Research Article
July
2017
Computer Science and Software Engineering
ISSN: 2277-128X (Volume-7, Issue-7)
Review of Optical Character Recognition Techniques&
Applications
Arusa Firdous
M. Tech Student
Department of Computer Sciences, Swami Devi Dyal Inst. of Engg. & Technology Kurukshetra University, Kurukshetra, Haryana, India
Neha Pawar
Assistant Professor Department of Computer Sciences, Swami Devi Dyal Inst. of Engg. & Technology Kurukshetra University, Kurukshetra, Haryana, India
Muheet Ahmed Butt
Scientist, PG Department of Computer Sciences, University of Kashmir, Srinagar, Jammu and Kashmir,
India
Majid Zaman
Scientist, Directorate of IT&SS.
University of Kashmir, Srinagar, Jammu and Kashmir, India
DOI: 10.23956/ijarcsse/V7I7/0158
Abstract:The Character Recognition of both keyboard typed and handwritten characters has still a long way to go in terms of research. Although significant success has been achieved in type written characters but in handwritten it is still to touch an appreciable level. Most of the methods that have been proposed in this regard have huge computational complexity. The proposed review provides an in depth review of the OCR methods which include segmentation, classification and recognition of characters independent in size and texture. The proposed review also provides the literature survey in a summarized manner providing a comparative analysis of various OCR techniques. Keywords:OCR, PSO, BFO, THD, EDM
I. INTRODUCTION
Optical Character Recognition focuses on extraction and interpretation of meaningful information pertaining to a character from a digitized image in which scanned images of handwritten, typewritten text are converted into relevant machine text.The typical Optical Character Recognition (OCR) systemsare based on three stages, preprocessing, features extraction and discrimination. Each stage has its own problems, challenges and effects on the system efficiency which is the time consuming and the recognition errors. In order to avoid these difficulties this review presents new construction of OCR system for english characters.
An Optical Character Recognition System is software engineered to convert a text written on paper into machine editable text formats. The character recognition over the past three decades has been an important area of research. The importance of the character recognition assumed great significance ever since the office automation projects were taken up. Presently the character recognition forms one of the most important activities in document processing. Considering the fact that different languages have different character sets therefore intense research has been going on for automating their recognition during document processing.
The conventional methods used for the recognition of the characters mostly use a matrix based approach where each character is divided into a predefined number of rows and columns. Then depending upon the character under process a particular set of cells in horizontal and vertical direction is selected. Similarly another approach called connected component traces the character under process from one end to another to find its different parts. Approaches of this nature involve excessive computations and are mostly time consuming. In these conventional approaches some pre-processing like thinning is required before actually taking up the actual character for recognition.
Types of Optical Character Recognition
Optical Character recognition has been a subject of research. Pattern recognition has three main steps:
observation,
pattern segmentation,
and pattern classification.
Optical Character Recognition (OCR) systems is transforming large amount of documents, either printed alphabet or handwritten into machine encoded text without any transformation, noise, resolution variations and other factors. In general, handwriting recognition is classified into two types as
1. Off-line Character Recognition.
2. Online Character Recognition.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0158, pp. 206-210
On-line character recognition deals with a data stream which comes from a transducer while the user is writing. The typical hardware to collect data is a digitizing tablet which is electromagnetic or pressure sensitive. When the user writes on the tablet, the successive movements of the pen are transformed to a series of electronic signal which is memorized and analyzed by the computer.
Optical Character Recognition (OCR) is a field of research in pattern recognition, artificial intelligence and machine vision, signal processing. Optical character recognition (OCR) is usually referred to as an off-line character recognition process to mean that the system scans and recognizes static images of the characters. It refers to the mechanical or electronic translation of images of handwritten character or printed text into machine code without any variation.
Phases of General Character Recognition:
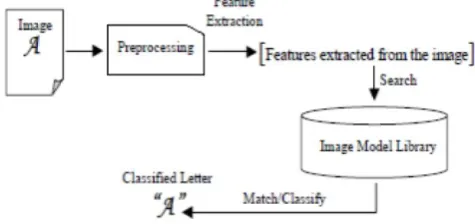
OCR consists of many phases such as Pre-processing, Segmentation, Feature Extraction, Classifications and Recognition. The input of one step is the output of next step. The task of preprocessing relates to the removal of noise and variation in handwritten. Several areas where OCR is used including mail sorting, bank processing, document reading and postal address recognition require offline handwriting recognition systems, pattern recognition.
The phases of a general character recognition system include:
1) Digitization: Digitization is the process of converting a paper-based handwritten document into electronic (Machine editable) format. The electronic conversion is accomplished by using a method whereby a document is scanned and an electronic representation of the original document as an image file format is produced. We used various computer scanners for digitization of the document, and the digital image has to go for next step that is preprocessing phase.
2) Pre-processing: In The pre-processing phase, there is a series of operations that is performed on the scanned input image. It enhances the image quality rendering it suitable for segmentation where the gray-level character image is normalized into a window sized object. After suitable noise reduction process a bitmap image is produced. Then, the bitmap image is transformed into a thinned image.
3) Segmentation: The Segmentation phase is the most important process in Optical Character Recognition. Segmentation is done by separation from the individual characters from the main image document so that each character is taken separately for recognition process. Segmentation of handwritten characters into different zones (upper, middle and lower zone) and characters is more difficult than that of printed documents that are in standard form as handwritten characters have very complex shapes and sizes. This is mainly because of variability in paragraph, words of line and characters of a word, skew, slant, size and curvedness of these characters. The components of two adjacent characters in the handwritten text may be touched or overlapped and this situation creates difficulties in the segmentation process. Touching or overlapping problem occurs frequently in the handwritten characters, because of modified characters in upper-zone and lower-zone.
4) Feature Extraction: In this phase, features of individual character are extracted and stored in various kinds of structures. It involves converting a quality of an image into a suitable and unique quantity which could be further recognized. The main features availableare zoning features, diagonal features, open-ended features and intersection.
5) Recognition: In this phase the character is recognized using the features extracted from the individual characters and building the training set. The character to be recognized is again passed through the above processes and then is compared with the training set. The best match provides the relevant information of the character to be recognized.
Figure I: Phases of Character Recognition
II. LITERATURE SURVEY
One of the oldest techniques for pattern recognition is used for character recognition, but through all days, more focus was on Latin, Chinese and Japanese languages, though connected. First, we applied Hadith’s method, which consists of removing the pixels that lie on the edge of the binary image until only one-pixel-wide line remains. This is followed by some conditions suggested by Al-Emami to reduce the junction points to one junction point. The matching procedure is executed based on an image based matching algorithm. From a practical viewpoint however, the matching time must be reduced as much as possible through the classification techniques.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0158, pp. 206-210
lexicon. Nishida attempted to recreate on-line data from off-line images and then use on-line recognition algorithms to classify words.
MAJIDA ALI ABED HAMID ALI ABED ALASADI [2005] considers a new approach to Simplifying Handwritten Characters Recognition based on simulation of the behaviour of schools of fish and flocks of birds, called the Particle Swarm Optimization Approach (PSOA).
Mohammed Z. Khedher, Gheith A. Abandah, and Ahmed M. Al-Khawaldeh2005 describes that Recognition of characters greatly depends upon the features used. Several features of the handwritten Arabic characters are selected and discussed. An off-line recognition system based on the selected features was built. The system was trained and tested with realistic samples of handwritten Arabic characters. Evaluation of the importance and accuracy of the selected features is made. The recognition based on the selected features give average accuracies of 88% and 70% for the numbers and letters, respectively.
Ivan Dervisevic [2006] proposes that the success of optical character recognition depends on a number of factors, two of which are feature extraction and classification algorithms. The proposed reasearchanalyses the results of the application of a set of classifiers to datasets obtained through various basic feature extraction methods.
Diego J. Romero, Leticia M.Seijas, Ana M. Ruedin[2007]proposes a preprocessing method for handwritten numerals recognition, based on a directional two dimensional continuous wavelet transform. The wavelet chosen is the Mexican hat and is given a principal orientation by stretching one of its axes, and adding a rotation angle. The resulting transform has 4 parameters like scale, angle (orientation), and position (x,y) in the image. By fixing some of its parameters a wavelet is obtained resulting in descriptors that form a feature vector for each digit image. The proposed research uses recognition of the handwritten numerals in the Concordia University data base. The preprocessed samples are given into to a multilayer feed forward neural network, trained with back propagation where results are seen highly promising. Chirag I Patel, Ripal Patel, Palak Patel [2011] proposes character recognition in a given scanned documents and study the effects of changing the Models of ANN. The proposed research describes the behaviors of different Models of Neural Network used in OCR andconsiders parameters like number of Hidden Layer, size of Hidden Layer and epochs. The proposed research also uses Multilayer Feed Forward network with Back propagation. The Preprocessing is achieved by applying some basic algorithms for segmentation of characters, normalizing of characters and De-skewing. The different Models of Neural Network have been applied on the test set to find the accuracy of the respective Neural Network. SushreeSangitaPatnaik and Anup Kumar Panda May 2011 proposes the implementation of particle swarm optimization (PSO) and bacterial foraging optimization (BFO) algorithms which are intended for optimal harmonic compensation by minimizing the undesirable losses occurring inside the APF itself. The total harmonic distortion (THD) in the source current which is a measure of APF performance is reduced drastically to nearly 1% by employing BFO. The proposed results demonstrate that BFO outperforms the conventional and PSO-based approaches by ensuring excellent functionality of APF and quick prevail over harmonics in the source current even under unbalanced supply.
Dileep Kumar Patel, Tanmoy Som1, Sushil Kumar YadavManoj Kumar Singh [2012]tackles the problem of handwritten character recognition by the method of multi-resolution technique using Discrete wavelet transform (DWT) and Euclidean distance metric (EDM). The technique has been tested and found to be more accurate and faster. Characters is classified into 26 pattern classes based on appropriate properties. Features of the handwritten character images are extracted by DWT used with appropriate level of multiresolution technique, and then each pattern class is characterized by a mean vector. Distances from input pattern vector to all the mean vectors are computed by EDM. Minimum distance determines the class membership of input pattern vector. The pro- posed method provides good recognition accuracy of 90% for handwritten characters even with fewer samples.
Vijay LaxmiSahu, BabitaKubde (January 2013) explains that classification methods based on learning from examples have been widely applied to character recognition from the 1990s and have brought forth significant improvements of recognition accuracies. This class of methods includes statistical methods, artificial neural networks, support vector machines, multiple classifier combination, etc. The proposed research identifies the characteristics of the classification methods that have been successfully applied to character recognition, anddemonstrates and discusses the remaining problems that can be potentially solved by learning methods.
Gurpreet Singh ChandanJyoti Kumar Rajneesh Rani Dr. RenuDhir (January 2013) proposes detailed review in the field of Off-line Handwritten Character Recognition. The proposed research also describes the techniques for converting textual content from a paper document into machine readable
Majida Ali Abed, Hamid Ali Abed Alasadi, (August 2013) proposes a new approach to Simplifying Handwritten Characters Recognition based on simulation of the behavior of schools of fish and flocks of birds, called the Particle Swarm Optimization Approach (PSOA). The work presents an overview of the proposed approaches to be optimized and tested on a number of handwritten characters in the experiments. The experimental results demonstrate the higher degree of performance of the proposed approaches. It is noted in the proposed research that the PSOA in general generates an optimized comparison between the input samples and database samples which improves the final recognition rate. Experimental results show that the PSOA is convergent and more accurate in solutions that minimize the error recognition rate.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0158, pp. 206-210
Amir BahadorBayat[2013] investigates the design of a high efficient system for recognition of handwritten digits. First it proposes an efficient system that includes two main modules: the feature extraction module and the classifier module. In the feature extraction module, seven sets of discriminative features are extracted and used in the recognition system. In the classifier module, as the first time in this area, the adaptive neuro-fuzzy inference system (ANFIS) is investigated. Experimental results show that the proposed system has good Recognition Accuracy (RA). However, the results show that in ANFIS training, the vector of radius has very important role for its recognition accuracy. At the second fold, it proposes an intelligence system in which a novel optimization module, i.e., improved bees algorithm (IBA) is proposed for finding the best parameters of the classifier. In test stage, 3-fold cross validation method was applied to the MNIST handwritten numeral database to evaluate the proposed system performances. Simulation results show that the proposed system has high recognition accuracy.
III. SUMMARISED LITERATURE SURVEY
This is detailed discussion about Optical Character Recognize and includes various concepts involved, and boosts further advances in the area. The accurate recognition is directly depending on the nature of the material to be read and by its quality. Current research is not directly concern to cursive handwriting and to recognize the child handwriting which require high supervised system. From various studies we have seen that selection of relevant feature extraction and classification technique plays an important role in performance of character recognition rate. This review establishes a complete system that converts scanned images of handwritten characters to text documents. In this paper, we have studied various papers with different algorithm. Each technique have own pros and cons. But, still there are many premature problems, when multiple optima exist. The performance is degrading. So, In future there is lots of work to remove drawbacks.” BFO WITH BPN” should give us good accuracy and increase performance. It may exist multiple optima. It is use for global optimization this proposed reviewpaper serves as a guide and update for readers working in the Character Recognition area.
Optical Character Recognition Applications
The past few decades we have seen that OCR (Optical Character Recognition) technology has been applied throughout the entire range of industry, revolutionizing the document management and digitizing process. Optical Character Recognition has enabled scanned documents to become more than just image files by converting them to a machine editable text. The OCR has enabled people to manually retype important documents when converting them to an electronic form by storing them in a machine editable text. The result have been promising, accurate, efficient and the conversion time has also be optimized.
o Banking Sector: The processing of financial cheques without human intervention is one of the widely known OCR application is in banking. A cheque is inserted into a machine, the writing on it is scanned instantly, and the correct amount of money is transferred and manipulated and reflected into the users account. This technology has nearly perfected for printed checks and for the handwritten cheques lot of research is still going on. o Legal System: The legal system demands significant computerization of manual paper documents that keep mounting over the time. The paper documents if scanned and stored demand high memory and other resources. Therefore OCR in such documents will not only reduce the storage size but will also enable the system to make these documents text-searchable, so that these documents are easily located and manipulated using standard databases using relevant keywords only.
o Public Healthcare: OCR technology provides window for digitizing large volumes of patient data including insurance details of the patient. To keep up with all of this crucial information, it has become important to ensure that input data is in machine readable form stored in a standard database that can be accessed on demand. The OCR has already provided with form processing tools so as to extract relevant information from forms with a very efficient manner in a very short span of time.
o Other Application: Optical Character recognition also finds very important applications which includeseducation, finance, and government bodies. OCR has made enormousacademic texts available on internet, which has resulted in saving huge money for students thus allowing huge intellectual sharing of knowledge. Barcodes and QR codes are playing a very important role in inventory management in manufacturing industry and retail shopping outlets. Although OCR’s show 100% success in recognizing typed characters have been developed but development of such a system for handwritten characters is still a challenge
IV. CONCLUSION
The character recognition is an active area of research and Automatic Recognition of characters of different languages has been going on since decades. Initially the research concentrated on the recognition of typed characters however later recognition of handwritten characters were also taken up.The proposed review paper provides a elaborative survey and processes involved in a typical optical recognition characters. A detailed optical recognition process is explained in brief which provides an clear insight about the conversion of Image document in a machine editable text. The review paper also provides the main objectives achieved by various researchers in the field of optical character recognition and at last the paper concludes with various applications of Optical Image Processing in various sectors..
REFERENCES
[1] Jie Zhou, QiiangGan and Ching Y Suen “A High Performance Hand–printed Numeral Recognition System with
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0158, pp. 206-210
[2] Park and Lee “Off line recognition of large-set handwritten characters with multiple hidden Markov models”,
Pattern recognition, vol 20, no 2, 1996.
[3] II-Seok Oh and Ching Y Suen “A Feature for Character Recognition Based on Directional Distance
Distribution”, ICDAR pp 288, 1997.
[4] Kim and Park Off line recognition of handwritten Korean and alphanumeric characters using hidden Markov models”, Pattern recognition, vol 29, no 5, 1996.
[5] Raymond Yee –MianTeo&RajjanShinghal “A Hybrid Classifier for Recognizing Handwritten Numerals”,
ICDAR pp 283, 1997.
[6] Dan ClaudiuCires¸an and Ueli Meier and Luca Maria Gambardella and JurgenSchmidhuber, “Convolutional
Neural Network Committees for Handwritten Character Classification”, 2011 International Conference on Document Analysis and Recognition, IEEE, 2011.
[7] GeorgiosVamvakas, Basilis Gatos, Stavros J. Perantonis, “Handwritten character recognition through two-stage
foreground sub-sampling” ,Pattern Recognition, Volume 43, Issue 8, August 2010.
[8] Devlin, Jacob, "Statistical Machine Translation as a Language Model for Handwriting Recognition." Frontiers in Handwriting Recognition (ICFHR), 2012 International Conference on. IEEE, 2012.
[9] Al-Khaffaf, Hasan SM, et al. "On the performance of Decapod's digital font reconstruction." Pattern Recognition (ICPR), 2012 21st International Conference on. IEEE, 2012.
[10] Rhead, Mke, "Accuracy of automatic number plate recognition (ANPR) and real world UK number plate problems." Security Technology (ICCST), 2012 IEEE International Carnahan Conference on. IEEE, 2012.
[11] MAJIDA ALI ABED HAMID ALI ABED ALASADI Simplifying Handwritten Characters Recognition Using a
Particle Swarm Optimization Approach EUROPEAN ACADEMIC RESEARCH, VOL. I, ISSUE 5/ AUGUST 2013 ISSN 2286-4822
[12] Mohammed Z. Khedher, Gheith A. Abandah, and Ahmed M. Al-Khawaldeh Optimizing Feature Selection for
Recognizing Handwritten Arabic Characters PROCEEDINGS OF WORLD ACADEMY OF SCIENCE, ENGINEERING AND TECHNOLOGY VOLUME 4 FEBRUARY 2005 ISSN 1307-6884
[13] Amir BahadorBayat Recognition of Handwritten Digits Using Optimized Adaptive Neuro-Fuzzy Inference
Systems and Effective Features Journal of Pattern Recognition and Intelligent Systems Aug. 2013, Vol. 1