Processing and Preparation of OLAP data cube
50
0
0
Full text
(2) ZAHVALA Zahvaljujem se mentorju izr. prof. dr. Urošu Rajkoviču za strokovno pomoč, nasvete in usmerjanje pri izdelavi diplomskega dela. Posebna zahvala gre ženi Vesni za vso pomoč in potrpljenje. Zahvalil bi se tudi staršem, ki so mi vedno stali ob strani..
(3) POVZETEK Diplomsko delo prikazuje obdelavo in pripravo podatkov, pridobljenih iz več različnih ERP-sistemov, tako da so primerni za OLAP-kocko. Težava takšnih podatkov iz več virov je, da jih je potrebno obdelati in uvoziti v enotno podatkovno skladišče. Cilj diplomske naloge je bila izvedba OLAP-kocke, ki je potrebna za analizo podatkov. Podatke iz različnih ERP-sistemov smo predelali, očistili in potem uvozili v podatkovno skladišče. V različnih delih ETL-procesa smo podatke obdelovali z različnimi metodami, dokler niso bili primerni za uvoz v podatkovno skladišče. Iz podatkovnega skladišča je bila nato narejena OLAP-kocka. Podatki, pridobljeni iz OLAP-kocke, so bili s testirani v vrtilni tabeli in primerjani z vhodnimi podatki pred obdelavo in pripravo za uvoz v podatkovno skladišče. Podatki iz OLAP-kocke so bili nato primerni za nadaljnje analize.. KLJUČNE BESEDE . ERP priprava podatkov ETL OLAP podatkovno skladišče. ABSTRACT The thesis contains a display of processing and preparation of the data obtained from several different ERP systems so that they are suitable for the OLAP cube. The problem of such data from multiple sources is in that they must be processed and imported into a single data warehouse. The aim of the thesis was to create an OLAP cube that is suitable for BI data analysis. Data from various ERP systems was transformed, cleaned and then loaded into the data warehouse. In various parts of the ETL process data was transformed with different methods until they were eligible for import into the data warehouse. From this data warehouse an OLAP cube was made. Data obtained from OLAP cubes have been tested in the pivot table and compared with the input data prior to processing and preparation for import into the data warehouse. The data from the OLAP cube was then suitable for further analysis.. KEYWORDS . ERP data preperation ETL OLAP data warehouse.
(4) KAZALO 1.. 2.. 3.. UVOD ........................................................................................................ 1 1.1.. PREDSTAVITEV PROBLEMA .................................................................. 1. 1.2.. CILJ DIPLOMSKE NALOGE .................................................................... 1. 1.3.. RAZISKOVALNO VPRAŠANJE ................................................................. 1. 1.4.. METODE DELA..................................................................................... 2. TEORETIČNA IZHODIŠČA ........................................................................... 3 2.1.. PREDSTAVITEV OKOLJA IN PRIDOBIVANJE PODATKOV .......................... 3. 2.2.. DATOTEKE POTREBNE ZA IZDELAVO OLAP-KOCKE ................................ 4. 2.3.. ERP CELOVITE PROGRAMSKE REŠITVE ZA IZVOZ PODATKOV ................. 5. 2.4.. METODE DELA ZA PRIPRAVO PODATKOV V OLAP KOCKO ....................... 8. 2.5.. ORACLE PODATKOVNO SKLADIŠČE ....................................................... 9. 2.6.. ORACLE OLAP-KOCKA ......................................................................... 10. 2.7.. ETL-PROCES....................................................................................... 13. 2.8.. PREVERJANJE PODATKOV ................................................................... 14. 2.9.. ZDRUŽEVANJE ALI AGREGIRANJE PODATKOV....................................... 16. 2.10.. TRANSFORMACIJA PODATKOV ......................................................... 16. 2.11.. ČIŠČENJE PODATKOV ...................................................................... 17. 2.12.. UVAŽANJE PODATKOV ..................................................................... 19. 2.13.. MANIPULACIJA ALI PRESTRUKTURIRANJE PODATKOV ....................... 20. 2.14.. PROFILIRANJE PODATKOV ............................................................... 21. 2.15.. PLEMENITENJE PODATKOV .............................................................. 21. 2.16.. PREVERJANJE KAKOVOSTI PODATKOV.............................................. 22. 2.17.. PODATKOVNO RUDARJENJE ............................................................. 23. PRIPRAVA BAZE PODATKOV ....................................................................... 26 3.1.. PREVERJANJE IN ČIŠČENJE PREJETIH PODATKOV ................................ 26. 3.2.. PROFILIRANJE PREJETIH PODATKOV ................................................... 29. 3.3. TRANSFORMACIJA IN MANIPULACIJA ALI PRESTRUKTURIRANJE PODATKOV .................................................................................................. 30. 4.. 3.4.. PODATKOVNO SKLADIŠČE................................................................... 30. 3.5.. NALAGANJE PODATKOV V PODATKOVNO SKLADIŠČE ............................ 32. 3.6.. IZDELAVA OLAP-KOCKE ...................................................................... 33. TESTIRANJE V PRAKSI............................................................................... 36 4.1.. TESTIRANJE POPRAVKOV VHODNIH PODATKOV ................................... 36.
(5) 4.2. TESTIRANJE VHODNIH PODATKOV S PODATKI IZ PODATKOVNEGA SKLADIŠČA .................................................................................................. 37 4.3. 5.. TESTIRANJE OLAP-KOCKE ................................................................... 38. SKLEP ...................................................................................................... 40. LITERATURA ................................................................................................... 42.
(6) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. 1. UVOD 1.1. PREDSTAVITEV PROBLEMA Organizacije in podjetja za svoje delovanje uporabljajo velike količine podatkov. Podatki in kasneje informacije so ključnega pomena za uspešno delovanje organizacije. Podatke s pomočjo celovitih programskih rešitev ali ERP-sistemov pretvarjamo v informacijski tok, ki pomaga pri delovanju ali vodenju organizacije. Podjetja, ki za svoje delovanje uporabljajo omenjene programske sisteme, imajo celoten pregled nad poslovanjem podjetja. Vodstvo s tem dobi celovit ima tako popoln in ažuren pregled nad poslovanjem organizacije in njenih oddelkov in zaposleni imajo pregled nad stanjem procesa, da lahko in tako sledijo statusu procesa. V organizaciji s celovito programsko rešitvijo tako preko celovite programske rešitve nastane agregiran pregled nad stanjem procesov. Celovite programske opreme so združene iz več modulov, ki skupaj tvorijo ERPsistem. Osredotočili se bomo na analizo transakcij prodaje različnih podjetij, ki prodajajo medicinske pripomočke, prehranska dopolnila in ostale izdelke splošne rabe. Podatke, pridobljene od različnih podjetij iz neenakih različnih ERP-sistemov, bomo pripravili za analizo celotne prodaje vseh izdelkov. Temelj poslovnih aktivnosti (in drugih namernih dejavnosti) je obdelava informacij, kar vključuje zbiranje podatkov, skladiščenje, prenašanje, manipulacija in pridobivanje (Thomsen, 2002).. 1.2. CILJ DIPLOMSKE NALOGE Cilj diplomske naloge je bil zagotoviti oziroma pridobiti ustrezne podatke iz več različnih sistemov, za analizo in nadaljnjo obdelavo podatkov z OLAP-kocko. Potrebno je bilo pripraviti in zmanipulirati pridobljene podatke, da so ustrezali za pripravo baze. Pripravljene podatke je bilo potrebno shraniti v podatkovno skladišče in iz njega narediti dimenzije in mere v hierarhijah, ki so določene za izgradnjo OLAP-kocke. Z OLAP-kocko lahko vodilni kadri ali analitiki analizirajo svojo ali konkurenčno prodajo, naredijo analize trga in se odločajo o nadaljnji usmerjenosti prodaje.. 1.3. RAZISKOVALNO VPRAŠANJE Zanimalo nas je, kako lahko iz različnih virov podatkov (ERP-sistemov in ostalih izvozov), struktur, tipov in razlik med podatki pripravimo podatke primerne za analizo z OLAP-kocko. Poskušali smo ugotoviti, ali lahko brez specializiranih ETL orodij naredimo podatke primerne za analizo. Ali bi lahko z različnimi procesi obdelave in priprave podatkov za uvoz v podatkovno skladišče naredili podatke primerne za končno analizo? S tem smo hoteli preveriti, če bi lahko s pripravo in obdelavo podatkov pred uvozom v podatkovno skladišče in. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 1.
(7) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. izgradnjo OLAP-kocke dobili podatke, ki bi jih lahko uporabili za končne analize, še preden bi se lotili podatkovnega rudarjenja ali analiz z OLAP-kocko. Za diplomsko nalogo smo morali uporabiti orodja, s katerimi smo obdelali in pripravili podatke pred uvozom v skladišče. Vprašanje je bilo, ali ta orodja zadoščajo ali je potrebno kupiti specializirano orodje za celoten ali posamičen del ETL-procesa.. 1.4. METODE DELA Za analizo podatkov smo izdelali OLAP-kocko iz več virov ali različnih ERP-sistemov. Vsako podjetje ima svoj ERP-sistem in tako ne omogoča enak izvoz podatkov, ker se podatki v ERP-sistemu razlikujejo po podjetjih. Tudi baze podatkov znotraj ERPsistemov so različne. Podatki, pridobljeni iz raznih ERP-sistemov, niso enako strukturirani, uporabljajo se drugačni tipi datotek, pojavljajo se anomalije v podatkih, podatki manjkajo itd. Težava nastane pri združevanju podatkov v enotno podatkovno skladišče, ki je primerno za nadaljnjo izgradnjo OLAP-kocke. Uporabljene metode dela so bili procesi znotraj ETL-procesa: popravljanje podatkov, združevanje, transformacija, čiščenje podatkov, uvažanje podatkov in njihova manipulacija. Z omenjenimi metodami dela nismo uporabili specialnih ETL-orodij za celoten proces, temveč smo posamezne sklope procesov razdelili in jih rešili z drugačnimi orodji.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 2.
(8) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. 2. TEORETIČNA IZHODIŠČA Priprava podatkov je proces zbiranja, čiščenja in združevanja podatkov v podatkovna skladišča ali baze, primerne za nadaljnjo obdelavo in kasneje analizo podatkov. Proces priprave podatkov običajno vsebuje združevanje podatkov iz več virov in različnih formatov, popravljanje podatkov in vnašanje praznih vrednosti ter vnašanje manjkajočih atributov. Procesni tok, kot ga prikazuje Slika 1, od vhodnih do izhodnih podatkov primernih za analize, vsebuje več različnih podprocesov: . Izvoz podatkov iz različnih podatkovnih virov kot del ETL-procesa. Obdelava podatkov kot del ETL-procesa. Uvoz podatkov v podatkovna skladišča kot del ETL-procesa. Izdelava OLAP-kocke ali drugih izvozov primernih za nadaljnje analize.. Slika 1: Podatkovni tok podatkov od vira do OLAP-kocke (Super Develop, 2015). 2.1. PREDSTAVITEV OKOLJA IN PRIDOBIVANJE PODATKOV Transakcije podatkov podjetij smo pridobili iz različnih ERP-sistemov, kot so SAP ERP, Microsoft Dynamics NAV in Oracle E-Business Suite. Nekaj podatkov smo dobili z direktnimi izvozi s SQL-poizvedbami iz programov, ki jih podjetja uporabljajo za svoje delovanje. Ostali izvozi so bili narejeni preko integriranih poročil v internih programih, ki omogočajo uporabniku, da izbere polja, ki jih želi izvoziti, ali z ročnimi izvozi iz internih sistemov. Pridobivanje enako strukturiranih podatkov iz različnih ERP-sistemov je že samo po sebi zahtevno. Dodatna težava nastane pri integriteti podatkov iz večjih podatkovnih sistemov. Napake pri večjih bazah so zelo pogoste in atributi so mnogokrat nezanesljivi ali neuporabni (Witten, Eibe in Hall, 2011).. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 3.
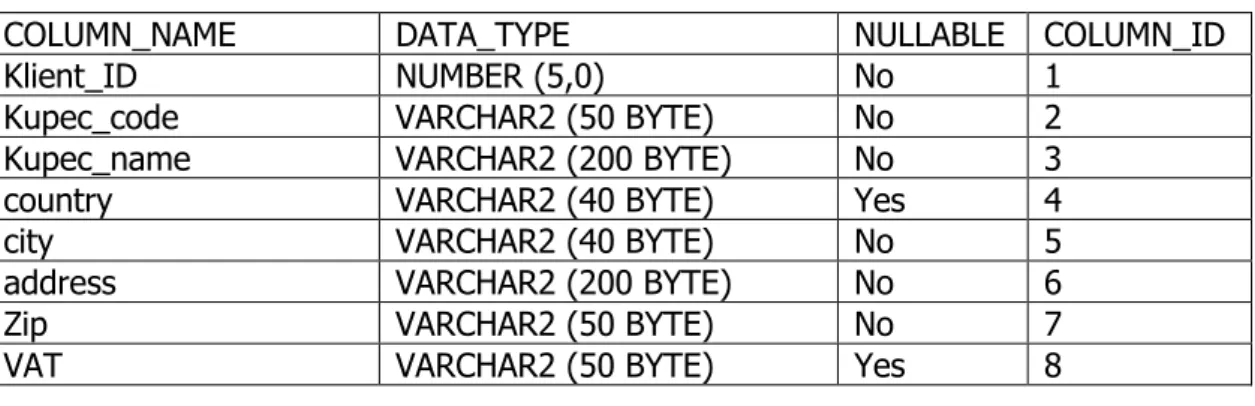
(9) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Za izvoze iz sistemov smo dobili tekstovne strukturirane datoteke ali Excel-datoteke. Organizirane so bile na dva načina: . . Serijsko – zapisi v datotekah so bili razvrščeni, kot so nastajali – po časovnem vrstnem redu. Novejši zapisi so bili na koncu datoteke. Datoteke so imele glavo in EOF (angl. End Of File). Neurejeno – zapisi v datotekah niso bili urejeni.. 2.2. DATOTEKE POTREBNE ZA IZDELAVO OLAP-KOCKE Izvozi pridobljeni iz podjetij, ki smo jih potrebovali za izdelavo OLAP-kocke, so bile narejene tri različne datoteke: . . Datoteka Kupcev (K-datoteka). Datoteka vsebuje podatke o kupcu. V njej so lahko vsi kupci ali samo kupci, ki so imeli prodajo v določenem obdobju. Datoteka Izdelkov (I-datoteka). Datoteka vsebuje podatke o izdelku. Lahko je presek vseh izdelkov v bazi ali samo izdelki, ki so bili prodani v določenem obdobju. Datoteka Prodaje (P-datoteka). Datoteka vsebuje vse podatke o transakcijah prodaje v obdobju enega meseca.. Za vse tri datoteke smo izdelali specifikacije za ureditev datotek. Skupno jim je bilo, da mora biti datoteka zapisana v kodnem zapisu UTF-8 ali Windows-1250. Kodna zapisa sta vsebovala šumnike č, š in ž. Za razdelilnik polja (angl. Field Delimiter) v podatkih med atributi smo določili razdelilnik »|«. Če je znak »|« obstajal med atributi, ga je bilo potrebno izpisati v narekovajih '|'. Polja v datotekah tipa Integer, Double, Single oziroma za vsa števila v poljih, se je uporabilo pri decimalnem zapisu za vsaj dvemi decimalnimi mesti vejica (,) in za vse vrednosti nad tisoč se naj bi izognili ločilu pika (.). Imena datotek za izdelavo kocke niso bila pomembna. Odločilno je bilo, da smo iz imena lahko razbrali vir, kdo pošilja podatke in za katero vrsto datoteke gre (K-, Iali T-datoteka). Če bi bili podatki zbirani periodično, bi bilo v nadaljevanju smotrno narediti specifikacije tudi za imenovanje datotek. Dodali bi lahko tudi datum in točno določeno strukturo poimenovanja. S tem bi dobili večjo transparentnost nad prejetimi datotekami. Datoteka Kupci Iz datoteke kupcev smo želeli pridobiti podatke končnega kupca. V datoteki so bili lahko zapisi vseh kupcev v sistemu ali pa samo izbor tistih, ki so imeli prodajo v določenem obdobju. Vsa polja v tabeli specifikacij: koda kupca, ime, kraj, naslov in poštna številka so bila obvezna. V primeru da so bila polja v datoteki prazna nam je sistem javil napako. Specifikacije polj za datoteko Kupci predstavlja Tabela 1.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 4.
(10) Univerza v Mariboru – Fakulteta za organizacijske vede. # 1. 2. 3. 4. 5.. Ime polja Koda kupca Ime Kraj Naslov Poštna številka. Diplomsko delo visokošolskega strokovnega študija. Podatkovni tip String String String String Integer. Opis polja Unikatna koda kupca Ime kupca Kraj kupca Naslov kupca Poštna številka kupca. Tabela 1: Specifikacije polj za tabelo Kupci Datoteka Izdelki V datoteki izdelkov smo poskušali pridobiti čim več podatkov, ki bi kasneje pri združevanju podatkov pomagali pri identificiranju izdelkov. Specifikacije polj za datoteko Izdelki predstavlja Tabela 2. # 1. 2. 3. 4. 5. 6.. Ime polja Koda izdelka Ime EAN Proizvajalec Enota mere DDV. Podatkovni tip String String Short String String Float. Opis polja Unikatna koda izdelka Ime izdelka Črtna koda izdelka Proizvajalec izdelka Enota mere izdelka Stopnja DDV za izdelek. Tabela 2: Specifikacije polj za tabelo Izdelki Datoteka Prodaja V datoteki prodaje so unikatna polja kupca in izdelka, vrednost prodaje in količina. Polja za datoteko Prodaja so prikazana v Tabeli 3. # 1. 2. 3. 4. 5.. Ime polja Koda izdelka Koda kupca Datum Količina Vrednost. Podatkovni tip String String Date Integer Float. Opis polja Unikatna koda izdelka Unikatna koda kupca Datum Količina prodanih izdelkov Vrednost prodanih izdelkov. Tabela 3: Specifikacije polj za tabelo Prodaja Agregirani podatki v datoteki Prodaja obsegajo obdobje enega meseca prodaje. S to datoteko smo pridobili količino prodaje izdelkov in vrednost prodaje izdelkov za obdobje enega leta.. 2.3. ERP CELOVITE PODATKOV. PROGRAMSKE. REŠITVE. ZA. IZVOZ. Večina podatkov pridobljenih za izdelavo diplomske naloge je bilo pridobljenih iz ERP-sistemov. Angleško Enterprise Resource Planning (ERP) sistemi so temeljni programi, ki jih podjetja uporabljajo za povezovanje in usklajevanje informacij na vseh področjih. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 5.
(11) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. poslovanja. ERP-programi pomagajo organizaciji upravljati poslovne procese v celotnem podjetju z uporabo skupne baze podatkov in skupnih orodij za poročanje. Poslovni proces je zbirka aktivnosti, ki ima eno ali več vrst vhodnih informacij, in ustvarja izhod, na primer poročila ali napovedi, ki predstavljajo vrednost končnemu kupcu. ERP celovita programska oprema podpira učinkovito delovanje poslovnih procesov z integracijo nalog v povezavi s prodajo, trženjem, proizvodnjo, logistiko, računovodstvom in kadrovskimi nalogami v celotnem podjetju. Poleg te navzkrižno funkcionalne integracije, ki je v središču ERP-sistema, podjetja povezujejo svoje ERP-sisteme, ki uporabljajo različne metode za usklajevanje poslovnih procesov s svojimi kupci in dobavitelji (Monk in Wagner, 2013). Podatki za izdelavo OLAP-kocke so bili pridobljeni iz treh ERP sistemov: SAP ERP, Microsoft Dynamics NAV in Oracle E-Business Suite. SAP ERP je ERP-sistem, ki ga je razvilo nemško multinacionalno programsko podjetje SAP SE (angl. Systems, Applications & Products). Podjetje velja za enega vodilnih proizvajalcev poslovnih aplikacij. Podjetje SAP ima preko 293.500 kupcev in pisarne v 190. državah po svetu. SAP ERP je del programskega kompleta SAP Business suite (SAP AG, 2016). SAP ERP je programska oprema za načrtovanje virov podjetja. Podpira vse ključne poslovne procese in funkcije, ki jih današnja podjetja zahtevajo. Zajema poslovanje, finančne podatke in upravljanje s človeškimi viri, dopolnjeno s skupnimi podjetniškimi storitvami. Industrijsko specifične izboljšave se skladajo z zahtevami programske opreme specifične za industrijo panogo kot so avtomobilska industrija, zdravstveno varstvo, visokotehnološka podjetja, trgovine na drobno ali zavarovanja (Böder in Gröne, 2014). Microsoft Dynamics NAV je ERP-sistem korporacije Microsoft. Microsoft Dynamics NAV izvira iz ERP-sistema Navision. Zbirko računovodskih aplikacij, ki jih je Microsoft odkupil v letu 2002 (Microsof Dynamics NAV, 2016). Microsoft Dynamics NAV je ERP-aplikacija, ki se uporablja v vseh različnih organizacijah po vsem svetu. Zagotavlja veliko različnih funkcionalnosti out-of-thebox na raznih področjih, kot so računovodstvo, prodaja in nabava, logistika in proizvodnja. Hkrati omogoča podjetjem razvoj aplikacij z uporabo in prilagajanjem rešitev za izpolnjevanje posebnih zahtev (Lorente in Lorente, 2013). Oracle E-Business Suite (znan tudi kot Applications / Apps ali EB-Suite / EBS) je integrirana programska poslovna rešitev. Oracle ERP-sistem je del oziroma modul zbirke Oracle E-Business Suite. Oracle E-Business Suite je sestavljen iz zbirke Enterprise Resource Planning (ERP), modulov za upravljanje odnosov s strankami (CRM) in upravljanje dobavne verige (SCM) računalniških aplikacij, razvite s strani Oracle korporacije ali pridobljenih s strani Oracle korporacije. Programska oprema uporablja jedro Oracle relacijski sistem za upravljanje podatkovnih baz s tehnologijo Oracle (Yang, 2010).. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 6.
(12) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Vsi opisani ERP sistemi omogočajo izvoz podatkov, ki smo jih prejeli in kasneje z različnimi orodji obdelali, da smo dobili željeno obliko podatkov. Zaradi različnih virov podatkov, podatkovnih baz, struktur v podatkih, nepravilnih zapisov, različnih tipov in ostalih različnih napak prihaja do težav v kakovosti podatkov. Slaba kvaliteta podatkov se lahko pojavi pri podatkih iz enega samega vira ali pri podatkih iz več neenakih virov, ki so odvisni drug od drugega in jih je potrebno združiti. Oba problema ločimo na težavo iz enega vira ali težavo iz več virov, rešita pa se lahko s pomočjo čiščenja podatkov (Rahm in Hai, 2000). Več kot je virov, večja je verjetnost, da bodo podatki slabše kakovosti. V Sliki 2 imamo prikaz klasifikacije težav po podatkovnih virih.. Slika 2: Klasifikacije težav v kvaliteti podatkov iz različnih virov (Rahm in Hai, 2000) Težava podatkov iz enega vira Pridobivanja podatkov iz samo enega vira nam lahko predstavlja več različnih težav. 1. Težava pri shemi ali opisu baze nastane zaradi pomanjkanja omejitev podatkovnih tipov in integritete omejitve atributov. Običajno se te težave pojavijo, ko baza podatkov ni pravilno zasnovana. Težava na shematskem nivoju se odraža tudi na nivoju atributov. Primeri: . Neveljavne vrednosti – vrednosti so izven definiranega območja vrednosti. Kršitev unitarnosti – podvajanje unikatnih polj. Referenčna integriteta – referenčno polje ni definirano. Kršenje odvisnosti atributov – atributi, ki so odvisni, se ne ujemajo, na primer mesto se ne ujema z njegovo poštno številko.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 7.
(13) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. 2. Težava pri atributih kot so napake, nedoslednosti in nepravilnosti v dejanski vsebini vsakega zapisa, niso opazni na ravni sheme. Napake, ki se pojavljajo na ravni atributov, obsegajo širši spekter nedoslednosti, ki ne odražajo strukturo podatkovne zbirke, vendar so podatki v navzkrižju. Primeri: . Pravopisne napake – tipkarske napake ali fonetične napake. Manjkajoče vrednosti – nedostopne vrednosti med vnosom podatkov. Vgrajene vrednosti – več vrednosti je vnesenih v en atribut. Vrednosti v napačnih poljih – atribut je zapisan v napačen stolpec. Kršenje odvisnosti atributov – atributi, ki so odvisni, se ne ujemajo, na primer mesto se ne ujema z njegovo poštno številko. Podvojene vrednosti – vrednost je podvojena. Kontradiktorne vrednosti – isti atribut ima različne vrednosti.. Težava podatkov iz več virov Ko je potrebno združiti več virov podatkov v eno podatkovno bazo, se poveča potreba po čiščenju podatkov, ker različni viri pogosto vsebujejo enake podatke, ki se večkrat pojavijo, ali se med seboj prekrivajo ali nasprotujejo. Ko so istočasno prisotne težave od shem in od atributov, pomeni, da niso težave samo pri nekaterih zapisih, ampak da so težave tudi pri strukturi baze zaradi težav s shemo podatkovne baze. Težave shem podatkovnih baz skoraj vedno povzročajo težave atributov. V kolikor se pojavita obe težavi, vplivata na ustreznost strukture baze podatkov in ustvarjata netočnosti. To pomeni tudi, da so nepravilnosti atributov povzročene ne zaradi shem, ampak zaradi napak pri vnosu (Rahm in Hai, 2000).. 2.4. METODE DELA ZA PRIPRAVO PODATKOV V OLAP KOCKO Za uspešen uvoz podatkov smo morali podatke obdelati in pripraviti za obliko, primerno za uvoz v podatkovno skladišče, iz katerega smo kasneje izdelali OLAPkocko za analizo podatkov. Podatke, primerne za uvoz, smo definirali s pomočjo specifikacij. Ker iz različnih ERP-sistemov ali ročnih izvozov in napačnih interpretacij specifikacij nismo dobili željene oblike, smo morali podatke preveriti in obdelati. Prejeti podatki so bili različnih tipov: .txt, .csv in Excel-datoteke. Imeli smo različna kodiranja ali kodne tabele tekstovnih datotek, ki so bile: UTF-8, Ansi in Unicode. V datotekah so bile prisotne prazne vrstice med podatki, na koncu ali na začetku datotek. Med preverjanjem smo pregledali še podvojene vrednosti in ostale anomalije, ki se lahko pojavijo pri izvažanju podatkov. Poleg .txt-datotek smo prejeli tudi Excelova poročila, ki so bila na enem listu in neprimerna za uvoz v bazo. S čiščenjem podatkov ali procesom Data Cleansing smo se znebili napak med podatki. S predelavo datotek smo naredili vse podatke primerne za uvoz.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 8.
(14) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Čiščenje podatkov, po angleško Data Cleansing ali Data Scrubbing, je postopek, ki odkriva in odpravlja napake in nedoslednosti iz podatkov, da se izboljša njihova kvaliteta. Težave s kakovostjo podatkov so prisotne v zbirki podatkov, kot so datoteke in podatkovne baze, na primer zaradi napačnega črkovanja med vnosom podatkov, manjkajočih podatkov ali drugih neveljavnosti v podatkih. V primeru združevanja iz več virov podatkov, ki se vključujejo v podatkovno skladišče, je potreba po čiščenju podatkov še večja (Rahm in Hai, 2000). Za obdelavo ali čiščenje podatkov smo med drugim uporabili orodja: MS Excel, MS Access, Notepad++, OpenRefine, Data Wrangler. Z izbranimi orodji smo odpravili napake, ki smo jih zaznali, in predelane ali preverjene podatke uvozili v podatkovno skladišče. Na voljo je še mnogo različnih orodij specializiranih za čiščenje podatkov, ki imajo svoje posebnosti, in so specializirana za odpravo določenih anomalij med podatki. Nekatera orodja za čiščenje podatkov so: Datacleaner, Winpure, Talend, Datapreparator. Z vsemi temi orodji se lahko obdelujejo podatki. Prejeli smo izvožene podatke iz različnih sistemov, zato smo morali obdelati izvožene datoteke. Obstajajo tudi orodja za čiščenje podatkov v ERP-sistemih in s temi orodji se lahko podatki prečistijo v samem ERP-sistemu. Med bolj pogostimi napakami v ERPsistemih je podvajanje zapisov, ko na primer več uporabnikov v sistem večkrat vnese istega kupca z drugačnim poimenovanjem. S temi orodji zelo učinkovito odpravimo omenjene napake.. 2.5. ORACLE PODATKOVNO SKLADIŠČE Prejete podatke smo uvozili v podatkovno skladišče podatkov. V našem primeru v Oracle Data Warehouse. Podatkovno skladišče je vsebinsko organizirana, integrirana, časovno odvisna in nespremenljiva zbirka podatkov za namene podpore odločitvenim procesom (Oracle, 2016). Oracle podatkovno skladišče je relacijska baza, zgrajena za poizvedbe in ne za transakcijsko tekočega procesiranja. Običajno vsebuje zgodovinske podatke, pridobljene iz transakcijskih podatkov, vendar lahko vsebuje tudi podatke iz različnih virov. Podatkovno skladišče za analize je ločeno od transakcijskega tekočega obdelovanja podatkov in omogoča organizaciji zbiranje podatkov iz ločenih virov. Takšen sistem omogoča: . ohranjanje zgodovinskih podatkov, analiziranje podatkov za pridobivanje boljšega razumevanja poslovanja podjetja in njegovo izboljšanje.. Poleg relacijske baze lahko podatkovno skladišče vsebuje ETL-rešitev, statistične rešitve, poročanje, rešitve za rudarjenje podatkov, uporabniška orodja za analizo in ostale aplikacije, ki vodijo proces zbiranja podatkov in transformiranje podatkov v uporabne podatke in jih dostavlja končnim poslovnim uporabnikom (Oracle, 1996). Podatke, ki smo jih prejeli in obdelali, smo uvozili v Oracle podatkovno skladišče.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 9.
(15) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Glavne tabele oziroma tabela dimenzij in tabela dejstev v podatkovnem skladišču so bile organizirane v obliki zvezdne sheme. Podatkovna skladišča omogočajo različno organizirane oblike ali sheme, kot je zvezdna shema, obratna zvezdna shema, snežna shema, zvezdna snežna ali ploska shema. Zvezdna shema je logična struktura, ki vsebuje v središču tabelo z dejstvi in je obkrožena z dimenzijskimi tabelami z referenčnimi podatki, ki so lahko de normalizirani. Za naš primer je bila najbolj primerna shema v obliki zvezde, kot jo prikazuje Slika 3.. Slika 3: Zvezdna shema v podatkovnem skladišču Tabela dejstev v zvezdni shemi vsebuje podatke, dejstva. Tabela ima ponavadi dva tipa stolpcev: stolpec, kjer so dejstva, in stolpec, kjer so vsi tuji ključi iz tabele dimenzij. Primarni ključ v tabeli dejstev je običajno sestavljen iz tujih ključev. Vse naravne primarne ključe se nadomesti s surogati – umetnimi ključi, kjer vsak stik med tabelo dejstev in dimenzijsko tabelo temelji na surogatih. Tabela dejstev lahko vsebuje točna ali agregirana dejstva. Tabele dejstev z agregirani podatki se večinoma imenujejo zbirne tabele dejstev ali materializiran pogled (angl. Materialized View). Iz podatkovnega skladišča smo iz teh podatkov izdelali Oracle OLAP-kocko z orodjem Oracle Warehouse Builder (OWB).. 2.6. ORACLE OLAP-KOCKA OLAP (angl. Online Analytical Processing) ali analitična obdelava podatkov s povezavo je tehnologija zbirk podatkov, ki je bila prilagojena za poizvedovanje in poročanje in ne za obdelavo transakcij. Izvorni podatki za OLAP so zbirke podatkov OLTP (transakcijska obdelava podatkov s povezavo), ki so običajno shranjene v skladiščih podatkov. Podatki OLAP so izpeljani iz podatkov iz preteklosti ter združeni v strukture, ki omogočajo zapletene analize. Podatki OLAP so urejeni hierarhično in. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 10.
(16) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. shranjeni v kocke ter ne v tabelah. Gre za izpopolnjeno tehnologijo, ki uporablja večdimenzijske strukture in tako omogoča hiter dostop do podatkov za analizo (Learn about Online Analytical Processing (OLAP), 2016). Kocka OLAP je način shranjevanja podatkov v večdimenzionalni obliki, na splošno za namene poročanja. V OLAP-kocki so podatki razvrščeni po dimenzijah, kot kaže Slika 4. OLAP-kocke so pogosto vnaprej agregirane vrednosti po dimenzijah, ki pripomorejo k občutnemu izboljšanju časa za poizvedbe preko relacijskih podatkovnih baz. Uporabljen jezik za poizvedbe ali za interakcijo in opravljane s kockami OLAP je večdimenzionalni jezik (MDX). Jezik MDX je Microsoft prvotno razvil v poznih 1990-ih in sprejeli so ga tudi drugi prodajalci večdimenzionalnih baz podatkov. Kocka je zato, ker je struktura podatkov, ki združuje mere v ravneh in hierarhijah vsake od dimenzij, ki jo hočete analizirati, podobna obliki kocke. Kocke združujejo več dimenzij, na primer čas, kupce in različne izdelke s povzetimi podatki, na primer količinska prodaja ali vrednostna prodaja, kot jo prikazuje Slika 4 (Nanda, 2015).. Slika 4: Dimenzije v OLAP kocki (Nanda, 2015) Oracle OLAP omogoča večdimenzionalno shranjevanje in izredno hitre odzivne čase pri analiziranju podatkov preko različnih dimenzij. Podatkovna baza nudi bogato podporo za analitiko časovnih kalkulacij, napovedovanje, napredno združevanje z dodatnimi in brez dodatnih in lokacijskih operatorjev. Te sposobnosti uvrščajo in spreminjajo Oracle podatkovno bazo v popolno analitično platformo, ki podpira celoten spekter poslovne inteligence in napredno analitično aplikacijo (Oracle, 2012). Zbirke podatkov OLAP vsebujejo dve osnovni vrsti podatkov: mere, ki so numerični podatki, količine in povprečne vrednosti, ki jih uporabljamo za sprejemanje utemeljenih poslovnih odločitev, ter dimenzije, ki so kategorije, ki jih uporabljamo za. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 11.
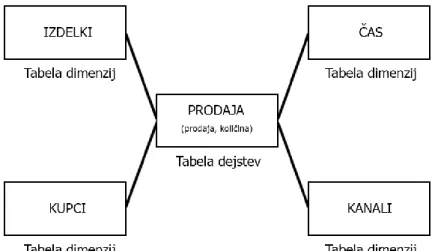
(17) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. organiziranje teh mer. Zbirke podatkov OLAP nam pomagajo organizirati podatke na več ravneh podrobnosti in uporabljajo poznane kategorije za analiziranje podatkov (Learn about Online Analytical Processing (OLAP), 2016). Kot je navedeno v (Learn about Online Analytical Processing (OLAP), 2016) so komponente znotraj OLAP-kocke: . . . . . . Dimenzija je nabor nekaj organiziranih hierarhij ravni v kocki, ki jih uporabnik razume in uporablja kot osnovo za analizo podatkov. Geografska dimenzija lahko vsebuje ravni za države, regije, mesta in občine. Dimenzija časa lahko vključuje hierarhijo z ravnmi za leto, četrtletje, mesec in tedne. Vse dimenzije lahko umetno spremenimo, da ustrezajo našim zahtevam. Na primer mesta lahko združimo v svojo regijo ali časovno dimenzijo naredimo iz več mesecev ali tednov. V OLAP-poročilih postane vsaka hierarhija nabor polj, ki jih lahko razširimo ali skrčimo, in s tem prikažemo nižje ali višje ravni dimenzije. Hierarhija je logična struktura drevesa, ki organizira člane dimenzije, da ima vsak član nadrejenega člana in nič ali več podrejenih članov. Podrejeni član je naslednji član v naslednji podrejeni ravni hierarhije, ki je neposredno soroden trenutnemu članu. V hierarhiji Čas, ki vsebuje ravni Leto, Četrtletje, in Mesec, je na primer januar podrejeni član Četrtletju1. Nadrejeni član je član v naslednji višji ravni hierarhije, ki je neposredno soroden trenutnemu članu. Nadrejena vrednost je običajno uskladitev vrednosti vseh njegovih podrejenih članov. V hierarhiji Čas, ki vsebuje ravni Leto, Četrtletje, in Mesec ter Teden, je na primer Četrtletje1 nadrejeni član januarja, ali pa mesec nadrejeni član tedna. Mera je niz vrednosti v kocki, ki temeljijo na stolpcu v tabeli dejstev kocke in so običajno številčne vrednosti. Mere so osrednje vrednosti v kocki, ki so predhodno obdelane, zbrane ali agregirane in analizirane. V našem primeru sta to količinska prodaja in vrednostna prodaja. Član je element v hierarhiji, ki predstavlja eno ali več pojavitev podatkov. Član je lahko enoličen ali neenoličen. 2015 in 2016 na primer predstavljata enolična člana na ravni let dimenzije časa, januar pa predstavlja neenolične člane na ravni mesecev, saj se lahko mesec januar pojavi večkrat, če dimenzija vsebuje podatke za več let), če dimenzija vsebuje podatke za več kot eno leto. Izračunani član je član dimenzije, katerega vrednost se izračuna ob času zagona z izrazom. Vrednosti izračunanih članov so lahko izvedene iz vrednosti drugih članov. Izračunani član Cena izdelka določi na primer z deljenjem vrednosti člana Prodaja z vrednostjo člana Količina. Raven - znotraj hierarhije so podatki lahko organizirani v nižje in višje ravni podrobnosti, na primer ravni Leto, Četrtletje, Mesec in Teden v hierarhiji Čas.. V našem primeru je bila kocka iz treh dimenzij. Uporabili smo Čas ali angleško »Time«, Izdelek ali angleško »Product« in Kupec ali angleško »Customer«. Meri sta bili Količina in Prodaja, shranjeni v tabeli dejstev.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 12.
(18) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. 2.7. ETL-PROCES Proces pridobivanja podatkov iz podatkovnih virov in nalaganje podatkov v podatkovno skladišče imenujemo ETL-proces: . . Angleško Extract je pridobivanje podatkov iz različnih virov podatkov, kot so: operacijski sistemi, ERP-sistemi, CRM-sistemi (angl. Customer Relationship Management), ploske datoteke (angl. Flat Files). Angleško Transform je preoblikovanje podatkov v pravilen format primeren za uvoz. Angleško Load je nalaganje, importiranje ali uvažanje podatkov v baze ali podatkovna skladišča.. ETL-sistem je osnova za podatkovna skladišča. Pravilno zasnovan ETL-sistem izvaža podatke, izboljšuje kakovost podatkov in doslednosti standardov, usklajuje podatke, da se lahko ločeni viri podatkov med seboj združujejo in na koncu dostavi podatke v primernem formatu, da lahko aplikacijski razvijalci izdelajo aplikacijo za končnega uporabnika (Kimball in Caserta, 2004). ETL-sistem močno pripomore h kakovosti podatkov in je veliko več kot samo izvoz podatkov iz sistemov v podatkovno skladišče. Kot navajata Kimball in Caserta (2004) je specifično za ETL-sistem, da: . odstrani napake in popravi manjkajoče podatke, zagotavlja dokumentirane ukrepe za zaupanje v podatke, zajame tok transakcijskih podatkov za shranjevanje, prilagaja podatke iz različnih virov, da se lahko uporabljajo skupaj, strukturira podatke, da so uporabni za BI-orodja za končnega uporabnika.. ETL-proces je potrebno učinkovito integrirati v sisteme, ki imajo različne (Kimball in Caserta, 2004): . sisteme za upravljanje s podatkovnimi bazami, operacijske sisteme, strojno opremo, komunikacijske protokole.. Nekaj bolj znanih komercialnih orodij za ETL-proces so Ab Initio, IBM InfoSphere DataStage, Informatica PowerCenter, Oracle Data Integrator, Microsoft Dynamics AX Transition tool, SQL server integration Sevices in SAP Data Integrator. Obstajajo tudi odprtokodni programi za ETL-proces: Apatar, CloverETL, Pentaho Data Integration, Talend. Na trgu je veliko različnih ETL-orodij, ki so prilagojeni posameznim ERP-sistemom, kot je navedeno na ETL (Extract-Transform-Load) | Data Integration Info (2016). Prvi del procesnega toka podatkov do končnega kreiranja OLAP-kocke je izvažanje podatkov. Ker podatke izvažamo iz različnih sistemov, je zelo pomemben del procesa, da dobimo pravilno izvožene podatke. Pravilno izvoženi podatki so bistveni za celoten del procesa, sicer lahko na koncu dobimo napačne podatke za analize.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 13.
(19) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Vsak podatkovni vir ima svoje značilnosti, ki jih je potrebno obvladati oziroma upravljati za učinkovit izvoz podatkov v ETL-procesu (Kimball in Caserta, 2004). Pridobivanje podatkov iz različnih, med seboj neskladnih virov podatkov na pravilen način, je pogosto najbolj zahteven del ETL-procesa, s katerim se soočimo v celem ETL-procesu. Na splošno je cilj pridobivanja podatkov preoblikovati podatke primerne za naslednji del procesa, ki ga imenujemo preoblikovanje. Vsak sistem lahko uporablja različno strukturo podatkov. Običajni viri podatkov so relacijske baze, ploske datoteke, ne-relacijski modeli baz in ostalih podatkovnih struktur. Lahko so tudi podatki pridobljeni s spletnim luščenjem. Večinoma so podatki iz izvornih sistemov zelo kompleksni, zato je izvozni del procesa zelo zapleten in težaven in zamuden (Kakish in Kraft, 2012). Naslednji del ETL-procesa je preoblikovanje podatkov. Preoblikovanje podatkov je prav tako bistven pomemben del procesa, saj se znebimo anomalij in nepravilnosti v podatkih. Podatke nato preoblikujemo v obliko, ki je primerna za uvoz v podatkovno skladišče. Nekatere podatke ni potrebno preoblikovati in jih lahko neposredno uvozimo v podatkovno skladišče. Takim podatkom pravimo “Rich Data” ali “Direct Move” ali “Pass Through” podatki. Preoblikovanje podatkov je običajno sestavljeno iz več različnih korakov, kjer vsak korak lahko izvaja shemo – transformacije, ki so med seboj povezane z naslednjimi stopnjami (preslikavami). Za zmanjšanje količine transformacij in omogočanje preoblikovanja podatkov je potrebno definirati transformacije in jih napisati v primernem jeziku. Različna ETL-orodja omogočajo transformiranje podatkov v programskih jezikih lastniškega sistema (Rahm in Hai, 2000). Podatke lahko transformiramo že pred izvozom ali pridobljene podatke kasneje preoblikujemo z različnimi koraki transformacij in validacijo: 1. Preverjanje podatkov (angl. Data Validation) je proces, ki zagotavlja, da program deluje na podlagi čistih, pravilnih in uporabnih podatkih. 2. Združevanje podatkov (angl. Data Aggregation) je proces zbiranja informacij iz podatkovnih baz z namenom, da se pripravi kombinirane podatkovne nize za obdelavo podatkov. 3. Čiščenje podatkov (angl. Data Cleansing ali Data Scrubbing) je proces odkrivanja in popravljanja ali odstranjevanje pokvarjenih ali netočnih zapisov v setih podatkov, datotekah ali bazah. 4. Preoblikovanje ali transformiranje podatkov (angl. Data Transforming) je proces preoblikovanja setov podatkov iz pridobljenih podatkov do končnih podatkov v podatkovnem sistemu.. 2.8. PREVERJANJE PODATKOV Preverjanje podatkov (angl. Data Validation) je ocenjevanje podatkov za njihov namen z uporabo vrednotenja metod, po katerih so podatki prišli, in primerjanjem teh vrednosti z neodvisnimi pridobljenimi ocenami, ki so znani ali so najboljši približke le-teh. Uporabnik podatkov s to oceno zagotovi, da podatki izpolnjujejo. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 14.
(20) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. navedena merila za veljavnost iz predpostavke, da so podatki skladni z zahtevo o potrebi po določenih podatkih (Rothenberg, 1997). Proces validacije obsega dva različna koraka: 1. proces validacije, kjer se popravljajo podatki, 2. proces odločanja po validaciji, kjer se kvalificirana oseba odloči ali so podatki pravilni. Namen popravljanja je zagotovitev, da je vsak podatek točen in pravilen, da so podatki konsistentni ne glede nato, ali gre za uporabniški vnos ali avtomatiziran sistem. Implementiranje pravil validacije v sistem je lahko tudi preko uporabniškega vmesnika, aplikacijske kode ali z omejitvami vnosov v baze podatkov. Obstaja več načinov popravljanja podatkov, kot je opisano v MSDN: Data Validation (2015): . . . . Validacija tipov podatkov, kjer preverjamo tip podatkov. Na primer: ali je polje, ki je definirano kot številka, resnično številka in ali je v polju definirano kot e-poštni naslov pravilna oblika zapisa e-poštnega naslova. Obseg in omejitev vnosa, kjer preverjamo minimum in maksimum dovoljenega vnosa. Na primer: v zapisu, kjer je poštna številka, ne sme biti število večje od 9999. Koda za preverjanje, kjer podatke testiramo in na osnovi določenih operacij primerjamo podatke s pravili, ki veljajo za vnos podatkov. Ponavadi si pomagamo z lookup tabelo. Na primer: uporabnik je pravilno vnesel svoj epoštni naslov, vendar se domena e-poštnega naslova ne ujema s podjetjem, v katerem uporabnik dela. Kompleksno strukturirano potrjevanje, kjer s kombinacijo različnih tipov validacije preverjamo podatke. Pomagamo si s pravili, ki veljajo v okolju, iz katerega pridobivamo podatke. Na primer: uporabnik ima domeno epoštnega naslov drugačnega od podjetja, v katerem dela, ker je zunanji sodelavec.. Za različne načine validacije obstaja več metod validacij: . Dovoljeni znaki (angl. Allowed Character Checks) – preverja ali so zapisani dovoljeni znaki. Vsote polj (angl. Batch Totals) – se uporablja za preverjanje skupnega število polj za konsistentnost. Preverjanje števk (angl. Check Digits) – je validacija, če so numerična polja v pravilnem zapisu. Preveri vsote (angl. Control Totals) – je validacija za skupno vsoto polj konsistentnost. Preveri prisotnost (angl. Presenece Check) – preverja, ali so vsa polja vnesena. Preverjanje unikatov (angl. Uniquness Check) – preveri, ali so v datotekah unikatni zapisi, kjer so zahtevani.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 15.
(21) Univerza v Mariboru – Fakulteta za organizacijske vede. . Diplomsko delo visokošolskega strokovnega študija. Logično preverjanje (angl. Logic Check) – preveri, ali so zapisi v poljih logični.. Opisali smo nekaj metod, ki so bile uporabljene v našem primeru. Obstaja še veliko različnih metod validacij, ki jih uporabljamo ad hoc in so odvisne od posameznega primera obdelovanih podatkov.. 2.9. ZDRUŽEVANJE ALI AGREGIRANJE PODATKOV Združevanje podatkov (angl. Data Aggregation) je vsak proces, kjer se zbirajo informacije iz podatkovnih baz z namenom, da se izražajo v obliki povzetka za nadaljnjo statistično obdelavo. Združevanje podatkov je eden ključnih elementov, ki se uporablja v podatkovnih bazah, še posebno pri poslovni inteligenci (angl. BI – Businesss Inteligence), kot je ETL in OLAP ter analitika z metodo podatkovnega rudarjenja (angl. Data Mining) (Hameurlain, Liddle, Schewe in Zhou, 2011). Agregiranje vhodnih ali izhodnih podatkov lahko združuje različne primere istega primerka v enojni primer enega primerka z izračunom vsote, povprečja, minimuma ali maksimuma. Vsak posamezen nov primer z enojnim primerkom z njegovo vsoto, minimum ali maksimumom ohranja vrednost več različnih primerkov (Witten et al., 2011). Primer agregacije podatkov, ko združujemo več zapisov v enega, je, ko imamo za isto osebo v enem mesecu večdnevnih transakcij nakupa istega izdelka. V OLAPkocki je najmanjša časovna enota mesec in zato lahko zapise združimo v enega. S tem izgubimo nekaj detajlov, v našem primeru dnevne transakcije, vendar te niso bile za naše potrebe analize relevantni. Agregirani podatki bistveno izboljšajo hitrost in zmanjšajo količino podatkov v podatkovnem skladišču. Vnaprej izračunani in shranjeni povzetki podatkov ali agregacije, ki izboljšajo odzivne čase poizvedb, so shranjeni v tabeli dejstev (angl. Fact Table).. 2.10. TRANSFORMACIJA PODATKOV Transformacija podatkov (angl. Data Transforming) je postopek pretvarjanja podatkov iz ene oblike (datoteko zbirke podatkov, tekstovnih datotek, XMLdokumentov, Excel in ostalih formatov) v drugo. Ker se podatki pogosto nahajajo na različnih lokacijah in v različnih formatih v celotnem podjetju ali iz več različnih virov in več podjetij, je kritična integracija transformacije, da se zagotovi potrebno obliko podatkov za prenos podatkov iz ene aplikacije ali baze v drugo aplikacijo ali bazo. Postopek transformacije, kot je navedeno na strani (Oracle, 2010) delimo na dva dela: 1. Preslikava podatkov (angl. Data Mapping). Razporeditev elementov iz izvorne baze ali sistema proti končni bazi ali sistemu, da ujamemo vse transformacije, ki so izvršene. Je proces v podatkovnih skladiščih, kjer so različni izvorni seti podatkov povezani z vnaprej definirani metodami, ki. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 16.
(22) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. kategorizirajo podatke po specifični definiciji v podatkovnem skladišču. Proces preslikave določi, kateri podatki se prenesejo v nov sistem. Postopek nastane še težji, ko imamo relacije ena-proti-neskončno ali neskončno-protiena. Specifikacije preslikave podatkov so posebej dragocene pri: Migraciji podatkov med viri, kjer je vir podatkov prenešen v novo skladišče. Integraciji podatkov med viri, kjer je vir podatkov redno poslan v novo skladišče in si oba vira ne delita skupnega podatkovnega skladišča. Integracija se dogaja, kadar je potrebno (dnevno, tedensko, v realnem času). Postopka sta si podobna, razlikujeta se le v tem, da se po končani migraciji izvorni podatki ne vzdržujejo, medtem ko se pri integraciji vzdržujeta oba vira podatkov. Preslikava podatkov je zelo pomemben del pri integraciji podatkov v sistemu. Pravzaprav je prvi korak pri številnih zapletenih nalogah, povezanih z integracijo podatkov, ki vključujejo transformacijo podatkov med virom podatkov in končno bazo podatkov. 2. Generiranje kode (angl. Code Generation). Generiranje programa za transformiranje. Nastala specifikacija preslikanih podatkov se uporablja za izvajanje programa transformiranja na računalniku. Pogosto uporabljeni programski jeziki za generiranje kode so Pearl, AWK, XSLT, TXL, PL/SQL. Transformacije so PL/SQL-funkcije, procedure, paketi, ki omogočajo transformacijo podatkov. Transformacije se uporabljajo, ko se oblikujejo preslikave v procesnem toku, ki definira ETL-proces.. 2.11. ČIŠČENJE PODATKOV Čiščenje podatkov (angl. Data Cleansing) je iterativen proces. Običajno je uporabnik soočen s setom podatkov, ki bi jih rad očistil, da bi podatki dosegli pričakovano raven kakovosti izbranih specifikacijah. Sam postopek čiščenja podatkov lahko potencialno predstavi ali naredi nove napake, da postanejo podatki slabše kvalitete. Zato je potrebno pred vsaki novim korakom čiščenja podatke ponovno preveriti kakovost podatkov in ponoviti ali nadaljevati s procesom čiščenja podatkov. Proces čiščenja podatkov lahko vsebuje odstranjevanje tipografskih napak ali preverjanja ali popravljanje vrednostni na osnovi že znanih entitet. Shematična predloga čiščenja podatkov ima 4 večje faze, kot je prikazano na Sliki 5.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 17.
(23) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Slika 5: Faze čiščenja podatkov (Sadiq, 2013) Sadiqu (2013) deli čiščenje podatkov v štiri faze, v katerih podatke: 1. Opredelimo in identificiramo: prvi korak je, da dobro definirano, kaj za nas predstavlja napako v podatkih. Medtem, ko so že obstoječe definicije tipov napak (manjkajoči, podvojeni, nekonsistentni) je pomembno, da identificiramo tudi tiste, ki so relevantne za naš primer. 2. Poiščemo in ovrednotimo: ko imamo definirane relevantne napake, moramo poiskati metodo, ki bo prečesala podatke, poiskala napake in jih označila. Ko so vse napake označene, lahko ovrednotimo njihovo razširjenost in definiramo kvaliteto podatkov. 3. Počistimo in popravimo: ni nujno, da se popravi ali očisti vse podatke. Nekatere napake so pomembnejše, da se popravijo, in nekatere napake nimajo nobenega vpliva za končno analizo. Ker je za vsako vrsto napak na voljo veliko metod čiščenja, se uporabnik odloči, katero metodo bo uporabil. 4. Zmerimo in preverimo: po čiščenju podatkov se preveri, ali so podatki dosegli pričakovan nivo in če so uporabni za končno analizo podatkov. Čiščenje podatkov se v določenih fazah prekriva s popravljanjem podatkov, zato so vse faze obdelave podatkov važne in se dopolnjujejo. S procesom čiščenja podatkov identificiramo in odstranimo napake v podatkih, ki jih zaznamo. Napake so lahko duplikati, nekonsistentni podatki, manjkajoči podatki in vse, kar zmanjšuje kvaliteto podatkov. Razlogov, da pride do napak v podatkih, je več: napačno črkovanje, manjkajoči atributi, napačni podatki, duplikati itd. Ko združujemo podatke v podatkovno skladišče iz več različnih sistemov in več različnih baz z različnimi formati ter odvečnimi podatki, se potreba po čiščenju podatkov še poveča. Podpora s čiščenjem podatkov se zato v podatkovnem skladišču še. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 18.
(24) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. potencira. Pri podatkovnih skladiščih, na osnovi katerih na koncu pride do procesa odločanja, je to še bolj bistveno Eden najpogosteje uporabljenih sistem za reševanje tega, je ETL-proces. Sam proces čiščenja se začne že pred transformiranjem in uvozom podatkov. Večina procesa čiščenja je narejeno ročno s pomočjo preprostih programov, ki jih je težko vzdrževati (Databases: Understanding Data Cleansing, 2015).. 2.12. UVAŽANJE PODATKOV Nalaganje podatkov (angl. Data Loading) je proces kopiranja in nalaganja oziroma importiranja, uvažanja podatkov ali setov podatkov iz izvorne datoteke, mape, aplikacije ali baze v bazo ali podatkovno skladišče ali aplikacijo. Po eksportiranju in nato transformiranju podatkov imamo podatke pripravljene za nalaganje v podatkovno bazo. Za uvažanje podatkov v podatkovno skladišče se naredijo specifikacije za uvoz podatkov. Za vnos podatkov v podatkovno skladišče poznamo tri različne načine nalaganja podatkov: . Začetni uvoz - prvo nalaganje vseh podatkov v podatkovno skladišče. Inkrementalni uvoz – po potrebi nalaganje samo tekočih sprememb v določenih obdobjih Popolnoma novi uvoz – popolni izbris vsebine ene ali več tabel in nova naložitev podatkov v tabele.. Ker je nalaganje podatkov lahko zelo zamudno opravilo, jih je potrebno izvajati premišljeno, ob pravem času. Med nalaganjem podatkov v tabele so le-te nedosegljive in jih medtem uporabniki ne morejo koristiti ali z njimi delati. Za večje količine nalaganja podatkov v podatkovna skladišča uporabljamo specialne programe, ki omogočajo hitre metode nalaganja. Za vse načine nalaganja podatkov moramo predhodno pripraviti datoteko podatkov, ki jo bomo naložili v bazo. Kot navaja Ponniah (2001), poznamo štiri načine nalaganja podatkov (Slika 6): . . Nalaganje (angl. Load) – če ciljna tabela že obstaja in so v njej podatki, potem proces nalaganja podatkov izbriše vse obstoječe podatke in naloži podatke iz prihajajoče datoteke. Če je tabela pred nalaganjem prazna, potem proces enostavno napolni tabelo iz prihajajoče datoteke. Pripni (angl. Append) – je pravzaprav podaljšek nalaganja. Če podatki v ciljni tabeli že obstajajo, potem način pripenjanja le doda prihajajoče podatke in obstoječe podatke ohrani nedotaknjene. Če so podatki, ki se nalagajo že v ciljni tabeli in so zato podvojeni, lahko definiramo, kako bomo obravnavali podvajanje podatkov. Prva možnost je, da dovolimo podvajanje podatkov, druga možnost je, da se podvojeni podatki ignorirajo ali zavrnejo med postopkom nalaganja v ciljno tabelo.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 19.
(25) Univerza v Mariboru – Fakulteta za organizacijske vede. . . Diplomsko delo visokošolskega strokovnega študija. Destruktivno združevanje (angl. Destructive Merge) – v tem načinu pripnemo podatke v obstoječo tabelo. Če se prihajajoči primarni ključ ujema s ključem v obstoječi tabeli, se posodobi obstoječ zapis z novim zapisom. Če prihajajoči zapis še ni v obstoječi tabeli, se samo zapiše v tabelo. Konstruktivno združevanje (angl. Constructive Merge) – ta način je malo drugačen od destruktivnega združevanja. Če primarni ključ prihajajočega zapisa obstaja v obstoječi tabeli, potem pusti obstoječi zapis in doda prihajajoči zapis ter označi dodan zapis kot nadomestni zapis starega zapisa.. Slika 6: Razlike med nalaganjem podatkov v podatkovno skladišče (Ponniah, 2001).. 2.13. MANIPULACIJA ALI PRESTRUKTURIRANJE PODATKOV Manipulacija ali prestrukturiranje podatkov (angl. Data Wrangling) je celoten proces manipuliranja z nestrukturiranimi ali neurejenimi podatki v strukturirano in čisto obliko. Gre za ohlapen proces, kjer ročno ali s pomočjo pol-avtomatskih orodij pretvarjamo ali preslikavamo podatke iz »surove« oblike v drugo strukturirano in čisto obliko primerno za nadaljnjo obdelavo. Postopek prestrukturiranja se z določenimi deli procesa prepleta s postopki čiščenja, preverjanja in transformiranja podatkov. Z omenjenim procesom, ki je tudi zelo zamuden, prestrukturiramo surove podatke in jih pripravimo za nadaljnji proces, ki sega vse do analize podatkov. Pravilno strukturirani podatki pripomorejo k natančnejši analizi (Trifacta, 2016). Podatke, pridobljene iz različnih sistemov, ne dobimo vedno strukturirane v obliki (Excel, pdf, razni generični izvozi), ki jo želimo ali jo potrebujemo za nadaljnjo. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 20.
(26) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. obdelavo. Z manipulacijo ali prestrukturiranjem podatkov podatke prestrukturiramo v obliko, ki je primerna za uvoz in nadaljnjo obdelavo.. 2.14. PROFILIRANJE PODATKOV Profiliranje podatkov (angl. Data Profiling) je sistematična analiza podatkov, ki opiše njihovo vsebino, konsistentnost in strukturo. Profiliranje podatkov ima strateško in taktično nalogo. Na začetku vsakega projekta podatkovnega skladišča, takoj ko podatki prispejo, se mora narediti hitra ocena, ki pomaga pri odločitvi, ali se nadaljuje s projektom ali se projekt ustavi. Kasnejše spoznanje, da podatki ne ustrezajo projektu, je lahko usodno za celoten projekt. Profiliranje je stalen proces raziskovanja. V procesu podatkovnega skladišča je idealno mesto za odkrivanje podatkovnih napak na začetku – pri viru (Kimball in Caserta, 2004). Z dobro analizo profiliranja podatkov pridobimo opise skladišča specifičnih metapodatkov: . opredelitve shem, poslovne objekte, domene, vire podatkov, definicije tabel, sopomenke, pravila podatkov, pravila vrednosti.. Kot je navedeno v Kimball in Caserta (2004), s tem profiliranjem podatkov pridobimo kvantitativno oceno originalnih virov podatkov.. 2.15. PLEMENITENJE PODATKOV Plemenitenje podatkov (angl. Data Augmentation) je proces, ki doda vrednost obstoječim podatkom (šifrantom, dimenzijam ali atributom) z uporabo internih ali eksternih virov. Proces se lahko implicira na več različnih oblikah podatkov. Plemenitenje podatkov doda dodatno vrednost, na primer: kupcem dodamo koordinate k naslovu, izdelkom dodamo dodatne atribute, kot je proizvajalec, vzorcem prodaje dodamo demografske podatke. S tem dobimo poglobljen vpogled v podatke in dodatne analize. Prav tako pripomore k zmanjšanju ročnih posegov v posredovanje pomembnih informacij in močno poveča kvaliteto podatkov. Kot je navedeno na strani Techopedia (2016), so pogoste tehnike za plemenitenje podatkov: . Ekstrapolacija – temelji na hevristiki. Ustrezna polja so posodobljena ali pa so dodane vrednosti. Označevanje – pogosti zapisi so označeni in združeni ter jih je lažje razumeti in ločiti od ostalih zapisov.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 21.
(27) Univerza v Mariboru – Fakulteta za organizacijske vede. . Diplomsko delo visokošolskega strokovnega študija. Agregiranje – s pomočjo matematičnih vrednosti so izračunane določene vrednost za ustrezna polja, če so potrebna. Verjetnost tehnika - glede na hevristiko in analitično statistiko so vrednosti izpolnjene na podlagi verjetnostnih dogodkov.. 2.16. PREVERJANJE KAKOVOSTI PODATKOV Cilj preverjanja kakovosti podatkov (angl. Data Quality Asesment) je določanje kvalitete podatkov za poslovne ali druge namene, za katere bomo podatke uporabljali. Ocena kakovosti nam pomaga pri odločitvah, ali bodo uporabljeni podatki opravičili čas in uporabljene vire z odločitvami, ki jih bodo podatki k tem analizam prinesli. Pove nam tudi, ali so analize ali odločitve iz podatkov, ki jih uporabljamo, pravilne. Ocene kakovosti podatkov se je potrebno lotiti z metodološkim pristopom. Kvalitativne mere in standarde je potrebno postaviti učinkovito, da jih lahko apliciramo vsak trenutek procesa. S tem postane primarna zahteva ocena kakovosti podatkov na začetku ali na koncu procesa. Kot je navedeno v Meersman, Tari in Herrero (2008), obstajajo metodologije za uporabo ocene kakovosti, s katerimi lahko poskusimo določiti kvaliteto. Ta merila so:. . . Točnost (angl. Accuracy) – stopnja sporazuma med sklopom podatkovnih vrednosti in ustreznih pravilnih vrednosti ali so podatki pravilni. Popolnost (angl. Completness) – stopnja, kjer so vrednosti prisotne in med atributi, ki jih potrebujejo ali so podatki popolni. Doslednost (angl. Consistency) – sporazum ali logična skladnost v skladu z dejstvi brez variacij ali kontradiktornosti. Točnost (angl. Precision) – kvaliteta ali stanje točnosti v mejah definiranih ciljev. Zanesljivost (angl. Reliability) – sporazum o zanesljivosti ali logična usklajenost, ki omogoča racionalno povezavo v primerjavi z drugimi podobnimi podatki. Začasna zanesljivost (angl. Temporal Reliability) – pomen in semantika, ki se lahko spremenita s časom. Pravočasnost podatkov (angl. Timeliness Data) - elementi ali več elementov, ki so na voljo v času, ko so potrebni ali določeni. Unikatnost (angl. Uniqueness) – vrednosti podatkov, ki so omejene z nizom unikatnih lastnosti vsaka vrednost je edina svoje vrste. Veljavnost (angl. Validity) – skladnost vrednosti podatkov, da so sprejemljiva zmanjšanje verjetnosti napak.. Enotne metodologije za določanje kakovosti podatkov ni. Z različnimi pristopi ali metodologijami določimo mero kakovosti.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 22.
(28) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Pri merjenju kvalitete podatkov si lahko pomagamo tudi s poročili oziroma poizvedbami. Na primer v poljih z diskretnimi podatki lahko izpišemo distribucije frekventnosti posameznih vrednosti in ročno pregledamo tiste, ki najbolj izstopajo. Pri datumih si lahko pomagamo z minimalnimi in maksimalnimi vrednostmi ter ponovno ročno pregledamo ali označimo tiste, ki so sumljivi (Ferle, 2013).. 2.17. PODATKOVNO RUDARJENJE Podatkovno rudarjenje (angl. Data Mining) je izvoz implicitnih, prej neznanih in potencialno uporabnih informacij iz podatkov (Witten et al., 2011). Z metodami podatkovnega rudarjenja samodejno iščemo po velikih količinah podatkov ter iščemo vzorce in trende, ki jih ne najdemo s preprosto analizo. Rudarjenje podatkov uporablja sofisticirane matematične algoritme za segmentiranje podatkov in ocenjuje verjetnosti bodočih dogodkov. Glavne naloge podatkovnega rudarjenja so, kot je navedeno v Oracle (2008): . . . . Avtomatično odkrivanje vzorcev (angl. Automatic Discovery) – podatkovno rudarjenje je doseženo z izgradnjo modelov. Model uporablja algoritem, ki deluje na setu podatkov. Pojem avtomatskega odkrivanja vzorcev se nanaša na izvedbo modelov v podatkovnem rudarjenju. Predvidevanje najbolj verjetnih rezultatov (angl. Prediction) – Veliko oblik podatkovnega rudarjenja je predvidljivih. Predvidevanja imajo določeno verjetnost, iz katerih lahko naredimo pravila, ki so pogoj za določanje rezultata. Kreiranje koristnih informacij (angl. Actionable Information) – S podatkovnim rudarjenjem lahko izluščimo in kreiramo koristne informacije iz velikega obsega podatkov. Fokusiranje na velike sete podatkov (angl. Grouping) – Oblika podatkovnega rudarjenja, kjer s pomočjo združevanja podatkov naredimo skupine podatkov, ki imajo enake lastnosti.. Kot navajajo Fayyad, Piatetsky-Shapiro in Smyth (1996), podatkovno rudarjenje obsega več različnih tipov nalog ali metod, med drugim: . . . Preverjanje anomalij (angl. Anomaly Detection) – identificiranje nenavadnih zapisov, ki so potencialno zanimivi ali pa imajo potencialne napake, ki jih je potrebno dodatno preveriti. Asociacijsko učenje pravil (angl. Association Rule Learning – Dependency Modelling) – iskanje odnosov med spremenljivkami. Na primer: trgovina izbira podatke o potrošniških navadah. Z učenjem zveznih pravil se lahko naučijo, kateri so komplementarni izdelki in jih nato uporabijo v marketinške namene. Klasterska analiza (angl. Clustering) – je naloga iskanja skupin in struktur v podatkih, ki so si med seboj podobni, brez uporabe znanih struktur v podatkih.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 23.
(29) Univerza v Mariboru – Fakulteta za organizacijske vede. . . Diplomsko delo visokošolskega strokovnega študija. Klasifikacijska metoda (angl. Classification) – je naloga iskanja splošne strukture, ki se jo implicira na nove podatke. Na primer: poštni odjemalec lahko klasificira elektronsko pošto kot nezaželeno ali kot legitimno. Regresijska metoda (angl. Regression) – poskuša najti formulo, ki oblikuje podatke z najmanj napakami. Kreiranje povzetka (angl. Summarisation) – zagotavlja bolj kompaktno prezentacijo sklopa podatkov na osnovi vizualizacije in generiranjem poročil.. Podatkovno rudarjenje in statistika Obstaja velika korelacija med statistiko in podatkovnim rudarjenjem. Večina tehnik, uporabljenih za podatkovno rudarjenje, se uporablja v statističnem okviru nalog. Tehnike podatkovnega rudarjenja niso enake tradicionalnim tehnikam statistike. Tradicionalne statistične tehnike na splošno zahtevajo veliko interakcijo uporabnika, da se preveri pravilnost modela. Posledično je statistične metode težko avtomatizirati. Poleg tega statistične metode običajno ne ustrezajo velikim setom podatkov, bolj primerne so metode podatkovnega rudarjenja, saj se lažje implementirajo oziroma avtomatizirajo Običajno algoritmi podatkovnega rudarjenja zahtevajo velike sete podatkov. Podatkovno rudarjenja in OLAP OLAP lahko definiramo kot hitro analiziranje skupnih podatkov v več dimenzijah. OLAP in podatkovno rudarjenje sta drugačna, a se v določenih aktivnostih dopolnjujeta. OLAP podpira dejavnosti, kot so združevanje podatkov, razporejanje stroškov, časovne vrstne analize in Kaj-če-analize (angl. What-if). Večina OLAP-sistemov sicer nima induktivnega sklepanja, ki (bi presegal ali ker) presega podporo za časovno serijo napovedi. Induktivni proces splošnega sklepanja in zaključkov iz primerov je poseben (proces??? Kaj??) za podatkovno rudarjenje. Induktivno sklepanje je znano tudi kot računalniško učenje. OLAP-sistemi zagotavljajo večdimenzionalni pogled na podatke s popolno podporo hierarhij. Pogled na podatke je splošen način za analiziranje in organizacije. Podatkovno rudarjenje pa običajno nima koncepta pogleda na dimenzije in hierarhije. Podatkovno rudarjenje in OLAP lahko integriramo na več načinov. Podatkovno rudarjenje lahko uporabimo za kreiranje dimenzij v kocki, kreiranje novih vrednosti za dimenzije ali kocko. OLAP lahko uporabimo za analizo rezultatov podatkovnega rudarjenja na več ravneh. Rudarjenje podatkov lahko pomaga narediti bolj zanimive in uporabne kocke. Podatki pridobljeni iz predikativnega rudarjenja ali naše predvidevanje nam lahko pomagajo zgraditi nove mere. Taka mera bi lahko pomagala predvidevati, kaj bodo kupci kupili. Z OLAP-procesiranjem se lahko podatke agregira in kasneje povzame verjetnosti.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 24.
(30) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Podatkovno rudarjenja in podatkovna skladišča Podatkovno rudarjenje se lahko uporablja pri ploskih datotekah, preglednicah (angl. Spreadsheets), tabelah v bazah ali v kakšnih drugih oblikah. Bistven kriterij za podatke ni format, temveč uporabnost za rešitev problema. Učinkovito čiščenje podatkov in priprava podatkov sta zelo pomembni za podatkovno rudarjenje in podatkovno skladišče, da se olajša dejavnost podatkovnega rudarjenja. Podatkovno skladišče pa ne bo uporabno, če ne bo vsebovalo podatkov, ki bi rešili problem (Oracle, 2008). Obstaja zelo veliko orodij za podatkovno rudarjenje, ki so komercialna: Oracle Dataminig, PSeven, Microsoft Analysis Services, IBM SPSS Modeler. Odprto kodna programska oprema so: R, Weka, Knime, Torch, Orange.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 25.
(31) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. 3. PRIPRAVA BAZE PODATKOV Celoten proces, od prejema podatkov do izdelave OLAP-kocke, vsebuje več procesov. Prvi med njimi je ETL-proces. Obstaja več orodij, kjer se celoten ali samo del tega procesa implementira za izgradnjo podatkovnega skladišča. Postopki v tem procesu imajo enak cilj – zagotoviti podatke, primerne za končnega uporabnika. Obstaja več načinov ali orodij in metod, kako priti do primernih podatkov. Za diplomsko nalogo smo večji del teh nalog opravili na način, ki poskuša po korakih povzeti vse postopke. Podatki, ki smo jih pridobili, so bili razdeljeni po sklopih pošiljateljev. Preden smo dobili želen izvoz, je bilo potrebno podatke preveriti, prečistiti in nato profilirati.. 3.1. PREVERJANJE IN ČIŠČENJE PREJETIH PODATKOV Podatke, prejete v obliki tekstovnih datotek, smo uvozili v program Microsoft Access 2013. Uporabili smo specifikacije podatkov, ki smo jih zahtevali tako, da smo imeli enako število polj in tipov polja. Access omogoča uvoz različnih tipov podatkov: tekstovne datoteke (.txt, .csv), Excel (.xlsx, .xls), XML ali pa direktne povezave na podatkovne baze ali vire: ODBC, Access, Outlook mape, Sharepoint poročila. Program omogoča shranjevanje specifikacij uvoza (Slika 7), kar nam omogoča hitrejši večkratni uvoz enakih datotek. Za vsako datoteko smo naredili svojo specifikacijo in jo shranili, da smo jo lahko kasneje ponovno uporabili. Med specifikacijami določimo polja kot so: razdelilnik polja, tekstovni ločevalnik (angl. Text Qualifier), jezik, kodno tabelo, zapis datuma, decimalni simbol, tip in ime polja.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 26.
(32) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Slika 7: Specifikacije za uvoz podatkov Izbiramo lahko tudi med uvozom datoteke, kjer so polja razdeljena z razdelilniki, in med polji, ki imajo fiksno širino. S pomočjo polja Indeksiranja (polje »Indexed«) v tabeli specifikacij določimo vsako polje, ki ga uvažamo, ali je lahko podvojeno ali ne. Po uspešnem uvozu vseh treh datotek v tabele smo začeli podatke preverjati. Preverjanje za dvojnike Za polja, ki smo jih označili, da ne smejo vsebovati dvojnikov, nam pri uvozu dvojnika program javi, da je zaradi kriterija, ki smo ga vnesli prišlo do podvajanja polj. Program ne izpiše, katera polja so podvojena, zato smo naredili SQL_poizvedbo: SELECT K_datoteka.kupec_code, K_datoteka.name, K_datoteka.city, K_datoteka.address, K_datoteka.zip_code FROM K_datoteka WHERE (((K_datoteka.kupec_code) In (SELECT [kupec_code] FROM [K_datoteka] As Tmp GROUP BY [kupec_code] HAVING Count(*)>1 ))) ORDER BY K_datoteka.kupec_code;. Poizvedba nam izpiše vrstice, kjer so podvojene kode kupca. Preverjanje za tip podatkov Ko smo uvozili podatke s specifikacijami, ki smo jih definirali na začetku, nam program v primeru napačnih tipov podatkov samodejno javi, katera polja niso bila uspešno uvožena zaradi napačnega konvertiranja polja.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 27.
(33) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Preverjanje praznih polj (NULL) v datoteki izdelkov Med poizvedbami smo naredili SQL-stavek, ki je preveril, ali so vsa polja v tabeli zapolnjena: SELECT I_datoteka.izdelek_code, I_datoteka.kupec_code, I_datoteka.Date, I_datoteka.quantity, I_datoteka.sales FROM I_datoteka I_datoteka WHERE (((I_datoteka.izdelek_code) Is Null)) OR (((I_datoteka.kupec_code) Is Null)) OR (((I_datoteka.Date) Is Null)) OR (((I_datoteka.quantity) Is Null)) OR (((I_datoteka.sales) Is Null));. Vsa polja so morala biti polna, drugače smo dobili izpis vrstic(e), kjer manjkajo atributi. V primeru praznih polj smo prosili za nove datoteke, ali pa smo na osnovi že prejetih datotek poiskali in vnesli pravilen atribut in informacijo preverili pri viru podatkov. Enako smo naredili za tabeli Prodaje in Izdelkov. Preverjanje manjkajočih atributov Ker je tabela prodaje vsebovala kode Kupcev in kode Izdelkov, smo s SQL poizvedbo preverili, ali smo prejeli vse atribute med podatki: SQL za manjkajoče kupce: SELECT I_datoteka.* FROM I_datoteka LEFT JOIN K_datoteka ON I_datoteka.kupec_code = K_datoteka.kupec_code WHERE (((K_datoteka.kupec_code) Is Null));. SQL za manjkajoče izdelke: SELECT I_datoteka.* FROM I_datoteka LEFT JOIN P_file ON I_datoteka.izdelek_code = P_file.izdelek_code WHERE (((P_file.izdelek_code) Is Null));. V obeh primerih nam je poizvedba preverila polja v tabeli Prodaje in izpisala polja, ki so v tabeli izdelkov ali tabeli kupcev manjkala. Preverjanje obsega podatkov Zahtevali smo podatke za obdobje enega meseca. Na osnovi te informacije smo naredili SQL-poizvedbo, ki izpiše obseg datumov: TRANSFORM Sum(I_datoteka.quantity) AS SumKolicina SELECT I_datoteka.Date AS Expr1, Sum(I_datoteka.quantity) AS [Skupaj kolicina] FROM I_datoteka GROUP BY I_datoteka.Date PIVOT I_datoteka.DDV;. S tem smo preverili, da prejeti podatki niso izven določenega obdobja in da so v pravilnem zapisu.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 28.
(34) Univerza v Mariboru – Fakulteta za organizacijske vede. Diplomsko delo visokošolskega strokovnega študija. Preverjanje konsistentnosti podatkov Pridobili smo podatke za obdobje enega leta, zato smo lahko na podlagi mesečnih podatkov naredili povprečja vsot, seštevek števila vrstic ali število izdelkov in primerjali podatke po časovnih obdobjih. Uporabili smo SQL-poizvedbo: SELECT Count(I_datoteka.izdelek_code) AS SteviloIzdelkov_code, Sum(I_datoteka.quantity) AS VsotaKolicina, Sum(I_datoteka.sales) AS VsotaProdaja FROM I_datoteka;. Poizvedba izpiše število različnih izdelkov, vsoto količine in vsoto prodaje. Te podatke smo izpisali v drugo tabelo, kjer smo jih primerjali z ostalimi mesečnimi povprečji in primerjali odstopanja. Kompleksno preverjanje podatkov S podatki v tabelah smo lahko preverjali logične zapise med podatki: . S SQL-Distinct-poizvedbo smo naredili pregled vseh kupcev ali izdelkov in preverili doslednost. Preverili decimalne vrednosti v količinah. Preverili negativne vrednosti. Preverili vrednosti 0. Preveri/poiskali manjkajoče vrednosti.. Za kompleksno preverjanje podatkov je potrebno poznavanje okolja oziroma njegova pravila in logično sklepanje, ali so podatki skladni, konsistentni ali dosledni. Pri datoteki kupcev in izdelkov smo lahko dobili v izvozu vse kupce ali vse izdelke, ali samo tiste kupce ali izdelke, ki so imeli prodajo v obdobju, ki ga ja zavzela datoteka transakcij prodaje. Vsak izvoz ima svoje prednosti in slabosti. Če smo dobili vse zapise, je iskanje atributov v datoteki kasneje lažje, ker vzamemo zadnjo datoteko, v kateri imamo zajete vse podatke. Slabost pa je, da je datoteka lahko velika in so neaktualni kupci ali izdelki lahko odveč in da datoteka ni posodobljena. Težava je lahko tudi, če se uporabi ista koda in pride do podvajanja. Če smo dobili samo izdelke ali kupce iz določenega obdobja, je bila datoteka manjša, vendar vsi kupci skozi zgodovino niso bili zajeti. Datoteka je vsebovala posodobljene vrednosti in verjetnost za podvajanje podatkov je bila manjša. Na trgu je veliko različnih orodij, s katerimi lahko preverjamo podatke. Večinoma so si takšni programi komplementarni in se prekrivajo pri opravljanju svojih nalog.. 3.2. PROFILIRANJE PREJETIH PODATKOV Na osnovi rezultatov iz preverjanja in čiščenja ter kasneje transformacije in manipulacije podatkov, si ustvarjamo sliko podatkov. Glede na to sliko podatkov, se kasneje odločimo, če so podatki dovolj kvalitetni in uporabni za nadaljevanje projekta.. Gregor Povhe: Obdelava in priprava podatkovne kocke OLAP. stran 29.
Figure

Related documents
Process description: Biological treatment in a compact bioreactor containing small polymer foam cube media ‘Variopor’, followed by optional membrane filtration (the membrane
Moringa oleifera Intake during Pregnancy and Breastfeeding toward Docosahexaenoic Acid and Arachidonic Acid Levels in Breast Milk.. Open Access Maced J
The agricultural subsidy system (co-financing in agriculture) is implemented through policy measures in three areas: direct payments (income support), production
Key-stage curriculum outcomes are statements that identify what students are expected to know, be able to do, and value by the end of grades 3, 6, 9, and 12 as a result of
This study examined how online privacy affects social presence in online learning environments and whether e- mail, bulletin board, and real-time discussion affect online
La lista non pretende di essere esaustiva, si invitano le aziende a comunicare eventuali modifiche ed integrazioni al seguente indirizzo [email protected].. ITALIAN COMPANIES
The basic argument is that indebted taxpayers are better off if, instead of paying taxes to fund public pensions that earn the market return, they leave pensions unfunded, defer
The ritual devouring of this “succulent” pig is not, of course, due to an actual need for food: “Even those of us who’d stuffed ourselves earlier in the evening are panting
