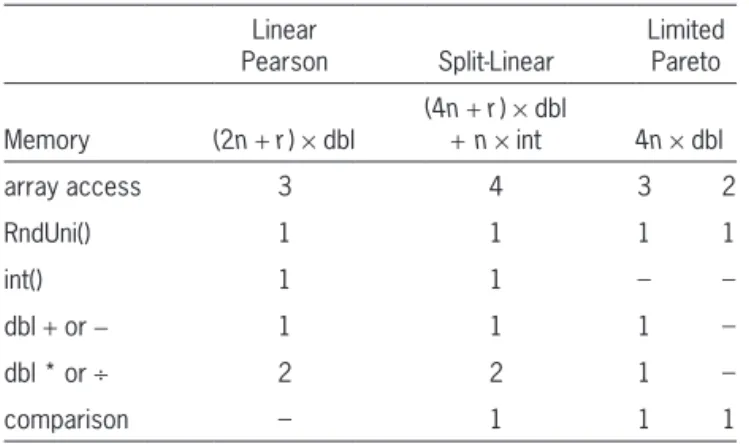
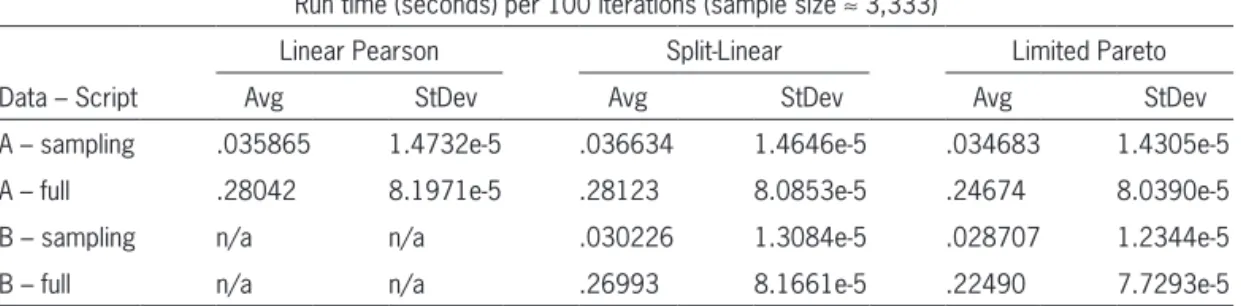
CAS: A Comparison of Resampling Methods for Bootstrapping Triangle GLMs
Full text
Figure

Related documents
Keywords: Intimate partner violence, Lesbian, Non-physical forms of abuse, Queer... Intimate partner violence (IPV) is a term that refers to something much
Our study aim is to evaluate changes in the team climate of surgical teams, associated with the introduc- tion of the perioperative briefings and debriefing in the operating
This result may be explained because Nurses and allied health professionals and Nonmedical support staff were the larger groups (46% and 23%, respectively, of the total sample)
The functional complementation of the mutant strain with only the ABC transporter also restored the growth on cellulose, although the final protein content at the stationary phase
The Collection Interface boolean add(Object o) boolean addAll(Collection c) void clear() boolean contains(Object o) boolean containsAll(Collection c) boolean
Japan’s universal health insurance system is composed of four main insurance systems, i.e., community health insurance for the self-employed and unemployed (National Health
These spectra along with literature spectra can aid assignment of a radical species residing on the cross-linked Tyr-His structure in the P M (associated radical)
While weight gain, relative breast weight, and relative abdominal fat pad weight were maintained across diets, average adipocyte size was decreased (P < 0.0001) by feeding the
