Author for Correspondence:
MAY-2015
International Journal of Intellectual Advancements
and Research in Engineering Computations
ATTRIBUTE DEPENDANT DATA LINKAGE SCHEME WITH CLUSTERING
TREES
1
M. Ramya,
2Dr. V. K. Manavalasundaram.
ABSTRACT
Data linkage is the task of identifying different entries or data items refer to the same entity across different data sources. Data sets are joined without a common identifier (Foreign Key). Data linkage is divided into two types one-to-one and one-to-many. One-to-one data linkage model associates an entity from one data set with a single matching entity in another data set. One-to-many data linkage associates an entity from the first data set with a group of matching entities from the other data set. The clustering tree is constructed with each leaves contains a cluster. Each cluster is generalized by a set of rules (conditional probabilities) stored in the appropriate leaf. Clustering tree is used for data leakage prevention, recommender systems and fraud detection.
One-to-many data linkage method is used to build links between entities of different natures. One-class clustering tree (OCCT) characterizes the entities should be linked together. The OCC Tree is built to transform into association rules. Splitting and pruning operations are used for inducing the OCCT. Structure identification and split based attribute selection tasks are used in inducing a clustering tree linkage model. Probabilistic models are build to represent the leaves in the tree. The data items are linked with induced models. The linkage model is cross validated with test sets to produce score with matched probability values.
The One Class Clustering Tree (OCCT) model is extended to handle Many to Many relationship data items. Positive (matching) and negative (Non matching) pairs are integrated in the training process. The system is enhanced to handle binary, categorical and continuous attributes. Accuracy level based splitting and pruning selection process is used in the system.
INTRODUCTION
Many businesses, government agencies and research projects collect increasingly large amounts of data, techniques that allow efficient processing; analyzing and mining of such massive databases have in recent years attracted interest from both academia and industry. One task that has been recognized to be of increasing importance in many application domains is the matching of records that relate to the same entities from several databases. Often, information from multiple sources needs to be integrated and combined in order to improve data quality, or to enrich data to facilitate more detailed data analysis. The records to be matched frequently correspond to entities that refer to people, such as clients or customers, patients, employees, tax payers, students, or travellers.
The task of record linkage is now commonly used for improving data quality and integrity, to allow re-use of existing data sources for new studies and to reduce costs and efforts in data acquisition [11]. In the health sector, for example, matched data can contain information that is required to improve health policies, information that traditionally has been collected with time consuming and expensive survey methods. Linked data can also help in health surveillance systems to enrich data that is used for the detection of suspicious patterns, such as outbreaks of contagious diseases.
Statistical agencies have employed record linkage for several decades on a routinely basis to link census data for further analysis. Many businesses use reduplication and record linkage techniques with the aim to reduplicate their databases to improve data
quality or compile mailing lists, or to match their data across organizations. Many government organizations are now increasingly employing record linkage, for example within and between taxation offices and departments of social security to identify people who register for assistance multiple times and collect unemployment benefits. Other domains record linkage is of high interest are fraud and crime detection, as well as national security. Security agencies and crime investigators increasingly rely on the ability to quickly access files for a particular individual under investigation, or crosscheck records from disparate databases help to prevent crimes and terror by early intervention.
RELATED WORK
DATA LINKAGE MODELS
One-to-one data linkage was implemented using various algorithms including: an SVM classifier that is trained to distinguish between matching and nonmatching record pairs [1]; calculating expectation maximization [1] or maximum-likelihood estimation (MLE) to determine the probability of a record pair being a match; employing hierarchal clustering to link between pairs of entities [4]; and performing behavior analysis to find matching entities [2]. These methods assume that the same entities appear in the two data sets to be linked, and try to match between records that refer to the same entity. Therefore, these works are less relevant for data linkage between entities of different types. Only a few previous works have addressed one-to-many data linkage. Storkey et al. [7] use the expectation maximization algorithm for two purposes: 1) calculating the probability of a given record pair being a match, and 2) learning the characteristics of the matched records. A Gaussian mixture model is used to model the conditional magnitude distribution. No evaluation was conducted on this work.
Ivie et al. [6] use one-to-many data linkage for genealogical research. In their work, they performed data linkage using five attributes: an individual’s name, gender, date of birth, location, and the relationships between the individuals. A decision tree was induced using these five attributes. The main drawback of this method is that it is tailored to perform matches using specific attributes and, therefore, very hard to generalize. Christen and
Goiser [3] uses a C4.5 decision tree to determine which records should be matched to one another. In their work, they compare different decision trees which are built based on different string comparison methods. In their method, the attributes according to which the matching is performed are predefined and only one or two attributes are usually used. Another related research domain is coclustering. Coclustering refers to a two-dimensional clustering process in which the entities and the attributes are clustered at the same time. The OCCT model also results in clusters of instances; each may be described with a different set of attributes. The clusters are later modeled in a compact way. In this sense, the proposed OCCT method can also be used for coclustering; in this paper, we focus on the linkage task.
DECISION TREE METHODS
De Comite´ et al. introduce POSC4.5, an adaptation of the C4.5 algorithm for learning from positive examples and unlabeled examples. In addition to the given data sets, it requires knowledge of the ratio of positive examples out of the whole data set. The novelty of this approach over the C4.5 algorithm is that it proposes a modified entropy formula that considers the weight of the positive class in the given data set and assumes the number of negative examples in the unlabeled data according to the given distribution. In addition, only binary classification problems can be considered.
Letouzey et al. [9] extend the above algorithm to create a forest of trees by iterating over different possible ratios of the positive class. Then, the model which is the most accurate is chosen for use. Experimental results show very good performance when the number of positive and negative examples in the data set is similar. However, it performs very poorly on imbalanced data sets. Therefore, the solution proposed by Letouzey et al. is not suitable for our problem.
Clustering trees are structured differently than traditional decision trees. In clustering trees, each node represents a cluster. The tree as a whole describes a hierarchy. Blockeel et al. extend this idea and describe an approach in which each of the leaves contains a cluster instead of a single classification. Each leaf of the tree is characterized by a logical expression representing the instances belonging to it. According to [5] the main advantage of using clustering trees is that they provide a description for each of the clusters using a logical expression.
ONE-TO-MANY
DATA
LINKAGE
ANALYSIS
Data linkage is the task of identifying different entries that refer to the same entity across different data sources. The goal of the data linkage task is joining data sets that do not share a common identifier. Common data linkage scenarios include: linking data when combining two different databases [2]; data deduplication, which is commonly done as a preprocessing step for data mining tasks; identifying individuals across different census data sets; linking similar DNA sequences [6]; and matching astronomical objects from different catalogues [7]. It is common to divide data linkage into two types: one-to-one and one-to-many [8]. In one-one-to-one data linkage, the goal is to associate an entity from one data set with a single matching entity in another data set. In one-to-many data linkage, the goal is to associate an entity from the first data set with a group of matching entities from the other data set. Most of the previous works focus on one-to-one data linkage.
In this paper, we propose a new data linkage method aimed at performing one-to-many linkage. In addition, while data linkage is usually performed among entities of the same type, the proposed data linkage technique can match entities of different types. For example, in a student database we might want to link a student record with the courses she should take. The proposed method links between the entities using a One-Class Clustering Tree (OCCT). A clustering tree is a tree in which each of the leaves contains a cluster instead of a single classification. Each cluster is generalized by a set of rules that is stored in the appropriate leaf.
The OCCT was evaluated using data sets from three different domains: data leakage prevention, recommender systems, and fraud
detection. In the data leakage prevention domain, the goal is to detect abnormal access to database records that might indicate a potential data leakage or data misuse. The goal is to match an action, performed by a user within a specific context, with records that can be legitimately retrieved within that context. In the recommender systems domain, the proposed method is used for matching new users of the system with the items that they are expected to like based on their demographic attributes [12]. In the fraud detection domain, the goal is to identify online purchase transactions that are executed by a fraudulent user and not the legitimate user. The results show that the OCCT performs well in different linkage scenarios. In addition, it performs at least as accurate as the well-known C4.5 decision tree data-linkage model, while incorporating the advantages of a one-class solution. The OCCT is preferable over the C4.5 decision tree because it can easily be translated to linkage rules.
The contribution of this work is twofold. First and foremost, we propose a method that allows performing one to- many linkages between objects of the same or of different types. This is opposed to existing methods that are only able to link between objects of the same type. Second, we use a one-class approach. This is an important advantage because in certain domains obtaining meaningful nonmatching examples can be difficult. For example, in the fraud detection case, we can easily obtain genuine matching examples; these are actually legitimate transactions performed by users. Nonmatching examples are rare and more difficult to obtain. In such cases, nonmatching examples can be artificially created and added to the training set; we can receive examples that do not make sense. For example, a fraudulent customer purchases a product that is not being sold in the customer’s country.
PROBLEM STATEMENT
in the tree. The data items are linked with induced models. The linkage model is cross validated with test sets to produce score with matched probability values. The following problems are identified from the current data linkage analysis scheme.
• The system supports One to Many linkage model only
• Continuous data values are not supported by the system
• Split and pruning selection is not optimized • The system uses the training set with positive
matching pairs only
DATA LINKAGE WITH OCCT
The proposed solution is divided into the following steps: 1) inducing a clustering tree linkage model; 2) building probabilistic models to represent the leaves; and 3) linking items according to the induced model.
INDUCTION PROCESS
The linkage model encapsulates the knowledge of which records are expected to match each other. The induction process includes deriving the structure of the tree. Building the tree requires deciding which attribute should be selected at each level of the tree. The inner nodes of the tree consist of attributes from table TA only. Selecting the attribute is done by using one of the possible splitting criteria presented. The splitting criteria ranks the attributes based on how good they are in clustering the matching examples. In addition, a prepruning process is implemented. This means that the algorithm stops expanding a branch whenever the subbranch does not improve the accuracy of the model. The inducer is trained with matching examples only.
LEAVES REPRESENTATION
Once the construction of the tree is completed, each leaf contains a cluster of records. A set of probabilistic models is induced for each of the leaves. Each model Mi is used for deriving the
probability of a value of attribute bi
B from tableTB, given the values of all other attributes from table
TB. There are two motivations for performing this
step. First, the sets of probabilistic models result in a more compact representation of the OCCT model. Second, by representing the matching records as a set
of probabilistic models, the model is better generalized and avoids over fitting.
LINKAGE PHASE
During the linkage phase, each pair of records in the testing set is cross validated against the linkage model. The output is a score representing the probability of the record pair being a true match. The score is calculated using MLE. The tested pair is classified as a match if the score is greater than a given, predefined, threshold or, if not, as a non-match. The threshold is defined by taking into consideration the tradeoff between the false positive rate (FPR) and the true positive rate (TPR).
SPLITTING
AND
PRUNING
MECHANISM
The OCCT is induced using one of the proposed splitting criteria. The splitting criterion is used to determine which attribute should be used in each step of building the tree. In addition, we use a pruning process to decide which branches should be trimmed.
Build tree (TAB,A,B,t)
INPUT: TAB- set of matching instance s
A - Set of attributes from table TA,
B - Set of attributes from table TB
T - Threshold; the minimum size for split
OUTPUT: T (OCCT tree)
1. Node T
newNode
()
2. if
T
AB
t
OR (A)=
then3. Tmodels
)
,
(
T
,B
lsForLeaf
createMode
AB
4. else
5. a
chooseBest
Split
(
T
AB,
A
)
6. if not prune Tree(TAB
,
a
) then7. set T.attribute
a8. for each
v
i
a
9. T.Child[i]
buildTree
avT
AB,
A
\
{
a
}
,
B
,
t
10.end for12. T.Models
,
)
(
T
B
lsForLeaf
createMode
B AB
13.end if
14.end if
15. return T
Choose Best Split (TAB
,
A
)INPUT: TAB-set of matching instances,
OUTPUT: A - set of attributes from table TA
1.
sp
opt
0
2.
a
'
3. For each a in A
4.
sp
evaluateSp
lit
T
AB,
a
5. If
sp
is better thansp
opt then 6.sp
opt
sp
7. a’
a
8. End if 9. End for 10. return a’
Create Models for Leaf (TB
,
B
)INPUT: TB - set of matching instances from table
TB
B - Set of attributes from table TB
OUTPUT: M - set of models for given dataset
1. M
2. for each b
B3. Set b as class attribute of TB
4. M
Build probabilities model for TB5. M
M
m
6. End for 7. Return MALGORITHM 1 THE PSEUDO CODE
OF THE TREE INDUCTION PROCESS
Algorithm 1 describes the pseudo code of the induction process of the OCCT model. It consists of three procedures: build Tree, which is the main function; choose Best Split, in which the splitting
attribute is chosen; and create Models For Leaves, in which a set of probabilistic models are created.
The input of the algorithm is a training set of matching instances TAB instance r is a pair of
records
r
a,
r
b
:
one from table TA and one from table TB; and two lists of attributes: A describing theattributes of table TA, and TB describing the
attributes originating from table TB.
The build Tree process for building the tree
is an iterative process. Let
T
AB(d)
T
AB be the subset of matching instances at node d of the tree,and let Ad
A be the set of attributes of TA thatwere already selected as splitting attributes in the path from the root of the tree to node d. Thus, A n Ad denotes the attributes of TA that were not selected yet as splitting attributes. The process terminates either
when the subset of matching instances TAB is
smaller than the given threshold, or when there are no more candidate attributes for split in A;. Otherwise, in each iteration we find the next best splitting
attribute by evaluating every attribute a
v
1,
v
2,....,
v
n according to the selected splitting criterion (line 5).Let a be an attribute with n possible values v1, v2,. .
. ,vn. We define
}
,...
,
2 ABd2 a ad AB a d AB d
AB
a
T
T
T
T
Split
as the splitting of
T
AB d into n subsets according toattribute a
i d
AB a
di
AB
r
T
a
v
nT
i
1
,....,
|
orsimplicity reasons. We assume that a can have only
two possible values v1 and v2. Therefore, splitting
d AB
T
according to attribute a results in two sets such thatT
AB d2 a includes all records fT
ABb d2 a for which a =v1 andT
AB d a includes all records of for which a =v2. At the end we explain how to extend theOnce the best splitting attribute a is
determined, each subset
T
AB di a will be sent recursively to the procedure build Tree (lines 8-10).The selection operator of the form
p
T
AB d s used to select records inT
AB d that satisfy the given predicate p. The projection operator of the form
d AB AT
is used to select a subset of attributes in T(d) AB that appear in the attribute collection A.ATTRIBUTE
DEPENDANT
DATA
LINKAGE SCHEME
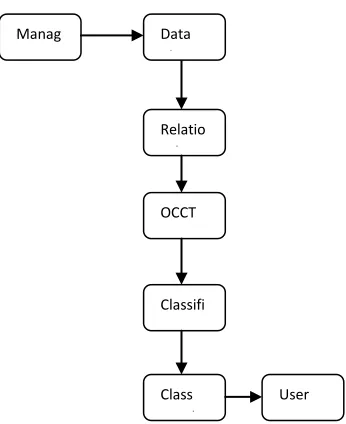
The system performs data classification in one to many and many to many data environment. The system supports all types of data values. Tree splitting threshold is dynamically adjusted by the system. The system is divided into six major modules. They are data cleaning process, clustering tree construction, splitting and pruning, multi model data process, one to many data classification and many to many data classification.
Data cleaning module is designed to perform noise removal process. Transaction grouping is performed in the clustering tree construction module. Tree separation is performed under splitting and pruning module. All types of data are analyzed under multi model data analysis module. One to many classification is designed to categorize data value. Many to many classification is used to analyze many to many relationships.
DATA CLEANING PROCESS
Data cleaning process is designed to update incomplete records. Movie review and customer transaction data sets are used in the system. Data populate process is used to update the data values in Oracle database. Training set and testing set selection is initiated by the user.
CLUSTERING TREE CONSTRUCTION
One-class clustering tree (OCCT) is used to construct the tree with transactions. Class rules are identified from the OCC Tree. The tree is constructed using matching examples from training data sets. The tree is constructed for one to many and Many to Many data linkage models.
SPLITTING AND PRUNING
Splitting and pruning tasks are applied to rearrange the OCC Tree. The splitting criteria are used to rank the attributes with matching details. Best split selection algorithm is used for the splitting process. Maximum-likelihood method is used for the pruning process.
MULTI MODEL DATA PROCESS
The OCCT scheme is constructed for the binary attributes only. The OCCT is enhanced to support binary, categorical and continuous attributes. Class rules are identified from the training process. Training process is tuned to learn rules from multi model data values.
Fig. No: 6.1. Attribute Dependant Data Linkage Scheme with Clustering Trees
Manag ement
OCCT Constr uction
User Relatio
nship Analysi s
Classifi cation
ONE TOO MANY DATA CLASSIFICATION
The classification process is carried out on the One to Many data linkage environment. Test sets are compared with the trained class rules. The class name is assigned with reference to the associated class matching information. Movie review classification is performed in the One to Many data classification process.
MANY TOO MANY DATA CLASSIFICATION
The data classification is carried out on the Many to Many data linkage models. Testing set is used for the classification process. Class identification is performed with rule set matching process. Customer transaction classification is performed in the Many to Many data classification process.
CONCLUSION
Data linkage is performed to make links between matching entities of same type or different type. One-class clustering tree (OCCT) scheme is used to identify the rules for the linkage process. The system supports one to Many and Many to Many data linkage models. The linkage model is enhanced to handle multi attribute data sets. Many to Many data linkage mechanism are adopted in the system. The system supports all data types based features. The system achieves high precision and recall ratio.
REFERENCES
[1]. D.J. Rohde, M.R. Gallagher, M.J. Drinkwater, and K.A. Pimbblet, “Matching of Catalogues by Probabilistic Pattern Classification,” Monthly Notices of the Royal Astronomical Soc., vol. 369, no. 1, pp. 2-14, May 2006.
[2]. M. Yakout, A.K. Elmagarmid, M. Quzzani and A. Qi, “Behavior Based Record Linkage,” Proc. VLDB Endowment, vol. 3, nos. 1/2, pp. 439-448, 2010.
[3]. P. Christen and K. Goiser, “Towards Automated Data Linkage and Deduplication,” technical report, Australian Nat’l Univ., 2005
[4]. L. Gu and R. Baxter, “Decision Models for Record Linkage,” Data Mining, vol. 3755, pp. 146-160, 2006.
[5]. J. Struyf and S. Dzeroski, “Clustering Trees with Instance Level Constraints,” Proc. 18th European Conf. Machine Learning, pp. 359-370, 2007
[6]. S. Ivie, G. Henry, H. Gatrell and C. Giraud-Carrier, “A Metric- Based Machine Learning Approach to Genealogical Record Linkage,” Proc. Seventh Ann. Workshop Technology for Family History and Genealogical Research, 2007
[7]. A.J. Storkey, C.K.I. Williams, E. Taylor and R.G. Mann, “An Expectation Maximisation Algorithm for One-to-Many Record Linkage,” Univ. of Edinburgh Informatics Research Report, 2005
[8]. P. Christen and K. Goiser, “Quality and Complexity Measures for Data Linkage and Deduplication,” Quality Measures in Data Mining, vol. 43, pp. 127-151, 2007.
[9]. F. Letouzey, F. Denis and R. Gilleron, “Learning from Positive and Unlabeled Examples,” Proc. 11th Int’l Conf. Algorithmic Learning Theory, pp. 71-85, 2009
[10]. C. Li, Y. Zhang, and X. Li, “OcVFDT: Class Very Fast Decision Tree for One-Class One-Classification of Data Streams,” Proc. Third Int’l Workshop Knowledge Discovery from Sensor Data, pp. 79-86, 2009.
[11]. Xiao-Lin Wang, Hai Zhao and Bao-Liang Lu, “A Meta-Top-Down Method for Large-Scale Hierarchical Classification” IEEE Transactions On Knowledge And Data Engineering, Vol. 26, No. 3, March 2014 [12]. Yubin Park and Joydeep Ghosh, “Ensembles