Sherine et al. World Journal of Engineering Research and Technology
OPTIMIZATION OF THE SEARCH GRAPH USING HADOOP AND
LINUX OPERATING SYSTEM
P. M. Dayana Sherine*1, Gooty Dadameer1 and Manasa K.2
1
Assistant Professor, Koshys Institute of Management Studies, Bangalore. 2
Assistant Professor, Adrasha Institute of Technology, Bangalore.
Article Received on 24/07/2017 Article Revised on 14/08/2017 Article Accepted on 03/09/2017
ABSTRACT
The evolution of Social networking sites has lot of challenges for
technology firms and researchers. The Social networking sites are
gaining popularity among the users across the globe and networking of
individuals is increasing very rapidly. People search on the Social
networking sites to find old friends and other interesting people, this search operation runs in
the background of Social network. The search operation needs to be optimized to enhance the
user‟s experience. In this paper a MapReduce based search algorithm was designed and
processed on a selected Hadoop cluster. The search operation on Hadoop framework could be
affected by system parameters like memory, I/O and CPU performance etc. In this research
paper one of the functionality of memory i.e. swappiness (which handles a Swap space) is
changed & all the other parameters are kept constant to achieve the optimization of the search
operation. The search operation is optimized by processing the BigData of different sizes and
varying the swappiness which behave as a virtual memory of the system.
KEYWORDS: Social Network; Search Graph algorithms; Big Data; Hadoop; Map Reduce; Swappiness; Linux; Operating System.
INTRODUCTION
With the several advancements in computing and networking technologies are manifested to
change the way of computing in business. Many of these changes/trends emphasized through
managerial computing likewise Cloud computing, Distributed computing, and many more.
wjert, 2017, Vol. 3, Issue 5, 438-448.
World Journal of Engineering Research and Technology
WJERT
www.wjert.org
ISSN 2454-695X
Original Article
SJIF Impact Factor: 4.326
*Corresponding Author
P. M. Dayana Sherine
Sherine et al. World Journal of Engineering Research and Technology
Social network initiated at the grassroots level has been growing quickly in several sectors
and it‟s a combination of many computing technologies like Cloud computing, distributed
computing &, parallel computing. Social network leading to real business models, and
provide efficient platform for new emerging businesses. Some examples of Social network
platforms are MySpace, Bebo, FaceBook, and LinkedIn.
The internet users are empowered to connect and access any information through social
networking by rapid development and integration of various computing concepts. The
number of users increased at a fast pace and at the same time the evolvement of users is
increasing rapidly. The development & emergence of social network posed various research
problems and issues for researchers.
Humongous data is stored across the globe in the social networking sites; this data is
interacting, assimilating and coordinating. Hence this huge data may pose issues related to
fragmentation of the social graph on the networks, data security & ethical issues in the
networked globe. The data available on social networks could be used for various business
solutions like marketing, data management and other fields.
In Social networking one of the main backbone technologies is graph search algorithm. It
runs in the background of the Social network for searching and networking operation. Today,
the main problems faced by graph search algorithm are Inefficiency of the system,
unstructured graph, Poor locality, Big Data access to computation etc.
In this research, two problem areas- Inefficiency of the system and Big Data access to
computation are targeted. The Big Data computation is optimized by selecting an appropriate
configuration of the system. The system is configured in form of Hadoop cluster and
computation of Big Data is processed by designed graph search algorithm. The sample of Big
Data size is 2GB, 4GB, 8GB & 10GB & system configuration is constant for processing of
all size of data. The processing of Big Data is optimized, in terms of time complexity, by
selecting an optimum value of swappiness (form of virtual memory).The search algorithm is
designed for processing the Big Data on the Hadoop cluster and able to achieve the optimized
performance of algorithm for the designed cluster using operating system memory
Sherine et al. World Journal of Engineering Research and Technology
Development of Search Algorithm for Optimization on Hadoop Framework
The process of finding a solution can be divided in various steps, like developing an
algorithm, executing it on Hadoop framework, finding the parameters affecting the
processing, selecting the parameters for optimization & finally concluding on the efficient &
effective method of optimizing the developed algorithm.
Before understanding further, it is necessary to know the basic terminologies related to the
developed algorithm.
A. What is Distributed System?
The data is distributed in different systems and the data search operations are carried out by
connecting various systems (defined as nodes). The advantage of this system is that data can
be retrieved & stored on the network.
“The distributed is a collection of various computers, connected through a network with the
help of software called middleware. The system helps to share various resources of the all the
computers and is perceived as a single system with good, fast and integrated computing
facility”.
B. What is Parallel Process?
The concept is focused on the processing of the huge data simultaneously on the same
network. This concept is widely applicable in Big Data processing in social networks.
“Parallel processing solves Big Data problems by fragmenting them into smaller ones and
solving them at the same time. Parallel processing was considered mainly for solving
data-intensive problems encountered in computing problems related to the field of engineering,
science”.
C. What is Cloud Computing?
The principle of Cloud computing is a type of bigger platform of Distributed systems on the
internet. The nodes can be connected on a large scale; this concept has a vital usability in the
Social networking sites.
“Cloud computing: is based on a principle of sharing computing resources on internet, cloud
computing concept promotes cost effective solution for business to set virtual office with
Sherine et al. World Journal of Engineering Research and Technology
D. What is MapReduce?
Map/Reduce was first implemented by the Google search engine; the technology helps in
indexing and analyzing of the BigData. Map/Reduce distributes the data across a large.
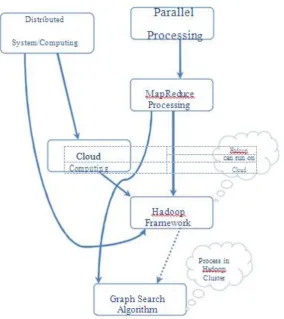
Fig. 2.1: Concept of emerging technologies in flow-diagram.
Cluster can divide the tasks to work independently, & in Parallel. This helps in swift &
efficient processing of the Big Data.[11]
E. What is Hadoop?
Hadoop was developed to support the open- source web search engine project called Nutch.
Today Hadoop is the best– known MapReduce framework in the market. Its java base
program but it also supports python and ruby programming for the development of the
algorithms.
F. Development of Algorithm
Social networking sites have become prominent tool to connect with people across the globe.
Users keep on searching people to expand their network, this search operation happens after a
Sherine et al. World Journal of Engineering Research and Technology
to enhance the user‟s experience; therefore all technology companies working on Cloud
computing; are striving to optimize the search operation.
In this research, the search algorithm is developed on MapReduce concept & processed on
the Hadoop framework. As the Hadoop framework is an open source and is a combination of
Distributed systems and Parallel processing.
Algorithm I. Mapper
Step-1- Enter the keyword to search.
Step-2- The keyword will be searched on the networking sites.
Step-3 Searched keyword data is stored in a variable Step-4 Restore all URL and text data in
new variable.
II. Reducer
Step-5 Calculate the number of search of that particular keyword on webpage/networking
site.
The Social networking site/webpage data will be stored on the Distributed system; the stored
data is further used for optimization of the search operation.
Following steps are undertaken to develop the algorithm; it is divided in two stages- Mapper
& Reducer:
The developed algorithm was processed in a Hadoop cluster and parameters like system
memory, Input-Output system & CPU are monitored to optimize the algorithm.
Figure 2.1 is the flow diagram to understand the concept of all technologies used in research.
It was observed that the system memory is the key parameter affecting the processing time of
BigData; hence in the next step, the system memory was microscopically focused for the
optimization of the algorithm. Further study shows that the swappiness of the system memory
could help in understanding the advance level optimization of the designed search algorithm.
Sherine et al. World Journal of Engineering Research and Technology
A. Swappiness
Swappiness is an important parameter of Linux kernel and its value is between “0” to
„100”.This function is basically a devoted space in the hard drive and that is generally two
times the capacity random access memory ( RAM) of the system.
Linux kernel uses this swap function by swapping the chucks from the RAM to the swap; this
allows the availability of RAM for other active and important processes.
The value of swappiness derives that, how much and how frequently the linux kernel will
copy the RAM contents to the swap memory. The system defined default value of swappiness
is “60” and it can vary between “0” to “100”.The higher value of swappiness denotes that the
kernel will be more aggressive to ummap the mapped pages and on the counter side a lower
value of swappiness shows that kernel will not tend to unmap the mapped pages.
B. Why to Change Swappiness?
The default value cannot be a perfect fit solution for all the individual cases; it depends upon
hardware specifications and user needs. Hence, it is very important to understand the
functionality of swappiness; this function derives the effcieincy of the operating system in
BigData processing, having said that, it is required to focus on swappiness function for
different system configurations to optimize the user experience on the social networks .
The applicability of swappiness with an example
Example: BigData of 10 GB is taken for processing; the system configuration has 4GB RAM
and 10 GB swap memory. The 10GB data is executed, the default value of swappiness is
“60”; in the next step it was observed that when 40% of the RAM memory is used the
processing will be handled by the swap memory. In the second iteration the swappiness is
changed from default to “100”; this resulted in slow processing of the data. The basic reason
of slow processing of the data is because swap memory act as a virtual memory, but
originally it opt space from the hard disk only.
When swappiness value is “10”; it will consume 90% of memory and 10% of swap space.
This means processing will be faster than “vm.swappiness=100”.
Therefore an experiment is set by varying the value of swappiness from “0” to “100” in the
Sherine et al. World Journal of Engineering Research and Technology
and various results of the all the set experiments on the swappiness will be discussed in the
section.
IV. Optimized Algorithm’s Results Based on Swappiness in Hadoop Cluster
To know the swappiness affect on the optimized performance of the algorithm, a cluster of
five systems was created; three out of the five performed the task of mapper/reducer (Task
trackers); one is job tracker (Controller of mapper/reducers) and one is name node (Hadoop
HDFS).
The configuration of three mapper/reducer system, job tracker and name node is 2GB RAM 2
Core processor & 100 mbps network. Big Data of different size viz. a viz. 2GB, 4GB, 8GB &
10GB are processed on the above defined Hadoop cluster. The swappiness is varied from “0” to “100” and results are obtained in terms of time (to the precision of milliseconds) taken to
process the Big Data.
Table 4.1; present the variation in swappiness and processing time of various size of the Big
Data. The Table 4.1 is presenting consolidated results of all the iterations and the details of
the each iteration are represented in the graphical format in the next few paragraphs. It can be
depicted from the table that minimum processing time of Big Data of different sizes, is falling
in the range of 45-50 swappiness. Each of the iterations is executed on the Hadoop cluster for
3 times and average Big Data processing is taken.
Table 4.1: Three Task tracker with 2GB Ram and Data are 2GB, 4GB, 8GB and 10GB. Sr. No. Swap Piness 2GB Data 4GB Data 8GB Data 10GB Data
1 0 1m28.45s* 2m32.77s 4m23.08s 14m5.75s 2 10 1m30.59s 2m31.98s 4m25.13s 11m32.31s 3 20 1m26.23s 2m32.49s 4m25.93s 12m17.16s 4 30 1m31.55s 2m32.82s 4m23.28s 11m43.57s 5 40 1m30.33s 2m33.10s 4m22.94s 12m39.60s 6 50 1m26.26s 2m28.65s 4m15.93s 10m59.60s 7 60 1m30.16s 2m31.65s 4m24.90s 11m12.18s 8 70 1m30.41s 2m31.62s 4m24.99s 11m17.37s 9 80 1m30.69s 2m31.55s 4m20.98s 13m3.28s 10 90 1m26.61s 2m33.69s 4m23.97s 10m47.51s 11 100 1m30.58s 2m36.81s 4m23.97s 11m0.26s *m- minutes, s- seconds
In the first set of experiment, 2GB BigData is processed on a Hadoop cluster of five systems
Sherine et al. World Journal of Engineering Research and Technology
the processing time of the Data. It could be depicted from the Fig. 4.1 that for swappiness
range of 45-50 (Data point is shown with green colour) the processing time reduced, while
the time taken at default value of swappiness is more and shown in blue colour in the graph.
The graph also shows some dips in the processing time at 20 % and 80% of swappiness but
these values could be rejected due to extreme lower & higher values of the swappiness; as on
lower swappiness value may face the problem during multitasking of the system due to
incapability of the Memory and on higher swappiness values may slow down the process
since swap memory use is at its peak.
The fourth set of the experiment is on 10GB Big Data processing on the same Hadoop
cluster. Fig. 4.4 shows the result of the 10GB data. The processing time presented on y-axis
against the % virtual memory (Swappiness) in Fig. 4.1 to 4.4, shows that the processing time
of all four size BigData viz. a viz. 2GB, 4GB, 8 GB & 10GB is reduced on the configured
Hadoop cluster taken for the experiment.
Fig. 4.2: Processing time for 4GB Data against swappiness.
Sherine et al. World Journal of Engineering Research and Technology
Fig. 4.4: Processing time for 10GB Data against swappiness.
The second set of the experiment is also processed on the same Hadoop cluster to swappiness
is changed in similar fashion as done in the first experiment; Fig. 4.2 shows the results of the
experiment.
The third set of the experiment is on 8GB BigData processing on the same Hadoop cluster.
Fig. 4.3 shows the result of 8GB data.
Table 4.2 presents the comparison of the processing time of BigData of 2GB, 4GB, 8GB &
10GB size with default swappiness of the Hadoop cluster and optimal value of swappiness.
The task of optimization (reduction in the processing time of BigData) is achieved in all the
sets of the experiment & the optimal range of swappiness coming for the experimental set up
is in the range 45- 50 The processing time improvement in 2GB, 4GB, 8GB & 10GB data is
4.32%, 1.98%, 3.38% & 1.87% respectively in case of optimal range of swappiness i.e.
45-50% as compared to default system value of swappiness (60%).
Table 4.2: Comparison of Processing time for Swappiness at Default & Modified value for 2gb, 4gb, 8gb and 10gb Bigdata for Hadoop Cluster.
Sr. No.
Data size
Time taken (sec) to Data process at Default Swappiness (60)%
Time taken (sec) to process Data at Swappiness range
(45- 50)%
% Improvement in processing time
(Optimization)
1 2 GB 86.269 86.785 4.32%
2 4 GB 151.658 148.654 1.98%
3 8 GB 264.903 255.938 3.38%
Sherine et al. World Journal of Engineering Research and Technology
CONCLUSION
All the experiments set to run the designed Search MapReduce algorithm on the configured
Hadoop cluster shows that optimization of BigData processing achieved by changing the
virtual memory (swappiness) in the optimal range.
These results could be extrapolated in the search operation of the Social networking sites, and
searching time can be optimized to enhance the user‟s experience. The results also shows that
range of improvement in processing time vary between 1.5 to 4.5 % for the given size of Big
Data by fixing the swappiness in the optimal range.
The sample data taken for processing varied from 2 to 10 GB, the data size is small as
compared to actual Big Data problems of the real world; but due to resource constraint the
bigger size of the data cannot be taken for the experiment. The processing of only 10 GB data
required a Hadoop Cluster of 5 systems with 2GB RAM, 2 core processor and 100mbps
network connection. The optimal swappiness range in bigger size of data would fetch us
more fruitful results in terms of optimization, of the search operation on the Social
networking sites.
The extreme lower ( below 30%) & higher ( above 70%) swappiness have given reduction in
processing time but not considered since lower swappiness create hindrance in multitasking
and higher swappiness will slow down the BigData processing.
The above fact of lower and higher % of swappiness for BigData processing; can be attained
by going in depth of the memory & processor‟s functionalities, of the operating system. For
future work researchers may take other functions of the system memory and processor; for
optimization of the BigData processing.
REFERENCE
1. Major Parameswaran and Andrew B. Whinston, “Resaearch Issues in Social Computing”,
In: Journal of the Association for Information System, 2007; 8(6): 22.
2. Preeti Narooka and Dr. Sunita Chaodhary, “Graph Search Process in Social Networks and
it's Challenges”, In IJCSET, June 2016; 6(6): 228-232.
3. Firat Tekiner and John A. Keane, “Big Data Framework”, In: International Conference on
Sherine et al. World Journal of Engineering Research and Technology
4. Preeti Narooka, Sunita Chaodhary, “Paradigm Shift of Big-Data Application in Cloud
Computing”, International Journal of Advanced Research in Computer and
Communication Engineering, 2016; 5(5): 515-521.
5. Bo Li and Prof. Raj Jain, “Survey of Recent research Progress and issues in Big Data”,
2013.
6. Harshawardhan S. Bhosale, Prof. Devendra P. Gadekar “A Review Paper on Big Data
and Hadoop” in International Journal of Scientific and Research Publications, October
2014; 4(10): 1-7.
7. Book: Bovet, Daniel & Cesati, Marco, Understanding the Linux Kernel. Copyright ©
O‟reilly Media Inc & Associates Sebastopol, CA, 2006.
8. Book: Wadkar, Sameer, and Madhu Siddalingaiah. "Hadoop Concepts", Pro Apache
Hadoop, 2014.
9. Book: Tom White, “Hadoop: The Definitive Guide”, publication is Oreilly and Yahoo
press, 2009.
10.Whitepaper: next MEDIA, CSA, “Social Networks Overview: Current Trends and
Research Challenges”, 2012.
11.Whitepaper: Jean Yan, “Big Data, Bigger Opportunities”.
Available:http://www.meritalk.com/pdfs/bdx/bdx-whitepaper-090413.pdf, 2013.
12.Whitepaper: Novell‟s Technical Whitepaper, “Determining the Correct Usage of Swap in
Linux* 2.6 Kernels”, 2007.
13.Whitepaper: Matthews, Bob & Murray, Norm, “Virtual Memory Behavior in Red Hat
Linux A.S. 2.1”, Red Hat whitepaper, Raleigh, NC, 2001.
14.Article: International Telecommunication Union – “Distributed Computing: Utilities,
Grids & Clouds Utilities, Grids & Clouds”, ITU-T Technology Watch Report, March
2009
15.Website: Bhavin Turakhia, “Understanding and Optimizing Memory Utilization”,
http://careers.directi.com/display/tu/Understanding+and +optimizing
+Memory+utilization, 2013.
16.Website:
http://unix.stackexchange.com/questions/265713/how-to-configure-swappiness-in-linux-memory-management.