urements of the performance of programs, presuming that appropriate test input data sets are available, and a considerable amount of work has been done in this area. However, there are two further areas which are now the subject of investigation which we feel may yield important components for our laboratory. These are mathematical analysis of algorithms and automatic generation of probability distributions for interesting system parameters.
Mathematical analysis of algorithms
14 Spring Joint Computer Conference, 1972
mechanical assistance in this activity, particularly in the area of aiding in the inevitable symbolic algebraic manipulation required in carrying out a mathematical analysis.
AutoDlatic synthesis of probability distribu tions
Some recent work by Nemeth (see [Nemeth]) may, when it is developed further, provide an interesting and valuable component of the laboratory. What he is trying to do is to develop algorithms for mechanically generat-ing probability distributions for various parameters from a computational schema augmented by given probability distributions for input variables and func-tions employed. Use of techniques like his should prove far superior to actually carrying· out the computation for sample data values. A mixture of mechanical genera-tion of distribugenera-tions and carrying out porgenera-tions of a computation might, in the earlier stages, provide a practical tool.
All the above work is related and relevant to auto-mating programming, but none, in our opinion, is ade-quate alone. The need .now is to integrate these facili-ties, techniques, and so on into a system-a laboratory for the study of automating programming.
THE APPROACH TO BE TAKEN IN THE LABORATORY
The goal of such a laboratory is a practical, running system that will be a significant aid to the construction of real-world programs. Automating programming en-tails transferring to the computer those facets of programming which are not carried out efficiently by humans. It is our contention that the activity most in need of such transfer is the optimization (in a very broad sense of the word) of programs. The orientation of the laboratory and the principal task to which it will be put is that of taking an existing program and improving upon it.
That optimization is, indeed, a key problem requires little defense. If "program" is taken in a sufficiently broad sense, it is easy to produce some algorithm which performs any stated task. Given just the right language, program synthesis is seldom a significant issue. For many problems, the most natural task description is precisely a program in an appropriate notation. The use of an extensible language makes straightforward the definition of such notation. For other problems, it may be that a predicate to be satisfied is a better task state-ment, but this too is in some sense a program. The line between procedural and non-procedural languages is
fuzzy at best and it may be erased entirely by the use of theorem-proving techniques to transform predicates into programs (and conversely).
As we see the problem, the issue is not arriving at a program, but arriving at a good one. In most cases, programs obtained from theorem provers applied to predicates, from a rough-cut program written as a task description, or even from the hands of a good program-mer leave much to be desired. Often, the initial program is several orders of magnitude away from desired or even acceptable behavior. The larger the program, the more likely this is to be the case. The reasons are gen-erally such defects as inefficient representation of data, failure to exploit possible constraints, use of inefficient or inappropriate control structures, redundant or par-tially redundant computations, inefficient search strat-egies, and failure to exploit features of the intended host environment. Recognizing the occurrence of such defects and remedying them is the primary goal of the labora-tory.
ECL AS A BASIS FOR THE LABORATORY
The ECL programming system and the ELI language have been designed to allow rapid construction of large complex programs, perhaps followed by modification and contraction of the programs to gain efficiency. The facilities of ECL permit one to compose, execute, com-pile and debug programs interactively. The ELI lan-guage is an extensible lanlan-guage with facilities for ex-tension on three axes: syntax, data, and operations.
The ELI language plays four roles in the laboratory: (1) it is the language used to construct the various com-ponents of the system; (2) it and its extensions are the language used to state algorithms which are to be manipulated by the system; (3) it is the target language for transformations (i.e., ELI programs are transformed into better ELl programs); and (4) it is the host lan-guage for the theorems constituting the data base.
*
The features of ELI and its host system, EeL, which are particularly relevant to the laboratory are the fol-lowing:
(a) Data types (called "modes" in ELl) can be pro-grammer defined usi~g several basic data types (e.g., integers, reals, characters, etc.) and, re-cursively, several mode valued functions (e.g., construction of homogeneous sequences, non-homogeneous sequences, pointers, etc.).