International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
943
Loch-Ness: A Lock Free Method using Virtual Memory Page
Table Entry Mechanism
Sesha Kalyur
1, Dr. G. S. Nagaraja
21Research Scholar, 2Professor, CSE Department, RV College of Engineering, Mysore Road, R V Vidyanikethan Post,
Bangalore, Karnataka 560059
Abstract— Operating Systems have offered Locking as a
de-facto mechanism for mutual exclusion. Locks have enjoyed widespread use due to their simplicity. However the burden of protecting a critical section is left to the programmer. Programmer has to ensure that the Locks are created, acquired, released and destroyed after use. Incorrect use of Locks can lead to race conditions. In Multi-programming, parallel environments Locks are also a source of performance bottlenecks. Researchers have tried to find alternatives to Mutual Exclusion Locks. Some of these approaches target specific cases of mutual exclusion and cannot be used as a main stream method. Others are general in nature but are complex to implement. In this paper we present a Lock Free method that is general enough to work in all situations, uses existing technology that is well established and is efficient and simple to implement.
Keywords—Critical Section, Mutual Exclusion, Lock Free
Method, Virtual Memory, Page Table Entry, Snoopy Cache, Mutual Exclusion Lock, Semaphore, Monitor, Conditional Variable, Transactional Memory, Lock Free Algorithm
I. INTRODUCTION
Multi-programming and parallel environments involve sharing main memory between different tasks. A task could be a process or a thread. Sharing between processes involves multiple address spaces where as sharing between threads involves one address space. However the issues of Critical Sections and Mutual Exclusion remain the same in both cases. Memory Operations (reads and writes) of different tasks are happening in parallel that needs to be serialized. The overriding issue is how we can achieve Transaction Semantics. Operating Systems have offered Mutual Exclusion Locks as a solution to the problem [1]. Locks are simple and elegant to use. Programmer defines a Lock to protect a critical section of the code which can only be accessed by one task at a time in a multi-programmed environment. Before running code in the critical section, programmer acquires the lock and holds it for the duration he is in the critical section of the code. Other tasks arriving at the critical section of the code will block when they try to acquire the lock. Only when the current user of the critical section releases the lock, can one of the waiters enter the critical section.
Other waiters will have to wait for their turn. Thus the parallel tasks enter the critical section in a serialized way one after the other.
Locks require special instruction support for their implementation. Hardware normally provides the test-and-set or compare-and-swap instructions that read, test-and-set and read memory in one atomic instruction. There are also other atomic instructions but the idea remains the same.
Locks are mainly of two types, Spin Locks and Mutual Exclusion Locks. Spin Locks are simple where the tasks are spinning on the lock variable, meaning they don’t leave the CPU. They are constantly checking on the status (busy or free) of the lock. Mutual exclusion locks on the other hand have a queue associated with them where the waiters of the lock sleep until the lock is available.
There are other implementations of Locks such as Monitors, Semaphores and Condition Variables. There are minor differences between each but all of them achieve the same result.
While Locks are simple, they are also a source of errors and performance bottle-necks. Researchers have proposed alternatives to locks. Transactional Memory is one such approach [2] [3] [4]. Majority of them suffer from one or more of the following problems: not general purpose solutions [5], solutions hard to implement and in some cases not simple or elegant.
Incorrect use of Locks can lead to the following well known problems, Priority Inversion and Deadlocks. Priority Inversion can happen when a lower priority process holds the lock required by a higher priority process. Deadlocks can happen when a lock holder crashes without releasing the lock and there are one or more waiter(s) for the lock. Deadlocks can also happen when locks are acquired without paying attention to the order in which locks are acquired.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
944 We call our implementation Loch-Ness, and it is based on the well understood Virtual Memory structure, Page Table Entry for realizing it.
The rest of the paper is organized as follows. Section 2 gives some background information on the topic of Virtual Memory and Page Table Entry. Section 3 presents a survey of related literature on the subject of process synchronization. Section 4 dives deep in to the proposed Loch-Ness methodology. Section 5 concludes the paper summarizing the ideas presented here with some ideas for future work.
II. BACKGROUND
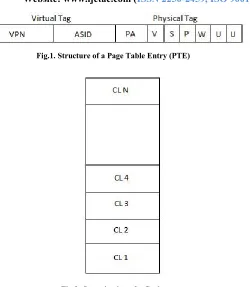
Page Table Entries (PTE) are an integral part of Virtual Memory implementation. Each Page Table Entry has information to translate a block (usually a page) of virtual addresses of a process to its corresponding physical addresses. Each Page table entry, besides storing the virtual and physical address also has a field to store other information such as the read and write permissions for the block. Additional bits in the field store information about the translation such as page size, process context (address space), etc. Usually PTE has some unused or reserved bits. We can use a bit here to indicate if the page needs to be synchronized. If set, it points to text or data that needs to be serialized, meaning two or more processes can access the page at the same time and only one should be allowed to proceed at a time.
Figure 1 shows the different fields of a Page Table Entry. The Virtual Page Tag has the information pertaining to the Virtual Page and the Physical Page Tag has the information pertaining to the actual Physical or Hardware page. Virtual Page number or address (VPN) identifies a page in the process address space. Address Space Identifier (ASID) or Context Number identifies a process address space. Physical address (PA) points to a hardware page. The V bit is set if the translation (PTE) is valid. The S points to a field that identifies the page size. The field marked P represents the bits that denote protection information. The W bit is set if the page is writable. The U indicates an unused bit which can be used to denote that the page is synchronized. The fields of PTE are specific to a particular architecture. So the actual PTE structure for a given machine may be somewhat different than what is shown here.
Computing systems these days invariably use multiple levels of caches to speed up memory accesses. The caches closest to memory are called external caches and those towards the CPU are called internal caches. These caches store most recently used text and data from memory. Accessing a cache is much faster than going to main memory for a page. Finding required information in the cache is called a cache hit and not finding the information in a cache, is referred to as a cache miss. On a cache miss it takes several cycles to retrieve the information from memory. Normally operating system schedulers will remove the process taking a miss from the CPU and replace it with a process that is ready to run. When the data arrives from main memory the replaced process is given the CPU back and is ready to run.
In a Multi-processing system each processor is connected to a hierarchy of caches before reaching main memory. Caches belonging to one processor are able to look in the caches of other processors to see if a data item is present or not. This process is normally referred to as snooping.
Figure 2 shows how a cache is organized. Each entry in the cache is called a cache line (CL) which includes the tag part and the data part. Their sizes are unique for a particular machine. For instance the data part could be 256 bytes long. Each transfer of data from memory to cache or cache to memory or cache to cache happens at the granularity of a cache line.
III. LITERATURE SURVEY
[6] [1] [7] [8] are good references on traditional locking methods. Borkowski et al. [6] present flexible synchronization primitives for the design and implementation of parallel programs. Raghunathan et al. [1] looks at extending the mutex and condition wait primitives from a robustness perspective. Ramamritham et al. [7] present SYSL a specification language for synchronization based on temporal logic. Wisniewski et al. [8] discuss spin lock extensions to improve performance in heavy contention situations.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
[image:3.612.55.305.126.413.2]945
Fig.1. Structure of a Page Table Entry (PTE)
Fig.2. Organization of a Cache
Herlihy et al. [11] discuss Instruction Set Architecture extensions to support Transactional Memory. McDonald et al. [12] explore supporting Transactional Memory at the architectural level. Moore et al. [13] present a Transactional Memory implementation that is based on transaction logs. Rajwar et al. [14] propose virtualization of Transactional Memory so that the hardware details and constraints are hidden from higher level software. Ramadhan et al. [15] present TXLinux, a Linux kernel modified to support Transactional Memory. Saha et al. [16] present HASTM. Hardware Assisted Software Transactional Memory by extending the IA32 ISA. [2] looks at the past, present and future of Software Transactional Memory.
[18] [19] [4] [20] [5] are very good papers on the subject of lock free algorithm techniques. Dragicevic et al. [18] survey the performance of Traditional Locking, Lock Free techniques and Software Transactional Memory schemes as applied to a priority queue. Huang et al. [19] present a parallel lock-free memory allocator that performs well in comparison to existing allocators. Prakash et al. [4] present a lock less implementation of a FIFO queue. Schellhorn et al. [20] presents KIV an interactive theorem prover for verification of lock free algorithms. Tsay et al. [5] looks at a lock free technique for processing tree structures.
Traditional locking has enjoyed a long reign as the de-facto mechanism for process synchronization. However the technique is innately error prone and burdensome for the user. Researchers have looked at alternatives that are simple and robust. Lock free algorithms and techniques have been proposed that work well in certain situations but are not general purpose solutions.
Transaction Memory is a lock free technique that has attracted a lot of attention from researchers recently. Similar techniques have been in use in the database area which are now applied to the field of process synchronization. Solutions have been proposed entirely in software and also in hardware. Software solutions are flexible but slow comparatively and hardware solutions are faster but are not without limits. Hybrid solutions have been proposed that bring forth the best of both hardware and software. Complexity for the user is still there in terms of learning the API calls for Software Transactional Memory and mastering ISA extensions for Hardware Transactional Memory. However, Transaction Memory is still an attractive and evolving research domain.
In this paper we propose Loch-Ness, a lock free alternative to traditional locking schemes. It is our belief that it reduces the chances of error and reduces the burden of managing critical sections from the user. User has to just identify the critical sections once. Entering and exiting the critical sections happen transparently without hints from the user.
IV. LOCK-NESS LOCK FREE METHOD
In the Loch-Ness Lock Free Method we present here, Data structures (Data Segment) and Code (Text Segment) are declared as synchronized. Identifying a data item or code as synchronized is the only step for the programmer. Such data or text is stored on a memory page tagged as synchronized. This information is stored in a bit in the Page Table Entry for the page. Any attempt to access such data or text, works only if none of the other caches in the system have already allocated the data. We make use of the Snooping ability of a Cache to achieve this. Otherwise such attempts will cause a Hardware Trap dedicated for this condition (say synchronized memory access) and the process trying to load the page is taken off the CPU. The process can try to load the page at a later time.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
946 Mutual exclusion of the critical section is thus achieved. The smallest region of memory marked as synchronized is a page whose size can vary across systems. The smallest block of memory enforcing a critical section is a cache line whose size is also system dependent.
The critical section involving data is treated a little differently than one involving text. For data, critical sections are created at the granularity of a cache line. So for a data structure of size 512 bytes, with a cache line size of 256 bytes will have two separate critical sections (two separate cache lines). Each of the cache lines can be allocated in caches belonging to separate processors at the same time.
For critical sections involving code, pre-emption is disallowed when executing in the critical section. So it is enough if the cache line containing the beginning or start of the block of code or procedure is in the cache. This cache line is locked down for the duration the process is in the critical section. Many commercial processors support the cache line locking feature.
When a processor is accessing synchronized code or data, the fact is recorded in Processor Status Word, a register in the CPU and is not pre-empted. When a process after using synchronized page relinquishes the CPU either voluntarily or involuntarily, the synchronized pages of the process are evicted from the cache. This gives processes on other caches a chance to access these pages. When a processor accesses a synchronized page and takes a cache miss, the page is loaded from main memory and the fact that it is using a synchronized page is recorded in the Processor Status Word.
Critical section can be at a process level where multiple threads of a process are trying. It could be at the global level between multiple processes. In this case, the page would be marked shared and synchronized.
Compiler can generate code to evict cache lines containing the beginning or start of synchronized procedure or block of code. During compilation, when the compiler encounters the end of the synchronized procedure or block of code, it generates assembly code to evict the cache line containing the start of procedure or code block. So managing the critical sections happens without user intervention and the resulting complexity is hidden from him.
How to achieve Fairness and avoid Infinite Starvation? A counter can be maintained in the process or thread structure that records the total number of failed attempts made by the process or thread to load synchronized data or text in the cache. Process Scheduler can take this count into account when waking up the waiting processes. So that processes with large counts (more failures) are scheduled first.
Since cache lines of code segment is locked down it works best if the cache is Set Associative meaning a particular data item can be allocated in multiple locations in the cache.
A data item allocated dynamically from the heap can also be marked as synchronized. So memory allocation function such as Malloc() in C and its variants would need modifications so that they can handle synchronized pages. Since stack pages are local to a process or thread and not shared, they are not considered further.
Interrupts from I/O devices can happen on a processor which is in the middle of executing synchronized code. There are two ways to handle this, ignore until the critical section of code is exited or pass it on to another processor that can handle it immediately.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
947 We have defined synchronized Data, Text and Heap segments. Stack is normally local to a task (process or thread) and is not used for sharing. So stack pages (as pointed out earlier) are not candidates for marking as synchronized.
Marking a data structure as synchronized allows Atomic Updates. Tagging code as synchronized lets one enforce Transaction Semantics. When running synchronized code, the task is ensured that it will not be pre-empted and taken off CPU. Process Status Word, a system register in the CPU can be used to track if the process is inside a critical section or not.
We have used C as the language of choice to present the method. But these concepts are applicable to any modern high level language such as C++ and Java. Implementing the method discussed here would require changes to the Operating System and the Compiler.
V. CONCLUSION
In this paper we presented a Lock Free Method that uses the well established Virtual Memory structures and techniques, mainly the Page Table Entry. The method also depends on the snooping ability of modern caches. The method totally removes the burden of managing a critical section from the programmer. Programmer has to just identify the Data and the Text that is shared once and is shielded from the underlying details of implementation. This method is error free and eliminates common programming errors associated with locking. The method is general purpose unlike some of the lock free techniques that work only in certain situations. It is different from the Transactional Memory approach, in the sense that it requires no user support in managing the APIs or ISA extensions.
Acknowledgments
The authors would like to thank Dr. G. S. Nagaraja and Dr. N. K. Srinath of R. V. College of Engineering for their valuable support and encouragement.
REFERENCES
[1] S. Raghunathan, “Extending inter-process synchronization with
robust mutex and variants in condition wait,” in Proceedings of the 2008 14th IEEE International Conference on Parallel and Distributed
Systems, 2008, pp. 121–128. [Online]. Available:
http://dx.doi.org/10.1109/ICPADS.2008.98
[2] N. Shavit, “Software transactional memory: Where do we come
from? what are we? where are we going?” in Proceedings of the 2009 IEEE International Symposium on Parallel&Distributed Processing, ser. IPDPS ’09, 2009, pp. 1–. [Online]. Available: http://dx.doi.org/10.1109/IPDPS.2009.5160860
[3] T. Harris, A. Cristal, O. S. Unsal, E. Ayguade, F. Gagliardi, B. Smith, and M. Valero, “Transactional memory: An overview,” IEEE Micro, vol. 27, no. 3, pp. 8–29, May 2007. [Online]. Available: http://dx.doi.org/10.1109/MM.2007.63
[4] S. Prakash, Y. H. Lee, and T. Johnson, “A nonblocking algorithm for
shared queues using compare-and-swap,” IEEE Trans. Comput., vol.
43, pp. 548–559, May 1994. [Online]. Available:
http://dx.doi.org/10.1109/12.280802
[5] J.-J. Tsay and H.-C. Li, “Lock-free concurrent tree structures for multiprocessor systems,” in Proceedings of the
1994 International Conference on Parallel and Distributed
Systems, 1994, pp. 544–549. [Online]. Available:
http://dl.acm.org/citation.cfm?id=646860.706817
synchronized struct X { int a;
int b; float c; } Var_X;
A. Definition of a synchronized structure variable
synchronized int A[100];
B. Definition of a synchronized array
synchronized void write() { printf("Hello World\n"); }
C. Definition of a synchronized procedure
void display() { synchronized {
printf("Hello World\n"); }
}
D. Definition of a synchronized block of code
synchronized int *p = malloc(sizeof(int)); E. Definition of a
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
948
[6] J. Borkowski, “Towards more powerful and flexible synchronization primitives,” in Proceedings of the International Conference on Parallel Computing in Electrical Engineering, ser.
PARELEC ’00, 2000, pp. 18–. [Online]. Available:
http://dl.acm.org/citation.cfm?id=518911.825932
[7] K. Ramamritham and R. M. Keller, “Specification of synchronizing
processes,” IEEE Trans. Softw. Eng., vol. 9, no. 6, pp. 722–733,
Nov. 1983. [Online]. Available:
http://dx.doi.org/10.1109/TSE.1983.235435
[8] R. W. Wisniewski, L. Kontothanassis, and M. L. Scott, “Scalable
spin locks for multiprogrammed systems,” Tech. Rep., 1993.
[9] C. Fu, D. Wen, X. Wang, and X. Yang, “Hardware transactional
memory: A high performance parallel programming model,” J. Syst. Archit., vol. 56, pp. 384–391, Aug. 2010. [Online]. Available: http://dx.doi.org/10.1016/j.sysarc.2010.06.006
[10] A. Cohen, J. W. O’Leary, A. Pnueli, M. R. Tuttle, and L.
D. Zuck, “Verifying correctness of transactional memories,” in Proceedings of the Formal Methods in Computer Aided Design, ser. FMCAD ’07, 2007, pp. 37–44. [Online]. Available: http://dx.doi.org/10.1109/FMCAD.2007.39
[11] M. Herlihy and J. E. B. Moss, “Transactional memory: architectural
support for lock-free data structures,” in Proceedings of the 20th annual international symposium on computer architecture, ser. ISCA
’93, 1993, pp. 289–300. [Online]. Available:
http://doi.acm.org/10.1145/165123.165164
[12] A. McDonald, B. D. Carlstrom, J. Chung, C. C. Minh, H. Chafi, C.
Kozyrakis, and K. Olukotun, “Transactional memory: The hardware-software interface,” IEEE Micro, vol. 27, pp. 67–76, Jan. 2007. [Online]. Available: http://dx.doi.org/10.1109/MM.2007.26
[13] K. Moore, J. Bobba, M. Moravan, M. Hill, and D. Wood, “Logtm:
log-based transactional memory,” in High-Performance Computer Architecture, 2006. The Twelfth International Symposium on, 2006, pp. 254–265.
[14] R. Rajwar, M. Herlihy, and K. Lai, “Virtualizing transactional
memory,” in Proceedings of the 32nd annual international symposium on Computer Architecture, ser. ISCA ’05, 2005, pp.
494–505. [Online]. Available:
http://dx.doi.org/10.1109/ISCA.2005.54
[15] H. E. Ramadan, C. J. Rossbach, D. E. Porter, O. S. Hofmann, A. Bhandari, and E. Witchel, “Metatm/txlinux: transactional memory for an operating system,” in Proceedings of the 34th annual international symposium on Computer architecture, ser. ISCA ’07,
2007, pp. 92–103. [Online]. Available:
http://doi.acm.org/10.1145/1250662.1250675
[16] B. Saha, A.-R. Adl-Tabatabai, and Q. Jacobson, “Architectural
support for software transactional memory,” in Proceedings of the
39th Annual IEEE/ACM International Symposium on
Microarchitecture, ser. MICRO 39, 2006, pp. 185–196. [Online]. Available: http://dx.doi.org/10.1109/MICRO.2006.9
[17] P. Aggarwal and S. Sarangi, “Lock-free and wait-free slot
schedul-ing algorithms,” in Parallel Distributed Processschedul-ing (IPDPS), 2013 IEEE 27th International Symposium on, 2013, pp. 961–972.
[18] K. Dragicevic and D. Bauer, “A survey of concurrent priority queue
algorithms,” in Parallel and Distributed Processing, 2008. IPDPS 2008. IEEE International Symposium on, 2008, pp. 1–6.
[19] X. Huang, C. I. Rodrigues, S. Jones, I. Buck, and W.-m. Hwu, “Xmalloc: A scalable lock-free dynamic memory allocator for many-core machines,” in Proceedings of the 2010 10th IEEE International Conference on Computer and Information Technology, ser. CIT ’10,
2010, pp. 1134–1139. [Online]. Available:
http://dx.doi.org/10.1109/CIT.2010.206
[20] G. Schellhorn and S. Baumler, “Formal verification of lock-free
algorithms,” in Proceedings of the 2009 Ninth International Conference on Application of Concurrency to System Design, ser.
ACSD ’09, 2009, pp. 13–18. [Online]. Available:
http://dx.doi.org/10.1109/ACSD.2009.10