A COMBINED ALGORITHM FOR DATA
WAREHOUSE FRAGMENTATION
SELECTION
M.THENMOZHIDepartment of Computer Science and Engineering, Pondicherry Engineering College, Puducherry, India
K.VIVEKANANDAN
Department of Computer Science and Engineering, Pondicherry Engineering College, Puducherry, India
Abstract :
Data warehouses are designed to handle the queries required to discover trends and critical factors for Online Analytical Processing (OLAP) systems. Such systems are composed of multiple dimension tables and fact tables (in the form of star schema). Queries running on such systems contain a large number of costlier joins, selections and aggregations. To optimize these queries, the use of advanced optimization techniques is necessary. Data partitioning that has been studied in the context of data warehouse aims to reduce query execution time and to facilitate the parallel execution of these queries. Horizontal partitioning is one of the important aspects of such data partitioning technique. It is a divide-and-conquer approach that improves query performance, operational scalability, and the management of ever-increasing amounts of data. It improves performance of queries by the means of pruning mechanism that reduces the amount of data retrieved from the disk. The horizontal partitioning approach consider several dimension tables involved in the queries and the number of fact fragments generated by this partitioning methodology can be very huge and it is difficult for the data warehouse administrator to maintain all the fragments. Hence it is necessary select optimal set of fragments that are manageable in the underlying database. In this paper we proposed combined hill climbing and genetic algorithm in order to enhance fragmentation selection for horizontal partitioning approach. Our experimental results show that our method can provide a significantly better solutionthan existing fragmentation selection techniques in terms of minimization of query processing time.
Keywords: Data Warehouse Partitioning; Horizontal Fragmentation; Fragmentation Selection.
1. Introduction
Fig.1. Star Schema
Since data warehouses contain integrated data from several operational database sources they tend to be large orders of magnitude than operational databases. An enterprise data warehouses are hundreds of gigabytes to terabytes in size and they are accessed using complex queries which performs lots of joins and aggregates. Hence in such an environment query throughput and response times are more important than transaction throughput. Data warehouse partitioning plays an important role in order to provide efficient query processing. Existing works on data warehouse partitioning mainly adapted horizontal partitioning while others followed vertical partitioning and few followed hybrid partitioning approach. While adapting partitioning approach it is essential to manage the large set of fragments in the data warehouse. The main objective of this paper is to propose an optimized algorithm fragmentation selection problem for horizontal partitioning of the data warehouse in order have manageable number of fragments and thus to obtain better query performance.
2. Background
This section explains the basics of data warehouse partitioning, partitioning types and partitioning methods.
2.1. Data Warehouse Partitioning
Data warehouses often contain large tables and require techniques both for managing these large tables and for providing good query performance across these large tables [Bellatreche et al (2000)]. Hence partitioning plays an important role for the data warehouse design. Partitioning means splitting one large table into several small tables in order to decrease the number of join created during the running of the queries. By this way, their execution times will decrease with the cost of having more tables. In other words, partitioning is the database process or method where very large tables and indexes are divided in multiple smaller and manageable parts [Koreichi and Le Cun (1997)]. There are three types of partitioning in a data warehouse are:
Horizontal Partitioning: In the horizontal partitioning, the large table is split in two or more tables having fewer rows but the same number of columns. The splitting is based on values in one or more columns in a row. In other words, it involves placing different rows into different tables. This in turn means that the number of rows in each table is reduced, thus improving search performance.
Vertical Partitioning: The large table is split in two or more tables having fewer columns but keeping the same number of rows. The vertical partition is done in order to make changes that can improve data storage usage and performance, which affects the entity structure itself. It is a technique in which a table with a large number of columns is split into two or more tables, each with an exclusive subset of the columns that are not table keys.
Hybrid Partitioning: A hybrid partitioning consists in slicing a very large dimension table both vertically and horizontally. Here, the large table is first sliced using one of the above mentioned methods. For example, we can say that we first partition it vertically in two tables. The first contains all the attributes that do not change over time (eg. birthday year of a customer), while the second contains all attributes that may change (eg. a phone number). After this, each of these two tables will further be split choosing horizontal partitioning criteria. The hybrid partitioning produces the most tables, as it combines two different methods of slicing tables. However, the main advantage is that each of the resulting tables will have a lot less rows and also less attributes. Thus the method spatially expands a very large dimension, both horizontally and vertically, into tables of far smaller sizes.
2.2. Partitioning Methods
There are different types of partitioning methods available as given below:
Range partitioning: It maps data to partitions based on ranges of partition key values that we establish for each partition.
Hash partitioning: It maps data to partitions based on a hashing algorithm based on the partitioning key that is identified.
Composite partitioning : It is a combination of the basic data distribution methods, a table is partitioned by one data distribution method and then each partition is further subdivided into sub partitions using a second data distribution method.
Reference partitioning: It allows the partitioning of two tables related to one another by referential constraints.
3. Related Work
Many research works dealing with horizontal partitioning problem were proposed in traditional databases and data warehouses. In [Costa et al (2004)] the authors propose a new approach called selective loading to deal with data warehouses involving big dimensions. The proposed technique enables the data warehouse technique to handle with large dimensions maintaining nearly linear speed up in query execution time. [Liu and Nadeem (2013)] this paper presents the design methods for modeling big dimensions. Three type of partitioning approaches are discussed which includes horizontal partitioning, vertical partitioning and the hybrid. This paper also presents an effective otology based tool to automate the modeling process. The tool can automatically generate the data warehouse schema from the ontology of describing the terms and business semantics for the big dimension. [Agrawal et al (2004)] In this paper the authors present techniques that enable a scalable solution to the integrated physical design problem of indexes, materialized views, vertical and horizontal partitioning for maintaining both performance and manageability. Their work on horizontal partitioning focuses on single-node partitioning. [Bellatreche et al (2009)] in this paper the authors gives a formalization of the referential fragmentation schema selection problem in the data warehouse and they study its hardness to select an optimal solution. Here they develop two algorithms: hill climbing and simulated annealing with several variants to select a near optimal partitioning schema. [Mahboubi and Jérôme (2008)] In this paper the authors have introduced an approach for fragmenting XML data warehouses that is based on data mining, and more precisely clustering and the k-means algorithm. They compare its efficiency to classical derived horizontal fragmentation algorithms adapted to XML data warehouses and show its superiority. [Bellatreche Ladjel (2012)] This paper proposes a comprehensive procedure for automatically selecting dimension tables which are candidate to referential partition a fact table. They use hill climbing algorithm to select fragmentation schema of the data warehouse due to its simplicity and less computation time. [Dimovski et al (2011)] In this paper the authors present a formal approach for horizontal partitioning of relations based on predicate abstraction. Here they show how to use the proposed approach for finding an optimal data warehouse design which takes account of the performance of queries and the maintenance cost. [Bellatreche and Kamel (2005)] This paper discusses the challenges on partitioning of relational warehouse. They concentrate on the benefits fragmenting fact table based on the partitioning schemas of dimension tables. They also discuss about managing the large set of fragments they presents genetic algorithm for schema partitioning selection problem.
4. Proposed Horizontal Fragmentation Approach
The data warehouse schema consisting of set of fact and dimension tables along with their attributes is considered. For referential partitioning of fact table with respect to dimension table, it is necessary to select the appropriate dimensions and attributes of the chosen dimension such that the query cost is minimized. A set of query workload is taken as input to select the dimension table. Using from clause in the queries the frequently used dimension tables are obtained. With the selected dimension tables not all the attributes are essential for performing partitioning. Hence to choose the set of attributes the query workload is taken as input of a given dimension table. Using the where clause in the queries the attributes are retrieved for a chosen dimension table. Next step is to partition the dimension tables based on the selected attributes. As the data warehouse administrator could manage only limited set of partitions or fragments in the underlying database, it is essential to choose only optimal set of fragments that minimizes the overall query cost. Existing works on fragmentation selection problems showed us that both the hill climbing and genetic algorithm are suitable tools for solving such problems. As each algorithm has some disadvantages, we develop a combined approach which integrates hill climbing and genetic algorithm. For selecting the optimal set of fragments from the large set of fragments, the proposed approach for fragmentation selection algorithm can be applied.
4.1. Hill Climbing Principles
solution is randomly generated and hill climbing begins again. The best prior solution is remembered. In general the key benefits of hill climbing are that it requires only limited amount of memory. If one or more solution exists in the search space hill climbing is effective in finding it.
Fig. 2. Hill Climbing Algorithm
4.2. Genetic Algorithm Principles
Genetic algorithms (GAs) are a general methodology for searching a discrete solution space in a way that is similar to process of natural selection procedure in biological systems [Mitchell (1998)]. The algorithm creates a “population” of possible solutions to the problem and lets them “evolve” over multiple generations to find better and better solutions. The population is the collection of candidate solutions that we are considering during the course of the algorithm. A single solution in the population is referred to as an individual. The fitness of an individual is a measure of how “good” the solution represented by the individual. Individuals are selected for “breeding” (or cross-over) based upon their fitness values the fitter the individual. The cross-over occurs by mixing the two solutions together to produce two new individuals. There is also chance for each individual to mutate in each generation, which will change the individual in some small way. After certain number of iterations, the algorithm converges to a set of solutions to the problem at hand once the population has converged and no more offspring produced are noticeably different from those in previous generations. The steps of genetic algorithm are given in Fig 3.
4.3. Combined Hill Climbing and Genetic Algorithm (Combined GAHC)
This section describes the proposed approach which combines the principles of the two approaches: hill climbing and genetic algorithm. At initiation it creates a set of random valid solutions and after several iterations it optimizes them using hill climbing based method. Genetic principles are applied to the set of solutions obtained, and this creates a new generation of solutions. Algorithm continues by the process of several hill climbing iterations followed by genetic-principles iteration until computation termination criteria are met. This approach combines the advantages of the two algorithms and mitigates the disadvantages. Hill climbing search that uses only one solution can easily miss some promising areas of the search space, and it may get struck in a local optimum. Genetic algorithms, show lower solution quality with increasing problem size; the most prominent cause is the damage to solutions that occurs during solution crossover. The combined algorithm we propose combines the parallelism and information-exchange of genetic algorithms with a strong local optimization of the hill climbing search algorithm.
Hill climbing components of the algorithm are similar to the algorithm given in Fig. 2. Genetic components are similar to GA described in Fig. 3. The steps of combined GAHC are given in Fig. 4. In this work the algorithm stops after a pre-set number of consecutive unsuccessful genetic iterations. This means that computation stops when maximum number of consecutive genetic-based steps that do not improve objective criterion value is reached; the best solution that was found during this time is used as the result. The evaluation function is based on the objective function. One of the advantages of heuristic algorithms such as the one we propose is the way the constraints of the problem are treated. As long as neighborhood generation, crossover, and mutation operators guarantee that only valid solutions will be generated, the algorithm itself does not have to take any constraints into account, because all are incorporated into the objective function. The random elements in the genetic parts of the algorithm guarantee asymptotic convergence towards the global optimum. The combination of sampling and mutations ensures that in infinite number of iterations the algorithm visits all valid solutions including the optimal ones.
Fig. 4 Combined GAHC algorithm
5. Experimental Study
We have conducted an experimental study to evaluate our proposed strategy for fragmentation selection in order to perform horizontal partitioning for a given data warehouse schema.
5.1 Data Set Used
A Sales data warehouse consisting of the Stock, Item, Acledger and Purchase is taken as input. The data warehouse schema is given in Fig. 5. The fact table Sales contains10,000 records, the dimension tables Acledger
Fig. 5 Sales Data Warehouse Schema
5.2Queries Used
The following are the queries that are used in the experiment for retrieving the results in the Sales data warehouse and these queries are also used for computing the time differences in the execution time and query cost. The list of queries is given in Fig. 6.
5.3 Domain Partitioning and Fragmentation Code
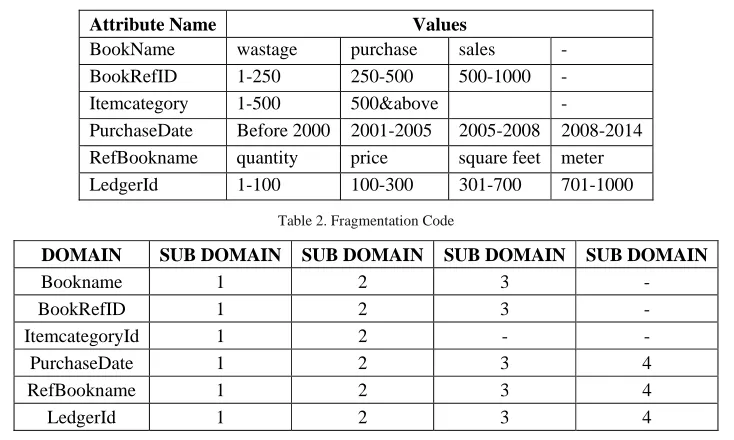
In order to apply hill climbing, genetic algorithm and Combined GAHC algorithm, we need to represent our problem solution. Table 1 represents a sample domain partitioning for different attributes. For example Stock dimension, the Bookname and BookRefId attributes contains 3 sub domains each, for Item dimension, ItemcategoryId contains 2 sub domains. Next each fragmentation schema needs to be represented using a multidimensional array, where each cell represents a domain partition of a fragmentation schema. We need to represent the fragmentation schema by the coding as given in Table 2. This code is the initial solution given as the input to the fragmentation selection algorithm.
Table 1. Domain Paritioning
Attribute Name Values
BookName wastage purchase sales - BookRefID 1-250 250-500 500-1000 -
Itemcategory 1-500 500&above -
PurchaseDate Before 2000 2001-2005 2005-2008 2008-2014 RefBookname quantity price square feet meter LedgerId 1-100 100-300 301-700 701-1000
Table 2. Fragmentation Code
DOMAIN SUB DOMAIN SUB DOMAIN SUB DOMAIN SUB DOMAIN
Bookname 1 2 3 -
BookRefID 1 2 3 -
ItemcategoryId 1 2 - -
PurchaseDate 1 2 3 4
RefBookname 1 2 3 4
LedgerId 1 2 3 4
5.4 Implemetation details of Combined GAHC 1) Initialization
Ten initial solutions (fragmentation schemes) are produced randomly which is the population on which the combined algorithm works. A sample fragmentation schema is given in Table 3. Here for the attribute PurchaseDate the predicates are P1= Before 2000, P2=2001-2008, P3= 2008-2014 and for the attribute RefBookname the predicates are P1= quantity, P2=price, P3= square feet or meter.
The total number of generation is initialized.
The Threshold value is set which is the maximum number of fragments managed by the database.
Table 3. Initial Solution
DOMAIN SUB DOMAIN SUB DOMAIN SUB DOMAIN SUB DOMAIN
Bookname 1 2 3 -
BookRefID 1 2 3 -
ItemcategoryId 1 2 - -
PurchaseDate 1 2 2 4
RefBookname 1 2 3 3
LedgerId 1 2 3 4
2) Evaluation
The fitness value for each and every fragmentation scheme is computed using the cost model. Cost Model formula: Fitness value= {(Size of each fact fragment)*(Length of each instance of
fact)}/Page size of the disk. 3) Hill Climbing
If N is greater than threshold then the sub domains in the fragmentation code of the individual is merged. For example the sub domains 1 and 2 of BookRefID can be merged as shown in Table 4.
If N is lesser than the threshold then the sub domains in the fragmentation code of the individual is spitted.
After applying merge or split operations the fitness of the individual is calculated.
When the individual has higher fitness than the original individual it is retained for further improvements.
After certain iterations when no further improvements are seen the hill climbing is terminated. The above steps are repeated for other individuals in the initial population.
Table 4. Initial Solution after merge
DOMAIN SUB DOMAIN SUB DOMAIN SUB DOMAIN SUB DOMAIN
Bookname 1 2 3 -
BookRefID 1 2 3 -
ItemcategoryId 1 2 - -
PurchaseDate 1 2 4 -
RefBookname 1 2 3 -
LedgerId 1 2 3 4
4) Genetic operations
Selection: Roulette wheel method is used in this algorithm. The two individuals with highest fitness value are chosen.
Crossover: New individual is created by crosses of selected individuals. Here we use one-point crossover mechanism to gives the same chances to the attributes with high and low number of sub domains. Fig. 7 is an example for crossover operation.
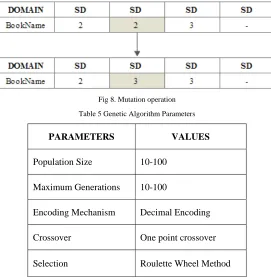
Mutation: It involves in modifying the cells (genes) in the individual to obtain a new individual. Fig. 8 is an example for mutation operation.
New population: The fitness value for each and every fragment is computed using the given cost model. These fragments form the new set of population.
Algorithm continues by the process of several hill climbing iterations followed by genetic-principles iteration until computation termination criteria are met.
5) Termination
If the termination condition is not satisfied then the whole process is repeated. After certain number of iterations the algorithm converges and we obtain the optimal fragmentation schema. The Table 5 represents the genetic algorithm parameters used in our approach.
Fig 8. Mutation operation
Table 5 Genetic Algorithm Parameters
PARAMETERS VALUES
Population Size 10-100
Maximum Generations 10-100
Encoding Mechanism Decimal Encoding
Crossover One point crossover
Selection Roulette Wheel Method
5.5 Partioning
After running the combined algorithm for fragmentation selection we obtain the optimal fragmentaion schema that can be used to partition the Sales data warehouse. Here we give the sample details of paritioning applied for Stock, Item , Purchase and Acledger dimension tables and Sales fact table.
Partitioning Stock Table:
Create table stock(StockId bigint, Sdate datetime, ItemId bigint, Qty bigint, MF int, IsDamage bit, BookName varchar(50),BookRefNo bigint, Description varchar(50), BookRefId bigint, CompanyId bigint, UserId bigint, CreatedDate datetime, Remarks varchar(150) )
PARTITION BY LIST(bookname) ( partition waste VALUES (‘wastage’), partition purchase VALUES (‘purchase’), partition sale VALUES (‘sales’) ), PARTITION BY RANGE( bookrefId)
( partition book_250 VALUES between 0 and 250, partition book_500 VALUES between 251 and 500, partition sale book_1000 VALUES greater than 501); Partitioning Item Table:
Create table tbl_Item(ItemId bigint, Item varchar(255), ItemCategoryId bigint, ItemCode varchar(50), Size varchar(50), SalesRate decimal(18, 2), PurchaseRate decimal(18, 2), CompanyId bigint, UserId bigint, CreatedDate datetime, UnitId bigint, Rate decimal(18, 2), RateType char(1), Vat decimal(18, 2), PurchaseRateId decimal(18, 2))
PARTITION BY RANGE(ItemCategoryId) (partition Item_500 values between 0 and 500, Partition Item_1000 values greater than 501); Partitioning Purchase Table:
Create table tbl_purchase(PurchaseId bigint, RefNo bigint, RefDate datetime, BillNo varchar(50), BillDate datetime, SupplierId bigint, NetAmount decimal(18, 2), CompanyID bigint, TotalAmount decimal(18, 2), VATAmount decimal(18, 2), UserId bigint)
PARTITION pur_2000 VALUES LESS THAN(TO_DATE('02/01/2000','DD/MM/YYYY')), PARTITION pur_2005 VALUES LESS THAN(TO_DATE('01/01/2005','DD/MM/YYYY')), PARTITION pur_20014 VALUES LESS THAN(TO_DATE('01/01/2014’,'DD/MM/YYYY')), Partitioning Acledger Table:
Create table Ac_Ledger(LedgerId bigint, GroupId bigint, AcName varchar(150), ShortCode varchar(50), Name varchar(50), sex char(10), Prefix varchar(50), Address1 varchar(250), Address2 varchar(50), Address3 varchar(50), CityId bigint, ZipCode varchar(10), Fax varchar(50), Phone varchar(50), EmailId varchar(150), MobileNo varchar(50), OpBal decimal(18, 2), IsCredit bit, BalanceMaintenance varchar(50), BEDPercent decimal(18, 2), AEDPercent decimal(18, 2), CessPercent decimal(18, 2), TaxPercent decimal(18, 2), SCPercent decimal(18, 2), CSTPercent decimal(18, 2))
PARTITION BY LIST(RefBookName)
(PARTITION ledger_cust VALUES(‘customer') , PARTITION ledger_supp VALUES( ‘supplier’)), PARTITION BY RANGE(LedgerID)
( partition ledger_250 VALUES between 0 and 250, partition ledger_500 VALUES between 251 and 500, partition ledger_750 VALUES greater than 750); Partition Sales Table(Fact Table):
Create table tbl_sales(SalesId bigint, stockID bigint, BillDate datetime, PurchaseId bigint, NetAmount decimal(18, 2), LedgerID bigint, DiscountPercent decimal(18, 2), DiscountAmount decimal(18, 2), TotalAmount decimal(18, 2), VATPercent decimal(18, 2), VATAmount decimal(18, 2) , UserId bigint, Deleted bit, PaymentMode varchar(50) , constraint sales_stock_fk foreign key(stockID) references stock(StockId) , sales_AcLedger_fk foreign key(LedgerID) references AcLedger(AcLedger))
PARTITION BY REFERENCE (sales_stock_fk , sales_tbl_purchase_fk , sales_AcLedger_fk );
6. Results and Analysis
After executing hill climbing, genetic and combined GAHC algorithms the query execution time is given in Table. The CPU time is the time for query to execute and elapsed time is the CPU time plus the time taken by the query waiting for reading from disk, waiting on locks, waiting on latches etc.,
Table 6 Query Execution Time
QUERY
BEFORE
PARTITIONING AFTER PARTITIONING
HILL CLIMBING GENETIC
ALGORITHM COMBINED ALGORITHM CPU TIME ELAPSED TIME CPU TIME ELAPSED TIME CPU TIME ELAPSED TIME CPU TIME ELAPSED TIME Q1 74ms 1189ms 36 ms 1012 ms 16 ms 625 ms 9 ms 550 ms
Q2 74 ms 845ms 36 ms 678 ms 16 ms 318 ms 9 ms 212 ms
Q3 106 ms 678ms 54 ms 348 ms 46 ms 281 ms 35 ms 170 ms
Q4 38 ms 1189ms 768 ms 1102 ms 647 ms 687 ms 580 ms 520 ms
Q5 230 ms 145ms 10 ms 120 ms 0 ms 63 ms 0 ms 42 ms
Q6 205 ms 430ms 120 ms 245 ms 94 ms 110 ms 76 ms 78 ms
Q7 236 ms 1250ms 134 ms 789 ms 109 ms 515 ms 87 ms 380 ms
Q8 259 ms 354ms 145 ms 156 ms 94 ms 94 ms 82 ms 68 ms
Q9 789 ms 1258ms 534 ms 1008 ms 515 ms 515 ms 478 ms 370 ms
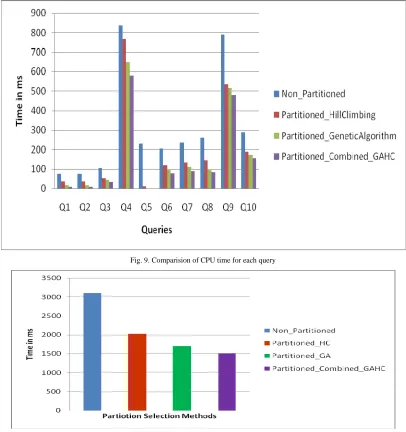
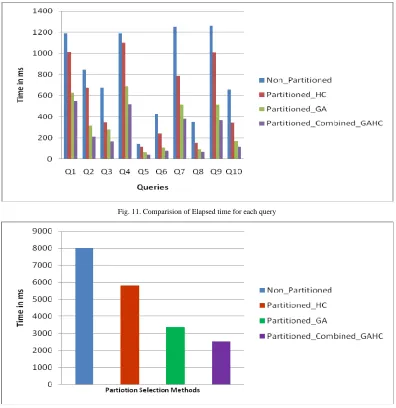
Fig. 9 compares the CPU time for each query for a non-partitioned data warehouse with horizontally partitioned data warehouse applying different fragmentation selection algorithm. Fig. 10 compares the total CPU time for a non-partitioned data warehouse with horizontally partitioned data warehouse applying different fragmentation selection algorithm. From the Fig. 9 and Fig.10 we infer that the combined hill climbing and genetic algorithm produces a better results that is, minimum CPU time for the given query work load.
Fig. 9. Comparision of CPU time for each query
Fig. 10. Comparision of Total CPU time for different methods
Fig. 11. Comparision of Elapsed time for each query
Fig. 12. Comparision of Total Elapsed time for different methods
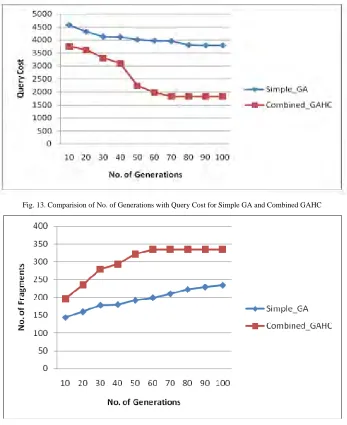
Fig. 13. Comparision of No. of Generations with Query Cost for Simple GA and Combined GAHC
Fig. 14. Comparision of No. of Generations with No. of Fragments produced for Simple GA and Combined GAHC
In Fig. 15, we studied the variation of the number of population in each generation. The results show the importance of this parameter to get a better performance of the Combined GAHC. A reduced number of populations do not allow the exploration of a large space of search.
7. Conclusion
Horizontal data partitioning is one of important aspects in order to enhance the logical design of data warehouse systems. The referential partition method is well adapted for business intelligence applications such as the data warehouse in order to optimize selections and joins defined in mega queries involving a large number of tables. In this paper we adapt a comprehensive procedure for using referential partitioning where, it first selects relevant dimension tables to partition the fact table along with their associated selection predicates. Further we proposed a combined algorithm for horizontal fragmentation selection using genetic and hill climbing technique and defined cost model evaluating the cost of a set of frequently queries performed on top of the partitioned data warehouse schema. Our experimental results show that our method can provide a significantly better solution than pure hill climbing and genetic algorithms in terms of minimization of query processing time and query cost.
References
[1] Agrawal, Sanjay, Vivek Narasayya, and Beverly Yang. "Integrating vertical and horizontal partitioning into automated physical database design." InProceedings of the 2004 ACM SIGMOD international conference on Management of data, pp. 359-370. ACM, 2004.
[2] Bellatreche, Ladjel, and Kamel Boukhalfa. "An evolutionary approach to schema partitioning selection in a data warehouse." In Data Warehousing and Knowledge Discovery, pp. 115-125. Springer Berlin Heidelberg, 2005.
[3] Bellatreche, Ladjel, Kamalakar Karlapalem, Mukesh Mohania, and Michel Schneider. "What can partitioning do for your data warehouses and data marts?." In Database Engineering and Applications Symposium, 2000 International, pp. 437-445. IEEE, 2000. [4] Bellatreche, Ladjel, Kamel Boukhalfa, Pascal Richard, and Komla Yamavo Woameno. "Referential horizontal partitioning selection
problem in data warehouses: Hardness study and selection algorithms." International Journal of Data Warehousing and Mining (IJDWM) 5, no. 4 (2009): 1-23.
[5] Bellatreche, Ladjel. "Dimension table selection strategies to referential partition a fact table of relational data warehouses." In Recent Trends in Information Reuse and Integration, pp. 19-41. Springer Vienna, 2012.
[6] Chaudhuri, Surajit, and Umeshwar Dayal. "An overview of data warehousing and OLAP technology." ACM Sigmod record 26, no. 1 (1997): 65-74.
[7] Costa, Marco, and Henrique Madeira. "Handling big dimensions in distributed data warehouses using the DWS technique." In Proceedings of the 7th ACM international workshop on Data warehousing and OLAP, pp. 31-37. ACM, 2004.
[8] Dimovski, Aleksandar, Goran Velinov, and Dragan Sahpaski. "Horizontal partitioning by predicate abstraction and its application to data warehouse design." In Advances in Databases and Information Systems, pp. 164-175. Springer Berlin Heidelberg, 2011.
[9] Golfarelli, Matteo, Dario Maio, and Stefano Rizzi. "The dimensional fact model: a conceptual model for data warehouses." International Journal of Cooperative Information Systems 7, no. 02n03 (1998): 215-247.
[10] Koreichi, A., and Le Cun, B. "On data fragmentation and allocation in distributed object oriented databases." (1997).
[11] Liu, Xiufeng, and Nadeem Iftikhar. "Ontology-Based Big Dimension Modeling in Data Warehouse Schema Design." In Business Information Systems, pp. 75-87. Springer Berlin Heidelberg, 2013.
[12] Mahboubi, Hadj, and Jérôme Darmont. "Data mining-based fragmentation of XML data warehouses." In Proceedings of the ACM 11th international workshop on Data warehousing and OLAP, pp. 9-16. ACM, 2008.
[13] Mitchell, Melanie. An introduction to genetic algorithms. MIT press, 1998.