Extending the Real Time Specification for Java
for Cache Coherent NUMA Architectures
Abdul Haseeb Malik
Submitted for the Degree of Doctor of Philosophy
University of York
Department of Computer Science
Abstract
The recent past has seen single processing systems becoming obsolete and multipro-cessor systems taking over as the architecture of choice. More scalable architectures
are being introduced to keep up with the ever increasing computational require-ments. Inevitably the software industry has to keep up and provide tools which
would allow easy development of parallel applications on these complex architec-tures. Programming languages unable to support these architectures will become
obsolete and new languages will be developed designed to serve the purpose. Ex-isting languages that have the potential of coping with such architectures will be
extended.
Java is an object oriented language which provides features like platform indepen-dence and concurrency by design. It is supported on a wide range of computational
devices starting from high performance computing servers to small hand held mo-biles. This makes Java a very popular language, with a large pool of programmers.
Therefore, it is not strange to see Java being extended for different multiprocessor and distributed systems.
The Real-Time Specification for Java (RTSJ) was introduced as a high level platform for developing real-time applications. It has been gaining popularity since
its inception and is being increasingly used for real time development. The recent version of RTSJ (i.e. RTSJ 1.1) has included some support for multiprocessors.
The changes that have been introduced are largely related to the scheduling and dispatching of threads in symmetric multiprocessors. It is assumed that the memory
allocations will not affect the timing properties of the system and it will be accessed uniformly. This thesis argues that these changes are not enough to support shared
are not scalable and will be replaced by cache coherent non-uniform memory
access (cc-NUMA) systems. Locality can largely affect the performance of applications and cause unpredictable delays in real-time applications on
cc-NUMA systems. These delays are caused by the distributed memory layout in cc-NUMA and can be reduced by giving applications more control and
visibility into the allocation policies of threads and memory.
• The increased computational power of multiprocessors encourages the plat-form to be shared by multiple applications. In such an environment, real-time applications require temporal guarantees from the platform to meet their
tim-ing requirements.
The key contribution of this thesis is to extend the programming model of RTSJ
to provide programmers with locality constraints. Existing support in RTSJ for locality is shown to be very limited and a new locality model is presented which
enables programmers to develop portable applications. Applications are divided into multiple partitions and temporal guarantees are provided to partitions allowing
them to be analyzed in isolation from the rest of the system.
A prototype of the aforementioned model is implemented and tested. A series
of experiments are conducted to prove the effectiveness of the model. In particular, the effect of locality is highlighted by performance measuring in a multithreaded
Contents
Abstract iii
Acknowledgements xix
Declaration xxi
1 Introduction 1
1.1 The Real-time Specification for Java . . . 3
1.2 Cache Coherent Non-Uniform Memory Access (cc-NUMA) Archite-cuture . . . 5
1.3 Support for Multiprocessors in RTSJ . . . 8
1.4 Motivation . . . 9 1.5 Hypothesis . . . 11 1.6 Thesis Aims . . . 11 1.7 Thesis Structure . . . 12 1.8 Summary . . . 13 2 Literature survey 15 2.1 Parallel Programming on Multiprocessors . . . 16
2.1.1 Parallelism . . . 16
2.1.2 Locality . . . 17
2.2 Real Time Systems and Multiprocessors . . . 21
2.3 Java on Multiprocessors . . . 24
2.3.1 Java on Distributed Systems . . . 24
2.3.3 Discussion . . . 31
2.4 Summary and Requirements . . . 31
3 Existing Support for cc-NUMA Architectures 33 3.1 Linux Support for cc-NUMA . . . 34
3.1.1 Discovering the Architecture . . . 34
3.1.2 Allocating Threads and Objects . . . 36
3.1.3 Supporting Group Budgets . . . 38
3.2 RTSJ and its Support for Multiprocessors . . . 39
3.2.1 The AffinitySet Class . . . 43
3.2.2 The Physical Memory Framework . . . 45
3.2.3 Processing Group Parameters (PGPs) . . . 47
3.3 Supporting cc-NUMA Systems . . . 50
3.3.1 Representing the NUMA Architecture . . . 53
3.3.2 Pinning Schedulable Objects to Processors . . . 57
3.3.3 Allocating Objects on Specific Nodes . . . 58
3.4 Limitations . . . 60
3.5 Summary . . . 62
4 Locality Model 65 4.1 Architectural Model . . . 66
4.1.1 Abstractions for Basic Architectural Components . . . 68
4.1.1.1 The Abstract Component Class . . . 68
4.1.1.2 The Processor Class . . . 69
4.1.1.3 The Memory Class . . . 71
4.1.1.4 The Device Class . . . 72
4.1.2 Abstractions for Architecture Representation . . . 72
4.1.2.1 Location . . . 72
4.1.2.2 The Locale Class . . . 73
4.1.2.3 The Neighbourhood Class . . . 73
4.1.2.4 The District Class . . . 74
Contents
4.1.4 Discussion . . . 75
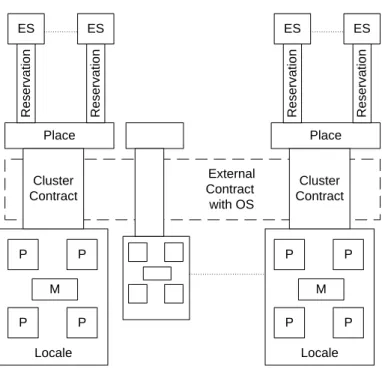
4.2 Application Model . . . 77
4.2.1 ExecutionSite: Abstraction for Controlling Execution . . . 77
4.2.1.1 Threads/Schedulables Instantiation . . . 80
4.2.1.2 Memory Areas Instantiations . . . 80
4.2.1.3 Retrieving Local Heap and Immortal . . . 80
4.2.1.4 Basic Resource Reservation Operations . . . 81
4.2.2 Place: A Logical Location . . . 81
4.2.3 Locality: AllocatingExecutionSite . . . 83
4.2.4 Local ImmortalMemory and Local Heap . . . 85
4.2.5 Conforming to the RTSJ . . . 87
4.2.5.1 RTSJ Rules . . . 88
4.2.5.2 Required Semantics of the Locality Model . . . 89
4.2.5.3 Using the Factory Pattern . . . 90
4.2.6 The Default Execution Model . . . 91
4.2.7 Example . . . 92
4.2.7.1 Static Allocation of Execution Sites . . . 92
4.2.7.2 Implicit Allocation of Execution Sites . . . 95
4.3 Resource Reservations . . . 98
4.3.1 Interface . . . 99
4.3.1.1 External Contract . . . 102
4.3.1.2 Partitioned Reservations . . . 103
4.3.2 Scheduling: The ReservationScheduler Class . . . 105
4.3.3 Admission Control . . . 106 4.3.4 Cost Enforcement . . . 108 4.3.5 Discussion . . . 108 4.4 Summary . . . 111 5 Implementation 115 5.1 Implementation Overview . . . 116
5.1.1 Implementing the AffinitySet Class . . . 117
5.1.3 Extensions Required for the Locality Model . . . 120
5.2 Implementing the Architecture Representation . . . 122
5.3 Implementing the Application Model . . . 127
5.3.1 Creating Places . . . 128
5.3.2 ExecutionSite Creation . . . 129
5.3.3 Thread/Schedulables Creation . . . 133
5.3.4 MemoryArea Creation . . . 135
5.4 Implementing Reservations Model . . . 136
5.4.1 Cost Enforcement . . . 138 5.4.2 Priority Assignment . . . 139 5.5 Summary . . . 141 6 Evaluation 143 6.1 Programmability . . . 144 6.2 Portability . . . 147 6.3 Performance . . . 149
6.3.1 The Producer/Consumer Problem . . . 149
6.3.2 The Prime Sieves Example . . . 153
6.3.2.1 Effect of the Locality Model on Performance . . . 155
6.3.2.2 Trade-off between Locality and Load Balancing . . . 157
6.4 Predictability . . . 162
6.4.1 Dispersions . . . 162
6.4.1.1 Locality Model vs. Normal Case . . . 162
6.4.1.2 Local vs. Remote . . . 163
6.4.1.3 Locality vs. Load Balancing . . . 164
6.4.2 Temporal Isolation . . . 165 6.5 Overheads . . . 168 6.5.1 Architecture Representation . . . 168 6.5.2 Application Model . . . 169 6.5.2.1 Creating Places . . . 170 6.5.2.2 Creating an ExecutionSite . . . 171
Contents
6.5.2.4 Realtime Thread Startup Latency Without
Reserva-tions . . . 173
6.5.2.5 Memory Area Creation . . . 174
6.5.2.6 Allocation Time Test . . . 176
6.5.3 Reservation Model . . . 177
6.5.3.1 Creating ReservationServers . . . 177
6.5.3.2 Realtime Thread Startup Latency using Reservations 178 6.6 Summary . . . 180
7 Conclusions and Future Work 181 7.1 Summary . . . 181
7.2 Contributions . . . 183
7.3 Future Work . . . 184
Appendix 189 A Memory Access Timings on Cache Coherent NUMA Systems 189 A.1 Comparing Local And Remote Memory Accesses . . . 192
A.2 Comparing Access Timings for Different Inter-Connect Speeds . . . . 192
A.3 Comparing Access Timings for Different NUMA Distances . . . 195
B The Producer Consumer Example 197 B.1 Statically Allocating ExecutionSites . . . 197
B.2 Allocating ExecutionSites Dynamically by the Runtime . . . 202
B.3 Allocating ExecutionSites with Reservations . . . 206
C Building JRate on 64bit Systems 211 D Schedulability Analysis 213 D.1 Scheduling Model . . . 213
D.2 Top Level Schedulability Test . . . 214
E The Prime Sieves Example 221 E.1 Without Using the Locality Model . . . 221
E.2 Using the Locality Model . . . 225
F Overheads of Libcgroup 231
F.1 Overheads Creating a ReservationServer/Place . . . 231
F.2 Attaching a Thread to a ReservationServer . . . 233 F.3 Summary . . . 234
References 236
Abbreviations 237
List of Figures
1.1 The Uniform Memory Access(UMA) Architecture . . . 6
1.2 The Non-Uniform Memory Access(NUMA) Architecture . . . 7
1.3 Time Taken by memcpy() . . . 10
2.1 The bounded delay model for single processors . . . 23
2.2 Java DSM built over existing DSM . . . 28
2.3 Native Java DSMs . . . 28
2.4 Java DSM with built-in DSM . . . 29
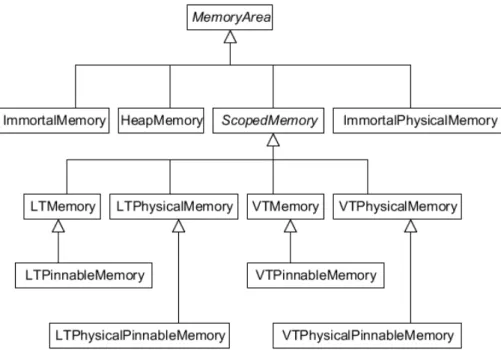
3.1 Memory classes in the RTSJ . . . 41
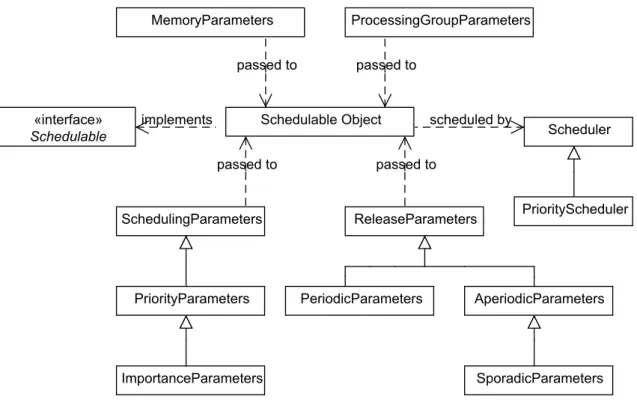
3.2 Schedulable objects in RTSJ . . . 42
3.3 Scheduling in RTSJ . . . 43
3.4 The AffinitySet Class . . . 45
3.5 Capacity on a single processor . . . 48
3.6 Single global capacity on multiple processor . . . 48
3.7 Partitioned equal capacities on multiple processors . . . 49
3.8 Partitioned different capacities on multiple processors . . . 49
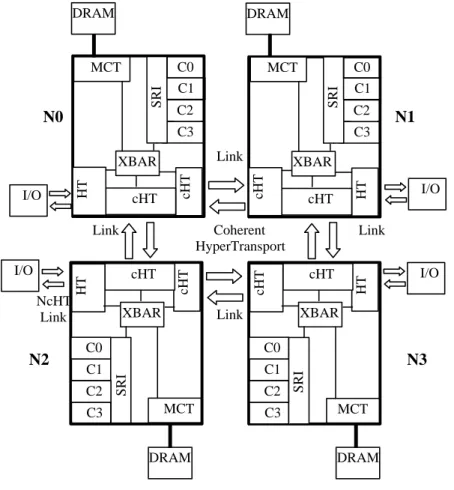
3.9 A 4 Node NUMA Architecture based on AMD Opteron . . . 50
3.10 Memory Hierarchy of a NUMA System . . . 51
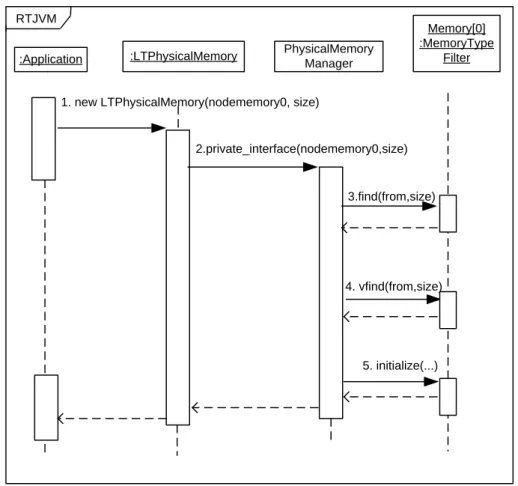
3.11 Creating an LTPhysicalMemory area . . . 59
3.12 Scope stack for a ThreadGroup . . . 62
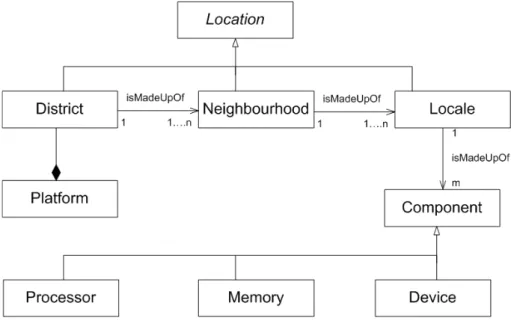
4.1 Abstractions for Architecture Representation . . . 69
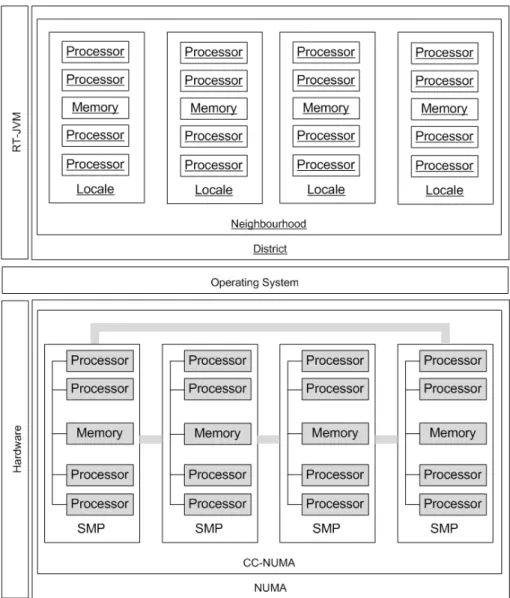
4.2 System Representation at the JVM level . . . 76
4.4 Scope stack showing memory access violations . . . 89
4.5 Remote allocation of producer/consumer . . . 94
4.6 Local allocation of producer/consumer . . . 97
4.7 Global Budget . . . 100
4.8 Partitioned Budget . . . 101
4.9 The Locality Model . . . 113
5.1 Simulating global scheduling in Linux . . . 118
5.2 Memory access timings . . . 121
5.3 Sequence diagram: building the Architectural Representation . . . 123
5.4 Graphical Output of lstopo(hwloc) . . . 127
5.5 Implementing the Locality model using the Control Groups . . . 128
5.6 Sequence diagram: initializing the virtual platform . . . 130
5.7 Sequence diagram: creating an execution site using a factory method 132 5.8 Creating and starting thread using the Locality model. . . 133
5.9 Sequence diagram: Creating a LTPhysicalMemory area . . . 137
5.10 Over-run on a single processor . . . 141
6.1 Architectural Representation of a single processor system . . . 148
6.2 Architectural Representation of a two processor SMP . . . 149
6.3 Execution times for local producer consumer problem using the lo-cality Model . . . 150
6.4 Execution times for remote producer consumer problem using the locality model . . . 153
6.5 Sieve of Eratosthenes . . . 154
6.6 Prime numbers for all N . . . 155
6.7 Number of threads created for all N . . . 155
6.8 Execution times for generating all prime numbers less than N=20000 using the locality model . . . 157
6.9 Execution times for generating all prime numbers less than N=20000 in the normal case . . . 160
List of Figures
6.10 Comparison of execution times using the locality model under
differ-ent configurations . . . 161
6.11 Architecture representation overheads . . . 169
6.12 Places Creation . . . 170
6.13 ExecutionSites Creation . . . 171
6.14 Real-time Threads Creation . . . 172
6.15 Real-time threads startup latency without reservations . . . 174
6.16 Scoped memory Area Creation Timings . . . 175
6.17 Object Allocation Timings . . . 176
6.18 ReservationServer Creation . . . 178
6.19 Real-time Threads Startup Latency . . . 179
7.1 Execution sites in a real-time Java application . . . 186
A.1 memcopy() timings(in seconds) for different interconnect speeds . . . 194
A.2 Comparing Access Timings for Different NUMA Distances . . . 195
D.1 Scheduling Architecture of Execution Sites on a Processor Based Bud-get . . . 215
D.2 Bandwidth requirements of T1T2T3 . . . 219
(a) All tasks’ bandwidth calculation . . . 219
(b) α1, α2 plane for all tasks’ bandwidth . . . 219
F.1 cgroup init() timings . . . 231
F.2 cgroup new cgroup() timings . . . 232
F.3 cgroup add controller() timings . . . 232
F.4 cgroup set value string() timings . . . 233
F.5 cgroup create cgroup() timings . . . 233
List of Tables
3.1 Distances based on bus accesses for Figure 3.9 . . . 52
3.2 System Locality Information Table for Figure 3.9 . . . 53
3.3 The System Resource Affinity Table (SRAT) for architecture in fig-ure 3.9 showing 16 processors . . . 54
3.4 The System Resource Affinity Table (SRAT) for architecture in fig-ure 3.9 showing memory . . . 54
4.1 The Component Class . . . 69
4.2 The Processor Class . . . 70
4.3 The ProcessorType Interface . . . 70
4.4 The Cache Class . . . 71
4.5 The Memory Class . . . 71
4.6 The Device Class . . . 72
4.7 The abstract Location Class . . . 73
4.8 The Locale Class . . . 73
4.9 The Neighbourhood Class . . . 74
4.10 TheDistrict Class . . . 74
4.11 ThePlatform Class . . . 75
4.12 TheExecutionSite Class . . . 79
4.13 ThePlace Class . . . 82
4.14 The finalLocality Class . . . 85
4.15 TheHeapPhysicalMemory Class . . . 87
4.16 Memory assignment rules in the RTSJ . . . 88
4.18 ThePartitionedParameters Class . . . 102
4.19 TheExternalContract Class . . . 102
4.20 TheClusterContract Class . . . 103
4.21 ThePartitionedReservation Class . . . 104
4.22 TheReservationScheduler Class . . . 105
4.23 TheReservationServer Class . . . 108
5.1 The LocalMemory Class . . . 119
5.2 The ESRealtimeThread Class . . . 134
5.3 The ESNoHeapRealtimeThread Class . . . 134
6.1 Execution times (in microseconds) for local producer/consumer . . . 151
6.2 Execution times (in microseconds)for remote producer/consumer . . . 152
6.3 Execution times (in milliseconds) statistics for the prime sieves in the locality model case . . . 158
6.4 Execution times (in milliseconds) statistics for the prime sieves in the normal case . . . 159
6.5 Analyzing the execution times of all cases . . . 161
6.6 Architecture representation overhead (milliseconds) statistics . . . 169
6.7 Places creation execution times in microseconds . . . 171
6.8 ExecutionSites Creation Execution Times in Microseconds . . . 172
6.9 Real-time Threads Creation Execution Times . . . 173
6.10 Real-time threads startup latency (in microseconds) without reserva-tions statistics . . . 174
6.11 Scoped memory Area Creation Timings (milliseconds) Statistics . . . 176
6.12 Object Allocation Timings (milliseconds) Statistics . . . 177
6.13 Creating ReservationServer Timings (microseconds) . . . 178
6.14 Real-time Threads Startup Latency (in microseconds) Statistics . . . 179
A.1 memcpy() timings (in milliseconds) with N0-N1 interconnect at 200Mhz193 A.2 memcopy() timings (in seconds) for different interconnect speeds . . . 194
List of Tables
D.1 Symbols used for schedulability analysis . . . 216
D.2 Workload for the execution site . . . 217
D.3 Candidate interfaces of the execution site . . . 219
Acknowledgements
This thesis would have not been possible without the guidance and support of my supervisor, Professor Andy Wellings. I am greatly indebted to him for his time,
understanding, patience and support. His invaluable advice and support guided me my ideas into this thesis.
I would like to thank all the members of the RTS Group especially Professor Alan Burns, Dr. Neil Audsley, Dr. Rob Davis, Dr. Yang Chang and Dr.
Mo-hammad AlRahmawy for their help and support. A large part of my work involved implementation work on Linux and I was lucky to have two gurus of Linux, Seyeon
Kim and Sitsofe Wheeler. I am grateful for their time and advice which made my job easier.
I would like to thank all my friends, Furqan Aziz, Muhammad Haseeb, Tasawer Khan, Usman Khan, Dr. Ahmad Shahid, Thomas Richardson, Shiyao Lin and Emad
Al-Oqayli for giving me strength, self belief and all the enjoyable moments.
My family has been supportive of me throughout my Ph.D. I would like to thank
my wife, my son Abdullah and my daughter Hafsah for their patience, sacrifices and support. I also thank my sister, for encouraging me throughout my work. Lastly,
but not the least, I would like to thank my father for guiding and supporting me in every possible way, and my mother for her love, support and patience.
Declaration
I declare that the research described in this thesis is original work, which I undertook at the University of York during 2007 - 2012. Except where stated, all of the work
contained within this thesis represents the original contribution of the author.
Some parts of Chapter 4 are based on the paper presented in the 8th International Workshop on Java Technologies for Real-time and Embedded Systems (JTRES 2010)
entitled A Locality Model for the Real-Time Specification for Java [Malik et al., 2010].
Chapter 1
Introduction
Java is a platform independent, strongly typed and secure language which has gained considerable popularity since its inception in 1994. It is a high level language which
has a syntax very similar to C and C++, however, it discards the complexities of these languages to provide the programmers with a simple and powerful
envi-ronment. Applications designed for Java follow the Write Once, Run Anywhere
(WORA) philosophy, hence, applications must be able to run anywhere without prior knowledge of the target hardware and software platform. As a result, Java applications are being used on a range of platforms from large server machines to
small embedded devices such as mobiles.
The real-time specification for Java (RTSJ) extends the Java programming lan-guage to provide a platform for the programmers to develop and execute applications
that have some specific timing constraints. Typically real-time applications monitor events in the real world and then responds to those events in an appropriate
man-ner within a finite period of time. Some real-time systems can tolerate occasional deadlines misses (in soft real-time systems) while in others missing the deadlines is
as bad as producing a wrong result (in hard real-time systems). In order to sup-port such systems, a large number of extensions have been made to the standard
Java technology especially to the scheduling and the memory models to make the execution of programs more predictable.
Recent years have seen a change of paradigm in the computing world from single
the physical limits of speed and a large amount of effort and cost was required for the little gain in performance [Asanovic et al., 2006]. As a result, now single processor
systems are becoming obsolete and vendors are replacing them with multi-cores. In 2004, Intel canceled the development of two of their high speed microprocessors to
focus on the development of multi-core processors [Flynn, 2004]. Newer architectures are replacing high-clock-speed processors with many simpler and smaller processing
elements. The number of cores in future system will be in thousands [Asanovic et al., 2006]. In order to support such parallelism, the memory sub-system also
becomes distributed. These architectures will be capable of producing very high performance; however, their programming will be more complex than in the single
processor case.
Real-time systems are also increasing in size and complexity and the only archi-tectures that will be able to satisfy the needs of these applications will be
multipro-cessors. At the same time, it is quite possible that the real-time systems may be sharing the same platform with many other applications. These applications can be
of different criticality levels and may have diverse timing requirements. Typically, real-time systems require timing requirements of all the different applications
run-ning simultaneously with the real-time application to be known a priori to ensure that timing requirements are met. However, on large systems it becomes nearly
impossible to do the global analysis of the system. Hence, architectural complexity and tight timing constraints make the development of real-time systems on
mul-tiprocessor architectures extremely difficult. The usual objective of programming platforms for these systems is to hide the complexity of the architectures so that
the programmers are not distracted by low-level architectural issues. However, for real-time systems, the programming languages need to provide high level constructs
with semantics to use the underlying architecture predictably and efficiently. If achieved, this will lead to programmers being more productive and at the same
time predictability and performance of the applications will also increase.
Java’s built-in support is adequate to make sure it runs seemlessly on shared memory multiprocessors even if memory access timings become non-uniform.
1.1 The Real-time Specification for Java
allocation policies of threads and objects. The current RTSJ, i.e. RTSJ 1.02, does not support multiprocessors, however, a number of extensions have been proposed
for RTSJ 1.1, these are discussed in Section 1.3. The focus of these changes is to pro-vide a set of tools to support the construction of parallel real-time Java systems for
symmetric multiprocessor systems (SMPs) having uniform memory access timings. In such systems, there is little to be gained (performance wise) from the
program-mer having direct control over where data is stored. From a schedulability analysis perspective, the programmer may still require control over where threads are
exe-cuted, but control of where data is placed has no effect. However, in systems where memory timings change depending in the processor from which it is being accesses,
then in such systems, control of data becomes very important because remote ac-cesses can cause unpredictable delays. These delays not only effect the performance
of applications but can lead to very pessimistic worst case timing analysis.
In this thesis, we focus on the support that we can provide in RTSJ for soft
real-time systems to execute on cache coherent non-uniform memory access (cc-NUMA) systems by providing them resource guarantees. Calculating the worst case
execution time (WCET) for such systems is out of the scope of this thesis, however, the effect of non-uniform memory access (NUMA) on the execution times will be
analysed.
Section 1.1 gives an overview of the RTSJ, followed by Section 1.2 which discusses different types of shared memory multiprocessors which include uniform and
non-uniform memory access systems. Section 1.3 outlines the existing support for mul-tiprocessors in RTSJ. Section 1.4 presents the motivation of supporting cc-NUMA
systems in RTSJ followed by the hypothesis in Section 1.5 and the aims of the thesis in Section 1.6. Section 1.7 outlines the basic structure of the thesis. Section 1.8 is
the last section which summarizes the whole chapter.
1.1
The Real-time Specification for Java
The correctness of a real-time system depends on two things: the logical results of
defined by [Young, 1982] (as cited in [Burns and Wellings, 2001]) as “any information processing activity or system which has to respond to externally generated input
stimuli within a finite and specified period”. Meeting the deadlines does not mean that the system should be super fast; rather it requires the system to be predictable.
Real-time Systems can be classified broadly in to hard or soft time. Hard real-time systems are very strict in terms of their timing requirements and missing any
specified deadline can have catastrophic consequences. Examples of hard real-time systems include flight control system of a combat aircraft, braking system on a car or
some industrial process control system. Soft real-time systems on the other hand are much more relaxed in terms of their timing requirements and occasionally deadlines
can be missed, however, missing the deadline can lead to degraded quality of service and usually does not have any critical consequences. Examples of soft real-time
systems include audio/visual systems which require a specific frame rate to ensure an enjoyable experience.
Since its introduction, Java was designed to be a high performance language
with dynamic features such as garbage collection and just in time compilation. In addition there was no support to implement different scheduling policies for thread
scheduling within the application. Mostly it relied on the OS scheduler to dispatch threads for execution; which meant that it is quite possible that the highest priority
thread might be waiting because a low priority thread cannot be preempted. In order to support real-time systems (RTSs), the Java community has developed the
RTSJ which makes a number of extensions to make the execution of the program predictable. Among these changes the most important are the changes that have
been introduced to bound the delays of the garbage collector and introduce a new scheduling model to support different scheduling policies.
The Java Language Specification [Gosling et al., 2005] implicitly defines the
behaviour of the garbage collector by defining the life cycle of a Java object. Most Java virtual machines (JVMs) implement the lifecycle by using a garbage collector
that traverses through all the unreachable objects to reclaim the memory in the heap. In such environments, garbage collector disrupts the normal program execution and
1.2 Cache Coherent Non-Uniform Memory Access (cc-NUMA) Architecuture
The RTSJ introduces new memory areas which are not affected by the garbage collector. These memory areas include the scoped memory areas and the immortal
memory area. The scoped memory areas are coarse grained memory areas where objects are not collected individually, however, the entire memory area is reclaimed.
Immortal memory areas are never collected, therefore, any object allocated inside here remains forever. These new memory areas provide an alternative to the heap
memory area which is the only memory area used for object allocation in Java.
The RTSJ also introduces new threads which are capable of avoiding any in-terference from the garbage collector. These threads implement a new interface,
Schedulable, which attach these threads with scheduling parameters. The Schedula-bleinterface is implemented byRealtimeThread andAsyncEventHandler classes and are called schedulable objects or simply schedulables. The scheduling parameters are used to implement different policies and executing schedulables along with the
new memory areas allows RTSJ control over the behaviour of the garbage collector.
1.2
Cache Coherent Non-Uniform Memory
Ac-cess (cc-NUMA) Architecuture
Shared memory multiprocessors (SMMPs) consist of a number of processors con-nected together with the help of shared memory. Processors communicate with
each other with the help of shared variables [Hennessy and Patterson, 2006]. An important characteristic of the SMMP is the presence of a single address space for
all processors. The single address space enables the processors to access memory using simple load and store instructions.
SMMPs can further be classified as uniform memory access (UMA) and non
uni-form memory access (NUMA) depending upon the uniuni-formity of the time taken by different processors to access memory. UMA is a computer architecture defined as “a
multiprocessor in which all processors work through a central switching mechanism to reach a shared global memory” [Quinn, 1994].
The multiprocessors which follow UMA architecture are Symmetric
processors which are connected to a shared memory through a common bus. Al-though there are multiple processors, the memory is uniformly accessible by all of
them, hence all data is at the same distance from all the processors as shown in Figure 1.1. The examples of SMPs are SGI Power Challenge, DEC Alpha Server
8400, CDC6600, IBM Power4 and IBM Power 5.
On an SMP, each processor has equal priority to access the shared memory and
I/O devices. The shared memory bus (or the shared memory controller) becomes congested during memory accesses as multiple processors use the bus
simultane-ously. A single OS image runs on top of the SMPs and handles the hardware. As the number of processors increases, bus contention becomes a problem which results
in high latency memory accesses. The use of large caches reduces the use of the bus. They provide low latency access to the memory and reduce the bandwidth
re-quirement of the processors. Each processor is able to cache data, and with multiple caches around it is possible that the data is cached at more than one place. This
requires that the data in different caches and in the memory is coherent. Updates performed by a processor should become visible to all processors before they use it.
This requires the implementation of cache coherent protocols which ensure consis-tency of data in caches. These protocols have been discussed in detail in [Hennessy
and Patterson, 2006].
Figure 1.1: The Uniform Memory Access(UMA) Architecture
NUMA is a shared memory multiprocessor which does not support constant time memory access. According to [Quinn, 1994] “in most NUMA architectures, memory
is organized hierarchically, so that some portions can be read and written more quickly by some processors than by others”. SMPs do not scale very well because
1.2 Cache Coherent Non-Uniform Memory Access (cc-NUMA) Architecuture
NUMA systems however are somewhat distributed in nature; some memory banks are closer to some processors while farther from others. They are typically created
by coupling SMPs together by connecting the memory controllers through a high speed interconnect; as a result NUMA systems scale better than a SMP. While a
processor can access all memory areas, still latency of memory accessed depends on where the memory is allocated. Figure 1.2 shows a generic 4 node NUMA system.
Figure 1.2: The Non-Uniform Memory Access(NUMA) Architecture
Each processor has low latency access to one or more memory banks that are nearer to the processors and higher latency access to the rest. Still latency of the
farthest memory banks is very small as compared to distributed systems due to high speed interconnects. Like SMPs, a single OS image is present over the NUMA
systems. The important thing to note is that in NUMA architectures, the global address space is provided at the hardware level. This means that all processors can
access any memory word with simply load and store instructions. NUMA distance is measured in hops or by latencies.
Cache coherent NUMA (cc-NUMA) is a type of NUMA which allow data to be cached from remote memory. Most of the NUMA machines are cache coherent and
like SMPs they also require cache coherence protocols to keep data consistent. Non cache coherent NUMA (ncc-NUMA) machines only allow data from local memory
to be cached, though processors are able to access remote memory but they cannot store the data from remote memory in their cache.
Remote accesses have high latency; if the accesses are frequent then data can be
migrated or replicated in the local memory [Bolosky et al., 1989]. The SGI 3000 fam-ily is a NUMA architecture based on the 64 bit Intel Itanium 2 processor [Woodacre
can support up to 1024 nodes or 2048 processors i.e. each node has two processors. These nodes are connected by a high speed interconnect, NUMALink, which
pro-vides low latency access to memory on other nodes. For desktops, AMD Opteron and Athlon families are based on the HyperTransport link and are capable of
pro-viding support for NUMA systems. The behaviour of an application depends on the number of components (processors, memory and devices) in a system and how
they are inter-connected to each other. Because of the wide variety of multi-core architectures, it is necessary to make some assumptions of what is and what is not
supported. In this thesis, we consider a reference NUMA architecture. NUMA sys-tems are shared memory multiprocessors where memory is physically distributed
among nodes. Nodes can have a number of processor memories directly attached to it. Nodes are connected by a very high speed interconnect which allows fine grained
access to remote memory. Usually NUMA systems have the following properties:
• A single address space exists.
• Cache coherency may exist globally or partially.
• Memory access latencies may vary when different processors access the same memory bank.
1.3
Support for Multiprocessors in RTSJ
On multiprocessors, the multi-threading model of Java enables Java applications to use more than one processor thereby effectively speeding up the application
(assum-ing there is 1-1 mapp(assum-ing between Java threads and operat(assum-ing system threads). This allows non real-time applications to execute unchanged on multiprocessors.
How-ever, the availability of many processors completely changes the scheduling model for a real-time systems. Therefore, real-time Java applications require multiprocessor
scheduling models to be supported by the Java platform.
A number of extensions have been outlined for RTSJ-1.1 [Dibble and Wellings, 2009], which mainly focus on supporting different scheduling models available in
1.4 Motivation
pinning real-time threads and bound asynchronous event handlers to specific pro-cessors, clarification of the logical dispatching model on multiprocessors and the
behaviour of processing group parameters on multiprocessors.
Although SMPs have nice properties from a programmability perspective, as previously mentioned they do not scale well due to contention on the shared buses
accessing the memory banks. NUMA architectures on the other hand use different busses to access different memory banks, allowing all processing cores to access all
the main memory banks; however, the access time will vary from core to core. As a result, performance of a program can be increased by keeping data local to its
accessing threads. Therefore, new high level semantics need to be introduced at the language level to support such systems.
1.4
Motivation
Single processor systems will become less frequent while multiprocessors are
in-creasing in popularity. NUMA systems are more scalable multiprocessors and it is likely that this architecture will be used more and more as the platform of choice.
Real-time programming will become increasingly difficult with traditional low-level languages on complex multiprocessor architectures.
Real-time Java is a developing real-time language which provides high level
ab-stractions for real-time programming, therefore, this makes real-time Java a suit-able language which can be extended for such systems. Supporting NUMA systems
means there are performance benefits to be had and the behaviour of the application can be made more deterministic.
Cache coherent NUMA (cc-NUMA) has a memory hierarchy which is physically distributed. This makes it a more scalable architecture than the conventional UMA
based SMP system. However, the memory distribution affects the application be-haviour on the system because of the introduction of remote memory accesses which
have higher latencies. In such systems, there are considerable benefits to be had by allocating related threads and data close to each other.
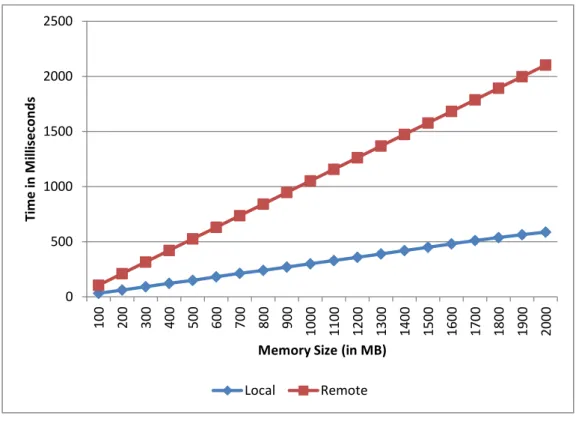
keeping data local while using the memcpy() function. This function copies a chunk of memory from one place to another. The figure shows that there is a large
per-formance difference when executing the memcpy() function on local memory when compared to the remote memory. This figure is based on results obtained by
execut-ing the TAU benchmark1 on a small cc-NUMA system. More details can be found
in Appendix-A. 0 500 1000 1500 2000 2500 100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 2000 Ti m e in M il li sec o n d s
Memory Size (in MB)
Local Remote
Figure 1.3: Time Taken by memcpy()
Multiprocessors encourage platform sharing among applications, these applica-tions can have different timing requirements and can be of different criticality levels.
The Linux OS also supports multiple applications executing at the same time, both real-time and non real-time. Typically for real-time systems, it is required that
the system should be globally analyzed and worst case timings of all applications which can be sharing the platform with the real-time application should be taken
in consideration. On such a large system, it is nearly impossible to analyze all the different permutations that the applications can have to run simultaneously with the
1.5 Hypothesis
real-time application. Instead, it is more efficient and flexible to isolate the applica-tion and provide resource guarantees. Such an approach, removes any dependencies
that the application has regarding the hardware or sharing the platform with other applications.
1.5
Hypothesis
The current RTSJ does not have appropriate support mechanism to enable pro-grammers to easily develop portable and deterministic soft real-time applications for NUMA systems. However, it is possible to enhance the ability of RTSJ platforms by providing visibility into the underlying architecture, controlling the allocation policies and finally supporting resource reservation for guaranteeing timeliness and temporal isolation. These extensions will enable programmers to develop more deterministic and portable applications.
1.6
Thesis Aims
This thesis mainly concerns the execution model of real-time Java programs on cc-NUMA shared memory multiprocessors. The major aim of the research is to
enhance the programming model of RTSJ to enable programmers to develop portable real-time Java applications on a shared and open environment. To support the
hypothesis, the following objectives are considered:
1. To investigate the limitations in existing RTSJ to develop portable real-time Java applications on cc-NUMA architectures.
2. To propose new high level abstractions which make the real-time Java virtual machine (RTJVM) aware of the hardware resources available for the
applica-tion.
3. To propose new high level abstractions to manage the allocation policies of threads and objects in order to minimize the non-determinism caused by the
4. To support static and dynamic allocation of applications on hardware.
5. To support temporal guarantees to applications to ensure they meet their
timing requirements.
6. To demonstrate that such a model can be implemented by presenting a pro-totype implementation.
7. To analyze the proposed model to check for improvements in performance and
predictability.
Achieving these objectives would facilitate the development of portable real-time
Java applications on cc-NUMA architectures.
1.7
Thesis Structure
In accordance with the motivations and objectives of the research, the thesis is
organized with seven chapters. Brief descriptions of the remaining chapters are given below:
Chapter 2. Literature Survey: The chapter reviews three different areas. First existing parallel programming languages are reviewed and issues of parallelism
and locality are discussed. Next, existing work on real-time systems on multi-processors is reviewed. An open and shared environment is considered and the
support required for soft real time systems is discussed. Java is discussed as the language of choice for parallel programming and how it is used in different
contexts of multiprocessors, starting from shared memory multiprocessors to distributed systems. Lastly a set of of requirements are derived which need to
be supported towards the goals of the thesis.
Chapter 3. Existing Support for cc-NUMA Architectures: The chapter dis-cusses the extensions made in order to support real-time systems in Java and
the support RTSJ has for multiprocessors. The chapter highlights support provided for cc-NUMA systems in Linux and RTSJ. This chapter focusses on
1.8 Summary
NUMA nodes which can then be used for explicit memory allocation, this chapter also looks in detail at the AffinitySet class that has been proposed for
RTSJ 1.1 and using it to pin schedulable objects to processors. At the end of the chapter, limitations are outlined in the existing RTSJ for the development
of portable real-time applications for cc-NUMA systems.
Chapter 4. Locality Model: The chapter presents a locality model for the RTSJ
which overcomes the limitations outlined in Chapter 3. New abstractions are presented to represent NUMA architectures along with design patterns which
are used to create memory areas and schedulable objects (and Java threads). Extensions are presented to the physical memory model and a new memory
area, PhysicalHeapMemory, is proposed. A new abstractionExecutionSite to provide locality on a cc-NUMA system. It also discusses open-systems and how
contracts can be used to map applications onto NUMA systems. Contracts are discussed in the context of execution sites and open systems based on these
execution sites are discussed.
Chapter 5. Implementation: The chapter explains the details of the
implemen-tation of the prototype.
Chapter 6. Evaluation: The chapter evaluates the Locality model. A set of
ex-periments are also performed to evaluate the locality model in terms of per-formance. Overheads of the Locality model and the prototype are presented.
Chapter 7. Conclusions and Future Work: Finally, in the last chapter, con-clusions are drawn and recommendations are made for future work.
1.8
Summary
This is the introductory chapter of the thesis which discusses the non-determinism
caused as a result of cc-NUMA Systems. This chapter discusses shared memory architectures and gives an overview of the RTSJ along with some of the features it
has to support multiprocessors. The chapter further outlines the hypothesis, goals and objectives of this thesis ending with the structure of the rest of the thesis.
Chapter 2
Literature survey
This thesis combines practices from both parallel computing and real-time system communities into the real-time Java programming language to support large scale
systems on cc-NUMA architectures.
The goal is to provide programmability, performance, portability and predictabil-ity on shared memory architectures where memories have variable access timings. The chapter highlights issues of parallelism, locality and resource guarantees to
achieve the goals of the thesis.
The chapter reviews the existing literature in the following areas:
1. Parallel programming on multiprocessors
2. Real time systems and multiprocessors
3. Java based programming languages on multiprocessors
Cc-NUMA systems are now entering main stream computing due to the scalabil-ity issues of traditional SMPs. Real-time systems’ transition from single processor to
multiprocessors is a very active research area with the emphasis being on scheduling on SMPs. However, cc-NUMA systems have been around for quite some time in
the High Performance Computing (HPC) community. The Java platform has also provided a base for extension for parallel programming. In this chapter we discuss
multiprocessors in all these three cases. A set of requirements is extracted to sup-port large scale parallel applications on cc-NUMA multiprocessors in the context of
Section 2.1 reviews parallel programming languages especially in the HPC com-munity in terms of parallelism and locality. Section 2.2 discusses real-time systems
and multiprocessors. Section 2.3 presents the Java platform in the context of mul-tiprocessors. Finally, section 2.4 summarizes the chapter.
2.1
Parallel Programming on Multiprocessors
The HPC community has vast experience in parallel programming and while other communities are making the inevitable shift to multiprocessors, a number of things
can be learnt from the evolution of parallel programming in HPC.
In this section we review different approaches taken in the literature to provide parallelism and locality on NUMA systems.
2.1.1
Parallelism
Parallelism has been the main focus of programming on shared memory multipro-cessors. The HPC community focuses on increasing both run-time performances,
by maximizing parallelism in applications, and to increase productivity of program-mers.
Early work in parallel programming was concentrated towards automatically
par-allelizing where compilers and runtime systems were used to extract parallelism from sequential programs. The advantage of such an approach is that existing applications
need not be modified for the speedup. High Performance Fortran (HPF) [Koelbel et al., 1994] automatically parallelizes operations on matrices and vectors to be
performed on separate processors. However, extracting parallelism from sequential programs is very limited and it does not allow the application to fully exploit the
parallelism that is on offer at the hardware level.
In order to achieve better performance, parallelism needs to be expressed in applications to exploit the parallelism available at the hardware level.
The POSIX threading library [IEEE, 2008] allows explicit parallelism where
threads are created and managed explicitly.
2.1 Parallel Programming on Multiprocessors
directives to tell the compiler the existence of a parallel region. OpenMP is much easier to use as the compiler manages the threads, workload is implicitly divided
and threads are implicitly synchronized based on programmer’s directives of syn-chronization.
Java follows a similar approach to the POSIX threading library where threads are created and managed explicitly by the programmer. X10 [Charles et al., 2005]
replaces the existing threading mechanism by light weight threads called activities. These activities are managed implicitly in place of Java’s existing explicit model.
The RTSJ uses the same threading model as standard Java. RTSJ has integrated it with scheduling parameters which allow implementation of scheduling policies to
control the order in which threads will be executed. This thesis uses the same threading model for parallelism and concentrates on providing locality on a
cc-NUMA system.
2.1.2
Locality
An application requires efficient mapping onto the hardware architecture to achieve better performance. This performance on a NUMA system depends on the thread
and memory allocation policies. Portability of performance is also very important on portable platforms (such as Java), that is to get the best performance regardless
of the underlying machine without having to modify the application or the execution environment. Applications which are not supposed to be portable (often in the case
of an embedded system) are required to extract the best performance out of the system, however, for portable applications mapping policies should be focussed on
achieving portability of performance.
On a cc-NUMA system, related threads and objects need to be placed close
together to each other. This reduces the number of remote accesses resulting in a better performance of the application. However, not all mapping strategies follow
the same rule. Generally, the following strategies can be adopted during application mapping:
1. In the first approach the mapping is done by the runtime without any
such as Linux where threads and memory are allocated based on load balanc-ing.
Threads are evenly spread across a number of processors and are migrated
in case of any load difference between processors. The Linux scheduler tries to balance load in a hierarchical fashion in a cc-NUMA system where it first
tries load balancing at the node level and then proceeds to balance the load between the nodes [Aas, 2005].
For the allocation of memory, a number of different policies can be used.
Touch policies are very common for memory allocation where the allocation is based on the pattern of data being accessed. For example, the first touch
policy allocates the memory local to the processor which accesses the data for the first time. Another policy is the next touch policy which allocates
the data on the local memory when it is accessed the second time and is considered to perform better than the first touch policy [Goglin and Furmento,
2009]. Memory interleaving is another policy where data is allocated in a round robin fashion among the nodes. Such a policy does not consider locality
among threads and data but rather tries to achieve maximum bandwidth while accessing the data.
These approaches certainly have the advantage that applications are very
portable across such platforms and benefit from these policies. However, the performance of the applications is far from the peak performance which can
be achieved on the system. In this case, the relationship among threads and between threads and data is ignored which can help in improving the
perfor-mance of the system.
2. The second approach is based on applications that have been designed to run on specific platforms. Allocations are done explicitly by the programmer
requiring significant effort and become extremely difficult and complex in the case of large systems.
The architecture of the system is analyzed and then thread affinities and
2.1 Parallel Programming on Multiprocessors
Following are some of the examples of programming models using this ap-proach:
• The Sequoia programming language [Fatahalian et al., 2006] is designed specifically for embedded systems. It is an extension of C which enables
programmers to statically map applications on platforms with non stan-dard memory architectures. It represents the architecture as a virtual
tree and explicitly manages data movements between memory banks. It requires programs that can be broken down into a hierarchy of isolated
units of execution and then physically mapped onto the architecture.
• The RTSJ provides physical and raw memory access. Objects are created using physical addresses of memory and similarly raw memory can be accessed through their memory addresses (in case of memory mapped
I/O) or their port number.
This approach has been designed to extract the maximum performance out of
the system; however, applications are not portable. Threads and data can be co-located with devices using this approach.
3. The third approach tries to combine the above two approaches to provide portability and performance. The mapping is based on the negotiations of the
application and the architectural platform.
At the architecture level, the operating system can provide detailed informa-tion on the target machine. For example, the informainforma-tion can include number
of processors, organization of caches, organization of the memory banks on NUMA machines etc. The application needs to be aware of the processors,
memory and devices in a system and how they are connected. A single system image hides all the information regarding the hardware and presents a
sim-ple environment for the applications to execute on. Processors and memory devices are usually hidden by the single system image provided by operating
systems and the application executes as if it has a single processor and single memory. However, operating systems also provides libraries and APIs which
At the application level, information can be provided regarding the behaviour
of the application. Determining the sharing patterns of threads and data
is an important step before the threads/data can be allocated. [Tam et al., 2007] suggest that the sharing patterns of threads should be detected online
and threads should be grouped once this pattern is known. The advantage of using this approach is that threads can be dynamically regrouped during
different phases of a program based on changing relationships between threads, however, the overheads are very high. Most modern programming languages
X10 [Saraswat, 2010], Fortress [Allen et al., 2007], Chapel [Diaconescu and Zima, 2007] depend on the programmers to define the relationship among the
components of the application.
Following are some the examples of programming languages that adopt this
approach:
• The Fortress [Allen et al., 2007] programming language provides an ex-tensive library of language contructs calledDistributions which allow the programmers to specify data distribution and locality. Fortress provides
regions which abstractly describe the architecture of the hardware on which the application is running. Each region contains an execution level where the threads reside and a memory level where the objects reside.
The programmer is enabled to place threads in a particular region and objects in most cases are placed local to the thread calling the
construc-tor.
• The X10 language [Saraswat, 2010] has multiple non-overlapping places; these are virtual locations which group together multiple activities (threads) and objects. Physical location of places can change depending upon the
load balancing policy. Activities and objects remain in the same place for their lifetime and are unable to migrate to other places. Remote access
is only possible by spawning asynchronous activities which are used to communicate between two places.
2.2 Real Time Systems and Multiprocessors
units of uniform memory access (nodes). There is no difference between local and remote access as there is in X10. Chapel also allows
program-mers to distribute objects into specific locales and objects are not bound to a single locale for their lifetime.
This approach provides a balance between portability and performance. This is required when the application is portable but still requires threads and data
to be co-located. The execution of an application is closely tied to the structure of the hardware. Portable applications need to adapt to target architecture
for better performance and efficient use of resources.
As part of this thesis, we focus on providing an environment which will allow the programmers to develop applications with portable performance by supporting
a programming model which in similar to the third approach described as above. In addition, the model will also extend support available in the RTSJ to access physical
and raw memory on cc-NUMA systems.
2.2
Real Time Systems and Multiprocessors
The paradigm shift towards multiprocessors increases the motivation for sharing the platform and most modern general purpose operating systems allow a number
of different applications to run on a platform simultaneously. Executing real-time systems on shared platforms requires the system to behave as if the platform is
dedicated to the real-time application where resources are provided to it according to its scheduling parameters and any other application should not be able to cause any
disruptions during its execution. In other words the system should be able to provide temporal isolation (or temporal protection) to the real-time application. [Buttazzo
et al., 2005] puts it as “the temporal protection property requires that the temporal behaviour of a task is not affected by the temporal behaviour of the other tasks
running in the system”.
Temporal isolation can be provided to applications by resource reservation
manner so that their timing requirements are met. In the case of a multi-threaded application/component resource reservation mechanisms can be applied to the thread
level. Essentially multi-threaded applications need a hierarchical scheduler where at the global level the application is competing against other applications for
re-sources. Within the application/component threads compete among themselves for the available resources.
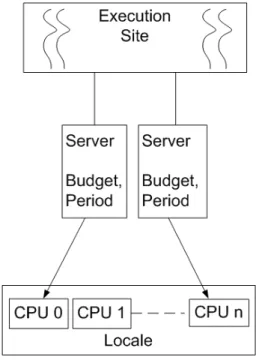
A server is a CPU execution accounting and enforcing mechanism which has a
capacity and a replenishment period, it makes sure that an activity or a group of activity does not use more than the capacity and replenishes the capacity
periodi-cally. Execution-time servers have mainly been used to service aperiodic activities without affecting periodic and sporadic activities. Aperiodic activities do not have
well defined release characteristics; as a result they can have an unbounded demand for processor time while competing with periodic and sporadic activities. Running
these aperiodic activities at a lower priority than periodic or sporadic means, they get very little chance to run and they often have poor response times. As a result
servers have been used to provide a lower response time for aperiodic tasks.
Alternately, servers have also been used to build compositional real-time
embed-ded systems. The focus of the servers shifts to make sure that components actually get the execution time that they have been guaranteed.
[Deng et al., 1997] were the first ones who used hierarchical scheduling to provide
temporal isolation for multithreaded applications. Each application was allocated a dedicated constant utilization server (CUS) with a maximum utilization factor Ui.
Later a bandwidth sharing server (BSS) was used to provide temporal isolation in multithreaded applications. Both of these approaches require the global scheduler
to be aware of the timing parameters of tasks inside an application. In the case of open systems, such information might not even be present because of the presence
of non-real time threads which do not have scheduling parameters (such as WCET and deadlines).
[Mok et al., 2001] present a resource partition model where a resource parti-tion is a periodic sequence of disjoint time intervals. This approach is based on the
2.2 Real Time Systems and Multiprocessors
within a task group are scheduled while the second level scheduler (global sched-uler) is responsible for assigning partitions to task groups. Both these schedulers
are completely isolated at runtime because the global scheduler does not require the timing parameters of the tasks within each task group. The bounded delay model
was proposed in [Mok et al., 2001] which generalizes the partition model to accom-modate an on-line global scheduler. The bounded delay model can be represented
by the interface (α,△), where α is the bandwidth while △ is the bound on the bandwidth for which it will be unavailable.The bounded model for single processors
can be represented by the Figure 2.1.
Figure 2.1: The bounded delay model for single processors
These approaches were defined for single processor systems, in case of
multi-processors, the presence of multiple processors increases the complexity of providing resource reservation when applications/components want concurrency on these
plat-forms essentially allowing them to run in parallel on different processors.
The following resource models can be used for resource reservations on multipro-cessors:
• The Periodic Model (P, Θ, m’)–The multiprocessor periodic resource model (MPR) was presented in [Shin et al., 2008] which was based on the idea of
having virtual cluster based scheduling. In this model, any application was allocated a number of periodic tasks or servers. These servers were statically
allocated on processors having the periodP and they were assigned a cumula-tive budget Θ. Application level tasks were then scheduled globally on top of
the servers. The MPR model was specified by an interface (P, Θ, m’), where m’ is the maximum level of parallelism.
• Bandwidth ω – Another interface based on the total bandwidth ω of applica-tions was presented in [Leontyev and Anderson, 2009]. The idea was to allocate
the bandwidthωonto⌊ω⌋processors and then globally schedule the remaining bandwidth on the remaining processors using a periodic server. This interface
was designed for soft real time systems and did not have any notion of period.
• Bounded delay multipartition (BDM) – The multi supply function extended
Bounded Delay Model for multiprocessors [Bini et al., 2009b] where all the
processors had the same (α,△) repeated for m processors. This multi sup-ply function was next generalized in the parallel supsup-ply function [Bini et al.,
2009a] which allowed different processors to contribute differently to the bud-get. Based on the parallel supply function, interfaces are derived in [Lipari
and Bini, 2010] to reduce the pessimism.
2.3
Java on Multiprocessors
Java has been used in a number of distributed and high performance systems where
high level APIs have been provided to support parallel and distributed applications. In this section, we will focus on the different Java based extensions that have targeted
distributed systems and shared memory multiprocessors.
2.3.1
Java on Distributed Systems
On a distributed system, Java threads and Java objects are distributed between the
nodes of the distributed multiprocessor which do not share a single address space. This, however, should not restrict Java threads from accessing all objects irrespective
of the location of threads and objects. This means when a thread running on one node accesses an object on another node then either the code of the thread should be
transferred to the remote node or the data from the remote node should be retrieved. Java provides an API, the Java RMI (remote method invocation), which allows
the JVM to invoke methods of objects running on another JVM. Java RMI’s stub and skeleton architecture gives the impression that the method is being executed
locally while the reality is that it executes on a remote node and returns the re-sults. This allows the programmer to distribute objects on various machines, and
2.3 Java on Multiprocessors
distributed garbage collection. Remote objects are considered alive when they have been referenced within a certain period of time i.e. lease period. When the lease
expires and it is not renewed, the objects become available for garbage collection. The problem with Java RMI is that it requires the programmer to manage and
dis-tribute the computation explicitly. This makes RMI programming difficult because the programmer has to put extra effort to program interfaces and classes which do
not help him in solving his actual problem.
Java distributed shared memory systems (DSMs) provide the Java platform over a distributed system by hiding its distribution and providing a single system
im-age (SSI). Java DSMs provide a higher level of abstraction than Java RMI. While Java RMI requires the programmer to explicitly distribute computation load among
the nodes, Java DSMs on the other hand automatically maps threads to different processors and provide a shared heap where the objects can be placed.
The following highlights design and implementation issues of Java DSMs:
1. In a Java DSM the following changes are required to different memory areas:
(a) Implementing the heap – The heap is a memory area which is shared by all threads. In order to extend the heap to Java DSMs the objects
should be accessible by all the threads irrespective of the location of the thread or the physical location of the object. One way of doing this is by
implementing the heap over an existing DSM.
(b) Implementing the method area – The method area stores the code, which is shared by all threads. In order to extend it to multiple processors, it
should be copied to all nodes of the cluster. Multijav first looks for class bytecode in its local memory, then asks the root node to send the desired
class bytecode.
(c) Implementing the stack – The stack is a JVM memory area which is private to a thread. The stack contains frames which are pushed when
a method is invoked and is popped when a method returns. Normally in the case of a Java DSM there is no need to make any changes to
of nodes as it is in the case of method shipping in cJVM [Aridor et al., 1999]. Then the stack is also distributed along with the thread. Here the
thread is required to have a global id. Even after the distribution the stack is required to be traversal and it should give the correct value on
calling the Thread.currentThread().
2. The following scenarios can be envisaged to provide access to a remote object:
(a) Method Shipping – Method shipping is used when remote accesses are fine grained and rare, then it is possible to redirect the code to the home node
of the object. The thread is not migrated but only the method executes remotely on the object and then returns back to the home node. This
approach uses mechanisms such as remote procedure call (RPC) such as Java RMI. However, this is at a higher level than RMI and the
commu-nication between thread and remote object is handled by the runtime. This approach has been followed in cJVM [Aridor et al., 1999].
(b) Object replication – Object replication is used when remote accesses are
coarse grained and frequent, and multiple nodes try to access the object simultaneously. The object replication approach allows multiple nodes
to simultaneously read the objects. The original copy of the object re-mains on the home node, which is updated consistently in case of any
write and all other copies are invalidated. This approach is used by JES-SICA (Java Enabled Single System Image Computing Architecture) [Ma
et al., 2000], Jackal [Veldema et al., 2001], JavaSplit [Factor et al., 2006], JESSICA2 [Zhu et al., 2002] and Hyperion [Antoniu et al., 2001].
(c) Thread migration – Thread migration is usually used to balance the load, but it can also be used to provide access to remote object. It is different
from method shipping in a way that in method shipping the control of execution returns backs to the original node after the execution of the
method on the remote node. In order to perform thread migration, all the associated data also has to be migrated along with the thread, which
2.3 Java on Multiprocessors
it has to access a remote object.
(d) Object migration – Object migration only benefits in the case when re-mote accesses are frequent from a single node, then the object can be
migrated to the remote node. However, in a shared memory environment (in Java) objects can be referenced by more than one thread, therefore,
it is not viable to migrate the object every time it is referenced.
While all of the above enable threads to access remote objects, the top two
are the only ones that are actually used for providing distributed access in Java DSMs. The bottom two are used for load balancing; they can be used
for providing remote access to objects.
3. Java DSMs can be implemented using the following approaches:
(a) Java DSMs built over existing DSMs: In a Java DSM which has been
built on already existing DSM subsystem as shown in Figure 2.2, effi-cient channeling of information from a JVM to the DSM subsystem is
very difficult and causes performance lapses. Page based DSMs such as Treadmarks [Amza et al., 1996] which have been used in JESSICA [Ma
et al., 2000] and Java/DSM [Yu and Cox, 1997] causes false sharing. The implementations use the API provided by the DSM subsystem for
memory and thread management.
(b) Native Java DSMs: Java DSMs that have been based on interpreter JVMs(JESSICA, Java/DSM) as shown in Figure 2.3, are unable to
pro-vide the performance which can be propro-vided by native machine code. As a result a number of Java DSMs i.e. Jackal and Hyperion opted to
trans-late Java code into native code for achieving performance in the long run. Such approaches do not use the JVM and do not benefit from the security
and portability provided by the JVM.
(c) Java DSMs with built-in DSM: In this approach the JVM is modified to provide a distributed shared heap at the JVM level as shown in Figure 2.4.