Calibration of choice model parameters in a transport scenario with heterogeneous traffic conditions and income dependency
Full text
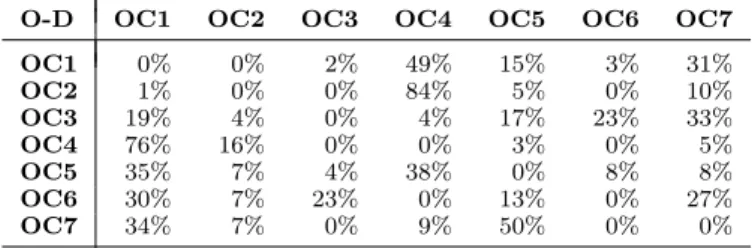
Figure
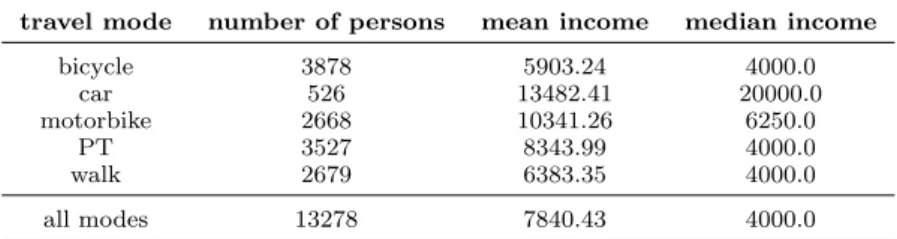



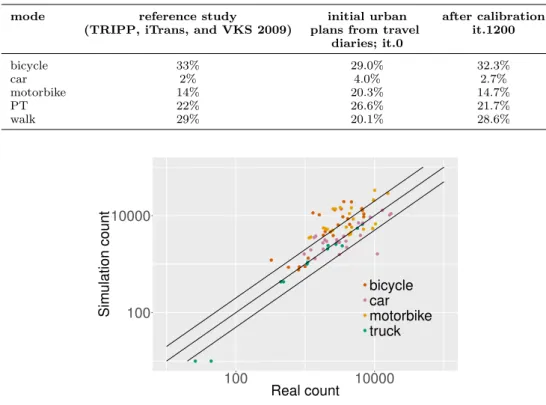
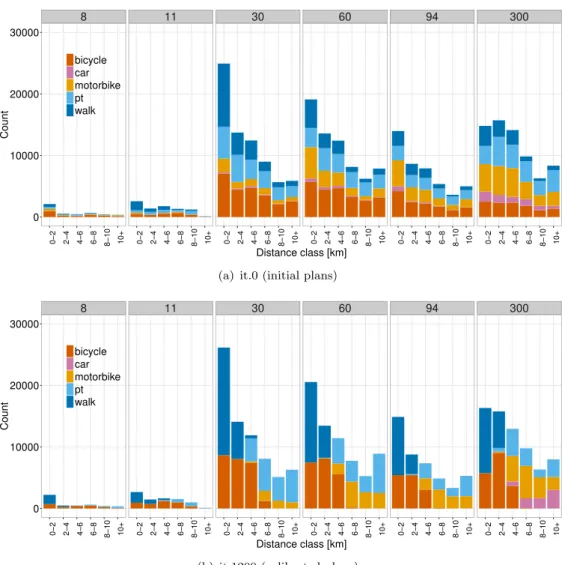
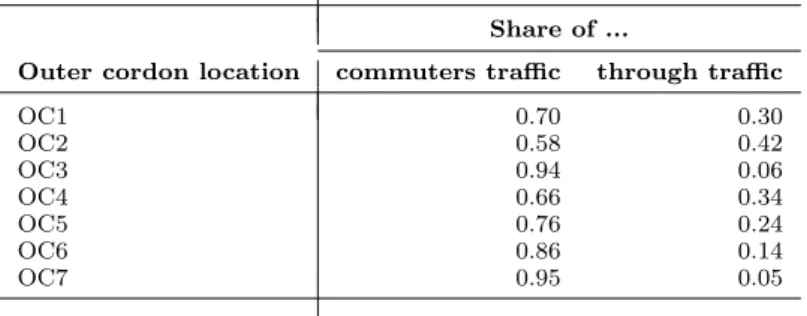
Related documents
Feedforward neural networks with a single hidden layer that use radial basis activation functions for hidden neurons are called radial basis function (RBF) networks.. RBF networks
It is along such purpose, the current study would like to find out if ABM (Accounting, Business, Management) grade XII students of Senior High School of Divine
Calculate the maximum allowable pressure difference between the inside and outside of a sphere 50 mm mean diameter with a wall 0.6 mm thick if the maximum allowable stress is 150
Applications Mgmt Virtualization Mgmt Network Mgmt Storage Mgmt Log Mgmt System Mgmt 1) Analytics 2) Event Management 3) Unified Monitoring.. © Copyright
Third-party management of insurance company general account assets continues to flourish, judged by the results of the 2015 edition of the Insurance Investment Outsourcing
Two hundred ninety-nine March-born, nulliparous heifers (253 ± 2 kg initial BW) from 3 production years were utilized to compare traditional postweaning DL development with a
I am extremely pleased that our academic priorities have become our university priorities and welcome the opportunity to work with the Academic Senate through the Executive
1) There is an identifiable relationship between problem gambling and criminal activity in clients of OARS SA. It seems that the majority of offenders who are also problem gamblers
