ÜCL
Implications o f Hierarchical Name Resolution and
Name Space in Dynamic Distributed Networks
Ph.D. Thesis
M aria Paula A lv e s Pereira Q uintela
D ep a rtm e n t o f E lectronic a n d E lectrical E ngineering, U niversity C ollege London,
Torrington Place, London, W C IE 7JE, U nited K ingdom
ProQuest Number: U641850
All rights reserved
INFORMATION TO ALL USERS
The quality of this reproduction is dependent upon the quality of the copy submitted.
In the unlikely event that the author did not send a complete manuscript
and there are missing pages, these will be noted. Also, if material had to be removed,
a note will indicate the deletion.
uest.
ProQuest U641850
Published by ProQuest LLC(2015). Copyright of the Dissertation is held by the Author.
All rights reserved.
This work is protected against unauthorized copying under Title 17, United States Code.
Microform Edition © ProQuest LLC.
ProQuest LLC
789 East Eisenhower Parkway
P.O. Box 1346
A b stract
M obility support is an emerging design consideration tliat poses challenging problems for all
protocol layers o f computer and com m unications networks. Nam ing systems gain a special
importance in a dynamic environment, because a network resource unique identifier has to be
dissociated from its address. This dissertation investigates the consequences and im plications of
designing a distributed naming system and its ability to support a dynamic and evolving
environment. The objective is to adopt a distributed approach so tliat scalability is introduced but
tlie extra com plexity due to the distribution o f the data is m inim ized by the use o f sim ple
state-independent transactions, where the atomicity property is relaxed, making tlie system naturally
robust and capable o f self-m anagement. The idea is to test tlie level o f distribution such a system
can support by im posing com plete independence am ong tlie system ’s nodes. Tliis thesis presents a
general name resolution protocol, called REM US (Routing Enquiiy M echanism s Utilizing
Strategy), designed according to the described strategy. Its applicability has been immediately
recognized by industry and the system is now patented [1]. REM US is capable o f resolving any
name scheme rehably and efficiently. It does not assum e any special organization to the name
syntax or the encoding o f any information into the name. Hence. REM US provides the general
service o f resolving a unique identifier into its associated data independently o f how the umque
identifier has been assigned to the network resources. A general name resolution protocol such as
REMUS is required in heterogeneous distributed environments like the Internet. The Internet is an
ever evolving and expanding computing environment witli local independent administrative
control, hence it needs s)stem s that are flexible and general enough to accom modate changes.
REM US can be tuned to resolve specific name schem es according to tlie associated applications so
tliat its performance is optimized, or it can be used as a unifying resolution protocol, encom passing
Acknowledgements
I would like to express my sincere appreciation to Dr. Mark Wilby for his experienced guidance
tliroughout tlie course o f my study and research. I am deeply indebted to liim for initially
proposing the hierarcliical control mechanism on vvliich tliis research is based and providing
crucial support throughout tlie evolution o f this work, at tlie expense o f his own com m itments and
liis other areas o f work. I would also like to tliank Dr. Mark Searle who provided me with tlie
necessary support towards the conclusion o f this study.
I especially acknowledge the help and support o f my husband, w ho always believed in my
abilities, w hich made me think much harder and be much more persistent in my work. My sweetest
tlianks goes to my little daughter Tabatha for providing me with constant inspiration and whose
sim ple way o f interpreting the world is immensely wise, having shed light on crucial points o f my
work. I carmot thank my parents and parents-in-law enough for supporting me all tlie way through
L ist o f Figures
2.1 R ecursive name resolution 20
2.2 Iterative name resolution 20
2.3 Transitive name resolution 21
2.4 Terminal and personal mobility definitions 25
2.5 GSM and IS-41 updating procedure 31
2.6 G SM call delivery procedure 32
2.7 M ob ile IP entities and their relationships 41
2.8 D N S name space 42
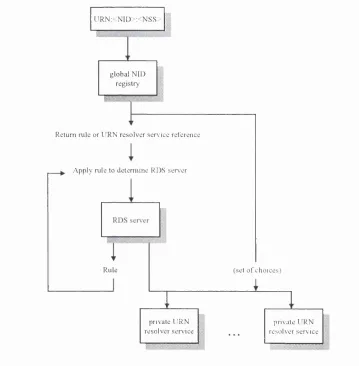
2.9 U R N resolution framework 47
3.1 R EM US Hierarchical database structure 54
3.2 R EM US basic update mechanism 55
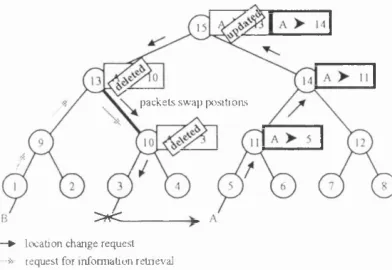
3.3 Order o f packet delivery 56
3.4 Retrieval mechanism for objects with multiple instances 56
3.5 Parallel liierarchical trees 62
3.6 Binary tree network topology 67
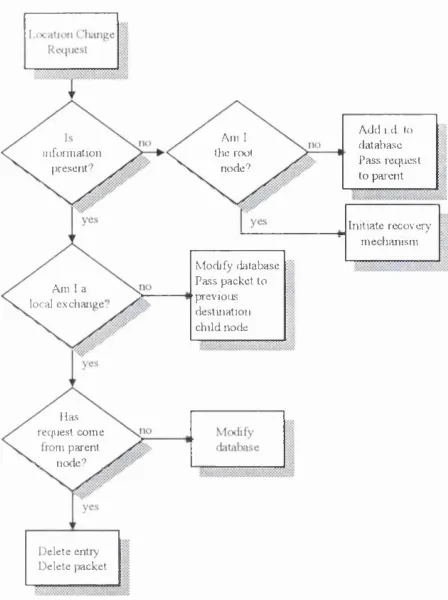
3.7 Flow diagram o f basic control mechanism for user de-registration 68
3.8 F low diagram o f basic control mechanism for database updates 69
3.9 Flow diagram o f basic control mechanism for data retrieval 69
4.1 Exam ple o f data loss detection and recovery 74
4.2 Exam ple o f incom plete location change request 81
4.3 Child node reconnection and direct link establishment 84
4.4 Restoration on demand 87
4.5 Exam ple o f first node in com m on between the paths o f the two packets 91
4.6 Exam ple o f contention problem 92
4.7 Problem due to subsequent re-configurations: case 1 93
4.8 Problem due to subsequent re-configurations: case 2 93
4.9 Link failure 98
4.10 Node failure 99
4.11 Joining two existing networks 103
4.12 Introduction o f intermediate nodes 104
4.13 Introduction o f a new local exchange 105
4.15 Flood fill scalability: case 1, approach, sub-network contains only old location 110
4.1 6 Flood fill scalability: case 2, second approach 1 11
4 .1 7 Main flow diagram for location change requests 119
4.1 8 Main flow diagram for call requests 120
4.19 Main flow diagram for stamp packets 121
4.20 Main flow diagram for resetting packets 121
6.1 Country represented as 7/ x A / square location areas 13 2
6.2 Quaternary tree matched to 4x4 country 135
6.3 Scalability results: switch throughput 140
6.4 Scalability results: end-to-end delay 140
6.5 Recovery results: average end-to-end delay for location change and call requests 143
6.6 R ecovery results: average end-to-end delay requests that detected an error 144
6.7 R ecovery results: standard deviation for average end-to-end delay 144
6.8 Recovery results: average throughput o f location cliange and call requests 145
6.9 Recovery results: contribution o f call retry rate to call request throughput at local exchanges 146
6.10 Recovery results: standard deviation o f average local exchange throughput 146
6.11 Recovery results: average local exchange tlu-oughput o f flood fill packets 147
6.12 Recovery results: comparison between detection and correction according to error rate 148
6.13 Recovery results: time interval between detection and correction according to error rate 148
6.14 Recovery results: variation o f average packet waiting time according to error rate 148
6.15 R ecovery results: variation o f average percentage o f delayed packets according to error rate 149
6.16 Recovery results: location change request tliroughput for different hierarchical levels 150
6.17 Recovery results: node capacity according to error rate for different liierarchical levels 150
6.18 Recovery results: average packet w aiting time at input buffer for different hierarchical levels 151
6.19 Recovery results: average percentage o f packets processed that have to wait to be processed 152
6.20 Recovery results: variation o f percentage o f unsuccessful first call attempts witli error rate 152
6.21 Recovery results: total percentage o f corrupted database entries according to error rate 153
6.22 Recovery results: number o f errors present in the system against simulation time 154
6.23 Recovery results: difference betw een detection and correction rates against number o f errors 155
6.24 Recovery results: number o f errors present in the system against ratio o f error to request rate 156
6.25 Recovery results: variation o f error rate with simulation time 158
6.26 Recovery results: variation o f total detection rate with simulation tim e 158
6.27 Re-configuration results: average end-to-end delay according to node serv ice tim e 1 6 1
6.28 Re-configuration results average end-to-end delay for requests that detected an error 162
6.29 Re-configuration results: percentage o f packets tliat detected an error x node service time 162
6.31 Re-configuration results; average re-configuration rate plotted against node service time 163
6.32 Re-configuration results: interval between error detection and correction x node service time 164
6.33 Re-configuration results: error detection and correction rates versus node service time 164
6.3 4 R e-configuration results: load variation according to each node initial hierarchical level 165
6.35 Re-configuration results: average percentage o f delayed packets versus node service time 165
A .l jV'/'^plot 175
A .2 Variation o f X*: according to for 0 < ^ < root 179
A .3 log 4 plot 184
C. 1 Probability o f simultaneous error detection x fraction o f corrupted database entries 194
C.2 Probability o f simultaneous error detection x reconnected ch ild ’s hierarchical level 195
C.3 Probability o f simultaneous error detection x number o f local exchanges 196
D. 1 Tim e domain representation o f contention problem 198
D .2 Contention probability x number o f entries at ex- child at re-configuration time, ea sel 205
D.3 Network diagram for case 1 206
D .4 Contention probability x total country population, case 3 207
D .5 Network diagram for case 3, expanding tlie network by joining networks together 207
D .6 Variation o f contention probability according to A c 208
D .7 Variation o f contention probability according to the immediate restoration rate 210
D .8 Variation o f contention probability according to 211
D .9 Variation o f contention probability according to movement rate per user 212
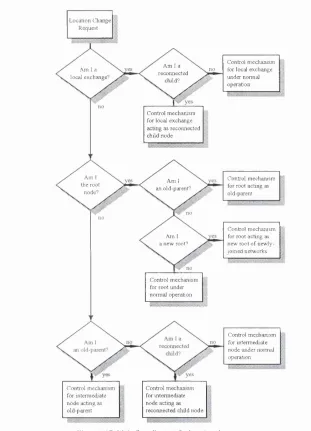
E. 1 Control m echanism for location change requests for local exchanges under normal operation 214
E.2 Control m echanism for location change requests for local exchanges as reconnected children 215
E.3 Control mechanism for location change requests for tlie root node under nonnal operation 216
E.4 Control mechanism for location cliange requests for the root node acting as old parent node 217
E.5 Control m echanism for location change requests for the root o f two newly Joined networks 217
E.6 Control m echanism for location change requests for intermediate nodes in nonnal operation 218
E.7 Control mechanism for location change requests for intermediate nodes as old parent nodes 218
E.8 Control m echanism for location change requests for intermediate nodes as ex-children 219
E.9 Control m echanism for call requests for local exchanges imder normal operation 219
E. 10 Control mechanism for call requests for local exchanges acting as reconnected child nodes 220
E. 11 Control m echanism for call requests for tlie root node in normal operation and as new root 221
E. 12 Control mechanism for call requests for the root node acting as old parent node 222
E. 14 Control mechanism for call requests for intennediate nodes acting as old parent nodes 223
E. 15 Control m echanism for call requests for intennediate nodes acting as reconnected children 224
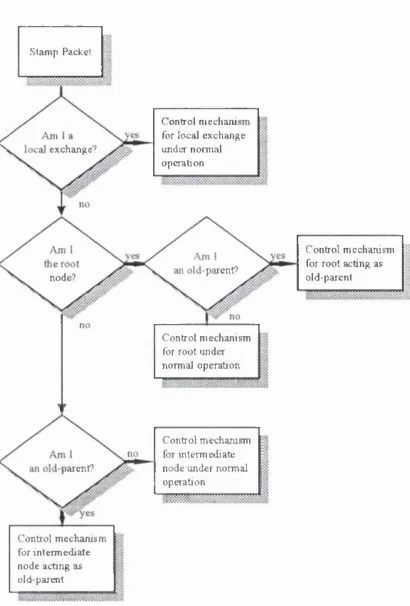
E. 16 Control m echanism for stamp packets for local exchanges 224
E. 17 Control mechanism for stamp packets for tlie root node in nonnal operation and as new root 225
E. 18 Control mechanism for stamp packets for tlie root acting as old parent node 226
E. 19 Control mechanism for stamp packets for intermediate nodes in normal operation 227
E.20 Control m echanism for stamp packets for intermediate nodes acting as old parent nodes 227
E.21 Control mechanism for resetting packets for nodes acting as reconnected children 228
F. 1 Validation plot: location change request switch throughput 234
F.2 Validation plot: call request switch throughput 234
F.3 Validation plot: location change request switch tliroughput 236
F.4 Validation plot: call request switch tliroughput 236
List o f T ables
4.1 Load distribution among network’s hierarcliical levels for location change requests 119
4.2 Load distribution am ong network’s hierarcliical levels for call requests 120
4.3 Load distribution am ong network’s hierarchical levels for stamp packets 120
4.4 Load distribution am ong network’s hierarcliical levels for resetting packets 120
6.1 Input parameters for plots in figures 6.3 and 6.4 141
6.2 Input parameters for plots in Section 6.2.2 143
6.3 Num ber o f nodes at each hierarchical level 150
6.4 Input parameters for plots in Section 6.2.3 161
C. 1 Input parameters for plot in figure C. 1 194
C.2 Input parameters for plot in figure C.2 195
C.3 Input parameters for plot in figure C.3 196
D. 1 Input parameters for case 1 205
D .2 Input parameters for case 2 206
D .4 Input parameters for case 3 206
D .4 Input parameters for and Ar^ dependencies 208
D .5 Input parameters for r dependency 209
D .6 Input parameters ior k dependency 211
F. 1 Validation results; location change requests switch throughput 235
F.2 Validation results: call requests switch throughput 235
F.3 Validation results: location change requests switch throughput 236
F.4 Validation results: call requests switch throughput 237
Chapter 1
Introduction
M obility support lias become an em erging design consideration for all protocol layers o f computer
and com m unications networks due to recent advances in tlie w ireless commmiication teclm ology
and due to the expanding area o f personal communication. Both factors are fuelling the
developm ent o f new control m echanism s capable o f supporting higlily dynam ic environments, in
w hich the bindings between terminal and location and between user and terminal are no longer
constant in time. Previous studies [1][2][3] have shown tliat a dynamic enviromnent represents a
significant load increase upon the signalling network and network databases, and that this increase
in load is dependent upon the data management strategies adopted.
The grow ing popularity o f the Internet as a communications medium and o f the World W ide Web
as an on-line distributed database means that a vast amount o f resources (files, objects, services,
pieces o f equipment, etc.) can be made available to an ever-expanding number o f users. In such an
environment, not only can the users and terminals becom e mobile, but also tlie network resources
can migrate to different parts o f the network. This represents a liighly dynamic environment, in
w hich resources are accessed, added, updated and moved constantly according to variations in
demand. M obility support is a major consideration in tlie design o f applications and services for
the Internet, so that the protocols are able to support this evolving environment.
In computer and communication networks, in order to make the network resources available, or to
use the resources that have been made available, it is necessary to be able to identify and locate the
resource in question. Tliis task is performed by the naming system s, w hich define how names are
assigned and resolved. In static environments, the definitions o f name, address, location and route
tend to m erge with each other according to the way the systems and protocols are designed. A
more extensive discussion o f the issue is given in [4] [5]. The classical definitions [ô] :
> name indicates what we seek,
> address indicates where it is, and
> route tells how to get tliere,
are ambiguous in various points. In a static environment, in w liich tlie location o f the network
resources does not change, the naming function is often merged witli tlie addressing and routing
functions. For exam ple, in the addressing system o f tlie Internet, the address does two things, first
it identifies the addressed object (destination host or network attaclunent point), i.e. tlie classical
naming function, secondly it indicates the destination and aides in routing tlie packet to it, i.e. tlie
often encoded into the name, as in area dialling codes (for fixed telephony) and network address
parts {e.g. network.subnet.host, in tlie Internet). Altliough the name is tlie entire list, each
com ponent contains information about location. Furtliennore, tlie route to a particular location,
tliough many routes may exist between two points, is just another way o f view ing tlie address o f
tliat location. Wlien tlie objects witliin a network becom e mobile, naming systems gain a special
im portance because tlie naming function has to be dissociated from tlie addressing and routing
functions since the location o f the named resource is no longer constant in time.
W itli increasing demands for mobility support in today’s com puting environments, tracking the
location o f m obile users and system ’s entities (hosts, network resources, etc.) is a problem o f
considerable research and commercial interest. The reason for this interest is because, in dynamic
distributed networks, the real-time use o f remote resources is essential. This means tliat the
network performance is dependent on the adopted name resolution system as it determines the
delays in locating tlie required resources. In computing environments such as the Internet, there is
a vast amount o f services being offered with different characteristics to satisfy different
requirements and specifications. There is the need for a mechanism for the advertising and
discovery o f services given the required attributes. Such a mechanism should be able to support a
highly dynam ic environment in which tlie service attributes and the server properties are frequently
b eing changed and updated.
With respect to naming systems, there are two main approaches to the problem, centralized and
distributed. The centralized approach, in wliich tlie information for name resolution is kept at fixed
central locations, although sim ple to implement and maintain, suffers from two serious problems;
scalability and robustness. Centralized solutions inevitably create potential points o f congestion
since tlie position o f central look-up tables is hard to optim ize and, being fixed, carmot be adapted
to variations in signalling traffic. As the network is expanded, tlie fact tliat tlie signalling has to be
re-directed to a fixed point in the network means that the signalling across the system is
proportional to tlie system size and hence is not scaleable. From the reliability point o f view ,
congestions and hardware failures can cause central databases to becom e isolated with serious
consequences to the operation o f the network.
In order to make the system scaleable, some level o f distribution has to be introduced. A
distributed strategy allow s the sharing o f signalling load across the network. The placement o f the
databases can be optim ized so that the signalling traffic due to database transactions is minimized.
With respect to robustness, the distribution o f the data makes tlie network more reliable, as the
nodes fail independently affecting only parts o f the system, which can be b>q)assed by w
ell-designed protocols. However, tlie cost o f introducing scalability and robustness is tlie need for a
more com plex protocol capable o f managing tlie communication and guciranteeing data
In this dissertation tlie benefits and consequences o f tlie distributed strategy are studied in detail. It
demonstrates tlie feasibility o f a com pletely distributed protocol in wliicli a high level of
concurrency is allowed. And how such characteristics can be explored to render a robust, flexible
and evolvable system.
1.1 C on tribu tion
This thesis investigates the consequences and implications o f designing a distributed naming
system and its ability to support a dynamic and evolving environment. Tlie objective is to adopt a
distributed approach so that scalability is introduced but tlie extra com plexity due to tlie
distribution o f tlie data is m inimized by the use o f sim ple state-independent transactions tliat make
the system naturally robust and capable o f self-management. The idea is to test the level o f
distribution such a system can support by im posing com plete independence among the system ’s
nodes.
This dissertation presents a general name resolution protocol, called REM US (Routing Enquiry'
M echanism s U tihzing Strategy), designed according to tlie described strategy. Its applicability has
been immediately recognized by industry and the system is now patented [7]. REM US is capable
o f resolving any name scheme reliably and efficiently. It does not assum e any special organization
to the name syntax or the encoding o f any information into the name. Hence, REM US provides the
general service o f resolving a unique identifier into its associated data independently o f how the
unique identifier has been assigned to the network resources. A general name resolution protocol
such as REM US is required in heterogeneous distributed enviromnents like tlie Internet. The
Internet is an ever evolving and expanding computing enviromnent witli local independent
administrative control, hence it needs systems that are flexible and general enough to
accommodate changes. REMUS can be tuned to resolve specific name schem es according to tlie
associated applications so tliat its perfonnance is optimized, or it can be used as a unify ing
resolution protocol, encom passing existing and future naming systems.
REM US main characteristics are listed below:
> Distributed system, adopting a com pletely distributed strategy.
> Hierarcliical organization o f the data.
> State-independent transactions.
> Asynchronous node operation.
> N odes have lim ited knowledge on system ’s topology and size.
> Robustness.
> M aximization o f switch tluoughput.
> Scalability.
> Maintainability.
> Legacy support and integration.
> M obility support.
> Flexibility (evolvable system).
The design strategy is that by making die nodes follow a simple set o f instructions and operate
independendy from each other, die system can be made to behave in an apparently intelligent way.
This means the system is able to detect inconsistencies, restore its database and re-configure its
topology to bypass congestions and node/link failures. If, on top o f that, die system is able to
monitor its own status and take decisions based on that, it becomes capable o f m anaging itself
w ithout the need for external intervendon. In order to preserve the system ’s distributed nature, the
transactions were made state-independent, i.e. no information is kept by ongoing transactions and
transaction atomicity is not imposed. Simple consistency checks are introduced to the basic node
functionahty so that reliabihty is provided without the need to introduce com plex monitoring
m echanism s. The objective is to m axim ize throughput, thereby improving performance. A system
diat is scaleable, robust and that can be easily re-configured and expanded with limited effect to its
operation is sim ple to manage and maintain and is capable o f adapting to evolving requirements.
1.2 O utline
This dissertation is organized as follows. Chapter 2 presents formal definitions for naming
system s, discusses the main design strategies and presents som e exam ples o f applications that
require som e level o f mobility support. This chapter also summarizes recent proposals for the
described applications and for the introduction o f mobility support into existing w ell-established
naming system s. The general mechanisms o f REMUS are outlined in Chapter 3. The system's main
characteristics are discussed in detail, together with tlie system ’s design strategy and basic control
mechanism. Chapter 3 also gives a brief description o f the personal mobility service, as this service
has been used as the underlying application for testing tlie feasibility and performance o f tlie
system ’s m echanism s.
The recovery m echanism s are discussed in Chapter 4, it explains how tlie system's basic control
m echanism s can be expanded in order to detect data inconsistencies and re-configure its topology
to bypass overloaded parts o f the network or hardware failures, and then be able to restore and
rebuild the network databases. The full protocol is described and the reasons for each design
decision are discussed in detail. Chapter 5 discusses how tlie system can be given the ability to
monitor its own signalling load in order to decide when and how to reconfigure so that tlie network
topology is optim ized according to the current usage pattern. The objective is to introduce
monitoring and decision-m aking mechanisms able to modify tlie network topology dynam ically in
response to changes in signalling traffic. This chapter also discusses methods for finding the
optimmn placement o f databases in a signalling tree so as to minimize tlie transactions average
In order lo evaluate the system's performance and to study the introduction o f the recovery
mechamsms, the system was simulated for the particular application o f the personal mobility
service. A brief description o f the simulation model and design and the obtained results and
relevant discussions are presented in Chapter 6. The first set o f results demonstrates tlie system's
scalability. The second set shows the feasibility o f the adopted recovery m echanism s and how tlie
system responds to different error rates. The third and final set o f results demonstrates the
feasibility o f the re-configuration procedure and how the system supports re-configuration under
different loading conditions. Chapter 7 presents a summary o f the project’s findings and outlines a
Chapter 2
Naming Systems
N am ing is one o f the most important and probably one o f the most frequently overlooked areas o f
computer science and communications. The remarkable growth in the telecom m unications
industry, from telegraphs to telephones to computer networks, has alleviated the problem o f being
able to com m unicate with another person or o f retrieving remote resources, provided that you
know how to reach them. The system and the users have to be able to identify and locate the
necessary resources {i.e. information, users, computer, objects, methods, services) in order to
perform the required operations. The naming service provides the principal m echanism through
w hich users and objects within the system locate other objects that they intend to use and make
requests of.
In a static environment, in which the location o f the network resources does not change, the
naming function is often merged with the addressing and routing functions. For exam ple, in the
addressing system o f the Internet, the address does two things, first it identifies the addressed
object (destination host or network attachment point), i.e. the classical naming function, secondly it
indicates the destination and aides in routing the packet to it, i.e. the classical addressing and
routing functions. In fixed networks, as the location is static, the address is often encoded into the
name, as in area dialling codes (for fixed telephony) and network address parts {e.g.
network.subnet.host, in the Internet). Although the name is the entire list, each com ponent contains
information about location. Besides, the route to a particular location, though many routes may
exist between two points, is just another way o f view ing the address o f that location.
A s m obility is introduced into the system, the relationship between network resource name and
location becom es dynam ic and hence the naming function has to be separated from the addressing
and routing functions. The impact o f mobility in computer and communications networks is
subject to extensive research mainly on the areas o f m obile computing and m obile telephony.
Many different naming system s and standards exist and are being independently developed or
expanded to cope with m obile network resources. The introduction o f mobility support into
existing naming system s means the existing infrastructure has to be used, im posing extra
constraints and requirements. In a large-scale distributed system, applications often have to deal
with a variety o f name schemes. The integration o f legacy naming systems to tlie w ide range o f
existing system s is also an important area o f study. As tlie network grows, so do its
essential. This means that tlie network performance is strongly dependent on the adopted naming
system as it determines the delays in locating the required resources.
The first four sections define wliat a naming system is and discuss the main design strategies.
Section 2.5 tlien presents tlie main applications for naming system together witli the specific
requirements for each application, focusing on tliose that require som e level o f mobility support.
The existing solutions for the described applications and recent proposals for tlie introduction o f
mobility into existing w ell-established naming systems are then discussed in Section 2.6. A
summary o f the chapter is presented in Section 2.7.
2.1 D efin ition s
This section summarizes the basic naming concepts, it defines each component out o f w liich a
naming system is built. Tlie terminology adopted is the one used in the A N SA Arcliitecture Report
ARM. 1003.01 [8]. For a full description o f the naming concepts and definitions, the reader is
referred to the mentioned document.
A nam e is a linguistic entity that singles out a particular entity from am ong a group o f entities (an
entity is defined as anything that may be o f interest). It consists o f a string o f sym bols (bits or
characters) that identifies an object [9]. There are two types o f names (although the distinction is
rarely made):
> attributive nam e is a name w hose resolution returns the entity in question, or provides a name
for the entity in a different nam ing co n text (defined below ). If tliis new name can be used to
access the entity, this new name is an address,
> invocation nam e is a name w hose resolution causes an action to be perfonned.
A naming system consists o f
> a nam ing dom ain, which defines the set o f distinguishable entities tliat can be named,
> one or more nam e sets (set o f names that are considered valid in a particular naming system),
each associated with a n am ing convention (tliat defines the acceptable forms o f names) used in
a part o f the naming system,
> a set o f n a m in g contexts, that determine what actual names have been chosen for the entities in
the n am ing dom ain, i.e. it defines a set o f b indings o f names to entities.
> a na m in g netw ork, that places restrictions on the extent to w hich entities can be named from
each o f tlie nam in g contexts. The n am ing netw ork can be seen as a directed graph, where each
vertex denotes a nam ing context and each edge denotes a b inding with a context.
> One or more nam e resolution proto co ls, that determine the entity associated with the name in
The n a m in g system is said to be com posed o f the nam e assignm ent stra teg y or nam e schem e and
tlie n a m e resolution p ro to c o l [10]. The n am e schem e is generally defined as tlie procedure for
creating and assigning unique identifiers {i.e. unique names) to tlie network resources. N am e
reso lu tio n is defined as tlie action o f isolating a particular entity from amongst a group o f entities,
given a name and an entity (and by implication a nam ing context and nam ing conventions).
Therefore, to resolve a name is to determine tlie entity associated witli the name in a given context.
The resolution p ro to c o l is the network service that resolves the name into the associated piece o f
data (usually resource physical location, description o f resource characteristics, authentication
information, etc.).
The nam e assig n m en t strategy and tlie resolution p ro to co l can be made independent from one
another. H ow ever, by encoding som e information {e.g. name server at which search should start),
the resolution mechanism can be speeded up. The name assignm ent strategy and how much
information (if any at all) should be encoded into the name are very much dependent on the
application, as each application imposes its own requirements and restrictions on the system.
A nam e b in d in g (name-to-entity association) is always defined relative to a n am ing context. In the
naming context each name is unique. Different names can be bound to an object in the same
n a m in g co n text (in w hich case they are called aliases) or different nam ing con texts (in which case
tliey are called synonym s) at the same time. Not all names in a nam e se t have to be bound to an
entity. N am es that are unbound but nevertlieless used are unresolveable. A nam e space is that part
o f a n a m in g netw o rk within which a single nam ing convention is used. Within a particular nam e
space, all names are drawn from one nam e set.
A naming system provides location transparency if the name is independent o f the entity current
location. When the path name reflects the physical structure o f tlie system, location transparency is
not present. Location transparency im plies that the entity can migrate to different locations without
having its name modified.
2.2 N am e R esolution
The general techniques identified for name resolution [9] are listed below.
> A lg o rith m clustering. Names are clustered onto name servers depending on the value that
results from applying a hash function to them. The resulting name server is independent o f
name structure or crurent object location. This means this teclinique can result in a ver>'
inefficient system in which an object might have its current location stored by a name server
located at the other extreme o f the network. This is the technique used by tlie Handle System
> Syn ta ctic clustering. This is the most com m on form o f clustering and is based around the
structure o f the name itself. For example, liierarchical name system s as in the Internet or tlie
telephone numbering plan for tlie fixed telephone network.
> A ttrib u te clustering. A more generalized form o f syntactic clustering, where the grouping of
names is based on tlie attributes tliose names possess. For exam ple, for the current m obile
telephone system s, the names are assigned a HLR according to tlieir hom e base location (HLR
identifier is encoded in the terminal’s directory number - M SISDN ). In this case, tlie attribute
used for determining the way names are grouped is static. However, the attribute can be
dynam ic as in the case o f REM US (Routing Enquiry M echanism U tilizing Strategy), the name
resolution system developed in this tliesis (see Chapter 3). In the REM US case, the grouping
is determined according to the objects current location. Hence, as the object’s current location
changes, so does the set o f name servers containing information about it.
N am e servers can cooperate in three different w ays to resolve names [9].
> R ecursive. The request migrates from server to server so tliat names are constantly being
resolved in new contexts. The migration process is carried out until a name server containing
the required information is found. The request response follow s the same chain o f name
servers as it is returned to the enquiring chent (see figure 2.1). Hence the servers are forced to
store return addresses for each ongoing lookup. The consequence is that tlie service degrades
rapidly as the number o f concurrent transactions increases. This is one o f the two strategies
used by the D om ain Name System (D N S), see Section 2.6.3 (the other one is the iterative
strategy, see below ). However, tliis strategy tends to be avoided due to the incurred overhead.
N am e w N am e N am e N am e
ag en t s erv er s e rv e r s erv er
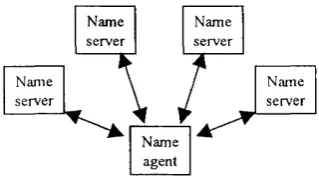
F igure 2.1 : R ec u rsiv e nam e re so lu tio n .
> Iterative. The enquiring client retains control o f the name resolution process. Each name
server contacted returns the current state o f the resolution together with the address o f the next
server to be contacted (a referral, as in tlie main strategy used in D N S - Dom ain Nam e
System, see Section 2.6.3). A lot o f the work in this case is performed by the enquiring client,
as shown in figure 2.2.
s erv er Name N am e
s erv er N am e
N am e
N am e a g en t
> Transitive. This procedure is similar lo the recursive procedure, in w hicli tlie request migrates
from name server to name server until tlie name can be resolved. However, unlike tlie
recursive procedure, tlie request response is returned straight to tlie client (refer to figure 2.3)
without tlie need to follow the sam e chain o f servers on the way back. This is tlie adopted
procedure for REM US (see Chapter 3).
N am e ag en t
N am e
N a m e
N am e
F ig u re 2.3: T ra n sitiv e nam e re so lu tio n .
2.3 N am ing System s D esign Strategies
There are tw o m ain approaches for the design o f name schem es [8] ;
> global nam e schem e — in w hich an entity name is tlie same no matter who uses tlie name,
w hen and from where,
> context relative name scheme — in which each name is bound to an entity in a particular
naming context.
The global name schem e can present elegant technical solutions in system s under the control o f a
sin gle authority. It is sim ple to use and implement, the names can be used from anywhere in the
system , im plying that the context in w hich names are resolved is invariant. However, global
naming does not provide a general solution to the naming problem in a large evolving distributed
system that may span many organizations. The problems encountered are;
> the difficulty in administrative authorities reaching an agreement for a unique absolute naming
system and in com m itting them selves to adhere to it,
> the need for a single centrahzed name allocation autliority,
> the difficulty in enforcing the global name scheme,
> as the system evolves, the maintenance o f a single system -wide context becom es
unmanageable.
Global nam ing can only work in som e specialized circumstances, in closed system s or in system s
tliat are strictly controlled by a single administration. The alternative to global naming is a context
relative nam e scheme. It allows the existence o f independent administrative domains in a
decentralized management structure, in which each administrative domain can coincide with a
naming context. This renders a flexible, adaptable and scaleable naming organization that can
respond to an evolving distributed network. Context relative naming permits tlie co-existence o f
Ihc need for Iranslalion and integration o f the different name schemes. This task can be performed
by a resolution protocol capable o f mapping tlie different name sets. REM US, the name resolution
protocol presented in tliis tliesis, is a general system capable o f integrating and resolving different
name schem es. This issue is furüier discussed in Chapter 3.
With respect to the name resolution service, tliere are also two main approaches centralized and
distributed. In a centralized system, tlie information is kept in central look-up tables and all updates
and enquiries need to be referred back to tliem. Whereas, for the distributed approach, tlie
information and data location knowledge are distributed across the w hole network. Due to the
conflicting requirements o f any existing system, tlie naming implementations often adopt one
policy but incorporate characteristics o f the other to try and improve perform ance'. A centralized
strategy does not require the overhead o f a com plex resolution protocol, the processes o f updating
and retrieving information are straightforward and no data inconsistencies arise. However, for
large, highly intercormected, dynamic networks the centralized approach can im pose prohibitive
delays w ithin the system. The central databases can represent serious bottlenecks and it is very
difficult to optim ize tlieir position to suit demand, incurring unnecessary com m unication
overheads. With respect to security, centralized systems are less vulnerable to non-autliorized
access. H owever, robustness is a problem. If the central databases are cut o ff from the system due
to node or link failures, the consequences are serious. In order to avoid the network com ing to a
halt, back-up copies o f the central databases have to be kept at different sites. To keep the back-up
copies consistent, all updates must be transmitted to tlie back-up sites. It is necessary to find tlie
optimum rate at which updates should be forwarded to tlie back-up sites so that tlie back-up copies
are kept reasonably up-to-date without compromising tlie system s performance, this means extra
com plexity and signalling overhead to the system.
Opposed to that, in a distributed approach the name resolution protocol ceases to be a sim ple table
look-up to becom e more o f a searching mechanism. By distributing the data location know ledge
across the network, the signalling load generated due to attempts to retrieve and update the
recorded data is automatically shared over the system. The usage pattern can detennine the way
tlie data records are distributed across the network so tliat tlie system can be optim ized and
bottlenecks avoided. Witli respect to robustness, it is a much more reliable system , as nodes fail
independently, affecting only parts o f the network tliat can be bypassed by w ell-designed protocols
[12]. H ow ever, a management m echanism becom es an essential part o f the system, adding extra
com plexity. A distributed system allow s incremental growth witli minimum degree o f impact on
tlie operation o f the system. The name resolution protocol has to be able to keep tlie data consistent
and up-to-date across tlie network, w hile allow ing efficient data retrieval. Consistency is
particularly problematic if congestions or link/node faihnes occur, isolating parts o f tlie network
for som e indcfinile period o f time. Name resolution protocols should be able to cope with such
problems. By distributing tlie data w e are trading tlie sim plicity o f the centralized approach witli
tlie efficien cy and low delays o f the distributed strategy.
REM US, tlie name resolution protocol presented in this tliesis adopts a com pletely distributed
strategy and represents a testbed for investigating tlie consequences and implications o f designing
a distributed naming system and its ability to support a dynamic and evolving environment. The
objective is to adopt a distributed approach so that scalability is introduced but the extra
com plexity due to the distribution o f the data is minimized by the use o f sim ple state-independent
transactions that make the system naturally robust and capable o f self-management. The idea is to
test the level o f distribution such a system can support by im posing com plete independence am ong
the system ’s nodes. This issue is further discussed in Chapter 3.
2.4 D yn am ic N am ing System s
When the nam e binding (name-to-entity association) is not static, tlie resolution protocol has to be
able to update its records dynamically. If the named entities (e.g. users, terminals, objects, services,
etc.) are m obile, then the resolution system has to be able to keep track o f tlie entities current
location.
The basic characteristic o f mobility is to allow network resources to change location and a
subscriber to be connected to the network via an access and a terminal tliat can change along the
time, without any impact on the services provided to this subscriber or to any other subscriber
registered in the network [5]. This means tliat regardless o f the terminal he uses, liis location and
the location o f the network resources he w ishes to access, the subscriber is able to make use o f tlie
network as if he were using his own terminal from home and as if tlie network resources were
static.
M obility im poses som e extra requirements on top o f the application-specific ones. The name
schem e and the resolution protocol have to be designed so that the resources can be updated,
m oved and replicated transparently to the users, i.e. without having to modify the resource name
and without any significant impact on tlie network performance. For tliis to be achieved, the
naming system has to be scaleable (i.e. tlie network can be reduced or expanded without
significantly affecting its performance), robust (i.e. congestions or hardware failures in parts o f the
network should not prevent the naming system from operating) and capable o f dealing with a high
rate o f queries and updates (in order to support resource and user mobilit>' as w ell as high network
access rate).
The impact o f mobility in computer and communications network is subject to extensive research
focuses on the impact o f mobility on naming system s and how mobility support can be introduced.
The follow in g sections present tlie main applications tliat require dynamic naming system s and
som e recently proposed solutions to the described applications.
2.5 A pplications
Nam ing system s are necessary in many services, each application has its own characteristics and
requirements. Some o f the factors that determine wliich approach should be adopted for the name
schem e and resolution protocol are given below;
> network size,
> number o f network resources,
> network usage pattern:
■ rate o f requests for data retrieval,
■ rate o f updates o f resources associated data (e.g. resources location changes),
■ percentage o f local and inter-domain requests,
> required perfonnance - QoS (Quality o f Service) requirements,
> administrative control strategy (centralized or distributed).
This section discusses som e naming system applications and their specific requirements. It
concentrates on applications that require the design o f dynam ic naming system s or the introduction
o f mobility support into existing systems.
2.5.1 Term inal and Personal M obility Services
Terminal mobility represents tlie ability to change the routing address attached to tlie terminal, it is
defined as [16].
“The ability o f a terminal to access telecom m unication seivices from different
locations and w hile in motion, and the capability o f the network to identify and
locate that tenninal.”
Personal mobility refers to tlie ability to change the relationsliip between a subscriber and tlie
terminal he uses to access the network services, again [16] defines it as
“T he ability o f a user to access telecom m unication services at any terminal on the
basis o f a personal identifier, and the capability o f the network to provide those
services according to the user's service profile.”
Further comparison o f tliese two kinds o f mobility can be found in [16]. Figure 2.4 shows the
relationships between user, terminal and network for tlie terminal and personal mobility services.
information as w ell as subscriber profile or tenninal profile information. It relies on two key
procedures:
> registration o f the current location in tlie database system {i.e. registration o f the association o f
a tenninal identity with a routing address or association o f a subscriber identity with tenninal
identity),
> retrieval o f routing information from the database system using the subscriber identification or
tlie terminal identification.
These procedures may in turn require other procedures such as authentication, profile checking,
etc. and optionally the transfer o f profile subsets to the visited area so that handling o f outgoing
requests are sim plified. This is part o f the service profile m anagement defined in [16] as the ability
to access and manipulate the user’s service profile. A user’s service profile consists o f tlie
information required to provide service to the user, including list o f specific services the user may
invoke and how incom ing and outgoing calls should be handled.
^ s ta tic ^
term in al <^ ---►s ta tic ^ n e tw o rk
^ sta tic ^
te rm in a l
^ d yn a m ic ^
--- ► n etw o rk
^ d y n a m ic ^
te rm in a l
^ s ta tic ^
<--- ► n e tw o rk
^ d y n a m ic ^
term in al ^ d y n a m ic ^ n e tw o rk
no m obility
term inal m obility
personal m obility
personal & term inal
m obility
Fig u re 2.4: T e rm in al an d perso n al m o b ility d e fin itio n s [17].
The adopted name schem e for tlie terminal mobility service in current m obile system s (G SM /lS-41
standards) is briefly outlined in Section 2.6.1. The personal mobility service has not yet been
implemented in large-scale systems. It is assumed that it w ill be provided on top o f the terminal
mobility service as part o f UM TS (Universal M obile Telecom m unications System), tlie tliird
generation for m obile networks [18]. Therefore two accesses to a naming system are necessary:
one to retrieve the identifier o f the terminal the subscriber is currently attached to, and a second
look-up to retrieve the current location o f this terminal. Proposals for enhancements and extensions
to the GSM /IS-41 system s [19] in order to improve their current performance so that personal
mobility can be supported are briefly discussed in Section 2.6.1.
The main requirements for tlie personal and terminal mobility services are listed below.
> scalability — the system design has to allow for an ever-increasing number o f subscribers
(m obile telephony has proven to be very popular, experiencing a remarkable growth since its
introduction [20] [21]),
> robustness — in an expanding network, with a high amount o f data and services distributed
cannot exist witliout m echanisms for detecting inconsistencies and recovering from
congestions and hardware failures,
> maintainability — due to tlie reasons listed in tlie previous items, the adopted naming system
has to be easy to maintain and manage,
> performance — this application requires very high switch tliroughput and low end-to-end
delays, customers are not prepared to face long delays, and competition in tliis area is fierce,
efficiency is a major requirement.
> provision o f service profile management — the data management aspects o f the problem (size
o f user profile, optimum file location, replication strategy, signalling load generated due to file
transfers, etc.).
2.5.2 Internet Protocol (IP) A ddresses
Because IP addresses encode both a network and a host on tliat network, they do not specify a host
but a connection to a host [22]. The main disadvantage is that if a host m oves from one network to
another, its network address must change. H ow ever the Internet suite o f protocols refers to tlie
hosts addresses and hence if the m obile host changes its address when it m oves, the TCP
(Transmission Control Protocol) connection breaks. However, if the old address is retained by the
mobile host, then the routing system fails to forward packets to its new location, unless
host-specific routes are propagated throughout most o f the Internet routing fabric.
In order to make this operation transparent to the user, anotlier level o f abstraction is needed in
which the host IP address is made independent from the network access point [23] [24]. This level
o f abstraction can be provided:
1) by the introduction o f a naming system that is made responsible for resolving the host IP
address into its current network attachment point. There are two main disadvantages to this
approach:
> When the Internet suite o f protocols was initially developed, it was implicitly assumed
that the name to address binding remained static. Thus, instead o f referring to hosts
through names, protocols were developed that referred to hosts through their addresses.
H ence in order to use a naming system to introduce this level o f abstraction, the Internet
protocols w ould have to be changed, particularly the transport layer protocol, TCP.
> The currently adopted Internet naming system, the Dom ain Nam e System (D N S), was
designed to work in a static environment and hence does not naturally support mobility.
Further discussions on D N S are presented in Section 2.6.3.
2) at tlie network layer, by the enhancement o f the current IP protocol. M obile IP, a protocol
intended for TCP/IP networks in general and the Internet in particular, has received a great
deal o f attention. The IETF (Internet Engineering Task Force) has been working towards a
specification for M obile IP. The strategy adopted by this proposed system is described in
The essential requirements are:
> scalability — given the huge size o f tlie Internet, its potential for further growth and the
popularity o f m obile data terminals, tliis is an important requirement,
> robustness — if the capability to deal witli failures and congestions is not present, tlien if
problems occur packets w ill be lost and tire transport layer connection (TCP connection)
might break.
2.5.3 Internet Hosts H igh-level Nam es and H ost-to-IP A ddress Resolution
U sers find names easier to use and remember tlian cumbersome network addresses. H ence a
naming system is needed to assign high-level names to Internet hosts, and store, maintain and
translate the name to address mapping. The naming system has to take into account the Internet
characteristics [22]:
> virtual network interconnecting a high number o f disparate, independent physical networks,
> local independent administrative control,
> large number o f hosts and an exponential network growing rate,
> distributed system,
> requests for data retrieval are mainly local,
> low update rate (however, with the developm ent o f m obile com puting, tlie update rate has tlie
potential to becom e high).
The minimum set o f requirements should include:
> scalability — for the same reasons as in Section 2.5.2,
> robustness — the naming system should continue operating even when faced with
congestions or hardware failures in parts o f the network,
> sub-networks should have autonomy to manage their ow n name space.
The D N S (Dom ain Nam e System) is the current adopted implementation. A brief overview o f
D N S characteristics and recent proposals to introduce som e level o f mobility support into it are
given in Section 2.6.3.
2.5.4 Library
Information stored in a library very often is kept at different geograpliical sites. If it is a static
environment (i.e. the data sources are kept at fixed locations) tlie data retrieval is trivial. However,
popular pieces o f information frequently have to be copied and moved to different locations to
avoid overloading parts o f the network (due to multiple simultaneous requests to access and
retrieve them). Further, the popularity o f pieces o f information varies with time, and hence the
environment is dynamic, having to be constantly adapted to the demand pattern. Therefore, a data
management m echanism is needed over tliis distributed dynam ic environment to update and find