Detection of Internet Scam Using Logistic Regression
Full text
Figure
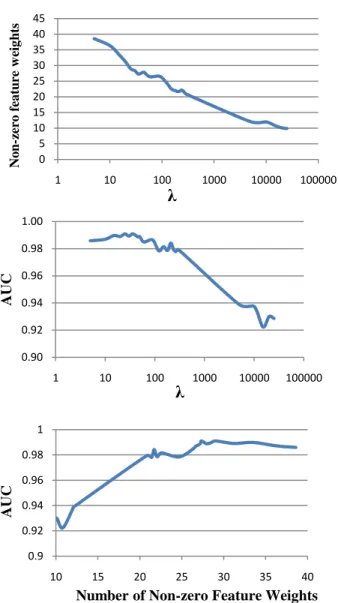
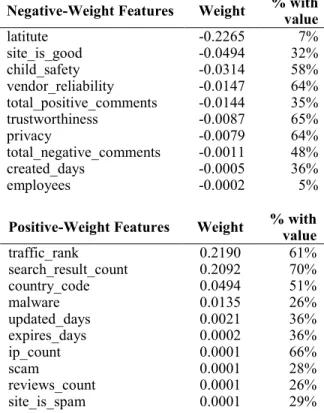
Related documents
1) The increase in the NRA from 65 in (and be- fore) 2002 to 67 in (and after) 2025. The reduction in benefi ts is based on the number of months of entitle- ment prior to the month
Offer activities and shows that allow us to monitor the maximum capacity of the area and make it easy to maintain a 2 meters distance from others.. The correct and constant
1 Improved window energy efficiency calculated in a computer simulation using RESFEN 5.0 default parameters for a 2,000-square-foot existing single-story home when comparing a
Using our Balance Transfer Authorization Form found on our VISA ® applications, transfer your high-rate credit card balances to our no-annual-fee, low-fixed-rate VISA ®
Telephone Services Unlimited sales staff and technicians are certified in all facets of the ESI, Comdial, and Key Voice product lines, including key and PBX telecommunications
Guided by the United Nations Sustainability Goals, FROEBEL constantly strives to provide early learning services which acknowledge and promote active participation in long
Parents and students will obtain the student’s individual class schedule at orientation and via FOCUS approximately one week prior to the start of school.. During orientation,
‘I thought “here goes” and we’ll just leave it at that … I should have, but I thought they might make you go onto another thing that costs more.’ This borrower said that
