International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)395
A Novel Page Rank Algorithm for Web Mining based on
User’s Interest
Aruk Kumar Singh
1, Niraj Singhal
21Sharda University, Geater Noida, India 2Shobhit University, Meerut, India
Abstract - The web can be viewed as the largest database available and presents a challenging task for effective design and access. With the tremendous growth of Web, the main objective is to provide relevant information to the user to fulfil their needs. Data Mining applied to Web has the poten-tial to be quiet beneficial. Web Mining is the mining of data related to World wide Web. Web search engines are usually designed to serve user requirement without considering the user’s interest. In this paper we present Web content mining technique known as Personalization. With Personalization, Web access or the contents of a Web page are modified to better fit the desires of the user. This may involve actually creating Web pages that are unique per user or using the desires of a user to determine what Web documents to re-trieve. This paper deals with the analysis of various Page Rank algorithms for Web mining based on user’s interest.
Index Terms —Page Rank, Web Mining, Personalized Search, Personalization.
I. INTRODUCTION
World Wide Web (WWW) is the universe of network accessible information, the embodiment of hu-manknowledge. It is estimated that WWW is expanded by about 2000% since its evolution and is doubling in size periodically in every six to ten months [1]. Due to massive growth of data on web it is quiet difficult to manage data or information on web. The web can be viewed as largest database, here we use term database quiet loosely because, there is no real structure or schema to the Web. Thus Web mining is very important to retrieve desired information on Web. As we know that Web is unstructured repository which provide massive information and thus complexity of dealing information also increases day by day [2]. Search engines are programs that search documents for speci-fied keywords and return a list of the documents where the keywords were found. Search engine gather, analyze, or-ganize and handle the data retrieved from the internet. One major problem with search engine is that it returns thou-sand of results which include information acombination of user interest or without interest information . From the study it is observed that nearly 65%-70% users will choose the first page of the return result and about 20%-30% may choose second and very few will select third and so on pages. But it is not always true that returned first or second page always is of user’s interest.
It is also possible that user’s interest information may present on later pages. So our main concern is to embed Personalization factor in Page Rank algorithm for web mining.
Personalization adapts the information provided by a web site in accordance with the requirement of a user. Web Personalization is used mainly in four categories: predict-ing web navigation, assistpredict-ing personalization, personaliz-ing content, and provide guidance to the user. Assistpersonaliz-ing personalization information helps user in organizing web pages based on his interest and thus enhances the usability of web. In this paper we focus on personalizing web search by ranking the pages based on interest of individual user, which can greatly aid the search through massive amount of data on web. The paper is organized as follows: Search engine, Web Mining, Page Rank algorithm is presented in Section II i.e. Background study, Section III describes the related work, and in section IV we present proposed work, Section V comprised of Conclusion.
II. BACKGROUND STUDY
2.1 Search Engine
As the volume of information on the Web is increasing day by day so there is a challenge to provide relevant in-formation to the internet user. Figure 1 shows the working of Search engine.
look in ind
Get list of matches
User opens a found page
Figure 1: Working of a Search engine
Figure 1 depicts the working of Search engine and it in-volves following steps:
User type words into the form and click on Search. Search engine will receive the query (words and
commands). Indexer
In-dex file
Search engine
Searc h form
HTML pages Result
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)396 Look in the index file for matches to the search item. Gather the matching page information.
Sort the results by relevance. Format the results page in HTML.
Return the results page to the searcher’s web brows-er.
An efficient ranking of query words has a major role in efficient searching for query words. There are various challenges associated with the ranking of web pages such that some web pages are made only for navigation purpose and some pages of the web do not possess the quality of self descriptiveness.
2.2 Web Mining
Web is a collection of inter-related files on one or more Web servers. Web mining is the application of data mining techniques to extract knowledge from web data. Web data can be classified into the following classes:
Content of actual web pages.
Intrapage structure includes the HTML or XML code for the page.
Interpage structure is the actual linkage structure between Web pages.
Usage data that describes how Web pages are accessed by visitors.
User profiles include demographic and registration information obtained about users. This could also in-clude information found in cookies.
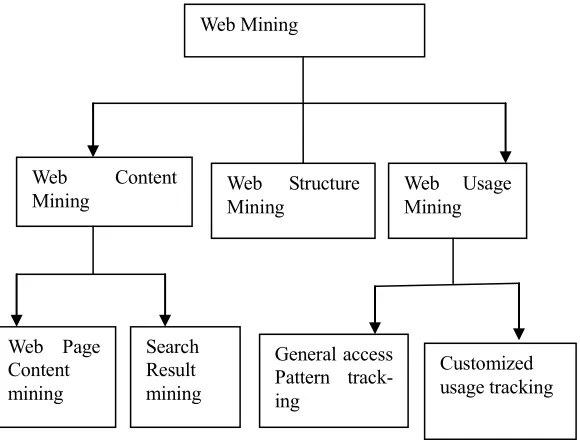
[image:2.595.368.496.423.587.2]Web mining is the technique to classify web pages by taking into account the contents of the web pages and be-haviour of Internet user in the past. Web mining task can be divided into several classes. Figure 2 shows the taxon-omy of web mining activities.
Figure 2: Web Mining Taxonomy
Web mining allows user to look for patterns in data through content mining, structure mining, and usage min-ing. Content mining is used to examine data collected by search engines and Web spider. Structure mining is used to examine data related to the structure of a particular Web site and usage mining is used to examine data related to a particular user's browser as well as data gathered by forms the user may have submitted during Web transactions. 2.2.1 Web Content Mining
[image:2.595.14.304.520.740.2]Web content mining can be thought of as a extending the work performed by basic search engines. Web content mining examines the contents of Web pages as well as results of web searching. The content includes text as well as graphics data. Web content mining is further divided into Web page content mining and search results mining. Most search engines are keyword based. Web content min-ing goes beyond the basic Information retrieval techniques. It can improve on traditional search engines through such techniques as concept hierarchies and synonyms, user pro-files, and analyzing the links between pages. Basic content mining is a type of text mining. As seen in Figure 3 a mod-ified version of text mining functions can be viewed in a hierarchy with the simplest functions at the top and more complex functions at the bottom.
Figure 3 Text mining hierarchy 2.2.2 Web Structure Mining
Web Structure mining can be viewed as creating a mod-el of the Web organization or a portion thereof. This can be used to classify Web pages or to create similarity measures between documents. With Web structure mining, infor-mation is obtained from the actual organization of pages on web. It is the process by which we discover the model of the link structure of web pages. Page Rank and HITS algorithm also fall in this category. The popularity of the web page is generally measured by the fact that a particu-lar page should be referred by particu-large number of other web pages and the importance of web pages may is judge by the number of outlinks in a web page. So Web Structure mining is of great importance in the field of web mining [5][6].
Keyword
Term Association
Similarity Search
Classification Clustering Natural Language
Pro-cessing Web Mining
Web Content
Mining Web Structure Mining Web Usage Mining
Web Page Content mining
Search Result mining
General access Pattern track-ing
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)397 2.2.3 Web Usage Mining
Web usage mining performs mining on web usage data, or Web logs. A Web log is a listing of page reference data. Sometimes it is referred to as click stream data because each entry corresponds to a mouse click. These logs can be examined from either a client perspective or a server per-spective. One taxonomy of Web usage mining application has included:
Personalization for a user can be achieved by keeping track of previously accessed pages.
By determining frequent access behaviour for users, needed links can be identified to improve the overall performance of future accesses.
Information concerning frequently accessed pages used for caching.
Web usage patterns can be used to gather business in-telligence to improve sales.
Gathering statistics concerning how users actually access Web pages may or may not be viewed as part of mining.
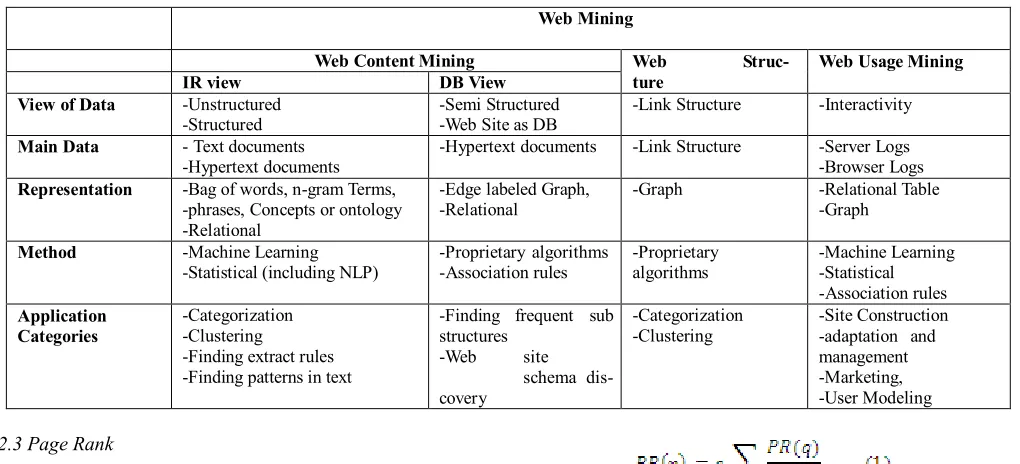
[image:3.595.50.560.309.541.2]Table I gives an overview of above mining categories [7]
TABLE 1 Web mining categories
Web Mining
Web Content Mining Web Struc-ture
Mining
Web Usage Mining
IR view DB View
View of Data -Unstructured
-Structured -Semi Structured -Web Site as DB -Link Structure -Interactivity
Main Data - Text documents
-Hypertext documents -Hypertext documents -Link Structure -Server Logs -Browser Logs
Representation -Bag of words, n-gram Terms, -phrases, Concepts or ontology -Relational
-Edge labeled Graph,
-Relational -Graph -Relational Table -Graph
Method -Machine Learning
-Statistical (including NLP) -Proprietary algorithms -Association rules -Proprietary algorithms -Machine Learning -Statistical -Association rules
Application Categories
-Categorization -Clustering
-Finding extract rules -Finding patterns in text
-Finding frequent sub structures
-Web site schema dis-covery
-Categorization -Clustering
-Site Construction -adaptation and management -Marketing, -User Modeling
2.3 Page Rank
The Page Rank technique was designed to both increase the effectiveness of search engines and to improve effi-ciency. The algorithm was developed by Brin and Page at Stanford University [8]. Page rank is a method for rating Web pages, effectively measuring the human interest. Page rank is used to measure the importance of a page and to prioritize pages returned from a traditional search engine using keyword searching. The effectiveness of this meas-ure has been demonstrated by the success of Google. The PageRank value for a page is calculated based on the number of pages that point to it. This is actually a measure based on the number of back links to a page. A backlink is a link pointing to a page rather than pointing out from a page. The measure is not simply a count of the number of backlinks because a weighting is used to provide more importance to backlinks coming from important pages. Given a page p, we use Bp to be the set of pages that point
to p, and Fp to be the set of links out of p. The PageRank of
a page p is defined as:
Here Nq = |Fq|. The constant c is a value between 0 and
1 and is used for normalization.
A problem, called rank sink, that exists with this Pag-eRank calculation is that when a cyclic reference occurs, the PR value for these pages increases. This problem is solved by adding an additional term to the formula:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)398
III. RELATED WORK
Many research works are being contributed in applica-tion of page rank algorithm in web mining based on user’s interest. Page et al. [9] first proposed personalized web search by modifying the global PageRank algorithm with the input of bookmarks or homepages of a user. Their work describes the global importance of link structure of web. Haveliawala [10] determined that PageRank could be computed for huge subgraphs of the web. Brin et al. [11] suggested the idea of biaing the PageRank computation for the purpose of Personalization. Bharat and Mihaila [12] describe an approach called Hilltop that generates a query specific authority score. Widom [13] scaled the number of hub pages beyond 16 for finer-grained personalization.
In papers[14] Web Personalization have been pro-posed to achieved by majorly user profiling obtained from content based filtering, collaborative filtering and rule based filtering. In papers [15] author has done tasks on browsing activities of a surfer at the web browser contrib-uted significantly in improving design of browser. [16] proposed Web Intelligent model using Genetic algorithms on web navigation page views in transactions. In the re-search in 2011, a system is proposed to perform web us-age mining on user activities on a web pus-age i.e. event tracking.
The work [17] work is done on search engines. It found user preferences from click through behaviour of users and semantic relation between documents to adapt the search engine’s ranking function. It proposed the combination of Web usage mining and Web Content mining for client side analysis to have effective information retrieval in Web Personalization.
In [18] Personalized PageRanks are computed based on the user profiles. Researchers have also proposed ways to personalize web search based on ideas other than Pag-eRank [19,20]. This work describes content analysis of the visited pages.
Finally, Google has started a beta-testing of a new per-sonalized search service, which seems to estimate a searcher’s interest from his/her past queries.
IV. PROPOSED WORK
Web Search engines are usually designed to serve all users, without considering the user interest. Personalized Web search incorporates the interest of individual user when return back the relevant web page to the user.
Personalization has recently got significant attention to address the challenge of accessing the web page or the contents to better fit the desire of the user. In this study we proposed a PageRank algorithm that counts user interest while ranking the web pages.
PageRank is used to measure the importance of a page and to prioritize them using keyword searching but in this study we apply a little change so that page according to user requirement are retrieved from the server, for that mining activities related to personalization requires exam-ining Web log data to uncover patterns of access behav-iour by use. There are three basic types of Web Page Per-sonalization technique which we embed with existing PageRank algorithm to create Web pages that are unique per user or using the desires of a user to determine what Web documents to retrieve. We can apply any of the tech-nique to rank Web pages based on user interest.
Manual Technique, perform personalization through registration preferences or via the use of rules that are used to classify individual based on profiles or de-mographics.
Collaborative filtering, accomplishes personaliza-tion’s by recommending information that have previ-ously been given high rating from similar user. Content-based filtering retrieves pages based on
sim-ilarity between them and user profile.
Our study show that user preferences can be learned ac-curately either from Manual Technique, or through Col-laborative filtering, or via Content-based filtering and yield significant improvement over the existing PageRank algo-rithm which only includes the Link analysis to determine the PageRank of a given Web Page. We propose to learn a user profile using either of three techniques mentioned above from web pages that are of interest to the user. The user’s interest will be determined implicitly, without di-rectly asking the user. Using this, we study method to rank the results and when used with a search engine, can yield more relevant web pages for the individual user. In the existing PageRank algorithm that page which has many links has higher rank and thus improves retrieval efficien-cy, but if we add Personalization to rank pages it can re-trieve only those pages which are useful to the individual user. We propose a method to rank the page by considering the user interest over the search result that will not consid-er the usconsid-er intconsid-erest while ranking the web pages.
The proposed page rank algorithm based on user’s in-terest works as follows:
Retrieve the top k documents that match the user query.
User preference documents are framed in a graph by weighing the initial set of documents using Term Frequency and Inverse document frequency (TF-IDF).
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)399 The result set is now ranked based on User interest
document and TF-IDF value.
The proposed system works first for the computation of TF-IDF value then for finding the user interest document then to rank pages in accordance with the user interest.
Fig.4 demonstrates the overall working of this proposed page rank algorithm based on user’s interest.
Fig.4 overall architecture of working of proposed system The proposed algorithm proceeds as follows:
Firstly Top k documents are collected from search engine.
Then We compute the value of TF-IDF.
Then incorporates the factor the list all the document based on user’s interest.
Finally rank the web pages.
So the output is the set of web pages ranked as per the user’s interest.
Fig.5 depicts the changes in the working of a search en-gine when user’s interest factor is embedding while searching and ranking of the web pages
Fig.5 working of a search engine based on user’s interest
V. CONCLUSION
The purpose of this research is to devise a new method of ranking web pages to serve each individual user’s inter-est. The algorithm that is discussed above are significantly effective in retrieving the Web pages from the search en-gine in accordance with the user interest. In this paper we have proposed a technique which ranks the web pages based on user’s interest based on TF-IDF Measure . It in-corporates not only the Existing PageRank algorithm but also Personalization of the web to rank the web pages. It helps to enhance PageRank of the Web pages so that end use could retrieve the Web pages which is most relevant to user query.
REFERENCES
[1 ] Naresh barsagade, “Web Usage mining and Pattern Discovery: A
survey paper”, CSE8331,Dec.8,2003
[2 ] P Ravi Kumar, and Singh Ashutosh kumar, Web Stru ture mining
Exploring Hyperlinks and Algorithms for Information Retrieval, American Journal of applied sciences, 7 (6) 840-845 2010.
[3 ] Justin Zobel, Alistair Moffat, Ron Sacks-Davis.” An Efficient
index-ing technique for full-text database systems”.[c]//Proc of 18th INT Conf on VLDB, august 23-27,1992, Vancouver, Canada, Morgan Kaufmann,1992:352-362.
[4 ] Dell Zhang. “Semantic, Hierarchical, online clustering of Web
search results”[C]. Hangzhou China:Proceedings of the 6th Asia
Pa-cific web conference,2004:69-78. Existing
Concepts
Preferred term
Related con-cepts from
word
User Interest based document computa-tion
Ranking
TF-IDF Value
Ranked web page based on us-er’s interest Sorted
list of terms
Top K documnets User
TF-IDF
Existing Concepts
New Concepts
Indexer
In-dex Search engine
HTML Pag-es
Ranked docu-ment based on user’s interest
TF-IDF com- puta-tion
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 9, September 2012)400
[5 ] Wenpu Xing and Ali Ghorbani, “ weighted Page Rank Algorithm”,
In proceedings of the 2nd Annual conference on communication
Networks & Services Research,PP.305-314,2004.
[6 ] Neelam Duhan, A.K. Sharma and Komal Kumar Bhatia, “Page
Ranking algorithms: A Survey”, In proceedings of the IEEE Int. ad-vanced Computing conf (IACC), 2009.
[7 ] R.Kosala and H.Blockeel,”Web Mining Research:A survey”, In
ACM SIGKDD Explorations,2(1),PP.1-15,2000.
[8 ] S. Brin, and L. Page, the Anatomy of a Large Scale Hypertextual Web Search engine,,Computer Network and ISDN Systems, Vol.30, Issue 1-7 ,pp.107-117,1998.
[9 ] Page,L.,Brin,S.,Motwani,R.,Winograd,T.:The Page Rank citation
Ranking: Bringing order to the web. Technical Report, Stanford University Database Group (1998).
[10 ] Haveliawala, T.H.:Efficient computationof PageRank.Technical
Report, StanfordUniversity Database Group
(1999)http://dbpubs.stanford.edu/pub/1999-31.
[11 ] Brin,S.,Motwani,R.,Page,L.,Winograd,T.:What can you do with a web in your pocket. In Bulletein of the IEEE Computer Soci-ety Technical Committee on Data Engineering (1998).
[12 ] Ben Schafer, J.,Konstan, J.A., Riedl,J.:Electronic Commerce Rec-ommender Applications, Journal of Data Mining and Knowledge Discovery,5 (2001) 115-152.
[13 ] Jeh, G..,Widom,J.:Scaling Personalized Web Search. In Proc. of the
12th Int. Conf. on World Wide Web,Budapest,Hungary (2003) 20-24.
[14 ] Eirinaki, M., Vazirgiannis, M., 2003, Web Mining for Web Personal-ization. ACM transactions on Internet Technology, Vol. 3, No. 1, Feb 2003 pp. 1-27.
[15 ] Kellar, M., Watters, C. and Shepherd, M., 2006, The Impact of Task on the Usage of Web Browser Navigation Impact. Proc. of Graphics Interface 2006- portal.acm.org.
[16 ] Rao, V. V. R. M., Kumari, V. V., Raju, K. V. S. V. N., 2010, An Ad-vanced Optimal Web Intelligent Model for Mining Web User Usage Behavior using Genetic Algorithm. Proceedings ofInternational Conference on Advances in Computer Science 2010, Trivandrum, Kerela, India.
[17 ] Rekha, C., Nirase, F., and Iyakutti, K., 2011, An Attempt to Enhance The Information Retrieval System Towards Client Side for Web Personalization By Combining Usage and content Mining Tech-nique. Proceedings of 2ndInternational Conference on Business and Economuc Research (ICBER 2011).
[18 ] M. Aktas, M. Nacar, and F. Menczer. Personalizing pagerank based on domain profiles. In Proc. Of WebKDD 2004: KDD Workshop on Web Mining and Web Usage Analysis, 2004.
[19 ] F. Tanudjaja and L. Mui. Persona: A contextualized and personalized web search. In Proc. of the 35th Annual Hawaii International
Con-ference on System Sciences, 2002.