An Efficient Modified K-Means Algorithm To
Cluster Large Data-set In Data Mining
Anwiti Jain Anand Rajavat Rupali Bhartiya Department of CSE Department of CSE Department of CSE
SVITS,Indore,M.P.,India SVITS,Indore,M.P.,India SVITS,Indore,M.P.,India
Abstract:-Data Mining is the process of extracting hidden and interesting patterns or characteristics from very large datasets and using it in decision making and prediction of future behavior. Clustering is such one of the functionality of data mining. Clustering is the task of segmenting a diverse group into a number of more similar subgroups, or the process of grouping a set of physical or abstract objects into classes of similar objects is called clustering. A cluster is a collection of data objects that are similar to one another within the same cluster and are dissimilar to the objects in other cluster. we proposed an efficient modified K-mean clustering algorithm to cluster large data-sets whose objective is to find out the cluster centers which are very close to the final solution for each iterative steps. Clustering is often done as a prelude to some other form of data mining or modeling. A analysis is performed with the K-Mean and K-Medoid clustering algorithms and the best algorithm in each category was found out based on their performance. The experimental results using the proposed algorithm with a group of randomly constructed data- sets are very promising.
Keywords: Data Mining, Clustering, k-means .
I. INTRODUCTION
Clustering divides a database into different groups [2]. The goal of clustering is to find groups that are very different from each other, and whose members are very similar to each other [13]. Unlike classification you don't know what the clusters will be when you start, or by which attributes the data will be clustered. Consequently, someone who is knowledgeable in the business must interpret the clusters [7]. Often it is necessary to modify the clustering by excluding variables that have been employed to group instances, because upon examination the user identifies them as irrelevant or not meaningful [4]. After you have found clusters that reasonably segment your database, these clusters may then be used to classify new data. Some of the common algorithms used to perform clustering include Kohonen feature maps and K-means [23]. Don't confuse clustering with segmentation. Segmentation refers to the general problem of identifying groups that have common characteristics [22]. Clustering is a way to segment data into groups that are not previously defined, whereas classification is a way to segment data by assigning it to groups that are already defined.
Cluster analysis divides data into meaningful or useful groups (clusters) [1]. As a data mining function cluster analysis can be used as a stand alone tool to gain insight into the distribution of data, to observe the characteristics of each cluster, and to focus on a particular set of clusters for further analysis [15]. For example, cluster analysis has been used to group patients having similar diagnosis, grouping of spatial locations prone to earthquakes, grouping books according to topics. Alternatively, it may serve as a preprocessing step for other algorithm, such as characterization and classification, data compression, which would operate on the detected clusters [11]. Clustering is an intriguing and intersecting topic in many research fields which include data mining, statistics, machine learning, pattern reorganization, spatial database technology, biology and marketing [9].
Clustering is the process of dividing data into group of objects/ items with the goal of maximizing intracluster similarity and minimizing intercluster similarity [5]. The greater similarity within a group and the greater difference between the groups, the better is the clustering. Partitioning of data into clusters can be hard or soft.
Fig: 1 clusters
II. CLUSTERING ALGORITHMS
The most well-known and commonly used partitioning methods are K-means, K-medoids and their variations.
A . K-mean algorithm :
1 Place K points into the space represented by the objects that are being clustered. These points represent initial group centroids.
2 Assign each object to the group that has the closest centroid.
3 When all objects have been assigned, recalculate the positions of the K centroids.
4 Repeat Steps 2 and 3 until the centroids no longer move. This produces a separation of the objects into groups from which the metric to be minimized can be calculated.
B. K-Medoids algorithm :
Input:
K: The number of clusters D: A data set containing n objects
Output: A set of k clusters that minimizes the sum of the dissimilarities of all the objects to their nearest medoid.
Method: Arbitrarily choose k objects in D as the initial representative objects;
Repeat:
1. Assign each remaining object to the cluster with the nearest medoid;
2. Randomly select a non medoid object Orandom; 3. Compute the total points S of swap point Oj with Oramdom
4. if S < 0 then swap Oj with Orandom to form the new set of k medoid
Until no change;
III. MODIFIED K-MEAN ALGORITHM
A . Modified K-mean algorithm:
The K-mean algorithm is a popular clustering algorithm and has its application in data mining ,image segmentation, bioinformatics and many other fields[14].This algorithm works well with small datasets.In this paper we proposed an algorithm that works well with large datasets. Modified k-mean algorithm avoids getting into locally optimal solution in some degree, and reduces the adoption of cluster -error criterion.
Algorithm: Modified K-means(S, k), S={x1,x2,…,xn }
Input: The number of clusters k1( k1> k ) and a dataset containing n objects(Xij+).
Output: A set of k clusters (Cij ) that minimize the Cluster - error criterion.
ALGORITHM
1. Compute the distance between each data point and all other data- points in the set D
2. Find the closest pair of data points from the set D and form a data-point set Am (1<= p <= k) which contains these two data- points, Delete these two data points from the set D
3. Find the data point in D that is closest to the data point set Ap, Add it to Ap and delete it from D 4. Repeat step 4 until the number of data points in
Am reaches (n/k)
5. If p<k, then p = p+1, find another pair of data points from D between which the distance is the shortest, form another data-point set Ap and delete them from D, Go to step 4
SUB ALGORITHMS
Algorithm 1
For each data-point set Am (1<=p<=k) find the arithmetic mean of the vectors of data points Cp(1<=p<=k) in Ap.
Select nearest object of each Cp(1<=p<=k) as initial centroid.
Compute the distance of each data-point di (1<=i<=n) to all the centroids cj (1<=j<=k) as d(di, cj)
For each data-point di, find the closest centroid cj and assign di to cluster j Set ClusterId[i]=j; // j:Id of the
closest cluster
Set Nearest_Dist[i]= d(di, cj)
For each cluster j (1<=j<=k), recalculate the centroids
Repeat Algorithm 2
1. For each data-point di
Compute its distance from the centroid of the present nearest cluster If this distance is less than or equal to
the present nearest distance, the data-point stays in the cluster
Else ;
For every centroid cj (1<=j<=k) Compute the distance (di, cj); Endfor
Set ClusterId[i] =j
Set Nearest_Dist[i] = d (di, cj); Endfor
2. For each cluster j (1<=j<=k), recalculate the centroids; until the convergence Criteria is met.
IV. EXPERIMENTAL RESULTS AND ANALYSIS
All the experiments are performed on a 2-GHz Pentium PC machine with 512 megabytes main memory, running on Microsoft Windows/NT. All the programs are written in Microsoft Visual studio .net(C# 7.0). Notice that we do not directly compare our absolute number of runtime with those in some published reports running on the RISC workstations because different machine architectures may differ greatly on the absolute runtime for the same algorithms. Instead, we implement their algorithms to the best of our knowledge based on the published reports on the same machine and compare in the same running environment. Please also note that run time used here means the total execution time, that is, the period between input and output, instead of CPU time measured in the experiments in some literature.
We feel that run time is a more comprehensive measure since it takes the total running time consumed as the measure of cost, whereas CPU time considers only the cost of the CPU resource.
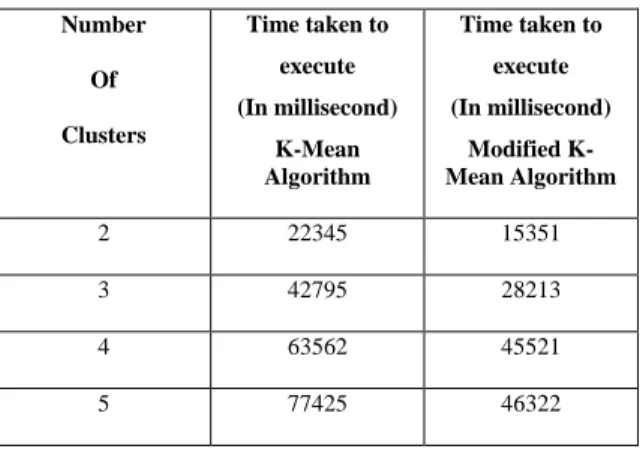
In this Paper, the most representative algorithms K-Means, and proposed algorithm Modified K-Mean were examined and analyzed based on their basic approach for large data set, using student class dataset. The best algorithm in each category will found out based on their performance. Comparison between K-Means, and Modified K-Mean algorithm with Number of Clusters and Execution Time (in milliseconds) is shown in the table.
TABLE I: K-MEAN AND MODIFIED K-MEAN PERFORMANCE
Number
Of
Clusters
Time taken to
execute
(In millisecond)
K-Mean Algorithm
Time taken to
execute
(In millisecond)
Modified K-Mean Algorithm
2 22345 15351
3 42795 28213
4 63562 45521
5 77425 46322
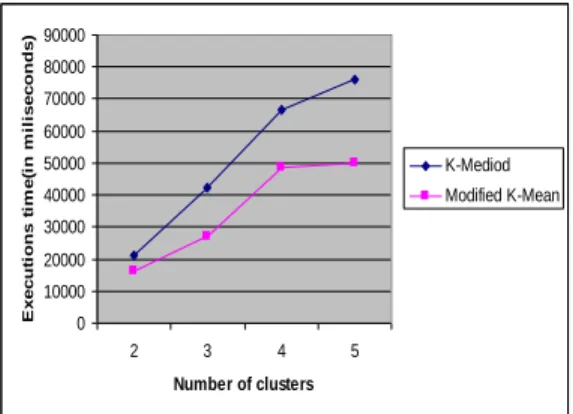
Graph shows the comparison between K-mean and Modified K-mean algorithm on the basis of various number of clusters and execution time using this algorithm.
Modified K-mean gives better performance in comparison to standard K-means algorithm.
Fig. 2: K-Mean and Modified k-mean Algorithm
Comparison between K-Mean, and K-Medoid algorithm with Number of clusters and Execution Time (in milliseconds) is shown in the table.
TABLE II: K-MEDOID AND MODIFIED K-MEAN PERFORMANCE
Number
Of
Clusters
Time taken to
execute
(In millisecond)
K-Medoid Algorithm
Time taken to
execute
(In millisecond)
Modified K-Mean Algorithm
2 21028 16342
3 42125 26923
4 66415 48532
5 76221 49921
Graph shows the comparison between K-medoid and Modified K-mean algorithm on the basis of various number of clusters and execution time. Modified K-Mean gives better performance in comparison to K-Medoid algorithm .
0 10000 20000 30000 40000 50000 60000 70000 80000 90000
2 3 4 5
Number of clusters
E
x
e
c
ut
ion
t
im
e
(
in
m
il
is
e
c
on
ds
)
K-Mean Algorithm
Fig.3 : k-Medoid and Modified k-mean Algorithm
Now we perform Comparison between K-Mean, K-Medoid and Modified K-Mean algorithms with number of clusters and execution time(in milliseconds) is shown in the table.
TABLE IV: K-MEAN, K-MEDOID AND MODIFIED K-MEAN PERFORMANCE
Number
of
Records
Time taken to
execute
(In
milliseconds)
K-Mean Algorithm
Time taken to
execute
(In
milliseconds)
K-Medoid Algorithm
Time taken to
execute (In milliseconds) Modified K- Mean Algorithm 2
22365 20622 17321
3 42301 42281 25915
4
67812 64536 47572
5
75343 72391 48343
Graph shows the comparison between K-mean, K-medoid and Modified K-mean algorithm on the basis of various number of clusters and execution time.. Modified K-Mean gives better performance in comparison to both the standard K-means and K-medoids algorithm .
Fig. 4: K-Mean, k-Medoid and Modified K-mean Algorithm
V. CONCLUSION
From the experimental results, it is observed that the comparison between K-means and Modified K-mean algorithm for various number of clusters, shows that proposed algorithm takes less time to execute than existing algorithm.
REFERENCES
[1] R. Agrawal , J. Gehrke , D. Gunopulos, and P. Raghavan, “Automatic Subspace Clustering of High Dimensional Data for Data Mining
Applications,” Proc.ACM SIGMOD Int. Conf. on Management of WA, 1998, pp. 94-105.
[2] M R. Anderberg Cluster Analysis for Applications, Academic Press, 1973.
[3] M. Ankerst , M. Breunig , H.P. Kriegel , and J. Sander, “ OPTICS: Ordering Points to Identify the Clustering Structure,” Proc. ACM SIGMOD Int. Con. Management of Data Mining, 1999, pp. 49-60. [4] L. Bottou, and Y. Bengio, “Convergence properties of the k- mean algorithm,” The MIT press, Cambridge, MA, 1995, pp. 585-592.
[5] P. S. Bradley , and U. M. Fayyad, “ Refining I nitial Points f or k-meanClustering,” Proc. of the 15th International Conference on
Machine Learning (ICML98), J.Shavlik (ed.).Morgan Kaufmann .
[6] S. Deelers, and S. Auwatanamongkol, “ Enhancing K- Means Algorithm with Initial Cluster Centers Derived from Data Partitioning Along the Data Axis with the Highest Variance,” PWASET vol 26,
2007, pp. 323-328.
[7] R.O. Duda , and P.E. Hart, Pattern Classification and Scene Analysis. John Wiley Sons, New York, 1973.
[8] M. Ester, H . P. Kriegel, J. Sander, and X. Xu, “ A Density - based Algorithm for Discovering Clusters in Large Spatial Databases with
Noise” Proc. 2nd Int. Conf. on Knowledge Discovery and Data AAAI Press, Portland, 1996, pp.226-231.
[9] A. M. Fahim, A. M. Salem ,F. A. Torkey, and M. Ramadan, “ An efficient enhanced k-means clustering algorithm,” Journal of Zhejiang University SCIENCE A, vol 7(10), 2006, pp. 1626-1633.
[10] U.M. Fayyad , G. Piatetsky-Shapiro , P. Smyth , and R. Uthurusamy
Advances in Knowledge Discovery and Data Mining, AAAI/ MIT 0 10000 20000 30000 40000 50000 60000 70000 80000 90000
2 3 4 5
Number of clusters
E x e c ut ion s t im e (i n m il is e c on ds ) K-Mediod Modified K-Mean 0 10000 20000 30000 40000 50000 60000 70000 80000
2 3 4 5
Number of clusters
e x e c ut ion t im e (i n m il is e c on ds ) K-Mean Algorithm K-Mediod Algorithm
Press,1996.
[11] A. Gersho, a nd R. M. Gray Vector Quantization and Signal Compression, Kluwer Academic, Boston, 1992.
[12] S. Guha , R. Rastogi, and K. Shim, “CURE: An Efficient Clustering Algorithms for Large Databases,” Proc. ACM SIGMOD Int. Conf. on Management of Data, Seattle, WA, 1998, pp. 73-84.
[13] V. Hautamaeki , S. Cherednichenko , I. Kaerkkaeinen , T. Kinnunen, And P. Fraenti, “Improving K-Means by Outlier Removal,” SCIA 2005,LNCS 3540, 2005, pp. 978-987.
[14] V. Hautamaeki , I. Kaerkkaeinen, and P. Fraenti, “ Outlier detection using k-nearest neighbourgraph,” In: 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, United Kingdom. [15] A. Hinneburg, and D. Keim, “An Efficient Approach to Clustering in Large Multimedia Databases with Noise,” Proc. 4th Int. Conf. on Knowledge Discovery and Data Mining, New York City, NY. 1998.
[16] Z. Huang, “ A fast clustering algorithm to cluster very large Categorical data sets in data mining,” Proceedings of the SIGMOD Workshop on Research Issues o n Data Mining and Knowledge Discovery, Dept. of Computer Science, The University of British Columbia, Canada, 1997,pp. 1-8.
[17] A. K. Jain, and R . C. Dubes, Algorithms for Clustering Data, PrenticeHall, 1988.
[18] L. Kaufman, a nd P. Rousseeuw, “ Finding Groups in Data: An Introduction to Cluster Analysis,” Wiley, 1990.
[19] J.B. MacQueen, “ Some methods for classification and analysis of multivariate observations. Proc. 5th Symp. Mathematical Statistics and Probability, Berkelely, CA, Vol(1), 1967, pp. 281297.
[20] R.T. Ng, and J. Han, “Efficient and Effective Clustering Methods for Spatial Data Mining,” Proc. 20th Int. Conf. on Very Large Data Bases,Morgan Kaufmann Publishers, San Francisco, CA, 1994,
[21] D. T. Pham , S. S. Dimov, and C. D. Nguyen, “Selection of k in K- Means clustering,” Mechanical Engineering Science, vol(219), 2004. [22] S. Ray, and R. H. Turi, “ Determination of number of clusters in k- mean clustering and application in colour image segmentation,” In Proceedings of the 4th International Conference on Advances in Pattern Recognition and Digital Techniques, 1999, pp.137-143. [23] G. Sheikholeslami, S. Chatterjee, and A. Zhang, “ Wave-Cluster: A Multi - Resolution Clustering Approach for Very L arge Spatial Databases,” Proc. 24th Int. Conf. on Very Large Data Bases. New York,1998, pp. 428-439
[24] R. Sibson, “SLINK: an optimally e fficient algorithm for the single- linkcluster method,” The Comp. Journal, 16(1), 1973, pp. 30-34.