Available Online atwww.ijcsmc.com
International Journal of Computer Science and Mobile Computing
A Monthly Journal of Computer Science and Information Technology
ISSN 2320–088X
IMPACT FACTOR: 6.017
IJCSMC, Vol. 6, Issue. 4, April 2017, pg.56 – 60
AUTOMATIC SLIDE CREATION FROM
PUBLICATIONS USING ILP METHOD
1
Mr. M.ARUN MARX,
2P.KEERTHANA,
3M.MAHALAKSHMI
1
Assistant Professor, Department of Information Technology, Prathyusha Engineering College, Chennai, India 2, 3,
Student, Department Of Information Technology, Prathyusha Engineering College, Chennai, India
Abstract:- The totally accessibility from claiming web documents done electronic manifestations obliges a programmed system to mark the documents for An predefined set from claiming topics, the thing that may be known as programmed content classification (TC). Through as long as decades, it need been seen an extensive amount for propelled machine Taking in calculations with location this testing assignment. Those created presentation slides camwood make utilized Likewise drafts to assistance those presenters get ready their formal slides On a snappier manner. A novel framework called PPSGen may be suggested on location this errand. Documents are typically quelled eventually Tom's perusing the “bag-of-words”: namely, every expression alternately phrase happens over documents when alternately more times may be viewed as similarly as a characteristic. It to start with utilizes the relapse technique with figure out the vitality scores of the penalties Previously, an academic paper, et cetera exploits the basic straight customizing (ILP) system with produce well-structured slides by selecting What's more adjusting enter expressions and penalties. This paper proposes a novel framework called PPSGen on produce presentation slides starting with academic papers. We prepare a sentence scoring model dependent upon svr Furthermore utilize the ILP system with adjust and extricate magic expressions and penalties to generating those slides. Test Outcomes indicate that our technique could produce considerably preferred slides over conventional systems.
Keywords: Slide Generation, Content Mining, Text classification.
I. INTRODUCTION
Slides bring been a viable and mainstream method for presentation from claiming majority of the data. Done a number conferences Furthermore meetings, a presenter takes those support about slides with display as much partake) energizes a deliberate path (pictorial). Previously, later a considerable length of time for those accessibility for huge numbers product devices such as Microsoft PowerPoint, open office Presenter and so forth. , to not difficult preparation about slides, their use need expanded enormously. Anyhow these instruments help main in the organizing of content (stylizing, slug focuses etc), at not clinched alongside get ready the substance itself.
We point should naturally produce well-structured slides and gatherings give such draft slides as An support to decrease the presenters’ occasion when and exert At get ready their last presentation slides.
A presentation for slides is thereabouts successful on pasquinade data to individuals over at whatever situations, for example, such that an academic gathering alternately business. Despite some software’s, for example, such that PowerPoint Furthermore Keynote, assistance us with settling on presentation slides, it may be at present awkward should make them starting with scratch.
Slides hold numerous those summarized rendition of a specialized foul report card. They hold numerous the indispensable focuses of the report card orchestrated for An precise way, including realistic components like figures What's more tables to not difficult outline of the clue. Provided for a document, “Automatic era about presentation slides” gets An nontrivial errand due to tests like segmental copyright c 2009, cooperation to those headway about computerized reasoning (www. Aaai. Org). The sum privileges reserved, summarizing content about each point and adjusting these topics with one or a greater amount slides What's more putting necessary graphical substance like figures, graphs and tables to fitting slides toward proper areas.
A slide may be a solitary page of a presentation. Collectively, an assembly about slides might be known as An slide deck. In the last and only the twentieth century, a presentation slide might have been made with respect to a transparency What's more seen with an overhead projector. In the advanced age, a slide A large portion usually alludes all the with a solitary page created utilizing An presentation project for example, such that Microsoft PowerPoint or fruit keynote. It is also time permits to make them with a archive markup language, for example for those latex class Beamer.
II. RELATED WORKS
M. Thangamani and P. Thangaraj in 2010 the characteristic determination systems were used to enhance those effectiveness and correctness from claiming grouping methodology. Those characteristic determination might have been carried out by dispense with the excess Also unimportant things starting with the quick report substance. Factual strategies were utilized within the quick grouping furthermore characteristic determination algorithm. Those 3d shape measures will be high and correctness may be low in the term based content grouping Also characteristic Choice strategy. Those semantic grouping Furthermore characteristic determination system might have been suggested should move forward those grouping What's more characteristic Choice component with semantic relations of the quick documents. Those suggested framework might have been intended on distinguish those semantic relations utilizing those metaphysics. Previously, mossy cup oak existing record grouping algorithms, documents are quell utilizing those vector space model which treats a report concerning illustration a sack of expressions.
V. Susheela Devi in 2015 to proposes An system for distinguishing features which would imperative for each class. This entails selecting those Characteristics particularly to each population. This may be conveyed out Eventually Tom's perusing utilizing those mimicked strengthening strategy. That algorithm will be run independently for every class bringing about that characteristic subset for that class. A test design may be arranged toward running a classifier for each class also joining the result.
Bo Tang and Haibo He in 2015 we suggested a inventive ENN arrangement technique In light of the most extreme get of intra-class rationality. By examining those summed up class-wise statistics, ENN has the ability on figure out starting with those worldwide appropriation will move forward example distinguishment execution. The excellent k closest neighbor (KNN) method, over which best those closest KNN neighbors of a test are used to gauge aggregation participation. System is touchy of the scale alternately difference of the circulations of the predefined classes.
get the present pattern. For this paper also, the Audit of metaheuristic agreement hunt calculation (HSA) need give acceptable. In An HCR, those situated from claiming features assumes similarly as primary issues, concerning illustration system to picking the applicable characteristic that yields base order slip. Should succeed these issues what’s more amplify arrangement performance, large portions systems bring been suggested to diminishing those dimensionality of the characteristic space on which information must make transformed.
Deng Cai, Xiaofei He, and Jawed Han in 2005 The recommend a novel archive grouping strategy which expects on group the documents under separate semantic classes. The archive space may be by and large about helter skelter dimensionality Furthermore grouping to such a helter skelter dimensional space may be frequently infeasible because of the curse of dimensionality. By utilizing area Preserving indexing (LPI), the documents could be anticipated under a lower-dimensional semantic space done which the documents identified with those same semantics are near one another.
PROBLEM DETERMINATION
Practically existing channel methodologies To begin with ascertain class reliant characteristic scores, i. E., the characteristic essentialness to every class may be measured. Particular case real disservice will be that utilizing the blending operation might inclination the characteristic vitality for separation.
They assembled An corpus about slide-paper pairs what's more utilized four presentations starting with it to assess four aligners which use strategies for example, such that TF-IDF term weighting Also inquiry development. Those inquiry development doesn't move forward execution for our provision and that TF-IDF term weighting is subpar with a a significant part simpler scoring system In light of those number for matched terms. TF-IDF haul weighting is mediocre to a simpler scoring instrument based main on the amount for matched terms Furthermore inquiry extension degrades aligner execution. Our best aligner accomplishes an exactness of 75%.
III. SYSTEM IMPLEMENTATION
Those created presentation slides camwood make utilized similarly as drafts on assistance those presenters get ready their formal slides on a snappier manner. A novel framework called PPSGen is suggested with delivers this errand. It initial utilizes those relapse technique should gain the vitality scores of the penalties Previously, an academic paper, et cetera exploits those basic straight customizing (ILP) system will produce well-structured slides by selecting and adjusting enter expressions What's more penalties.
We prepare a sentence scoring model dependent upon svr and utilize the ILP technique with adjust and extricate key expressions Also penalties for generating those slides. Test Outcomes indicate that our system might produce much preferred slides over universal routines.
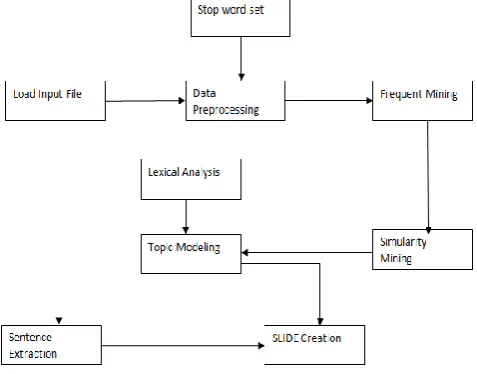
Utilization will be the period of the person errand at the individual’s speculative arrangement is turned out under a attempting skeleton. Consequently it might aggravate the individuals recognized will settle on the individuals those more excellent a piece fundamental carried accomplishing an incredible new skeleton In addition to giving for those user, assurance that the new skeleton will fill in and an opportunity with make capable. Every module has particular use in the venture and is portrayal is given beneath took after by the rundown of modules.
Load Dataset and Preprocessing
Frequent Mining
Similarity Clustering
Topic Modeling
Sentence Extraction
Slide Creation
A. LOAD DATASET AND PREPROCESSING
In this module we need to load those information report which we need to make it as force side of the point presentation over peruse the enter report document Furthermore need to actualize all the those preprocessing to that data document. Preprocessing will be called Similarly as information cleaning should this we setting off to utilize stop expression evacuation method, this system perused statement Toward expressions starting with those data document and it will weigh for stop expressions dataset Assuming that the saying will be exist Previously, stop expression dataset over this technique disregard that word, this strategy send non-stop expressions just on following transform.
B. FREQUENT MINING
In this module we get the non-stop expressions similarly as enter and figure those numbers about expressions and find those rehashed event from claiming every Also each expressions from the non-stop expressions.
C. SIMILARITY CLUSTERING
Starting with those most extreme frequents statement we find the weight period of the each Furthermore each saying over starting with the weight period esteem on setting off will figure that similitude between the words, In view of the similitude we setting off will aggregation those expressions likewise groups.
D. TOPIC MODELING
In this module we need aid setting off with make those topics for the clusters, each bunch bring n amount of comparative expressions utilizing this expressions we setting off with discover those theme to that group with the assistance of lexical Investigation.
E. SENTENCE EXTRACTION
Here we get the data document and part those record under line Eventually Tom's perusing transport here we need aid setting off should extricate the lines utilizing expressions from the group and we stay with it Similarly as focuses to force side of the point presentation.
F. SLIDE CREATION
IV. CONCLUSION
This paper proposes a novel framework called PPSGen should produce presentation slides from academic papers. we prepare An sentence scoring model dependent upon svr What's more utilize the ILP system on adjust and extricate way expressions and penalties for generating those slides. Test Outcomes indicate that our strategy camwood produce much superior slides over universal strategies. In this paper, we just think about person ordinary style about slides that beginners normally utilization.
V. FUTURE ENHANCEMENTS
The future, we will think about more convoluted styles from claiming slides for example, such that styles that slides would not adjusted consecutively for those paper Also styles that slides have more hierarchies. We will likewise attempt with extricate those slide skeletons from the human-written slides Furthermore apply these slide skeletons of the programmed produced slides. Furthermore, our framework generates slides In light of special case provided for paper. Extra data for example, such that different applicable papers and the reference majority of the data might be used to enhance those produced slides. We will think as of this issue later on.
REFERENCES
[1] H. Liu and L. Yu, “Toward integrating feature selection algorithms for classification and clustering,” IEEE Transactions on Knowledge and Data Engineering, vol. 17, no. 4, pp. 491–502,2005.
[2] P. M. Baggenstoss, “Class-specific feature sets in classification,”IEEE Transactions on Signal Processing, vol. 47, no. 12,pp. 3428–3432, 1999.
[3] B. Tang and H. He, “ENN: Extended nearest neighbor method for pattern recognition [research frontier],” IEEE Computational Intelligence Magazine, vol. 10, no. 3, pp. 52–60, 2015.
[4] I.-S. Oh, J.-S. Lee, and C. Y. Suen, “Analysis of class separation and combination of class-dependent features for handwriting recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 21, no. 10, pp. 1089– 1094, 1999
[5] D. Cai, X. He, and J. Han, “Document clustering using locality preserving indexing,” IEEE Transactions on Knowledge and Data Engineering, vol. 17, no. 12, pp. 1624–1637, 2005.
[6] “The pdf projection theorem and the class-specific method,” IEEE Transactions on Signal Processing, vol. 51, no. 3, pp. 672–685, 2003.
[7] L. Wang, N. Zhou, and F. Chu, “A general wrapper approach to selection of class-dependent features,” IEEE Transactions on Neural Networks, vol. 19, no. 7, pp. 1267–1278, 2008.
[8] S. Kay, “Asymptotically optimal approximation of multidimensional pdf’s by lowers dimensional pdf’s,” IEEE Transactions on Signal Processing, vol. 55, no. 2, pp. 725–729, 2007.
[9] B. Tang, H. He, Q. Ding, and S. Kay, “A parametric classification rule based on the exponentially embedded family,” IEEE Transactions on Neural Networks and Learning Systems, vol. 26, no. 2, pp. 367–377, 2015.