Supporting the Knowledge Life Cycle
with a Knowledge Network Management System
Sascha Uelpenich, Freimut Bodendorf
Department of Information Systems
University of Erlangen-Nuremberg
Lange Gasse 20
90403 Nuremberg
Germany
(Phone) ++49 911 5302 450
(Fax) ++49 911 5302 379
{uelpenich|bodendorf}@wiso.uni-erlangen.de
Abstract
Knowledge management requires changes in processes, organizational structure and corporate culture. These changes are very often accompanied by the introduction of knowledge management systems that manage digital documents or facilitate unstructured co-operation in distributed teams. Although the technology very often plays the important role of an enabler, its main functions are in many cases limited to knowledge retrieval which is supported for example by full text search mechanisms. The acquisition and classification phase of the knowledge life cycle, i.e. the systematic collection of new knowledge and its integration into a pre-defined structure, are not facilitated in general.
In this paper, a system is presented that in addition to knowledge retrieval also supports the acquisition and classification phases of the knowledge life cycle. It is aligned to the requirements of consulting companies and is based on a model of a knowledge network that incorporates not only explicit knowledge but also relevant objects of its context.
1. Introduction
Knowledge management is a field of research that comprises organizational, process-related, cultural, and technological topics. Many human oriented approaches recommend to enhance the management of so-called
implicit1 knowledge. This can be done by transforming a
company’s organization into a learning organization with “Communities of Practice” [2], integrating knowledge management into a company’s business processes [3] or changing the corporate culture in order to support the sharing of knowledge [4]. All these approaches are often supported by knowledge management systems (KMS) that provide means to manage explicit knowledge. A very common prerequisite for the usage of KMS is to define and implement a hierarchical knowledge classification scheme. Unfortunately, hierarchical schemes disregard the most important characteristic of knowledge that differentiates it from information and data: its inherent linkage to a specific context [5]. Hierarchical schemes consist of separate “drawers” that – in most cases – are organized in a tree structure. If explicit knowledge is put into one of those “drawers” all relations to other knowledge, people or other relevant objects of its context are cut.
Here, an approach for a Knowledge Network
Management System (KNMS) is presented, that avoids these disadvantages and is based on an object-oriented knowledge network model. The model comprises classes for explicit knowledge and relevant objects of its context as well as attributes and relationships between the classes. The knowledge network model introduced in this paper is
adjusted to the needs of consulting companies2.
Nevertheless, the knowledge network approach is generic
1 According to [1] ‘explicit’ knowledge is formal and systematic and
can thus be easily captured, whereas ‘implicit’ or ‘tacit’ knowledge is hard to formalize and to transfer to others.
and can be applied to a wide variety of industries, organizations, and enterprises.
The KNMS puts the knowledge network model into action. It contributes to knowledge acquisition, classification, and retrieval within the knowledge life cycle.
2. Knowledge Networks
2.1. Motivation
Experiences with hierarchical classifying schemes for knowledge, which are realized e.g. in file systems, show their major deficiencies:
• A substantial characteristic of knowledge is the
inherent linkage with its context. Hierarchical classifying schemes define separate "drawers". As a result, the integration of knowledge into those “drawers” destroys relations to contents of other classes or other relevant objects of the context.
• Explicit knowledge is characterized by a set of
attributes. A “drawer” in a hierarchy normally contains knowledge with a specific value in one of these attributes. E.g. the “drawer” “Before 2000” in figure 1 contains knowledge whose attribute “Creation Date” has a value that is a date before the year 2000. As a result, the attributes whose values define the “drawers” are prior to the other attributes. Which attributes get the priority depends on preferences of the person or the group that defined the classifying scheme. Other persons may regard the resulting access paths to the knowledge as unsuitable and would e.g. prefer that “Technical Format” is the prior attribute which would lead to different access paths (cf. figure 1).
Before 2000 2000 2001 2002 Jan - Mar Apr - Jun Jul - Sep Oct - Dec MS Powerpoint Adobe PDF MS Project ... MS Word Priority of Attribute „Creation Date“ Priority of Attribute „Technical Format“
1
2
Figure 1. Attribute priorities
• As the hierarchical classes do overlap very often, knowledge may belong to several classes. If no copies of the knowledge are to be made or can be made, users
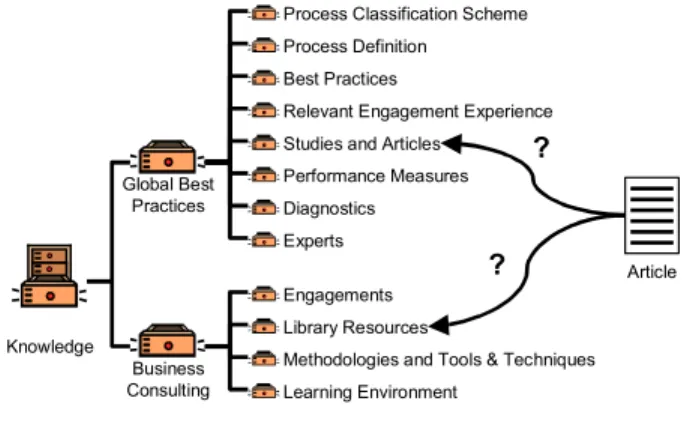
have to decide which class it has to be assigned to. This leads to problems if someone wants to access the stored knowledge. A user could expect the required knowledge in one particular class and will be disappointed if he/she cannot find it there. If copies are made and put into all appropriate “drawers” all the problems occur which come along with the administration of redundant data. Figure 2 shows a sample classification scheme according to [7] and the difficulties that arise if an article has to be integrated.
Knowledge
Global Best Practices
Business Consulting
Process Classification Scheme Process Definition Best Practices
Relevant Engagement Experience Studies and Articles
Performance Measures Diagnostics Experts
Engagements Library Resources
Methodologies and Tools & Techniques Learning Environment
Article
?
?
Figure 2. Overlapping classes
• The defined classifying schemes are in many cases not complete, so that new knowledge can only be integrated if the scheme is extended. This leads very often to the restructuring of the entire scheme (cf. figure 3). Knowledge Global Best Practices Business Consulting
Process Classification Scheme Process Definition Best Practices
Relevant Engagement Expirience Studies and Articles
Performance Measures Diagnostics Experts
Engagements Library Resources
Methodologies and Tools & Techniques Learning Environment
Market Study
?
Figure 3. Incomplete scheme
Despite these disadvantages hierarchical classification schemes are widely accepted and many users are familiar with them. However, there are many requests for a more flexible way of knowledge organization to cope with the problems outlined above.
2.2. Knowledge Network Object Model
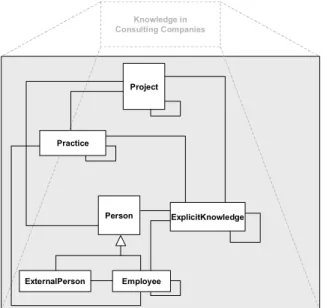
In a knowledge network knowledge is connected with relevant objects of its context. Here, a knowledge network
consulting companies. The core business of consulting companies is “project execution”. The most important objects in this context are instances of the classes person, practice, and project. The whole knowledge network can be seen as a semantic net that leads to the knowledge network object model depicted in figure 4.
Knowledge in Consulting Companies Person ExternalPerson Employee Practice Project ExplicitKnowledge
Figure 4. Knowledge network object model
It covers knowledge on different levels:
• The class "ExplicitKnowledge" represents specialized, documented explicit knowledge.
• The classes “Practice”, “Project”, and “Person” as well as its subclasses “ExternalPerson” and “Employee” represent knowledge about the relevant context of explicit knowledge.
• The knowledge about the connection of knowledge
with the context and about the connections within the context is represented by the model’s manifold typed relationships. These relationships are - for reasons of clearness - not individually specified in figure 4.
Thus, the network incorporates knowledge in consulting companies as a whole.
Table 1 provides the detailed specification of the model’s most important class “ExplicitKnowledge”.
Table 1. Attributes of “ExplicitKnowledge”
Attribute Values
ID Unique identifier Title The knowledge’s descriptive title
Type request for proposal, letter of intent, contract, checklist, questionnaire, project plan, proposal, organizational charts, flyer, presentation, profile, minutes, report, calculation, article, study, abstract/summary, book, magazine, journal, website, chapter, section, image, diagram, table, method, guideline, scenario, memo, directory
Topic strategic consulting, human-resources management, it consulting, organizational development
Quality not checked, approved, good practice, best practice
Status draft, final Confidentiality public, restricted, confidential
Region Americas, North America, Central America, Latin America, Europe, Western Europe, Eastern Europe, Middle East, Far East, Africa, EMEA, Asia Pacific, and all countries Format All mime types and paper
Language All languages
CreationDate Date of the knowledge’s creation
Modifica-tionDate
Date of the knowledge’s last modification Template yes, no
URI The Uniform Resource Identifier that points to the resource or the section of the resource containing the explicit knowledge
Figure 5 shows a part of an exemplary knowledge network that is consistent with the knowledge network object model. On the one hand the incorporated knowledge consists of contents that are referred to by the instances of the class “ExplicitKnowledge”. On the other hand it consists of knowledge about the facts, that e.g.
• a project plan and a checklist for the creation of project plans were developed in project2,
• person2 is a member of practice1, and
• person1 is the author of the project plan that is rated as best practice.
Explicit-Knowledge Project Plan Checklist Explicit-Knowledge Project Plan Template Explicit-Knowledge Project Plan (rated Best Practice) Project1 Practice IT Strategy Explicit-Knowledge Market Study is used in is auth or is used in was created in Employee Bodendorf Project2 execut es produces is u se d in is memb er of is expert for is based on wa s crea ted in Employee Uelpenich
Figure 5. Exemplary Knowledge Network
The example shows why the class “ExplicitKnowledge” does neither have attributes like “author”, “contributor” or “expert”, that relate to persons, nor attributes like “origin” that relate to projects or practices. These characteristics of explicit knowledge are expressed by relationships to instances of the respective classes.
2.3. Addressing and Markup of Explicit
Knowledge
Knowledge can be stored and administered in many different formats and on many different media. It is made explicit e.g. in electronic documents on a network drive, within tables of a relational database and on paper in a library. These examples point out that it does not make sense to store contents within the knowledge network’s nodes. This would lead to redundancies which make it difficult to guarantee consistency. In addition, explicit knowledge that is contained on paper, e.g. in books or magazines, could only be integrated into the knowledge network if scanned. In order to avoid such additional efforts and to ensure the integrity of the network’s knowledge, only pointers to knowledge are kept within the nodes. These pointers are based on the Uniform Resource Identifier (URI) technology [8] whose major objective is to provide a uniform syntax to reference almost any kind of resources on arbitrary media and in many different management systems. However, they normally point to whole resources. This can be a disadvantage if only a small section of a resource does actually contain valuable knowledge. It is desirable that this section, e.g. a short definition within a book, can easily be located. Thus, pointers from nodes to explicit knowledge should be able to address smaller units.
A powerful means for the addressing of knowledge within resources is “markup”. An XML markup language, called Knowledge Markup Language (KML), is defined
that provides the necessary elements to identify relevant knowledge within its surrounding context. As a result, fragment identifiers that point directly to a specific section can be appended to the URIs that refer to a resource. The fragment identifiers for XML documents are defined in the XPointer standard [9].
Figure 6 shows the KML document type definition (DTD) that defines the necessary elements for the markup of knowledge.
<!ELEMENT resource (beginning?, knowledgeasset, (inbetween?, knowledgeasset)*, remainder?)> <!ATTLIST resource type ( embed | stub )
#REQUIRED "embed"> <!ATTLIST resource uri CDATA> <!ELEMENT beginning (#PCDATA)> <!ELEMENT inbetween (#PCDATA)> <!ELEMENT remainder (#PCDATA)> <!ELEMENT knowledgeasset (#PCDATA)> <!ATTLIST knowledgeasset kaid ID #REQUIRED>
Figure 6. DTD of the Knowledge Markup Language
The root element of a KML document is the resource
element, which contains at least one knowledgeasset
element. A knowledgeasset element represents knowledge that refers to a single node of the knowledge network. Contents before the first knowledgeasset element, between knowledgeasset elements and after the last knowledgeasset element can be marked up with the beginning, inbetween and remainder elements. The XML namespace technology [10] allows to mix KML tags and other XML languages within a single document. The parameter type defines whether the markup is embedded within the resource containing the explicit knowledge or whether the document is a KML stub. A stub is a KML document that serves as a proxy for those documents that cannot be marked up with KML tags, e.g. if they are on an external HTTP server that does not allow write access. In this case a knowledgeasset’s parameter uri points to the resource that contains the knowledge (cf. figure 7). If there is no way of addressing knowledge within these resources the stub’s respective knowledgeasset elements contain human-readable hints about the knowledge locations. In the other case a knowledge network node’s parameter “URI” points directly to the section that is marked with an embedded knowledgeasset element.
< r e s o u r c e t y p e = „ s t u b " > . . . < k n o w l e d g e a s s e t k a i d = " 4 7 1 1 " u r i = " h t t p : / / . . . " > . . . < / k n o w l e d g e a s s e t > . . . < / r e s o u r c e > E xplicitK now ledge
Title Type Topic Q uality ... U R I N ode of a
K now ledge N etw ork K M L S tub
< h t m l > < h e a d > . . . < / h e a d > < b o d y > . . . < / b o d y > < / h t m l > R eso urce C o ntaining
E xplicit K now ledge points
to
points to
Figure 7. KML stubs
Figure 8 shows a XHTML document with added KML tags. It has to be pointed out that the resulting document
KML tags were not defined in the DTD of the target format - here XHTML. As a result the document does not conform to the DTD. Therefore, the KML tags define a second, knowledge-oriented view on the resource’s contents.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 STRICT//EN" "http://www.w3.org/TR/xhtml1/DTD/strict.dtd"> <kml:resource kml:type="embed" xmlns:kml= "http://www.wi2.uni-erlangen.de/home/sauelpen/kml"> <kml:beginning> <html xmlns="http://www.w3.org/TR/xhtml1/xhtml/strict"> <head>
<title>Supporting the Knowledge Life Cycle in Consulting Companies </title> </head> <body> ... </kml:beginning> <kml:knowledgeasset kaid="4711"> <p> <b>Definition 1.1 (Knowledge)</b> </p> <p> <i>Knowledge</i> is ... </p> </kml:knowledgeasset> <kml:remainder> ... </body> </html> </kml:remainder> </kml:resource>
Figure 8. XHTML document with embedded KML elements
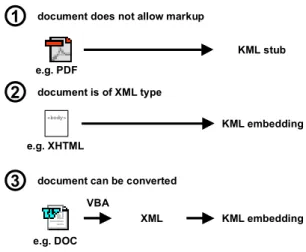
In addition to the embedding of KML elements within XML documents and KML stubs that act as proxies, a third case can be identified, if documents are stored in a proprietary format that can be converted into an XML format. As an example, an export filter has been developed that converts Microsoft Word documents into XHTML with embedded KML tags. Users have to markup the sections that contain knowledge with Word’s comment function. The export filter converts the document into XHTML. During the conversion process it scans the document for comment sections. If a comment starts with the string “kml:id=” it inserts a KML knowledgeasset element into the XHTML output stream. Thus, the result of the conversion process is comparable to the second case. Figure 9 shows a comprehension of all three knowledge markup cases that are supported.
<body>
KML stub e.g. PDF
1
document does not allow markup2
3
document is of XML type e.g. XHTML KML embedding XML KML embedding e.g. DOC VBAdocument can be converted
Figure 9. Knowledge markup
3. Knowledge Network Management System
In the following sections the concept of a Knowledge Network Management System (KNMS) is presented that manages knowledge in compliance to the knowledge network object model. In addition it provides functions that differentiate it from existing knowledge management systems in many regards. These systems very often focus on the support of knowledge retrieval. Here, three phases of the knowledge life cycle (knowledge acquisition, knowledge classification, and knowledge retrieval) are supported. Like the knowledge network object model the functions of the KNMS are aligned with the requirements of consulting companies but can easily be transferred to other domains. The system’s description is limited to the components and functions that differentiate the KNMS substantially from existing systems. The description comprises two parts: At first the system’s core architecture and its core components are introduced. Subsequently functions based on these basic services are outlined which support the knowledge life cycle.
3.1. Core Architecture
The KNMS core architecture consists of the following components:
• Navigation: The navigation component facilitates the user interaction with the system.
• Observation: The observation component observes the users during their work with the system.
• Log database: The log database contains the events that were recognized by the observation component.
• Analysis: The analysis component examines the
logged observations. As a result it draws conclusions and suggests measures to be taken by the execution component.
• Execution: The execution component interacts with the users in order to get their approval or disapproval for the measures that the analysis component suggested. After the users’ approval it is responsible for the realization of the measures.
• User and group database: The user and group database manages user accounts, user groups, and preferences. Thus, it facilitates that the system can adapt to the user’s needs on an individual as well as on a group level.
• Repository: The repository is the database that
manages the knowledge according to the knowledge network object model. It provides basic services that guarantee the consistency of a knowledge network. This means e.g. that edges must always connect two nodes and that each node must be connected with at least one other node.
Figure 10 depicts the relationships between the individual components. Three layers can be distinguished.
Log Database Navigation Component
Repository
User and Group Database Observation
Component
Interaction Layer Observation andAnalysis Layer Network ManagementLayer
Analysis Component Execution
Component
Figure 10. KNMS core architecture
The arrows in figure 10 indicate which components access other components. The following sections give a comprehensive overview of the navigation, observation, analysis, and execution component.
3.2. Navigation Component
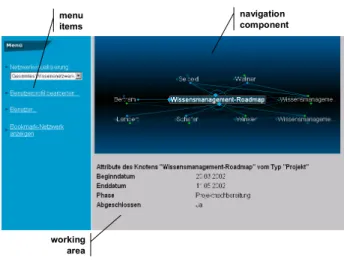
The navigation component is the major part of the user interface. It allows access to the nodes and edges of the knowledge network that are stored within the repository. A prototype is shown in figure 11. It uses a java applet that is based on the Brain SDK (www.thebrain.com) for visualizing the knowledge network.
menu items working area navigation component
Figure 11. KNMS “look and feel”
In addition to the navigation component the user interface consists of a menu bar on the left hand side of the navigation component and a working area below the navigation component. The menu bar provides function calls of the KNMS. The functions that the system offers depend on the role of the user. The role is given by the assignment to a specific user group. The administrator of the system can e.g. access the menu item "user administration" that comprises sub menus for creation, modification, and deletion of users and groups.
The working area’s content is depending on the selected menu item. Its most common task is to display the attribute values of the node that the user currently selected.
3.3. Observation Component
In contrast to a rather sequential execution of programs in text-oriented environments the operating sequence of a program with a graphical user interface cannot be foreseen. The user interaction, e.g. by mouse clicks or keyboard entries, triggers events whose kind and temporal occurrence cannot be predicted. The observation component’s task is to recognize these events and to log them in the log database. Among other things the logged events include clicks on nodes in the knowledge network and the activation of complex functions like the deletion or insertion of network nodes and edges. In order to preserve the chronological order each event is tagged with a time stamp.
3.4. Analysis Component
The analysis component uses the events that the observation component stores in the log database in order to draw conclusions and to suggest measures that improve the quality of the knowledge network. Among other things the conclusions are derived from key figures, e.g.:
• How often was a certain node of the network visited?
• Which search terms were entered?
• How often was a specific search term entered?
• Which search term did not yield any results?
The visualization of the network adapts to the requirements of different user groups. Thus, each user group has its own view on the knowledge network.
In most cases the conclusions that are drawn from key figures have an impact on the topology of a group view on the knowledge network. The central idea is that the observation of the user behavior leads to an adaptation of their view on the knowledge network or of the knowledge network itself. On the one hand that means for example that those nodes or edges that are activated very seldom are hidden (cf. figure 12).
Group View Knowledge Network
in Repository
Figure 12. A group view on the knowledge network
On the other hand new nodes and edges are integrated into the knowledge network, e.g. if a search term is entered very often but does not yield any results. The analysis component draws the conclusion that relevant knowledge concerning this search term has to be added to the KNMS.
3.5. Execution Component
The execution component has to solicit the users’ approval for the conclusions that the analysis component has drawn. If the users agree, the execution component’s task is to conduct appropriate measures that realize the suggested conclusions. Measures include e.g. the deletion of network nodes or edges. In this case the execution component has to pay attention to the fact that the network must not decompose into parts. Specific precautions are taken that are illustrated in figure 13.
Node to Delete Additional Edges
Figure 13.Deletion of network nodes
All nodes that are connected to a node that is about to be deleted are connected with each other. This temporarily leads to new edges that may increase the complexity of the network. However, edges that are not used will be recognized by the analysis component and thus be deleted within a short time. In addition to that the user can interfere with the deletion process and tell the KNMS which edges should be inserted in order to avoid separate networks. Similar measures are provided when edges of the network have to be deleted. Here, an algorithm is applied that checks whether the edge is the only path that connects the nodes at its both ends or whether there is another path from the node at one end to the node at the other end. If no such path exists, the user is notified that the edge cannot be deleted.
4. Supporting the Knowledge Life Cycle
The core components of the KNMS allow the realization of functions that support the three phases knowledge acquisition, knowledge classification, and knowledge retrieval.
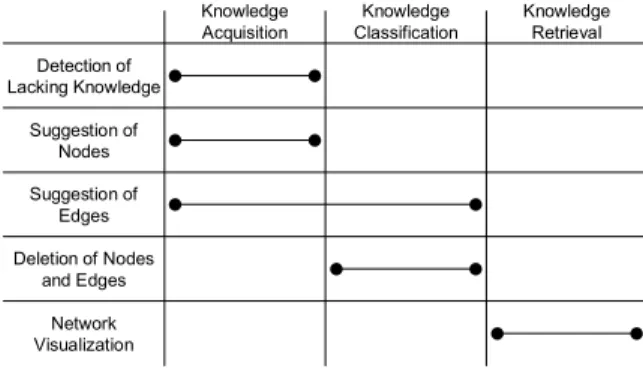
Figure 14 shows the main functions, mapping them to the respective phases.
Network Visualization Suggestion of Nodes Suggestion of Edges Detection of Lacking Knowledge Deletion of Nodes and Edges Knowledge Acquisition Knowledge Classification Knowledge Retrieval
Figure 14. Main KNMS functions
Except for the network visualization the functions are all based on the same idea: the analysis component tries to derive measures from the users’ behavior or from the comparison of different group views on the knowledge
network. The goal of the measures is to improve the knowledge network as a whole or to adjust a single view on the network in terms of completeness and topology.
Thus, the analysis component tries to detect whether new nodes should be integrated into the network in order to provide lacking knowledge. In addition, it suggest nodes and edges to specific groups that exist in other group views on the knowledge network. The deletion of nodes and edges is suggested if they are not or rarely visited over a specific period of time.
In combination with the associative retrieval of the knowledge via the navigation component’s visualization of the knowledge network, the KNMS is able to support all three phases of the knowledge life cycle.
4.1. Supporting Knowledge Acquisition
An important indicator for a lack of knowledge within the KNMS are search terms entered by the users. Especially the terms that do not yield any results are of particular interest. The search terms are evaluated by the analysis component according to the algorithm shown in figure 15.
nOccurrence := Number of Searches with a Specific Search Term
nResults := Number of Results for a Specific Search Term nMaxResults := Maximum of Results a Specific Search Term May Yield nMinOccurrences := Minimum of Searches with a Specific Search Term
For All Search Terms
Determine nResult for Current Search Term nResult < nMaxResults Determine nOccurrence for Current Search Term
Inform Users about Possible Lack of Knowledge nOccurrence > nMinOccurrences
Y N
N Y
Figure 15. Algorithm for the evaluation of search terms
The algorithm examines how often search terms whose number of results is below “nMaxResults” were entered. If they were entered more often than the threshold value “nMinOccurrences” the system informs the user who is responsible for the knowledge network, e.g. a content manager. In addition, it suggests to incorporate knowledge that is related to the search term into the knowledge network.
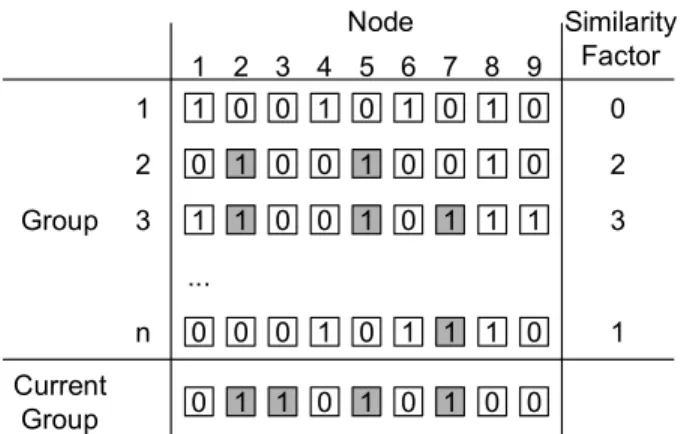
Another aspect of supporting the knowledge acquisition concerns group views on the knowledge network. The analysis component tries to detect group views that are most similar to the current group view according to the procedure illustrated in figure 16.
1 0 0 1 0 1 0 1 0 0 1 0 0 1 0 0 1 0 1 1 0 0 1 0 1 1 1 0 0 0 1 0 1 1 1 0 ... Node 1 2 3 4 5 6 7 8 9 1 2 3 n Group 0 1 1 0 1 0 1 0 0 Current Group Similarity Factor 0 2 3 1
Figure 16. Similarity of group views on the knowledge network
All nodes - in the example nine - are enumerated. If a node is part of the current group view and also part of another group view, the similarity factor of the latter view increases by one. As a result, the KNMS suggests nodes that are a part of the most similar networks but are not incorporated into the current group view on the knowledge network. It informs the users that are responsible for the administration of the respective view and suggests to incorporate those nodes.
In addition to that the KNMS may also suggest edges for the connection of the new nodes with the remainder of the current group view on the knowledge network. For that purpose it determines whether the suggested nodes are in the other group views connected to nodes that are also part of the current group view. If the KNMS detects such connections it recommends to add the respective edges to the current group view of the knowledge network.
4.2. Supporting Knowledge Classification
On the one hand the suggestion of edges can be assigned to the phase of knowledge acquisition as the edges themselves represent knowledge: the knowledge about the relationship between two nodes of the knowledge network. On the other hand it can be assigned to the phase of knowledge classification as well, as the network’s nodes are not only classified by the values of their attributes but also by relationships to other nodes that integrate them within their context.
The classification of knowledge can not only be supported and improved by new edges. It can also be supported by the deletion of nodes and edges. The analysis component determines how often a node or an edge is visited. If they are never or very seldom visited it concludes that they are obviously not important. As a result, their deletion will lead to a “leaner” knowledge network that does not contain unnecessary knowledge.
Thus, the quality of the classification is significantly improved as the context of the remaining nodes is reduced to relevant objects.
The algorithm shown in figure 17 defines the procedure for the deletion of edges. With small changes it can be applied to the deletion of nodes as well.
lEdges:= List of Edges that are Suggested for Deletion
nMinVisits := Minimum of Visits for an Edge nVisits := Number of Visits for a Specific Edge
For All Edges
Determine nVisits for Current Edge
nVisits < nMinVisits Add Current Edge to lEdges Suggest to Delete Edges in lEdges
Y N
Figure 17. Algorithm for the deletion of edges
4.3. Supporting Knowledge Retrieval
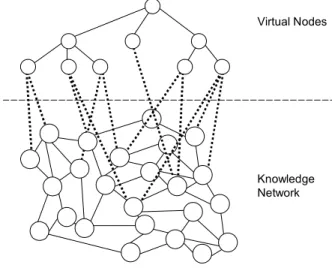
Knowledge retrieval is supported by the concept of virtual nodes that are not an integral part of the knowledge network (cf. figure 18). Their main purpose is to presort the network and to ease users’ first navigational steps therein.
The dotted lines show the relationships of the virtual nodes to the “real” nodes of the knowledge network. These lines are defined by criteria that are contained in the virtual nodes. These criteria refer to real nodes’ types (explicit knowledge, person, project, or practice), to nodes’ attributes, to types of relationships between nodes, or to arbitrary combinations.
Virtual Nodes
Knowledge Network
Figure 18. Virtual nodes
Thus, possible virtual nodes and their respective criteria are:
• The virtual node “Persons” that is connected with all real nodes whose type is “person”.
• The virtual node “New Knowledge” that is connected with all real nodes whose creation date is not older than (for example) 14 days.
• The virtual node “Project Leaders” that is connected with all nodes of type “person” that are linked to a node of type “project” by a relationship of type “project leader”.
As the KNMS allows to define different virtual nodes for every user group, the concept of the virtual nodes allows maximum flexibility for the presorting of the knowledge network. Nevertheless, if users leave the virtual nodes and enter the “real” knowledge network they can benefit from the knowledge network approach and do not have to tolerate the disadvantages of hierarchical approaches.
5. Conclusion and Outlook
Linear or hierarchical structuring of knowledge is often found in knowledge management systems but neglects the associative links of knowledge with other knowledge or objects. In addition, there is no consensus in many companies about any predefined structures for the organization of explicit knowledge. Here, an approach for a knowledge network is presented that puts knowledge in consulting companies into its context which consists mainly of persons, projects, and practices. An object model is presented that implements the proposed knowledge network. As a result, disadvantages of hierarchical approaches can be avoided.
Current knowledge management systems focus on support for the retrieval phase of the knowledge life cycle. They do not provide support for the acquisition and classification phase. Here, a knowledge network management system is outlined that puts the knowledge network object model into action. Its main components are a navigation, an observation, an analysis and an execution component. They cooperate in order to provide many innovative functions that in addition to knowledge retrieval support knowledge acquisition and classification, differentiating it significantly from other systems. Hence, the KNMS is among other things able to detect a lack of knowledge in the knowledge network, to suggest new nodes and new relationships to existing nodes and to configure the access to the knowledge network individually for every user group.
Nevertheless, there is still room for improvements. E.g. the analysis of similar networks and the analysis component’s resulting recommendations may be enhanced by quantitative statistical methods like cluster analysis [11]. Another approach is to use qualitative methods e.g. following the derivation of association rules in data mining [12]. The incorporation of knowledge into the multidimensional classifying scheme that is defined by its attributes can be supported by automated document
classification methods that are based e.g. on neural networks. In addition to that the application of the knowledge that is managed within the KNMS has to be ensured. Currently, a concept for the implementation of an internal knowledge market is developed, that uses the KNMS’ observations and users’ ratings of explicit knowledge to derive its “price”. An employee’s account balance at the end of a fiscal year represents his or her “knowledge work” and has an impact on his or her incentives.
6. References
[1] I. Nonaka, “The Knowledge-Creating Company”, Harvard Business Review, 69 (1991) Nov.-Dec., pp. 96-104.
[2] E. Wenger, “Communities of Practice - Learning as a Social System”, http://www.co-i-l.com/coil/knowledge-garden/cop/lss. shtml, 1998.
[3] B. Wolf, “Embedding Knowledge-Sharing into Work at SBS“, Knowledge Management Review, 3 (2000) 3, pp. 26-29. [4] D. Gurteen, “Creating a Knowledge Sharing Culture”, Knowledge Management Magazine, 2 (1999) 5.
[5] T. Buzan, and B. Buzan, The Mind Map Book - How to Use Radiant Thinking to Maximize Your Brain's Untapped Potential, New York, 1993.
[6] S. Uelpenich, and F. Bodendorf, “Management of Explicit and Implicit Knowledge in Consulting Companies”, Proceedings of AAAI Spring Symposium Series, Stanford, 2000. [7] S. Elliott, “Arthur Andersen Maximizes its Core Commodity through Comprehensive Knowledge Management”, Knowledge Management in Practice, (1997) 9.
[8] T. Berners-Lee, R. Fielding, and L. Masinter, “Uniform Resource Identifiers (URI): Generic Syntax”, http://www.ietf.org/rfc/rfc2396.txt, Internet Engineering Task Force, 1998.
[9] S. DeRose, E. Maler, and R. Daniel, „XML Pointer Language (XPointer) Version 1.0“, http://www.w3.org/TR/xptr/, World Wide Web Consortium, 2001.
[10] T. Bray, J. Paoli, C. M. Sperberg-McQueen, and E. Maler, “Extensible Markup Language (XML) 1.0 (Second Edition)”, http://www.w3.org/TR/2000/REC-xml-20001006, World Wide Web Consortium, 2000.
[11] K. Backhaus, B. Erichson, W. Plinke, and R. Weiber, Multivariate Analysemethoden, Berlin, 1994.
[12] R. Agrawal, T. Imielinski, and A. Swami, “Mining Association Rules between Sets of Items in Large Databases”, Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington DC, 1993, pp 207-216.