A Characterization Study of Arabic Twitter Data with a Benchmarking
for State-of-the-Art Opinion Mining Models
Ramy Baly,1 Gilbert Badaro,1 Georges El-Khoury,1 Rawan Moukalled,1 Rita Aoun,1
Hazem Hajj,1 Wassim El-Hajj,2 Nizar Habash,3 Khaled Bashir Shaban4 1Department of Electrical and Computer Engineering, American University of Beirut
2 Department of Computer Science, American University of Beirut
3Computational Approaches to Modeling Language Lab, New York University Abu Dhabi 4 Department of Computer Science, Qatar University
{rgb15,ggb05,gbe03,rrm32,rra47}@mail.aub.edu {hh63,we07}@aub.edu.lb, [email protected]
Abstract
Opinion mining in Arabic is a challeng-ing task given the rich morphology of the language. The task becomes more challenging when it is applied to Twitter data, which contains additional sources of noise, such as the use of unstan-dardized dialectal variations, the non-conformation to grammatical rules, the use of Arabizi and code-switching, and the use of non-text objects such as im-ages and URLs to express opinion. In this paper, we perform an analytical study to observe how such linguistic phenom-ena vary across different Arab regions. This study of Arabic Twitter character-ization aims at providing better under-standing of Arabic Tweets, and foster-ing advanced research on the topic. Fur-thermore, we explore the performance of the two schools of machine learn-ing on Arabic Twitter, namely the fea-ture engineering approach and the deep learning approach. We consider mod-els that have achieved state-of-the-art per-formance for opinion mining in English. Results highlight the advantages of us-ing deep learnus-ing-based models, and con-firm the importance of using morphologi-cal abstractions to address Arabic’s com-plex morphology.
1 Introduction
Opinion mining, or sentiment analysis, aims at au-tomatically extract subjectivity information from
text (Turney, 2002) whether at sentence or docu-ment level (Farra et al., 2010). This task has at-tracted a lot of researchers in the last decade due to the wide range of real world applications that are interested in harvesting public opinion in dif-ferent domains such as politics, stock markets and marketing.
Huge amounts of opinion data are generated, on a daily basis, in many forums, personal blogs and social networking websites. In particular, Twitter is one of the most used social media platforms, where users generally express their opinions on everything from music to movies to politics and all sort of trending topics (Sareah, 2015). Further-more, Arabic language is the5thmost-spoken
lan-guage worldwide (UNESCO, 2014), and has re-cently become a key source of the Internet content with a 6,600% growth in number of users com-pared to the year 2000 (Stats, 2016). Therefore, developing accurate opinion mining models for Arabic tweets is a timely and intriguing problem that is worth investigating.
However, applying Natural Language Process-ing (NLP) and learnProcess-ing opinion models for Arabic Twitter data is not straightforward due to several reasons. Tweets contain large variations of un-standardized dialectal Arabic (DA), in addition to significant amounts of misspellings and grammat-ical errors, mainly due to their length restriction. They also contain “Arabizi”, where Arabic words are written using Latin characters. Due to the cul-tural diversity across the Arab world, an opinion model that is developed for tweets in one region may not be applicable to extract opinions from tweets in another region. Finally, tweets usually contain special tokens such as hashtags, mentions, multimedia objects and URLs that need to be
dled appropriately, in order to make use of the sub-jective information they may implicitly carry.
In this paper, we present a characterization study of Twitter data collected from different Arab regions, namely Egypt, the Levant and the Arab Gulf. This study illustrates how the discussed topics, the writing style and other linguistic phe-nomena, vary significantly from one region to an-other, reflecting different usages of Twitter around the Arab world. We also evaluate the model that ranked first at SemEval-2016 Task 4 (Nakov et al., 2016) on “Sentiment Analysis in Twitter”. This model is developed for opinion mining in English, and uses feature engineering to extract surface, syntactic, semantic and Twitter-specific features. Therefore, we extract an equivalent feature set for Arabic to train a model for opinion mining in Ara-bic tweets. We compare this model to another class of models that are based on deep learning techniques. In particular, we use recursive deep models that achieved high performances (Socher et al., 2013; Tai et al., 2015). Experimental results show the advantage of deep learning at learning subjectivity in Arabic tweets without the need for artificial features that describe the properties and characteristics of Twitter data.
The rest of this paper is organized as follows. Section 2 describes previous work on opinion min-ing with particular focus on application to Twitter data. Section 3 presents the characterization study and highlights distinctive characteristics of tweets collected from different Arab regions. Section 4 describes the opinion models that we evaluate in this paper, and experimental results are presented in Section 5. Conclusion is provided in Section 6.
2 Related Work
Opinion Mining models for Arabic are gener-ally developed by training machine learning clas-sifiers using different types of features. The most common features are the wordngrams fea-tures that were used to train Support Vector Ma-chines (SVM) (Rushdi-Saleh et al., 2011; Aly and Atiya, ; Shoukry and Rafea, 2012), Na¨ıve Bayes (Mountassir et al., 2012; Elawady et al., 2014) and ensemble classifiers (Omar et al., 2013). Word ngrams were also used along with syntac-tic features (root and part-of-speechn-grams) and stylistic (letter and digit ngrams, word length, etc.). These features performed well after reduc-tion via the Entropy-Weighted Genetic Algorithm
(EWGA) (Abbasi et al., 2008). Sentiment lexicons also provided an additional source of features that proved useful for the task (Abdul-Mageed et al., 2011; Badaro et al., 2014; Badaro et al., 2015).
Many efforts have been made to develop opin-ion models for Arabic Twitter data and creat-ing annotated Twitter corpora (Al Zaatari et al., 2016). A framework was developed to han-dle tweets containing Modern Standard Arabic (MSA), Jordanian dialects, Arabizi and emoti-cons, by training different classifiers under dif-ferent features settings of such linguistic phe-nomena (Duwairi et al., 2014). A distant-based approach showed improvement over exist-ing fully-supervised models for subjectivity clas-sification (Refaee and Rieser, 2014a). A subjectiv-ity and sentiment analysis (SSA) system for Ara-bic tweets used a feature set that includes differ-ent forms of the word (lexemes and lemmas), POS tags, presence of polar adjectives, writing style (MSA or DA), and genre-specific features includ-ing the user’s gender and ID (Abdul-Mageed et al., 2014). Machine translation was used to ap-ply existing state-of-the-art models for English to translations of Arabic tweets. Despite slight accu-racy drop caused by translation errors, these mod-els are still considered efficient and effective, es-pecially for low-resource languages (Refaee and Rieser, 2014b; Salameh et al., 2015).
A new class of machine learning models based on deep learning have recently emerged. These models achieved high performances in both Ara-bic and English, such as the Recursive Auto En-coders (RAE) (Socher et al., 2011; Al Sallab et al., 2015), the Recursive Neural Tensor Networks (RNTN) (Socher et al., 2013) and Generalized Re-gression Neural Networks (GRNN) (Hobeica et al., 2011; Baly et al., 2016).
3 Arabic Tweets Characterization
Developing opinion mining models requires un-derstanding the different characteristics of the texts that they will be applied to. For instance, dealing with reviews requires different features and methods compared to comments or tweets, as each of these types have their own characteris-tics. Furthermore, when dealing with Arabic data, it is important to appreciate the rich cultural and linguistic diversity across the Arab region, which may translate into different challenges that need to be addressed during model development. First, we describe the general features of Twitter data, and then we present an analysis of three sets of tweets collected from main Arab regions: Egypt, the Arab Gulf and the Levant.
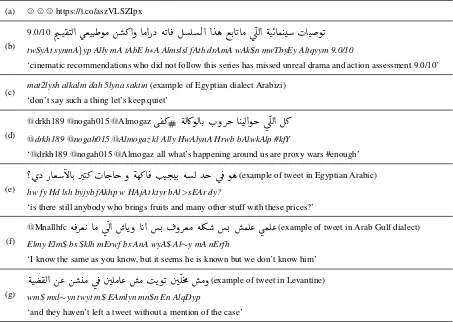
Twitter is a micro-blogging website where peo-ple share messages that have a maximum length of 140 characters. Despite their small size, the tweets’ contents are quite diverse and can be made up of text, emoticons, URLs, pictures and videos that are internally mapped into automat-ically shortened URLs, as in Table 1, example (a). Users tend to use informal styles of writ-ing to reduce the length of the text while it can still be interpreted by others. Consequently, Twit-ter data become noisy as they contain significant amounts of misspellings, and do not necessarily follow the grammatical structure of the language, as shown in Table 1, example (b). Arabizi and code-switching are frequently used and observed in tweets, as shown in Table 1, example (c). Hash-tags are very common and are used to highlight keywords, to track trending topics or events, to promote products and services, and for other per-sonal purposes including fun and sarcasm. Also, “user mentions” are quite common and have dif-ferent usages including tagging users in tweets to start a conversation, replying to someone’s tweet and giving credit for some media or source. Ta-ble 1, example (d) shows how hashtags and men-tions are used in Tweets. Finally, users can react to a tweet in three different ways, either using (1) “Like” by pressing the heart button, (2) “Reply” by mentioning the author and typing their com-ment in a new tweet, or (3) “Re-Tweet” by sharing it to their own followers.
We manually analyzed three sets of tweets that were retrieved from Egypt, the Arab Gulf and the Levant, using the Twitter4J API (Yamamoto, 2014). We refer to these sets of tweets as “EGY”,
“GULF” and “LEV”, respectively, where each set contains 610 tweets. Examples of tweets written in each of the region’s dialect are shown in Table 1, examples (e,f and g). We did not use a specific query as a keyword, in order to retrieve tweets cov-ering the different topics being discussed in each region. We also did not use the API’s language filter, in order to retrieve tweets that may be writ-ten in Arabizi. For each set, one of the authors analyzed the used languages, the discussed topics and the presence of emoticons, sarcasm, hashtags, mentions and elongation.
[image:3.595.324.509.303.422.2]Table 2 shows the distribution of the different topics in each set. Table 3 shows the different writ-ing styles and languages that are used in each set. Table 4 illustrates, for each set, the percentage of tweets that contain special Twitter tokens.
[image:3.595.319.513.466.573.2]EGY LEV GULF Religion 20.0% 22.3% 32.1% Personal 35.1% 58.9% 50.5% Politics 3.6% 5.3% 4.4% Sports 0.3% 6.9% 1.3% Other news 2.9% 1.6% 1.9% Spam 8.5% 3.4% 5.6% Foreign 29.5% 1.6% 4.1%
Table 2: Topics discussed in each set.
LEV EGY GULF MSA 28.5% 40.7% 55.7% Local dialect 18.4% 31.5% 28.5% Arabizi 0.7% 1.9% 0.0% English 13.4% 7.2% 4.1% Foreign 31.8% 1.6% 4.4% N/A 7.2% 7.1% 7.2%
Table 3: Languages and writing styles in each set.
Special tokens EGY LEV GULF User mentions 17.1% 31.6% 34.6% Hashtags 7.5% 13.4% 13.7% Emoticons 20.3% 30.9% 25.6% Elongation 2.6% 8.2% 3.3%
Table 4: Use of special Twitter tokens in each set.
(a) / / /https://t.co/aszVLSZIpx
(b)
9.0/10
ÕæJ®JË@ ùªJJ.£ñÓ á »@ð AÓ@PX éKA ¯ ÉÊÖÏ@ @
Yë ©K.AKAÓ ú
ÎË@ éJKAÒ J HAJñK
twSyAt synmA}yp Ally mA tAbE h∗A Almslsl fAth drAmA wAk$n mwTbyEy Altqyym 9.0/10‘cinematic recommendations who did not follow this series has missed unreal drama and action assessment 9.0/10’
(c) mat2lysh alkalm dah 5lyna saktin(example of Egyptian dialect Arabizi) ‘don’t say such a thing let’s keep quiet’
(d)
@drkh189@nogah015@Almogaz
ù ®»# éËA¿ñËAK. H.ðQk A JJË@ñk ú
ÎË@ É¿
@drkh189@nogah015@Almogaz kl Ally HwAlynA Hrwb bAlwkAlp #kfY‘@drkh189@nogah015@Almogaz all what’s happening around us are proxy wars #enough’
(e)
?øX PAª
BAK. QJ» HAg.Ag ð éê»A ¯ I.Jj.K. éË Yg ú ¯ ñë
(example of tweet in Egyptian Arabic) hw fy Hd lsh byjyb fAkhp w HAjAt ktyr bAl>sEAr dy?
‘is there still anybody who brings fruits and many other stuff with these prices?’
(f)
@Mnallhfc
é ¯Qª K AÓ ú
Í@ AKð A K@ . ¬ðQªÓ éʾ . ÒÊ« ù
ÒÊ«
(example of tweet in Arab Gulf dialect) Elmy Elm$bs$klh mErwf bs AnA wyA$Al∼y mA nErfh‘I know the same as you know, but it seems he is known but we don’t know him’
(g)
éJ ®Ë@ á« á Ó ú ¯ áÊÓA« Ó IKñK áÊ m× Óð
(example of tweet in Levantine) wm$mxl∼yn twyt m$EAmlyn mn$n En AlqDyp
[image:4.595.73.526.63.385.2]‘and they haven’t left a tweet without a mention of the case’
Table 1: Samples of tweets, with their English translations and transliterations2, highlighting the different
linguistic phenomena that can be observed in Twitter data.
sets, a significant amount of these tweets discuss religious topics. It can also be observed that Ara-bizi and code switching do not appear, and that tweets written in English are rare. Regarding the “EGY” set, MSA is less common compared to “GULF”, and a significant number of tweets are written using Egyptian Arabic. Most of the tweets discuss personal matters (nearly 59%). Also, Ara-bizi and code switching are rarely used. Finally, emoticons and user mentions are more frequently used compared to the other sets. As for the “LEV” set, it can be observed that both MSA and DA are used less than the other sets. Most of these tweets discuss personal matter, while religious topics are less discussed. A significant portion of the tweets are written in English, and many are written in for-eign languages that pertain to neighboring coun-tries (e.g., Cyprus and Turkey). Finally, it can be observed that elongation (letter repetition) is not common in the collected sets of tweets, and that Arabizi and code switching are infrequent as well.
This analysis confirms that Twitter is used differently (different characteristics, features and
topics), across the Arab world. This implies that different opinion models are needed to account for the peculiarities of each region’s tweets.
4 Opinion Mining Models
In this section, we describe two models that achieved state-of-the-art performances in opinion mining. The first model won the SemEval-2016 Task 4 on “Sentiment Analysis in Twitter” (En-glish), and uses feature engineering to train an opinion classifier (Balikas and Amini, 2016). The second model is based on modeling composition-ality using deep learning techniques (Socher et al., 2013). In this paper, we evaluate these models for opinion mining in Arabic tweets.
4.1 Opinion Mining with Feature Engineering
set of features that we extracted to train a similar model for opinion mining in Arabic tweets.
• Charactern-grams;n∈[3,5].
• Word n-grams; n ∈ [1,4]. To account for the complexity and sparsity of Arabic lan-guage, we extract lemman-grams since lem-mas have better generalization capabilities than raw words (Habash, 2010).
• Counts of exclamation marks, question marks, and both exclamation and question marks.
• Count of elongated words.
• Count of negated contexts, defined by phrases that occur between a negation parti-cle and the next punctuation.
• Counts of positive emoticons and negative emoticons, in addition to a binary feature in-dicating if emoticons exist in a given tweet.
• Counts of each part-of-speech (POS) tag in the tweet.
• Counts of positive and negative words based on ArSenL (Badaro et al., 2014), AraSenti (Al-Twairesh et al., 2016) and ADHL (Mohammad et al., 2016) lexicons. We also add to this set the two binary features indicating the presence of user mentions and URL or media content. Many of these features align with the factors that we single out in the charac-terization study presented in Section 3.
4.2 Opinion Mining with Recursive Neural Networks
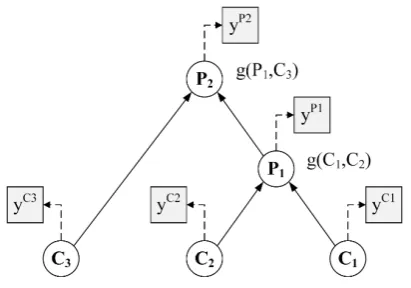
[image:5.595.313.519.65.209.2]Most deep learning models for opinion mining are based on the concept of compositionality, where the meaning of a text can be described as a func-tion of the meanings of its parts and the rules by which they are combined (Mitchell and La-pata, 2010). In particular, the Recursive Neu-ral Tensor Networks (RNTN) model has proven successful for opinion mining in English (Socher et al., 2013). Figure 1 illustrates the application of a RNTN to predict the sentiment of a three-word sentence{C1, C2, C3}, where words are rep-resented with vectors that capture distributional syntactic and semantic properties (Bengio et al., 2003; Collobert and Weston, 2008; Mikolov et al.,
Figure 1: The application of RNTN for opinion prediction in a three-word sentence.
2013). Each sentence is represented in the form of a binary parse tree. Then, at each node of the tree, a tensor-based composition function combines the child nodes’ vectors (e.g., C1, C2) and produces the parent node’s vector (e.g., P1). This process repeats recursively until it derives a vector for each node Ci in the tree, including the root node that
corresponds to the whole sentence. These vectors are then used to train a softmax classifier to pre-dict the opinion distributionyCi ∈RKfor the text represented by theithnode, whereK is the
num-ber of opinion classes. Further details are available in (Socher et al., 2013).
Training a RNTN model requires a sentiment treebank; a collection of parse trees with sen-timent annotations at all levels of constituency. For English, the Stanford sentiment treebank was developed to train the RNTN (Socher et al., 2013). For Arabic, we developed the Arabic Senti-ment Treebank (ArSenTB) by annotating∼123K constituents pertaining to 1,177 comments ex-tracted from the Qatar Arabic Language Bank (QALB) (Zaghouani et al., 2014).
5 Experiments and Results
In this section, we evaluate the performance of the feature engineering and deep learning-based mod-els for opinion mining in Arabic tweets. We fo-cus on the task of three-way opinion classification, where each tweet should be classified as positive, negative or neutral.
5.1 Dataset and Preprocessing
Twit-ter accounts. These tweets are annotated with four labels: positive (799), negative (1,684), neutral (832) and objective (6,691). Due to the highly skewed distribution of the classes, and since our focus is to perform opinion classification rather than subjectivity classification, we excluded the objective tweets, reducing the size of the data to 3,315 tweets with reasonable class distribution: 24% (positive), 51% (negative) and 25% (neutral). This data is split into a train set (70%), a develop-ment set (10%) and a test set (20%).
Each tweet is preprocessed by (1) replacing user mentions and URLs with special “global” to-kens, (2) extracting emoticons and emojis using the “emoji” java library (Vdurmont, 2016) and replacing them with special tokens (for this we used the emojis sentiment lexicon from (Novak et al., 2015), and prepared our own emoticons lex-icon), (3) normalizing hashtags by removing the “#” symbol and the underscores that are used to separate words in composite hashtags, and (4) nor-malizing word elongations (letter repetitions).
To extract features for the SVM classifier, we performed lemmatization and POS tagging us-ing MADAMIRA v2.1, the state-of-the-art mor-phological analyzer and disambiguator in bic (Pasha et al., 2014), that uses the Standard Ara-bic Morphological Analyzer (SAMA) (Maamouri et al., 2010). Since the evaluation corpus is in Egyptian Arabic, we used MADAMIRA in the Egyptian mode. It is worth noting that some recent efforts have added Levantine to MADAMIRA, but it is not public yet (Eskander et al., 2016).
5.2 Experimental Setting
We only includedn-grams that occurred more than a pre-defined thresholdt, wheret∈[3,5]. Prelim-inary experiments showed that using the radial ba-sis function (RBF) kernel is better than using the linear kernel. We used the development set to tune the model’s parameters, namely the cost of mis-classification andγ the width of the kernel, Then, the model with the parameters that achieved the best results is applied to the unseen test set.
As for the RNTN model, we generated word embeddings of size 25 by training the skip-gram embedding model (Mikolov et al., 2013) on the QALB corpus, which contains nearly 500K sen-tences. We train RNTN using ArSenTB, and then apply the trained model to perform opinion clas-sification in tweets. We alleviate the impact of
sparsity by training RNTN using lemmas, which is similar to our choice of training SVM using lemman-grams.
Finally, the different models are evaluated us-ing accuracy and the F1-score averaged across the different classes.
[image:6.595.315.515.393.499.2]5.3 Results
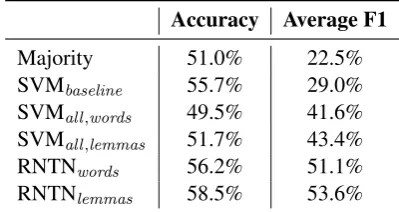
Table 5 illustrates the performances achieved with the state-of-the-art models in feature en-gineering (SVMall,lemmas) and deep learning
(RNTNlemmas). We compare to the following
baselines: (1) the majority baseline that auto-matically assigns the most frequent class in the train set, and (2) the SVM trained with word n -grams (SVMbaseline), which has been a common
approach in the Arabic opinion mining literature. To emphasize the impact of lemmatization, we include the results of SVM trained with features from (Balikas and Amini, 2016) and using word instead of lemma n-grams (SVMall,words). We
also include the results of RNTN trained with raw words (RNTNwords).
Accuracy Average F1
Majority 51.0% 22.5%
SVMbaseline 55.7% 29.0%
SVMall,words 49.5% 41.6%
SVMall,lemmas 51.7% 43.4%
RNTNwords 56.2% 51.1%
RNTNlemmas 58.5% 53.6%
Table 5: Performance of the different models for opinion mining, evaluated on the ASTD dataset.
6 Conclusion
In this paper, we described the main challenges of processing Arabic language in Twitter data. We presented a characterization study that analyzes tweets collected from different Arab regions in-cluding Egypt, the Arab Gulf and the Levant. We showed that Twitter have different usages across these regions.
We report the performance of two state-of-the-art models for opinion mining. Experimental re-sults indicate the advantage of using deep learn-ing models over feature engineerlearn-ing models, as the RNTN achieved better performances although it was trained using a non-Twitter corpus. Re-sults also indicate the importance of lemmatiza-tion at handling the complexity and lexical spar-sity of Arabic language.
Future work will include evaluating opinion mining models on tweets from different Arab re-gions and covering different topics. Also, we in-tend to apply an automatic approach for analyz-ing tweet characteristics instead of the manual ap-proach. We will exploit existing tools and re-sources for automatic identification of dialects in tweets.
We aim to perform cross-region evaluations to confirm whether different opinion models are needed for different regions and dialects, or a gen-eral model can work for any tweet regardless of its origins. This effort involves the collection and annotation of Twitter corpora for the different re-gions analyzed above.
Acknowledgments
This work was made possible by NPRP 6-716-1-138 grant from the Qatar National Research Fund (a member of Qatar Foundation). The statements made herein are solely the responsibility of the au-thors.
References
Ahmed Abbasi, Hsinchun Chen, and Arab Salem. 2008. Sentiment analysis in multiple languages: Feature selection for opinion classification in web
forums. ACM Transactions on Information Systems
(TOIS), 26(3):12.
Muhammad Abdul-Mageed, Mona T. Diab, and Mo-hammed Korayem. 2011. Subjectivity and
senti-ment analysis of modern standard arabic. In
Pro-ceedings of the 49th Annual Meeting of the Associ-ation for ComputAssoci-ational Linguistics: Human
Lan-guage Technologies: short papers-Volume 2, pages 587–591. Association for Computational Linguis-tics.
Muhammad Abdul-Mageed, Mona Diab, and Sandra K¨ubler. 2014. Samar: Subjectivity and sentiment
analysis for arabic social media. Computer Speech
& Language, 28(1):20–37.
Ahmad A. Al Sallab, Ramy Baly, Gilbert Badaro, Hazem Hajj, Wassim El Hajj, and Khaled B. Shaban. 2015. Deep learning models for sentiment analysis
in arabic. InANLP Workshop 2015, page 9.
Nora Al-Twairesh, Hend Al-Khalifa, and AbdulMalik Al-Salman. 2016. Arasenti: Large-scale
twitter-specific arabic sentiment lexicons. Proceedings of
the 54th Annual Meeting of the Association for Com-putational Linguistics, pages 697–705.
Ayman Al Zaatari, Reem El Ballouli, Shady ELbas-souni, Wassim El-Hajj, Hazem Hajj, Khaled Bashir Shaban, and Nizar Habash. 2016. Arabic
cor-pora for credibility analysis. Proceedings of the
Language Resources and Evaluation Conference (LREC), pages 4396–4401.
Mohamed A. Aly and Amir F Atiya. Labr: A large scale arabic book reviews dataset.
Gilbert Badaro, Ramy Baly, Hazem Hajj, Nizar Habash, and Wassim El-Hajj. 2014. A large scale arabic sentiment lexicon for arabic opinion mining.
ANLP 2014, 165.
Gilbert Badaro, Ramy Baly, Rana Akel, Linda Fayad, Jeffrey Khairallah, Hazem Hajj, Wassim El-Hajj, and Khaled Bashir Shaban. 2015. A light lexicon-based mobile application for sentiment mining of
arabic tweets. InANLP Workshop 2015, page 18.
Georgios Balikas and Massih-Reza Amini. 2016.
Twise at semeval-2016 task 4: Twitter sentiment classification.arXiv preprint arXiv:1606.04351.
Ramy Baly, Roula Hobeica, Hazem Hajj, Wassim El-Hajj, Khaled Bashir Shaban, and Ahmad Al-Sallab. 2016. A meta-framework for modeling the human
reading process in sentiment analysis. ACM
Trans-actions on Information Systems (TOIS), 35(1):7.
Yoshua Bengio, R´ejean Ducharme, Pascal Vincent, and Christian Jauvin. 2003. A neural probabilistic lan-guage model. Journal of machine learning research, 3(Feb):1137–1155.
Ronan Collobert and Jason Weston. 2008. A unified architecture for natural language processing: Deep
neural networks with multitask learning. In
Pro-ceedings of the 25th international conference on Machine learning, pages 160–167. ACM.
2016. Swisscheese at semeval-2016 task 4: Sen-timent classification using an ensemble of convo-lutional neural networks with distant supervision.
Proceedings of SemEval, pages 1124–1128. RM Duwairi, Raed Marji, Narmeen Sha’ban, and Sally
Rushaidat. 2014. Sentiment analysis in arabic
tweets. InInformation and communication systems
(icics), 2014 5th international conference on, pages 1–6. IEEE.
Rasheed M. Elawady, Sherif Barakat, and Nora M. El-rashidy. 2014. Different feature selection for sen-timent classification. International Journal of In-formation Science and Intelligent System, 3(1):137– 150.
Ramy Eskander, Nizar Habash, Owen Rambow, and Arfath Pasha. 2016. Creating resources for dialec-tal arabic from a single annotation: A case study on
egyptian and levantine. InProceedings of COLING
2016, the 26th International Conference on Compu-tational Linguistics: Technical Papers, pages 3455– 3465, Osaka, Japan, December. The COLING 2016 Organizing Committee.
Noura Farra, Elie Challita, Rawad Abou Assi, and Hazem Hajj. 2010. Sentence-level and
document-level sentiment mining for arabic texts. In 2010
IEEE International Conference on Data Mining Workshops, pages 1114–1119. IEEE.
Nizar Y. Habash. 2010. Introduction to arabic natural
language processing. Synthesis Lectures on Human
Language Technologies, 3(1):1–187.
Roula Hobeica, Hazem Hajj, and Wassim El Hajj. 2011. Machine reading for notion-based sentiment
mining. InData Mining Workshops (ICDMW), 2011
IEEE 11th International Conference on, pages 75– 80. IEEE.
Mohamed Maamouri, Dave Graff, Basma Bouziri, Sondos Krouna, Ann Bies, and Seth Kulick. 2010. Standard arabic morphological analyzer (sama)
ver-sion 3.1. Linguistic Data Consortium, Catalog No.:
LDC2010L01.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S. Cor-rado, and Jeff Dean. 2013. Distributed representa-tions of words and phrases and their
compositional-ity. InAdvances in neural information processing
systems, pages 3111–3119.
Jeff Mitchell and Mirella Lapata. 2010. Composition in distributional models of semantics. Cognitive sci-ence, 34(8):1388–1429.
Saif M. Mohammad, Mohammad Salameh, and Svet-lana Kiritchenko. 2016. How translation alters sen-timent. J. Artif. Intell. Res.(JAIR), 55:95–130. Asmaa Mountassir, Houda Benbrahim, and Ilham
Berrada. 2012. An empirical study to address the problem of unbalanced data sets in sentiment
classification. In Systems, Man, and Cybernetics
(SMC), 2012 IEEE International Conference on, pages 3298–3303. IEEE.
Mahmoud Nabil, Mohamed A. Aly, and Amir F. Atiya. 2015. Astd: Arabic sentiment tweets dataset. In
EMNLP, pages 2515–2519.
Preslav Nakov, Alan Ritter, Sara Rosenthal, Fabrizio Sebastiani, and Veselin Stoyanov. 2016. Semeval-2016 task 4: Sentiment analysis in twitter. Proceed-ings of SemEval, pages 1–18.
Petra Kralj Novak, Jasmina Smailovi´c, Borut Sluban,
and Igor Mozetiˇc. 2015. Sentiment of emojis. PloS
one, 10(12):e0144296.
Nazlia Omar, Mohammed Albared, Adel Qasem Al-Shabi, and Tareq Al-Moslmi. 2013. Ensemble of classification algorithms for subjectivity and senti-ment analysis of arabic customers’ reviews. Interna-tional Journal of Advancements in Computing Tech-nology, 5(14):77.
Arfath Pasha, Mohamed Al-Badrashiny, Mona T. Diab, Ahmed El Kholy, Ramy Eskander, Nizar Habash, Manoj Pooleery, Owen Rambow, and Ryan Roth. 2014. Madamira: A fast, comprehensive tool for morphological analysis and disambiguation of
ara-bic. InLREC, volume 14, pages 1094–1101.
Eshrag Refaee and Verena Rieser. 2014a. Can we read emotions from a smiley face? emoticon-based dis-tant supervision for subjectivity and sentiment
anal-ysis of arabic twitter feeds. In 5th International
Workshop on Emotion, Social Signals, Sentiment and Linked Open Data, LREC.
Eshrag Refaee and Verena Rieser. 2014b. Subjec-tivity and sentiment analysis of arabic twitter feeds
with limited resources. InWorkshop on
Free/Open-Source Arabic Corpora and Corpora Processing Tools Workshop Programme, page 16.
Mohammed Rushdi-Saleh, M. Teresa Mart´ın-Valdivia, L. Alfonso Ure˜na-L´opez, and Jos´e M. Perea-Ortega.
2011. Oca: Opinion corpus for arabic. Journal of
the American Society for Information Science and Technology, 62(10):2045–2054.
Mohammad Salameh, Saif Mohammad, and Svetlana Kiritchenko. 2015. Sentiment after translation: A
case-study on arabic social media posts. In
HLT-NAACL, pages 767–777.
Faiza Sareah. 2015. Interesting statistics for the top 10 social media sites. Small Business Trends.
Amira Shoukry and Ahmed Rafea. 2012.
Sentence-level arabic sentiment analysis. In Collaboration
Technologies and Systems (CTS), 2012 International Conference on, pages 546–550. IEEE.
Richard Socher, Jeffrey Pennington, Eric H. Huang, Andrew Y. Ng, and Christopher D. Manning. 2011. Semi-supervised recursive autoencoders for
conference on empirical methods in natural lan-guage processing, pages 151–161. Association for Computational Linguistics.
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment
tree-bank. In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language
Process-ing, pages 1631–1642, Seattle, Washington, USA,
October. Association for Computational Linguistics.
Internet World Stats. 2016.
In-ternet world users by language.
http://www.internetworldstats.com/stats7.htm. Kai Sheng Tai, Richard Socher, and Christopher D.
Manning. 2015. Improved semantic representa-tions from tree-structured long short-term memory networks. arXiv preprint arXiv:1503.00075. Peter D. Turney. 2002. Thumbs up or thumbs down?:
semantic orientation applied to unsupervised classi-fication of reviews. InProceedings of the 40th an-nual meeting on association for computational lin-guistics, pages 417–424. Association for Computa-tional Linguistics.
UNESCO. 2014. World arabic language day.
http://bit.ly/2lwRFYt.
Vdurmont. 2016. The missing emoji library for java. https://github.com/vdurmont/emoji-java.
Yusuke Yamamoto. 2014. Twitter4j-a java library for the twitter api.
Wajdi Zaghouani, Behrang Mohit, Nizar Habash, Os-sama Obeid, Nadi Tomeh, Alla Rozovskaya, Noura Farra, Sarah Alkuhlani, and Kemal Oflazer. 2014. Large scale arabic error annotation: Guidelines and