DOI : 10.32628/CSEIT195180
A Review on Predicting User Behaviour through Session Using
Web Mining
Veena Moharle1, Sonali Waghade1, Divyani Dhoke1, Sheetal Kolhe1, Snehal Narule1, Prof. Merajul Haque2 1BE Students, Department of Information Technology, JD College of Engineering and Management, Nagpur,
Maharashtra, India
2Assistant Professor, Department of Information Technology, JD College of Engineering and Management,
Nagpur, Maharashtra, India
ABSTRACT
Web usage mining is driving examination zone in Web Mining worried about the web client's behavior. Weblog mining is one of the ongoing regions of research in Data mining. Web Usage Mining turns into an imperative perspective in the present time because the amount of information is persistently expanding. We manage the web server logs which keep up the historical backdrop of page demands. Web log records are the documents, which contain total data about the clients, peruse exercises on the web server Web mining is the utilization of information mining strategies to find designs from the World Wide Web. This paper gives a consideration on Web usage mining to anticipate the behavior of web clients dependent on web server log records. Clients utilizing web pages, a successive access way's and continuous access pages, joins are put away in web server log records. Contingent on the recurrence of clients visiting each page mining is performed. By finding the session of the client we can break down the client behavior when spending on a specific page. Web log alongside the distinction of the client catches their perusing behavior on a website and talking about with respect to the behavior from the investigation of various algorithms and diverse strategies.
Keywords : Knowledge Sharing, Web Portal, Job Portal, Online Recruitment.
I. INTRODUCTION
Web Usage mining applies the information mining method to extricate learning from weblog records naturally. Web mining can be arranged into web content mining, web structure mining and web usage mining. Web content mining is the way toward separating data from an expansive measure of gathered information. This strategy extricates the data from the substance of web pages. Web content mining is again arranged into interactive media mining and web printed mining. Web structure mining is the way toward dissecting the connections
between web pages through the web structure. Web structure mining is again classified into hyper interface mining and inside structure mining. Web usage mining examinations weblog records for discovering program examples of the client. Web usage mining is additionally called weblog mining.
out of IP address of the asking for customer, date and time of the demand, asking for technique utilized, status code, the asked for the record, and so forth. It is conceivable to sort the arrangement of snap exercises into sessions, and after that utilization them for further investigation to get the predicted client behaviour. Breaking down clients' Web watching behaviours is one of the essential and testing research subjects of Web usage mining. On the off chance that clients' advantages can be naturally recognized from clients' Web log information, they can be utilized for data suggestion and showcasing which are valuable for the two clients and Web webpage engineers. Research for dissecting Web log information has been finished by numerous specialists in the field of Web usage mining; finding incessant examples of log information. The principle motivation behind the investigation of the client's visit record is to break down the client's most worried about the outcomes from the mining results. By breaking down the client access to assets of the time, recurrence, etc., alter the structure and plan of the site to anticipate that more clients should remain and better serve clients. Client behaviour investigation has turned into another examination hotspot.
The work of this research mainly contemplates the weblog Mining technology in client behaviour investigation and assembles the client premium model dependent on the client premium data, lastly draws the client's advantage.
II. LITERATURE REVIEW
G. Neelima and Dr. Sireesha Rodda individuals from IEEE have proposed a thought for anticipating client behavior through sessions utilizing weblog mining. They manage web server logs of NCSA normal log record design for mining. The proposed methodology comprises of information handling, client distinguishing proof and session recognizable proof procedures. They are utilizing three unique
algorithms for playing out every one of these procedures [1].
Anshul Bhargav and Munish Bhargav likewise the individuals from IEEE proposed edge work for web usage mining. The edge work is to perform client’s
characterization dependent on found examples and to discover the qualities of clients. The casing work comprises of three principal steps: pre-processing, design disclosure and client arrangement. The pre-processing stage incorporates log document cleaning, client ID and session recognizable proof. The example disclosure process finds a new example from the informational collection. In the client arrangement process, every client is grouped by his or her attributes. The groupings depend on nation-based arrangement, site section nation-based order and access time-based characterization [2].
S. S. Patil and H.P Khandagale proposed subjective client demonstrate which determine the foreseen usage behaviour dependent on the examples found in past pre-processing, stage. The edge work incorporates information cleaning, client recognizable proof, session distinguishing proof, way finish, exchange ID and example revelation and extraction forms. Way culmination alludes to creating rules for missing references dependent available structure, referrer, and other heuristic data. By breaking down the found example, the behavior of the client is recognized and route refreshes are given in the web page [3].
Fluffy c implies bunching is a standout amongst the most generally utilized fluffy grouping algorithms [4].
In this exploration [5] propose the structure and usage of a half and half framework by consolidating a few information mining methods to catch the client's web perusing behavior. Client route sessions that speak to the association with a given website are utilized to develop Hypertext Probability Grammar (HPG). Break down the HPG with the idea chain of command show and apply the network bunching procedure to separate the usual portrayal of client route behavior.
This paper [6] portrays a technique for clearing up clients' interests dependent on an examination of the site-catchphrase diagram. The technique is for removing sub-diagrams speaking to clients' primary advantages from a website Keyword chart. It is produced from increased Web crowd estimation information (Weblog information). Our commitments are 1) Web structure mining strategy (PageRank) is appropriate for assessing the characteristics of chose sub-diagrams and 2) two sorts of information (destinations and catchphrases) can be spoken to and handled in a similar way utilizing a webpage catchphrase diagram. Our technique is basic and it has capacities of separating sub-diagrams identified with clients' principle advantages. Our work is required to give bits of knowledge for preparing boisterous heterogeneous chart structures.
This investigation of work [8] for the most part presents the technique for weblog mining, which can find the method of web pages by burrowing web log records. By dissecting and investigating the standards of weblog records, we can recognize the potential clients of the website and enhance the nature of data administrations to clients. In the phase of client behaviour investigation, this examination investigates the distinctions in client perusing behaviour in various sorts of access occasions and figures the
client's advantage dependent on the M5 display tree to break down the explanatory occasions.
In this examination [9], we present the "errand trail" to comprehend client seek behaviours. We characterize an errand to be a nuclear client data need, while an assignment trail speaks to all client exercises inside that specific undertaking, for example, question reformulations, URL clicks. he considers investigations and correlations with assess the viability of undertaking trails in a few inquiry applications: determining client fulfillment, anticipating client seek premiums, and recommending related questions. Analyses on expansive scale datasets of a business internet searcher demonstrate that:
(1) Task trail performs superior to anything session and question trails in determining client fulfillment;
(2) Task trail builds web page utilities of end clients contrasting with session and inquiry trails; (3) Task trails are equivalent to question trails yet
more touchy than session trails in estimating distinctive positioning capacities;
(4) Query terms from a similar assignment are more topically predictable to one another than question terms from various undertakings; (5) Query proposal dependent on errand trail is a
decent supplement of question recommendations dependent on session trail and navigate bipartitely.
The discoveries in this paper check the need for removing errand trails from web look logs and improve applications in hunt and suggestion frameworks.
III.Discussion and Analysis
information, demonstrating clients' route designs, grouping clients of explicit Web webpage, and finding client networks.
A. Web Log Mining
Web Usage Mining is the use of information mining strategies to find intriguing usage designs from Web information to comprehend and better serve the requirements of Web-based applications. Usage information catches the character or beginning of Web clients alongside their perusing behaviour at a Web webpage.
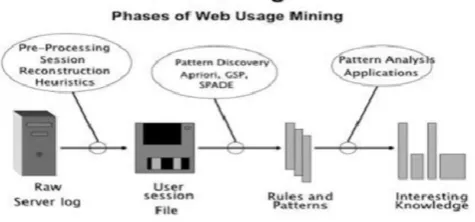
Fig 1. Phases of Web Usage Mining
A server log is a log document (or a few records) consequently made and kept up by a server comprising of a rundown of exercises it performed. Web server logs are utilized to bunch web clients having comparative interests. It is likewise characterized as adjusting administrations and data which was accessible on a website to the necessities and the desires for an objective client, the dynamic client; the personalization undertaking by might profit by the information picked up from an investigation of the client's navigational behaviour joined with different highlights which are curious to a Web setting, to be specific its structure and content [10].
B. Session Identification
At present, there is no standard meaning of session in the International scholarly network. The meaning of the session made by W3C Union is that it's a point of confinement set of pages produced by clients' one or a few demand click. In the Weblog, the demand records have a place with the clients who have distinctive IP addresses positively not in a similar session. A client may peruse a similar site a few times and the time interim between each peruse moderately expansive, at that point that is not in a similar session. Session distinguishing proof's undertaking is to partition clients' peruse records into a suitable session. We in every case initially do distinctive presumptions on the client's perusing behaviour on the customer, and after that distinguish the session. These sessions can be utilized as a piece of info information in grouping, bunching, expectation and different errands. In light of a uniform settled timeout, a conventional session recognizable proof calculation is utilized.
IV.CONCLUSION
keep up the historical backdrop of page demands Weblog record examination started with the reason to offer to Web webpage directors an approach to guarantee sufficient transfer speed and server ability to their association. By examining these logs, it is conceivable to find different sorts of learning, which can be connected behavior investigation of clients.
V. REFERENCES
[1] G. Neelima , Dr. Sireesha Rodda, “Predicting
user behavior through sessions using the web
log mining”, Conference on Advances in
Human Machine Interaction (HMI), R. L. Jalappa Institute of Technology, Doddaballapur, Bangalore, India, March 2016.
[2] Anshul Bhargav , Munish Bhargav, “Pattern
discovery and users classification through web
usage mining”, International Conference on
Control Instrumentation, Communication and Computational Technologies, IEEE 2014. [3] S. S. Patil, H. P. Khandagale, “Survey paper on
enhancing web navigation usability using web
usage mining techniques”, International journel
of modern trends inenginnering and research.2016.
[4] Virendra R. Rathod and Govind V Patel,
“Prediction of user behaviour using web log mining in web usage mining”, International
journel of computer application vol. 139- No. 8, April 2016.
[5] . M. -S. Kao, T. Ozyer, R. Alhajj,"Hybrid approach for predicting the behavior of Web users", IEEE International Conference on Information Reuse and Integration, Conf, 2005. [6] Tsuyoshi Murata, Kota Saito,"Extracting Users'
Interests from Web Log Data ", IEEE/WIC/ACM International Conference on Web Intelligence (WI 2006 Main Conference Proceedings) (WI'06)
[7] Mahendra Pratap Yadav, Pankaj Kumar Keserwani, Shefalika Ghosh Samaddar,"An
Efficient Web Mining Algorithm for Web Log Analysis: E-Web Miner ",1st International Conference on Recent Advances in Information Technology (RAIT) 2012
[8] Xipei Luo, Jing Wang, Qiwei Shen, Jingyu Wang, Qi Qi ,"User Behavior Analysis Based on User Interest by Web Log Mining ", 27th International Telecommunication Networks and Applications Conference (ITNAC),2017 [9] Zhen Liao, Yang Song, Yalou Huang, Li-wei
He, Qi He,"Task Trail: An Effective Segmentation of User Search Behavior",IEEE Transactions on Knowledge and Data Engineering,2014.