ABSTRACT
BAKER, JAMES DANIEL. Short-Term Memory for Instruction Sequences: Effects of Event Segmentation and Enactment. (Under the direction of Dr. Douglas J. Gillan).
Recent studies of event cognition have revealed pros and cons of displaying information in ways that trigger hypothetical event segmentation and/or action memory mechanisms. Such studies may be of interest to designers of instructional software user-interfaces. The present study employed a set of software-based memory games, which measured the user’s short-term memory for sequences of instructions. The games were designed to manipulate event segmentation by varying the number of windows in which the instruction sequences appeared, and they were designed to tap action memory via
manipulations of both the format of individual instructions and the format of immediate serial recall tasks. The experiment followed a 2×2×2 within-subjects design. Participants (N = 62) received sequences of instructions in the form of simple action-object pairs (e.g., save the ring, lift the wedge, etc.). The instruction sequences were presented either as typed phrases or as animated demonstrations, and these appeared within either one or two computer windows. Participants completed either a verbal or an enactment serial recall task. The verbal recall task required participants to match each action word (e.g., “save”) with its appropriate object word (e.g., “ring”). The enactment recall task required participants to perform each action upon its appropriate object (e.g., by dragging a ring icon to a save icon). Analyses did not find reliable effects of the window count manipulation, failing to support the event segmentation hypothesis. The results partially supported the action memory hypothesis, and they unexpectedly supported the encoding specificity hypothesis.
Short-Term Memory for Instruction Sequences: Effects of Event Segmentation and Enactment
by
James Daniel Baker
A dissertation submitted to the Faculty of North Carolina State University
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy
Psychology
Raleigh, North Carolina 2019
APPROVED BY:
Dr. Douglas J. Gillan Dr. Jing Feng
Chair of Advisory Committee
DEDICATION
For anybody who reads it…
Stay Positive and Love Your Life
BIOGRAPHY
James Daniel Baker grew up in Weirton, West Virginia. After graduating from Brooke High School in 2002, he attended West Virginia University. He graduated cum laude in 2007, earning Bachelor of Science degrees in Computer Science and Psychology. His interest in those fields led him to pursue a graduate degree in Human Factors and Applied Cognition – a Psychology program at North Carolina State University. To bring three decades of
ACKNOWLEDGEMENTS
For feeding my obsession with learning, I owe every teacher and professor who passed their knowledge and wisdom onto me within the last thirty years. “If I have seen further, it is by standing upon the shoulders of giants.”
For making sure that I submitted all the right forms, that I scheduled all the right things, and that I had a place to sit and complain, I owe my foster parents in Poe 640. Is it too late to change my concentration?
For paying me money to fix the stuff and things, and for tolerating my personality these last four years, I owe my coworkers in Poe 412. If you are reading this, I have the unfortunate duty of informing you that you are fired.
For keeping me company when I was working alone in my apartment on so many nights, I owe numerous live gaming streamers, ASMRtists, and their amazing communities. What’s your favourite brand of laundry detergent?
For keeping me afloat during my times of hopelessness, I owe my family and closest friends. I give special thanks to Mom and to the Ecks. The worst pains of my life were bearable because of you.
TABLE OF CONTENTS
LIST OF TABLES ... vi
LIST OF FIGURES ... vii
INTRODUCTION ...1
Background Research: Improving and Impairing Memory via Event Segmentation ...1
Background Research: Benefits of Encoding Action Information ...7
The Present Experiment: Overview and Hypotheses ...11
METHOD ...13
Design ...13
Participants ...14
Apparatus ...14
Memory Games: Stimuli and Responses ...14
General Procedure ...19
RESULTS ...21
Univariate Tests of Hypothesis H1 ...23
Univariate Tests of Hypothesis H2 ...24
Univariate Tests of Hypothesis H3 ...27
DISCUSSION ...28
CONCLUSION ...41
REFERENCES ...42
APPENDICES ...48
Appendix A: Words and Icons for Actions and Objects ...49
Appendix B: Example Draggable Items, Drag-Handles, and Hand-Cursors ...50
Appendix C: Computer Windows for Input Sequences ...51
Appendix D: Illustration of a Text-Input Sequence ...52
Appendix E: Illustration of a Demo-Input Sequence ...55
Appendix F: Illustration of a Verbal Output Task ...58
Appendix G: Illustration of an Enactment Output Task ...61
Appendix H: Results of Additional Univariate Analyses of Variance ...64
LIST OF TABLES
Table 1. Results of Multivariate Analysis of Variance ...22
Table 2. Results of Univariate Analysis of Variance – Serial Recall of Pairs...22
Table 3. Effect of Sequence Segment across the Four Input/Output Conditions ...27
Table 4. Encoding Strategies Used within the Four Memory Games ...33
Table H1. Results of Univariate Analysis of Variance – Serial Recall of Actions ...64
Table H2. Results of Univariate Analysis of Variance – Serial Recall of Objects ...65
LIST OF FIGURES
Figure 1. Interaction of Window Count and Sequence Segment ...23
Figure 2. Main Effects of Input Format and Output Format...24
Figure 3. Interaction of Input Format and Output Format ...25
Figure 4. Interaction of Input Format, Output Format, and Sequence Segment ...26
Figure 5. Example Motion Path – Type I ...35
Figure 6. Example Motion Path – Type II ...35
Figure 7. Stimulus Configuration from a Past Experiment...37
Figure A1. Words and Icons for Actions and Objects. ...49
Figure B1. Example Draggable Items, Drag-Handles, and Hand-Cursors ...50
Figure C1. Computer Windows for Input Sequences ...51
Figure D1. Illustration of a Text-Input Sequence ...52
Figure D2. Illustration of a Text-Input Sequence (Continued) ...53
Figure D3. Illustration of a Text-Input Sequence (Continued) ...54
Figure E1. Illustration of a Demo-Input Sequence ...55
Figure E2. Illustration of a Demo-Input Sequence (Continued) ...56
Figure E3. Illustration of a Demo-Input Sequence (Continued) ...57
Figure F1. Illustration of a Verbal Output Task ...58
Figure F2. Illustration of a Verbal Output Task (Continued) ...59
Figure F3. Illustration of a Verbal Output Task (Continued) ...60
Figure G1. Illustration of an Enactment Output Task ...61
Figure G2. Illustration of an Enactment Output Task ...62
Figure G3. Illustration of an Enactment Output Task ...63
Figure I1. Congruency Effects in Different Measures of Recall (Serial-Actions) ...67
INTRODUCTION
Research on event perception and cognition underwent a period of theory-building just after the start of the 21st century (e.g., Zacks, Speer, Swallow, Braver, & Reynolds, 2007; Zack & Tversky, 2001). In response to these new theoretical perspectives, researchers have begun examining various areas of application, including the area of instructional design (e.g., Mura, Petersen, Huff, & Ghose, 2013; van der Meij, & van der Meij, 2013; Zacks & Tversky, 2003). The present study focused more specifically on some potential implications for the design of user-interfaces for instructional software.
The present study included a memory experiment designed to test hypotheses that have emerged within two distinct lines of research related to episodic memory. The first part of the following literature review examines the line of research regarding event segmentation, and the second part of the literature review examines the line of research regarding action memory. Each line of research has produced implications for the design of instructional software. To further examine these implications, the present experiment integrated the methodologies of recent studies from within the separate lines of research.
Background Research: Improving and Impairing Memory via Event Segmentation
The first relevant line of research traces back to studies on environment-dependent memory (e.g., Bilodeau & Schlosberg, 1951; Greenspoon & Ranyard, 1957; Smith, 1982). Within those past studies, participants attempted to memorize multiple lists of words. Either they learned all of the lists within one room, or they walked among multiple rooms, learning one list per room. Participants were later able to recall more list items if learning had
occurs when the learning environments contain contextual information that participants either automatically or strategically learn alongside the word lists. Retrieval of the learning context can then serve as a trigger of retrieval of the associated list items. Accordingly, compared to a single learning environment, multiple learning environments offer a greater number of contextual retrieval triggers, increasing the chances of successful recall. Strand (1970), however, had found a similar memory improvement by requiring participants to learn one list, leave the room, and then return to the same room to learn the second list, suggesting that mere “psychological disruption” (p. 205), rather than contextual association, is responsible for the memory improvement effect. She hypothesized that the disruption can cause the second list to be more discriminable from the first list, reducing retroactive interference and potentially preventing proactive interference.
Pettijohn, Thompson, Tamplin, Krawietz, and Radvansky (2016) recently conducted four experiments with the goal of replicating, extending, and reinterpreting those past studies of environment-dependent memory. Their participants attempted to remember lists of nouns (Experiments 1 and 2) and short narratives containing ten to fourteen sentences (Experiments 3 and 4). Across the four experiments, the researchers employed different methods of
manipulating the segmentation of the lists and narratives. In the first experiment, during an inter-list interval, participants either walked through a doorway connecting two small rooms, or they walked across one large room. In the second experiment, either the two lists
segmentation on recall performance. With their first experiment, in which participants traveled among learning contexts, the researchers primarily replicated the methods and results of the past studies on environment-dependent memory (e.g., Smith 1982; Strand, 1970). With their three additional experiments, however, they found similar memory
improvement effects by using innovative methods, none of which required the participants to move among different environmental contexts. Consequently, the researchers justified a reinterpretation of the memory improvement effect, believing it to be partly the result of event segmentation.
According to Event Segmentation Theory (Zacks, Speer, Swallow, Braver, &
Reynolds, 2007), the process of event segmentation transforms continuous sensory input into sets of events, which are perceptually discrete representations bounded by temporal
beginnings and ends (Zacks & Tversky, 2001). Within a given perceptual modality (e.g., vision), event perception results in hierarchically structured event representations. That is, an event typically consists of a sequence of shorter subevents, and the event itself may be part of a sequence making up a longer event. For example, a complete pass in a football game may consist of throw and catch subevents, and the complete pass itself may be part of a longer flea flicker play, which consists of a carry and two complete passes. An observer may construct a visual hierarchy of this flea flicker play, while simultaneously constructing an auditory hierarchy that contains the sounds of player collisions, crowd cheers, and
Pettijohn et al. (2016) hypothesized that their experimental conditions triggered greater degrees of subjective event segmentation than did their comparison conditions. For example, consider their first experiment. During the inter-list interval, either the participants walked through a doorway from one small room to another small room, or they walked across one large room. In both cases, the complete walk from one point to another may have been perceived as an event. Compared to the one-room condition, in the two-room condition, the walk’s whole event representation may have been more likely to be further segmented into two subevent representations, with one subevent containing the pre-doorway information and the other subevent containing the post-doorway information. The researchers concluded that the additional segmentation led to a decrease in inter-list interference during later
retrieval, because the information about the two lists was stored in two different event representations. Note that this idea resonates well with Miller’s (1956) notion of chunking.
Though Pettijohn et al. (2016) found that event segmentation may lead to memory improvement, several related studies have produced a complementary finding, in which event segmentation may have caused memory impairment (e.g., Pettijohn & Radvansky, 2016a, 2016b; Radvansky & Copeland, 2006; Radvansky, Krawietz, & Tamplin, 2011; Radvansky, Pettijohn, & Kim, 2015; Radvansky, Tamplin, & Krawietz, 2010). In those studies,
condition, the memory probe appeared just after participants passed through the doorway into the second room. Across these studies, participants were more likely to forget an object’s identity when walking between two small rooms than when walking across one long room. The researchers hypothesized that walking through a doorway from one room to another served as a trigger for subjective event segmentation. In the two-room condition, when a participant carried the object through the doorway, information about the object may have been stored both in the pre-doorway subevent representation and in the post-doorway subevent representation. During the memory probe, when the participant attempted to retrieve information about the object, the two subevent representations competed and
interfered with one another, degrading recall performance relative to the one-room condition, in which the object’s information would have been stored in a single, unsegmented event representation.
In their Event Horizon Model of event segmentation, Gabriel Radvansky and colleagues have used these complementary findings as support for two generalizable
For their second experiment, Pettijohn et al. (2016) measured memory for lists of twelve nouns, which appeared on a computer display at a rate of one word per second. In half of the trials, all twelve nouns appeared within a single computer window, and in the other half of the trials, two sets of six nouns appeared within two separate computer windows. Within the two-window trials, an initial window closed after displaying the first six nouns, and then a second window opened to display the second six nouns. Within the one-window trials, the initial window displayed all twelve nouns, but there was a one-second pause between displays of the sixth and seventh nouns. In all trials, following a two-minute distractor task, participants typed as many of the twelve nouns that they could freely recall. The researchers’ analyses revealed a significant main effect of the window-segmentation manipulation (ηp2 = .21). Average accuracy of free recall within the two-window condition
(M = .37, SE = .03) was approximately 3% greater than within the one-window condition (M = .34, SE = .03). Drawing from the Event Horizon Model, the researchers hypothesized that transitioning from one computer window to a second may have triggered subjective event segmentation. Because the two halves of the sequence were displayed within separate computer windows, the two sets of item information were stored in separate subevent
In summary, Pettijohn et al. (2016, Exp. 2) showed that a simple method of manipulating computer windows could influence memory for sequences of nouns. Their finding may be useful to designers of a variety of software applications, such as electronic flashcards. However, for designers who may be especially interested in enhancing
instructional software, stronger implications would arise from a task that requires participants to remember sequences of instructions. The present experiment tested for window count effects within two versions of that type of task. In one version, participants verbally recalled the instruction sequences. In the other version, participants enacted the instructions, such that the task served a similar function as that of instructional software. A distinct line of research has led to recent experiments that have included those precise task conditions among several others. The present experiment’s design drew heavily upon the methodology from that line of research, allowing for the testing of hypotheses beyond those offered by Pettijohn et al.
Background Research: Benefits of Encoding Action Information
instruction sequence without performing the actions. For the other comparison, the experimenter performed each action (experimenter-performed task, or EPT), while the participant listened and observed. For all four conditions, participants completed immediate and 10-minute-delayed verbal recall tasks, in which they wrote down as many words or action phrases as they could remember. The SPT and EPT conditions produced similar recall accuracy scores, and both of those conditions produced significantly greater scores than the condition in which participants merely listened to instructions. Based on subjective reports and the results of additional experiments, Cohen (1981, 1983) found that participants were less likely to engage in controlled encoding strategies (e.g., rehearsal) within the SPT and EPT input conditions than in the purely verbal input condition. He hypothesized that the former conditions allowed participants to benefit from a more highly automatic encoding mechanism.
equal accuracy within the verbal (invalidly-cued) task and the enactment (validly-cued) task. On the other hand, when cued to expect the verbal task, participants recalled instructions with greater accuracy via the verbal (validly-cued) task than via the enactment (invalidly-cued) task. In their third experiment, the researchers extended those findings to a delayed free recall task.
Via subjective reports, the Koriat et al. (1990) learned that their participants were engaging in different encoding strategies in preparation for the different recall task formats. The participants more often engaged in verbal rehearsal in preparation for the verbal recall task, and they more often engaged in some form of imaginal enactment in preparation for the enactment recall task. The researchers hypothesized that the latter strategy may have been beneficial for both the verbal and the enactment recall tasks, because it produced additional memory representations (perhaps visual and/or motoric) beyond a purely verbal
representation. Zimmer and Engelkamp (1989) had recently defended this multi-code model as an explanation for the memory advantage produced by the SPT input condition in Cohen’s (1981, 1983) experiments. When expecting an enactment recall task, participants in the experiment by Koriat et al. (1990) may have taken strategic control of the same encoding mechanisms that had functioned with high automaticity for participants within Cohen’s SPT and EPT input conditions. However, Goschke and Kuhl (1993) later showed that to-be-performed actions may benefit from an automatic persistence in prospective memory, even when participants cannot engage in memorization strategies.
Participants attempted to remember sequences of five instructions. During encoding, the participants listened to and enacted each instruction, or they merely listened to the
instructions. For immediate recall tasks, the participants enacted the instruction sequences, or they verbally recited them. The results were consistent with those of both Cohen and Koriat et al. Between the two input conditions, enactment of auditory-verbal instructions led to better recall than did merely listening to instructions, and between the two output
conditions, enacted recall was superior to that of verbal recall. However, the benefit of enactment during encoding was limited to the verbal recall task. That is, the benefits of enactment during encoding and during recall were not additive.
Yang, Allen, Yu, and Chan (2015, Exp. 1) found similar results when substituting the enactment input condition with a demonstration input condition. For both verbal and
enactment recall tasks, experimenter-demonstrated instructions led to better recall than either spoken or written instructions, but the benefit of demonstrations during encoding was not additive with the benefit of enactment during recall. Most recently, when testing children, Waterman et al. (2017) replicated those two sets of findings (i.e., Allen & Waterman, 2015; Yang et al., 2015). Like their predecessors (e.g., Koriat et al.), all of these researchers have hypothesized that their participants benefited from a special confluence of memory
representations generated during the input/encoding of actions, be they demonstrated, performed, or anticipated. This action memory hypothesis is further supported by recent evidence of a motor storage component of working memory (Jaroslawska, Gathercole, & Holmes, 2018). Because the present experiment resembled those conducted by these
The Present Experiment: Overview and Hypotheses
In summary, as part of their recent study on event segmentation, Pettijohn et al. (2016, Exp. 2) examined memory for sequences of nouns, and they produced a retrieval advantage by displaying the sequences in two computer windows rather than in one. The primary goal of the present experiment was to test whether a similar manipulation would influence memory within an instruction-following task, which would provide clearer implications for the design of instructional software. Other researchers have recently published several studies on action memory for sequences of to-be-followed instructions of various formats (e.g., Yang et al., 2015), offering a convenient methodological toolbox for the design of the present experiment. Thus, the present experiment’s design became a cross between those of the two distinct (but related) lines of research.
Hypothesis H1. Pettijohn et al. (2016) hypothesized that their two-window condition triggered a greater degree of event segmentation than did their one-window condition. In their two-window condition, the first and second halves of the input sequence were confined to the first and second computer windows, respectively. The researchers hypothesized that this condition confined the two halves to separate subevent representations, reducing the degree of later retrieval interference relative to the one-window condition. In the present experiment’s two-window condition, the first half of the input sequence appeared in each of the two computer windows. For this scenario, the Event Horizon Model predicted a greater degree of retrieval interference in the two-window condition than in the one-window
condition. Thus, that model predicted lower recall accuracy within the two-window condition.
Hypothesis H2. In studies conducted by Waterman et al. (2017, Exp. 2a) and by Yang et al. (2015), action demonstrations led to better recall than did purely verbal
interactions between input and output conditions. However, Yang et al. hypothesized that demo-input and enactment-output may not be additively beneficial, because they recruit a common underlying action memory mechanism. That hypothesis predicted an interaction between the input and output formats. The benefit of demonstrated instructions over typed instructions was expected to be of greater magnitude for verbal recall than for enactment recall. Likewise, the benefit of enactment recall over verbal recall was expected to be of greater magnitude following typed instructions than following demonstrated instructions.
Hypothesis H3. Taken together, the event segmentation and action memory hypotheses gave rise to a third. If viewing demonstrations and planning for future actions produce a higher quantity of representations than do purely verbal tasks, and if event segmentation can operate on multiple representations in parallel, then the effect of event segmentation may be greater in action-oriented tasks than in purely verbal tasks. This hypothesis predicted a smaller window count effect within the one purely verbal task than within the three tasks that included either demo-input or enactment-output.
METHOD
Design
The primary manipulations followed a 2×2×2 completely within-subjects factorial design. For the input format (2) manipulation, instruction sequences appeared as either typed phrases or as demonstrations. For the window count (2) manipulation, either one computer window displayed an entire instruction sequence, or, halfway through a sequence, the initial computer window appeared to transition to a second computer window, which then displayed the remainder of the sequence. For the output format (2) manipulation, participants
Participants
The sample consisted of 62 undergraduate students attending North Carolina State University. The participants were required to be at least 18 years of age and have normal or corrected-to-normal vision. Their ages ranged from 18 to 30 years, and the sample’s median age was 19. For joining the study, participants received credits toward a
research-participation assignment within their introductory psychology course. Apparatus
All tasks and data collection were controlled by software installed on modern PCs within a 24-seat computer classroom. The task software was a Windows 10 PC app developed using the Unity (2017) game engine. The PCs displayed visual stimuli via 22-inch, wide-panel, LCD monitors. Graphics displayed at a resolution of 1920×1080p and at a framerate of 60 frames per second. Participants provided all responses via standard
keyboards and mice.
Memory Games: Stimuli and Responses
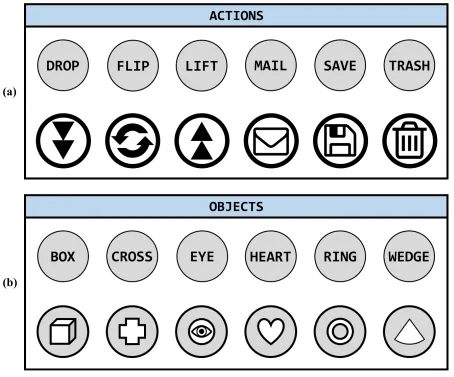
Action-object pairs. A set of 36 instructions were formed by crossing six
actions/verbs (drop, flip, lift, mail, save, and trash) with six objects/nouns (box, cross, eye, heart, ring, and wedge). The set was initially derived by merging the simpler actions and objects used by Allen and Waterman (2015) with a somewhat more complex
Third, the action and object words began with unique phonemes, such that they might be more distinguishable in their phonological form (see Baddely, 1966). Appendix A shows the actions and objects in their typed and iconic formats.
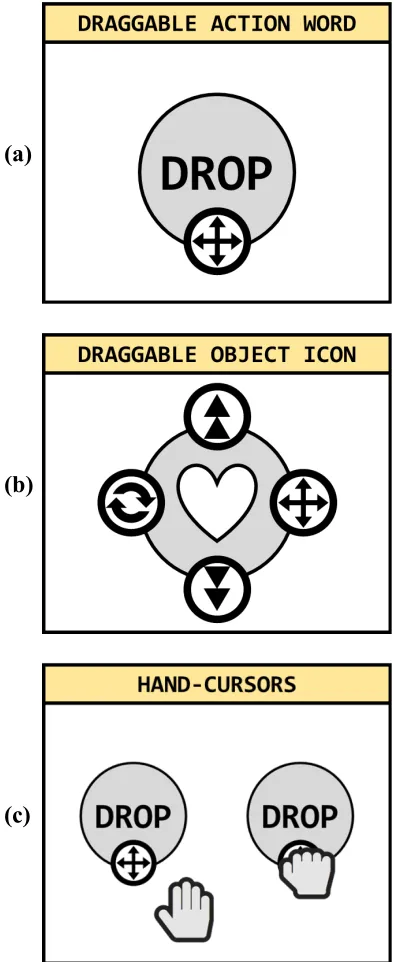
Draggable items and drag-handles. In the recall tasks, participants provided responses via a drag-and-drop user interface, using the mouse/cursor to move items among cells of a game grid. In both the verbal and the enactment output tasks, the draggable items had iconic drag-handles, but there were some differences between the two tasks. In the verbal output task, the action words were draggable items. Each action word had a common drag-handle, which is exemplified in the top panel of Appendix B. Because the verbal output task merely required the participant to match action words with object words, that drag-handle icon denoted the ability to freely drag the item to any one of multiple drop locations. In the enactment output task, the object icons were the draggle items. Because the enactment output task required the participant to perform one of multiple actions upon each object icon, each draggable item included a set of two to four drag-handles, which are exemplified in the middle panel of Appendix B. Three distinctive drag-handle icons denoted the separate abilities to drop, flip, or lift an item. These were short-actions, in that they required the participant to move the item to an adjacent grid cell. The fourth drag-handle icon was identical to that from the verbal output task, and it denoted the ability to either mail, save, or trash the item. These were long-actions, in that they required the participant to move the item to a nonadjacent grid cell. The bottom panel of Appendix B shows the two hand-cursors participants used to provide the drag-and-drop responses.
color set it apart from its background. Additionally, a drop-shadow effect increased the apparent depth between the window and the background. Because the window count effect potentially depended on the saliency of the change from one window to a second window, two distinct windows were designed. As shown in Appendix C, the two windows differed both in their primary hue and in their texture. An input sequence could begin in either the red window or the blue window, and it could be either a one-window or a two-window sequence. In the two-window conditions, the style of the initial window always changed during segmentation (i.e., from red to blue or from blue to red).
Text-input sequences. Appendix D illustrates steps of an example text-input sequence. At the start of a text-input sequence, four action words formed a vertical column toward the left of the screen, and four object words formed a column toward the right of the screen. The words appeared in a randomized order within each column. To form an
instruction, a single action word (e.g., drop) and a single object word (e.g., box)
simultaneously moved toward the center of the screen. When these words met at the center of the screen, the whole phrase (e.g., drop the box) appeared within a rectangular text box. Subsequent pairings formed phrases below their predecessors, such that by the end of an entire input sequence, the four instructions formed a vertical list.
demonstrate an instruction, a hand-cursor moved toward an object icon, grabbed one of the available drag-handles, and dragged the object icon to a separate grid cell. The hand-cursor then released the drag-handle, at which point the object icon became a darker shade of gray but remained visible. Between demonstrations of individual instructions, the hand-cursor moved directly from object to object. By the end of an entire input sequence, all four darkened objects were visible in their new locations. Because this input format was merely an automated performance of the enactment output task, further details are provided in the description of that task.
Verbal output tasks. Appendix F illustrates steps of a verbal output task. The task began with eight words organized into two columns inside a nine-by-nine grid. Four action words formed the left column, and four object words formed the right column. The order of words within each column was always random, regardless of the format of the preceding input sequence. To form pairs, a participant would drag action words away from the left column and release them within cells adjacent to the object words. The format of this verbal output task differed from the formats used within relevant past studies (e.g., Pettijohn et al., 2016; Allen & Waterman, 2015), mainly in that it could measure serial recall of instructions without requiring participants to speak or type. These changes allowed this task to be more like the enactment output task in terms of temporal and physical demands.
three cells of the middle grid row. When this task followed a demo-input sequence, all object icons and long-action icons started in the same grid cells that they had started in during the demonstration. When this task followed a text-input sequence, however, the object icons and long-action icons appeared to be in random orders within their respective regions of the grid. To enact an instruction, a participant would drag an object icon by a specific drag-handle and release it within a target cell. To perform a drop, flip, or lift action, the participant dragged the object icon down, left, or up (respectively) by one grid cell. To perform a mail, save, or trash action, the participant dragged the object icon to the central grid cell containing the appropriate long-action icon.
Input sequence procedure. The participant initiated an input sequence by clicking a “begin” button. The initial input window then appeared to open/expand from a point near the bottom right corner of the screen, and the instruction sequence began. Whether delivered as text or as a demonstration, an individual instruction filled a three-second presentation interval. Between the 2nd and 3rd instructions, there was an additional 1.5-second interval. In the one-window condition, the input sequence merely remained paused during this interval. In the two-window condition, the first window appeared to close/minimize toward the bottom left corner of the screen, and the second window then appeared to open/expand from the bottom right corner of the screen. After the 4th (final) instruction, the current window closed/minimized toward the bottom left corner of the screen, ending the input phase.
of the game grid, a countdown timer showed the seconds remaining in the trial. Upon selecting a draggable item’s drag-handle, the participant was shown a set of valid drop locations, denoted by darker grid cell outlines. For example, in the enactment output task, if an item’s drop handle was selected, only the grid cell immediately below the item was highlighted, whereas if the combined mail/save/trash handle was selected, multiple distant grid cells may have been highlighted. A response was recorded only if the item was dropped in a valid location. If dropped outside of a valid location, the item snapped back to its
original grid cell, allowing the participant further attempts at moving it. If dropped in a valid location, the item turned a darker shade of gray, and it could no longer be manipulated. Furthermore, no other items could be dropped within the newly occupied grid cell. Thus, valid responses were irreversible, and a single serial recall error necessarily resulted in at least one more error later in the sequence. If time expired before four valid responses were made, any remaining responses were counted as errors.
General Procedure
Data-collection sessions took place within a small computer classroom, with one to four participants attending each session. When multiple participants attended a single
session, they were seated at workstations spaced several feet apart. After providing informed consent, each participant proceeded through multiple phases of interaction with the data-collection application.
how the two formats of instruction sequences would be crossed with the two formats of recall tasks, creating the four memory games. Finally, it illustrated the appropriate usages of the various drag-handles, and it specified the rules for the two recall tasks.
The four memory games made up the next four phases of a session. There were 24 possible orders for completing the four memory games. The 24 orders were randomly distributed among each set of 24 participants to enroll in the study. Thus, across the 62 participants, each order was used two or three times. At the start of each memory game, participants saw a screen that described the precise instruction and recall formats for the upcoming set of trials. This granted the opportunity to prepare/adjust encoding strategies. Each memory game included nine trials, with the first trial serving as a practice trial. Data from the practice trials were not included in statistical analyses. Across the nine trials, all 36 possible action-object pairs were presented exactly once. For each participant, the order of the 36 pairs was pseudo-randomized, with the constraints that no one action and no one object could be repeated within a single trial. Across the eight non-practice trials, there four one-window trials and four two-window, which were randomly ordered for each participant and for each memory game.
RESULTS
Each trial of a recall task resulted in four response records corresponding to the four instructions presented during an input sequence. Each of these responses was deemed correct or incorrect across four categories. As the most stringent categorization, a correct serial-pair response required a correctly paired action and object at the appropriate serial position within the sequence. For less strict categorizations, a correct serial-action response required only the selected action to be at the appropriate serial position, while a correct serial-object response required only the selected object to be at the appropriate serial position. As another lenient categorization, a correct non-serial-pair response required only a correctly paired action and object from the given sequence, regardless of serial position. Aggregate accuracy scores (proportions of correct responses) then served as the dependent measures within a doubly multivariate repeated-measures analysis of variance. The four two-level factors were window count (one vs. two), input format (text vs. demo), output format (verbal vs.
enactment), and sequence segment (first vs. second), which separated the first two instructions/responses from the second two instructions/responses. All four factors were within-subjects.
Table 1. Results of Multivariate Analysis of Variance
Source of Variance
I O W S F(1, 61) 𝛈𝛈𝐩𝐩𝟐𝟐 p
✓ 8.666 .374 < .001 *
✓ 8.014 .356 < .001 *
✓ 0.361 .024 .835
✓ 56.011 .794 < .001 *
✓ ✓ 20.172 .582 < .001 *
✓ ✓ 0.953 .062 .440
✓ ✓ 1.502 .094 .213
✓ ✓ 4.227 .226 .005 *
✓ ✓ 2.874 .165 .031 *
✓ ✓ 0.146 .010 .964
✓ ✓ ✓ 0.971 .063 .431
✓ ✓ ✓ 9.589 .398 < .001 *
✓ ✓ ✓ 1.124 .072 .354
✓ ✓ ✓ 0.096 .007 .983
✓ ✓ ✓ ✓ 0.511 .034 .728
Note. I = Input Format. O = Output Format. W = Window Count. S = Sequence Segment. The asterisks indicate significant effects.
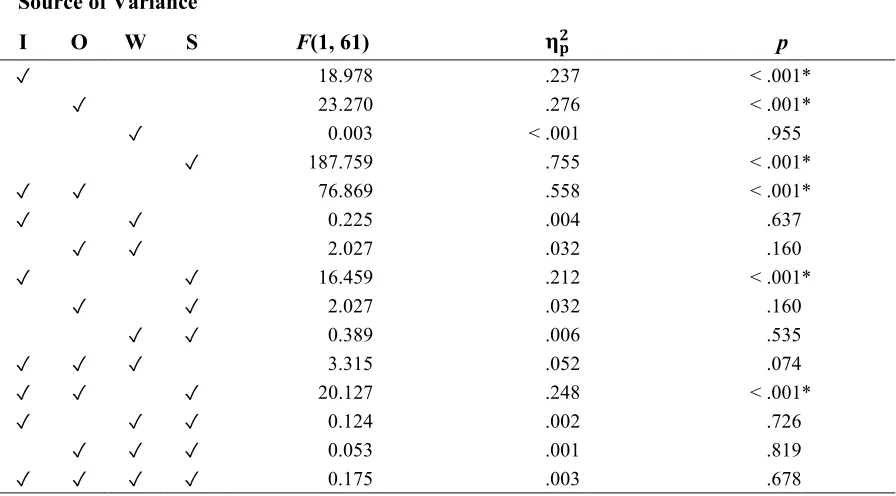
Table 2. Results of Univariate Analysis of Variance – Serial Recall of Pairs
Source of Variance
I O W S F(1, 61) 𝛈𝛈𝐩𝐩𝟐𝟐 p
✓ 18.978 .237 < .001 *
✓ 23.270 .276 < .001 *
✓ 0.003 < .001 .955
✓ 187.759 .755 < .001 *
✓ ✓ 76.869 .558 < .001 *
✓ ✓ 0.225 .004 .637
✓ ✓ 2.027 .032 .160
✓ ✓ 16.459 .212 < .001 *
✓ ✓ 2.027 .032 .160
✓ ✓ 0.389 .006 .535
✓ ✓ ✓ 3.315 .052 .074
✓ ✓ ✓ 20.127 .248 < .001 *
✓ ✓ ✓ 0.124 .002 .726
✓ ✓ ✓ 0.053 .001 .819
✓ ✓ ✓ ✓ 0.175 .003 .678
With few exceptions, the separate univariate analyses and subsequent pairwise comparisons revealed patterns of results that were consistent across the four measures of recall accuracy. Consequently, in avoidance of redundancy, most of the following summaries have been limited to the serial recall of action-object pairs, which was the strictest of the four measures. Noteworthy exceptions are included among the tests of hypotheses H2 and H3. Table 2 shows the results of the univariate analysis of the recall of pairs. Appendix H shows the results of the other three measures of recall accuracy.
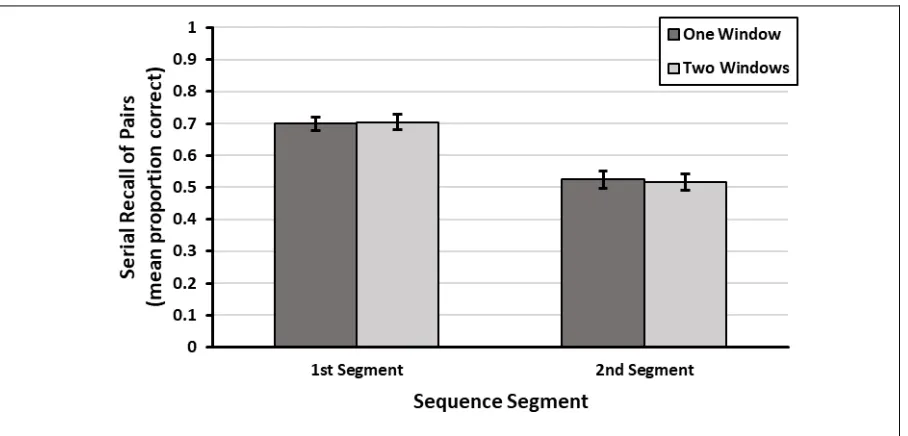
Univariate Tests of Hypothesis H1
Hypothesis H1 predicted a two-way interaction between window count and sequence segment, with a larger window count effect within the first sequence segment than within the second sequence segment. However, this interaction did not reach statistical significance within any of the four measures of recall accuracy. As shown in Figure 1, for each sequence segment, performance within the one-window condition was neither better nor worse than performance within the two-window condition.
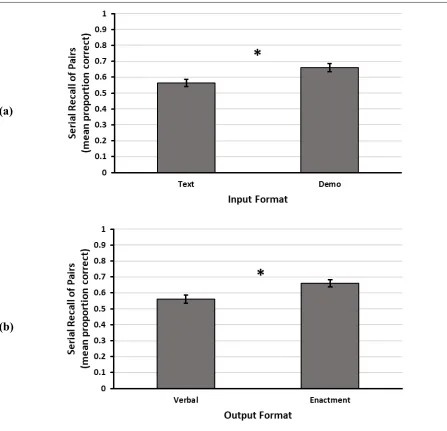
Univariate Tests of Hypothesis H2
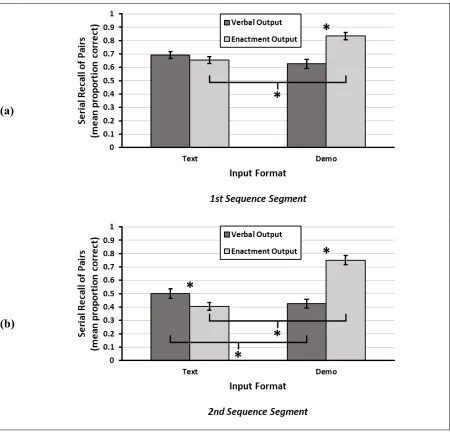
In accordance with hypothesis H2, there were significant main effects of both input format and output format, and the subsequent pairwise comparisons supported the directional predictions. As shown in Figure 2a, demonstrated instructions led to better performance than typed instructions. Likewise, Figure 2b shows that enactment recall was superior to that of verbal recall.
(a)
(b)
Figure 2. Main Effects of Input Format and Output Format
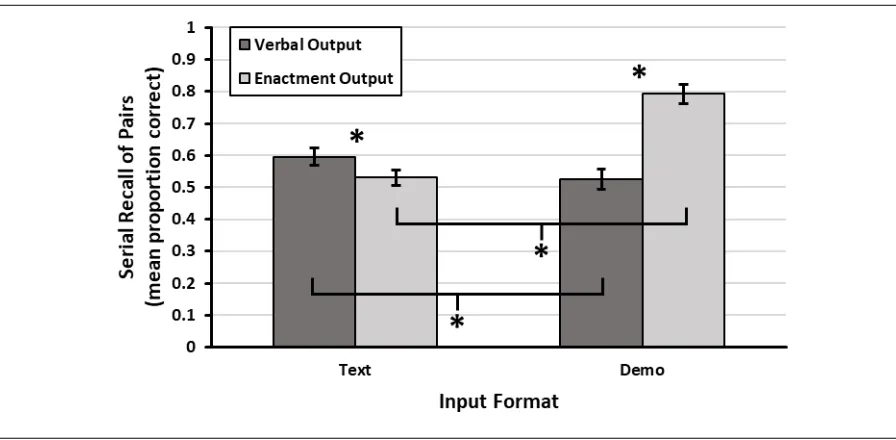
Hypothesis H2 also predicted a two-way interaction between input format and output format. Though the two-way interaction was significant, the mean differences strayed from the directional predictions, both when holding input format constant and when holding output format constant. As shown in Figure 3, typed instructions led to better verbal recall than enactment recall, while demonstrated instructions led to better enactment recall than verbal recall. Similarly, verbal recall was better following typed instructions than following demonstrated instructions, while enactment recall was better following demonstrated
instructions than following typed instructions. This pattern may have been a general effect of the congruency between the input and output conditions.
Beyond the predictions of hypothesis H2, there was a significant three-way
interaction among input format, output format, and sequence segment. Figure 4 reveals two aspects of this interaction. First, the effect of sequence segment differed across the four input/output conditions. Second, the effect of input/output congruency differed between the two sequence segments.
Figure 3. Interaction of Input Format and Output Format
For all four input/output conditions, recall accuracy was significantly higher for items in the first segment than for items in the second segment. This pattern is apparent when comparing each bar in Figure 4a with its counterpart in Figure 4b. Note, however, that the magnitude of this primacy effect differed across the four conditions, as indicated by Cohen’s d in Table 3. The effect was largest when text-input preceded enactment-output, and it was smallest when demo-input preceded enactment-output.
(a)
(b)
Figure 4. Interaction of Input Format, Output Format, and Sequence Segment
The input/output congruency effect had a greater presence in the second segment than in the first segment. In the second segment, the congruency effect was present in its full form. For example, when instructions were typed phrases, verbal recall performance was superior to enactment recall performance, and when instructions were demos, enactment recall performance was superior to verbal recall performance. In the first segment, however, only the latter component of the congruency effect was significant. That is, when
instructions were typed phrases, the difference between verbal recall performance and enactment recall performance was not statistically significant. This pattern differed between two of the less strict measures of recall accuracy. Specifically, in the first segment, partial congruency effects were found for the serial recall of objects, whereas the full congruency effect was found for the serial recall of actions. These different patterns are shown in Appendix I.
Univariate Tests of Hypothesis H3
Hypothesis H3 predicted a three-way interaction among window count, input format, and output format, with the smallest window count effect emerging within the task pairing text-input with verbal output. The three-way interaction did not reach statistical significance within any of the four measures of recall accuracy, but it nearly achieved significance for the recall of objects (F(1,61) = 3.779, ηp2 = .058, p = .057). Regardless, because the interaction
Table 3. Effect of Sequence Segment across the Four Input/Output Conditions
Input Output Mean Diff. (S1 - S2) SD t(61) Cohen’s d p
Text Verbal .192 .186 8.112 1.030 <.001 *
Text Enactment .250 .176 11.205 1.423 <.001 *
Demo Verbal .201 .191 8.266 1.050 <.001 *
Demo Enactment .083 .142 4.579 0.581 <.001 *
also did not achieve statistical significance at the multivariate level, this borderline-significant interaction could not be examined with a sufficient level of confidence.
DISCUSSION
In their second experiment, Pettijohn et al. (2016) measured memory for sequences of items that appeared in computer windows. In one condition, all items appeared within a single computer window. In another condition, halfway through the presentation of the item sequence, the initial computer window closed, and a second computer window opened to complete the sequence. Participants remembered more items within the two-window
condition than within the one-window condition. The present experiment included a similar manipulation of computer windows, but the manipulation did not result in any reliable effects on memory for item sequences. This may have been due to key differences between the two experiments.
Perhaps most importantly, the two experiments differed as to whether the first half of each item sequence was completely segregated from the second half. Pettijohn et al.
presented items in a purely serial fashion, with each item disappearing prior to the appearance of the next item. As a result, in their two-window condition, each half of a sequence appeared within just one of the two computer windows. According to their Event Horizon Model, this pattern of segmentation improved memory by reducing retrieval interference. In the present experiment, the items accumulated, such that by the end of a sequence, all four items were visible within a computer window. As such, in the
sequence. In the present experiment, the computer window transition did not reliably impair memory for instruction sequences. However, a future experiment may yet reveal that the computer window transition can improve memory for instruction sequences when the first and second halves of the sequences are completely segregated.
Another difference between the two experiments was the category of the items that participants attempted to remember. Pettijohn et al. presented sequences of single, typed nouns. However, their Event Horizon hypothesis specified the segmentation of
“information” (p. 142), not of nouns specifically. That general hypothesis was valid within the present experiment, in which each sequence item was an instruction that consisted of an action paired with an object. Nevertheless, a future experiment could more closely replicate the design used by Pettijohn et al. For example, the sequence items could be single objects, rather than action-object pairs. As in the present experiment, the objects could be either words or icons. The former condition would closely resemble the design used by Pettijohn et al., while the latter condition would extend that design by a much smaller degree than did the present experiment.
activity, the extra passage of time, and the window transition. Though this issue does not greatly diminish the researchers’ event segmentation hypothesis, it does prevent clear-cut implications for the design of software user interfaces. The present experiment’s method did not measure the separate effects of these variables. Instead, it employed automatic control of window changes, eliminating the requirement to click buttons. As there was no effect of window count in present experiment, future experiments may be needed in order to examine active versus passive segmentation methods.
Each of these differences could have played a role in preventing a reliable window count effect from emerging. However, Pettijohn et al. provided a general hypothesis to explain their effect. The hypothesis made no assumptions regarding most of the different design elements included in the present experiment. While the present study was in its data-collection phase, Pettijohn and Radvansky (2018) once again reproduced the effect of walking through doorways, extending the finding to measures of recall rather than
recognition. If their laboratory’s findings prove difficult to replicate, there will be little to discuss in terms of implications for the design of instructional software. In addition to testing the reliability of the doorway and window count effects, further studies ought to examine the effects of event segmentation within more mundane instruction-following tasks.
found beneficial effects of demonstrations at encoding and of enactment at recall, but they did not find significant interactions between their input and output formats. The present experiment replicated the benefits of demonstrations and enactment, but more importantly, it resulted in an interaction between the input and output formats.
The interaction revealed that verbal output performance was better following text-input than following demo-text-input, while enactment output performance was better following demo-input than following text-input. At a superficial level, this pattern reflects the
congruency between the input stimuli and the output stimuli. That is, in the text-input condition and in the verbal output task, the primary stimuli were typed words, whereas in the demo-input condition and in the enactment output task, the primary stimuli were icons. This stimulus congruency effect may have been the result of a predominance of multiple
beneficial encoding operations within the congruent scenarios.
When comparing memory for words and pictures, Weldon and Roediger (1987, Exp. 4) found a similar effect of stimulus congruency. During an input phase, all their participants viewed mixed sequences of single words and pictures. However, the participants were not aware that they would need to remember these stimuli. As output tasks, half of the
participants performed word fragment completion tests, and the other half performed picture fragment identification tests. For these tests, the experimenters erased parts of the words and pictures, such that participants could not easily recognize them. Instead, participants
attempted to resolve the fragmented stimuli, and the researchers determined whether participants’ solutions matched the unfragmented originals. Importantly, though an input stimulus and a test stimulus could correspond with one another, their formats could be
the input sequence, then half of the participants received a fragmented version of that same word (congruent test stimulus), while half of the participants received a fragmented picture of a windmill (incongruent test stimulus). Within both the word fragment completion test and the picture fragment identification test, participants performed best when the formats of the test stimuli were congruent with the formats of the corresponding input stimuli. Because the researchers never informed their participants that they would be engaging in any type of memory test, they hypothesized that lower-level perceptual features of the fragmented test stimuli must have cued implicit memories of the congruent stimuli that had appeared during the input sequences. In other words, participants had unintentionally encoded and retrieved the surface features of the input stimuli.
output task format would follow each instruction sequence, and they reported using several different encoding strategies among the four scenarios.
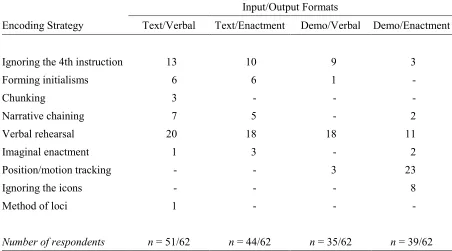
Table 4 shows the results of an informal analysis of their encoding strategies. The analysis was informal in the sense that no inter-rater reliability was determined when
categorizing participants’ responses, which were freely typed. The most informative pattern was that visuospatial encoding strategies were predominant only when enactment-output followed demo-input, whereas verbal encoding strategies were predominant in all three of the other memory games. These results were inconsistent with the prediction that the three tasks that included either demo-input or enactment-output would be more likely to induce
visuospatial encoding processes, as hypothesized by Yang et al. (2015) and Waterman et al. (2017). A methodological factor may account for the different results between their
experiments and the present experiment.
Table 4. Encoding Strategies Used within the Four Memory Games
Input/Output Formats
Encoding Strategy Text/Verbal Text/Enactment Demo/Verbal Demo/Enactment
Ignoring the 4th instruction 13 10 9 3
Forming initialisms 6 6 1 -
Chunking 3 - - -
Narrative chaining 7 5 - 2
Verbal rehearsal 20 18 18 11
Imaginal enactment 1 3 - 2
Position/motion tracking - - 3 23
Ignoring the icons - - - 8
Method of loci 1 - - -
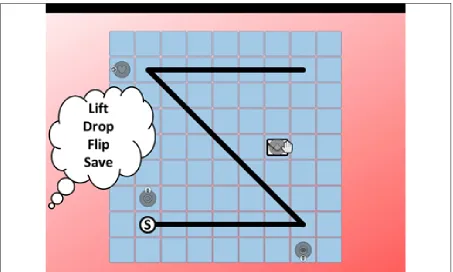
In the present experiment, when the enactment output task followed demos, the goal was to perfectly reproduce the demonstration sequence. To allow for this, the spatial arrangement of icons at the start of the output task was identical to the spatial configuration of icons at the start of the input sequence. During the input phase, as the hand-cursor demonstrated the sequence of instructions, its global motion path carried information useful for the serial recall of objects and long-actions (mail, save, and trash), and its smaller motions directly corresponded to short-actions (drop, flip, and lift). Thus, the cursor’s motions
carried all of the information necessary for perfect recall. Many participants reported attempting to remember motion paths, allowing them to ignore all or some of the symbolic information of the individual object and action icons.
Figure 5. Example Motion Path – Type I
This type encodes all four action/object pairs. An ‘S’ indicates the start position.
Figure 6. Example Motion Path – Type II
In each of the other three memory games of the present experiment, the spatial arrangements of words and icons at the start of the output tasks was random. As such, participants could not benefit from encoding the global motion paths of any of the stimuli during input. Their reports suggest a relatively higher reliance on verbal rehearsal. Among those three memory games, the verbal rehearsal strategy may have been simplest to use within the game pairing text-input with verbal output, because that encoding process did not involve a translation from words to icons, or vice versa. This type of transfer-appropriate processing may account for the somewhat higher performance within that memory game. Curiously, in those same three games, participants were also seemingly more inclined to use the strategy of ignoring the fourth instruction during input. This strategy was equally available in all four memory games, because there was always only one possible action-object pair remaining after the first three had already been made. If participants used this strategy equally in all four games, they were much less likely to report using it in the game pairing demo-input with enactment-output. Alternatively, participants may have been less likely to use that strategy, due to the efficiency of the visuospatial strategies (e.g., motion tracking).
increased the consistency of the external encoding and recall contexts, and it would have allowed precise planning of future motor actions, fulfilling the researchers’ multi-code and action memory hypotheses. Though the researchers did not report their participants’ encoding strategies, a closer examination of their methodology can reveal how their participants may have utilized motion paths where participants in the present experiment could not.
The design of the present experiment more closely resembled the design used by Yang et al. (2015, Exp. 1) than the design used by Waterman et al. (2017, Exp. 2a), so the former design serves as the more appropriate model. To deliver instructions to their participants, Yang et al. used a computer monitor to display either text (text-input) or recordings of demonstrations (demo-input). When providing recall responses, the
participants either spoke the instructions aloud (verbal-output) or manipulated real objects upon a table (enactment-output). The persistent visibility of those real objects would have been particularly beneficial within the two scenarios that corresponded to the present experiment’s incongruent scenarios.
Figure 7. Stimulus Configuration from a Past Experiment
Consider the scenario in which text-input preceded enactment-output. During the text-input sequences, participants could look from the text on the computer monitor to the objects on the table. In doing so, they could visualize the appropriate motion paths among objects in the instructions, and they could engage in imaginal enactment of the specific actions (e.g., push, drag, spin). Then, during the enactment output tasks, participants could use the objects as cues or landmarks when realizing the contents of their visual/motoric imagery. Importantly, if participants could accurately maintain the imaginal motion paths, then they would not need to maintain the names of objects, because only the locations were necessary for accurate enactment-output. Yang et al. found that performance within this scenario was at least equivalent to (if not marginally greater than) performance within the scenario pairing text-input with verbal-output.
Now consider the scenario in which demo-input preceded verbal-output. During the demo-input sequences, participants could encode the motion paths of on-screen stimuli, including the target objects and the experimenter’s hands and arms. Then, during the verbal output tasks, participants could use the objects on the table as cues or landmarks when
Thus, in each of those two scenarios, the visible objects would have allowed participants to simulate the one scenario that paired demo-input with enactment-output. In the present experiment, that same scenario evidently provided the best encoding and retrieval conditions, because it allowed participants to utilize the motion tracking strategy, and it also may have benefited from perceptual priming and implicit cueing, due to the match between the perceptual features of the input and output stimuli. This highlights two additional aspects of the design and the results of the experiment conducted by Yang et al. (2015, Exp. 1). Firstly, the beneficial effects of perceptual priming and implicit cueing were not likely to have been available when text-input preceded verbal-output. In that scenario, their
participants viewed instructions as typed words on the computer monitor, but there could not have been any congruent verbal stimuli during output, because participants provided spoken responses. Secondly, in that same scenario, participants could have strategically utilized imaginal motion paths, but this is difficult to surmise by comparing the methods and results of their experiment with those of the present experiment.
output task, participants were more likely to engage in imaginal enactment, and when
expecting the verbal output task, participants were more likely to engage in verbal rehearsal. In general, verbal rehearsal may be the most salient strategy for encoding text-input in preparation for verbal-output, even when visuospatial strategies are also available.
A future experiment can more formally test whether the stimulus congruency effect diminishes when participants have direct visual access to target objects during input and output phases. For example, the computerized memory games could be modified to include a static mini-map of the objects in one of the corners of the monitor, allowing participants to easily glance from the instruction-input region of the monitor. This method would allow for a comparison of performance within map-present and map-absent conditions, and it would have the added benefit of readily accommodating eye-tracking as an objective measure of strategy utilization. Such objective measures will help fill in the gaps left by participants who do not report using any encoding strategies.
CONCLUSION
REFERENCES
Allen, R. J., & Waterman, A. H. (2015). How does enactment affect the ability to follow instructions in working memory? Memory & Cognition, 43, 555-561.
https://doi.org/10.3758/s13421-014-0481-3
Baddeley, A. D. (1966). Short-term memory for word sequences as a function of acoustic, semantic and formal similarity. The Quarterly Journal of Experimental Psychology, 18, 362-365. https://doi.org/10.1080/14640746608400055
Baddeley, A. D. (2000). The episodic buffer: A new component of working memory? Trends in Cognitive Sciences, 4, 417-423. https://doi.org/10.1016/S1364-6613(00)01538-2 Bilodeau, I. M., & Schlosberg, H. (1951). Similarity in stimulating conditions as a variable in
retroactive inhibition. Journal of Experimental Psychology, 41, 199-204. https://doi.org/10.1037/h0056809
Cohen, R. L. (1981). On the generality of some memory laws. Scandinavian Journal of Psychology, 22, 267-281. https://doi.org/10.1111/j.1467-9450.1981.tb00402.x Cohen, R. L. (1983). The effect of encoding variables on the free recall of words and action
events. Memory & Cognition, 11, 575-582. https://doi.org/10.3758/BF03198282 Gandy, D. (2017). Font Awesome [Icon Repository]. Retrieved from
http://fortawesome.github.com/Font-Awesome
Greenspoon, J., & Ranyard, R. (1957). Stimulus conditions and retroactive inhibition. Journal of Experimental Psychology, 53, 55-59. https://doi.org/10.1037/h0042803 Goschke, T., & Kuhl, J. (1993). Representation of intentions: Persisting activation in
Jacoby, L. L. (1991). A process dissociation framework: Separating automatic from intentional uses of memory. Journal of Memory and Language, 30, 513-541. https://doi.org/10.1016/0749-596X(91)90025-F
Jaroslawska, A. J., Gathercole, S. E., & Holmes, J. (2018). Following instructions in a dual-task paradigm: Evidence for a temporary motor store in working memory. Quarterly Journal of Experimental Psychology, 71, 2439-2449.
https://doi.org/10.1177/1747021817743492
Koriat, A., Ben-Zur, H., & Nussbaum, A. (1990). Encoding information for future action: Memory for to-be-performed tasks versus memory for to-be-recalled tasks. Memory & Cognition, 18, 568-578. https://doi.org/10.3758/BF03197099
Miller, G. A. (1956). The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychological Review, 63, 81-97.
https://doi.org/10.1037/h0043158
Morris, C. D., Bransford, J. D., & Franks, J. J. (1977). Levels of processing versus transfer appropriate processing. Journal of Verbal Learning and Verbal Behavior, 16, 519-533. https://doi.org/10.1016/S0022-5371(77)80016-9
Mura, K., Petersen, N., Huff, M., & Ghose, T. (2013). IBES: A tool for creating instructions based on event segmentation. Frontiers in Psychology, 4.
https://doi.org/10.3389/fpsyg.2013.00994
Pettijohn, K. A., & Radvansky, G. A. (2016a). Walking through doorways causes forgetting: Environmental effects. Journal of Cognitive Psychology, 28, 329-340.
Pettijohn, K. A., & Radvansky, G. A. (2016b). Walking through doorways causes forgetting: Event structure or updating disruption? The Quarterly Journal of Experimental Psychology, 69, 2119-2129. https://doi.org/10.1080/17470218.2015.1101478 Pettijohn, K. A., Thompson, A. N., Tamplin, A. K., Krawietz, S. A., & Radvansky, G. A.
(2016). Event boundaries and memory improvement. Cognition, 148, 136-144. https://doi.org/10.1016/j.cognition.2015.12.013
Radvansky, G. A. (2012). Across the event horizon. Current Directions in Psychological Science, 21, 269-272. https://doi.org/10.1177/0963721412451274
Radvansky, G. A., & Copeland, D. E. (2006). Walking through doorways causes forgetting: Situation models and experienced space. Memory & Cognition, 34, 1150-1156. https://doi.org/10.3758/BF03193261
Radvansky, G. A., Krawietz, S. A., & Tamplin, A. K. (2011). Walking through doorways causes forgetting: Further explorations. The Quarterly Journal of Experimental Psychology, 64, 1632-1645. https://doi.org/10.1080/17470218.2011.571267 Radvansky, G. A., Pettijohn, K. A., & Kim, J. (2015). Walking through doorways causes
forgetting: Younger and older adults. Psychology and Aging, 30, 259-265. https://doi.org/10.1037/a0039259
Radvansky, G. A., Tamplin, A. K., & Krawietz, S. A. (2010). Walking through doorways causes forgetting: Environmental integration. Psychonomic Bulletin & Review, 17, 900-904. https://doi.org/10.3758/PBR.17.6.900
Radvansky, G. A., & Zacks, J. M. (2014). Event cognition. New York: Oxford University Press.
Smith, S. M. (1982). Enhancement of recall using multiple environmental contexts during learning. Memory & Cognition, 10, 405-412. https://doi.org/10.3758/BF03197642 Strand, B. Z. (1970). Change of context and retroactive inhibition. Journal of Verbal
Learning and Verbal Behavior, 9, 202-206. https://doi.org/10.1016/S0022-5371(70)80051-2
Thomson, D. M., & Tulving, E. (1970). Associative encoding and retrieval: Weak and strong cues. Journal of Experimental Psychology, 86, 255-262.
https://doi.org/10.1037/h0029997
Tulving, E., & Thomson, D. M. (1971). Retrieval processes in recognition memory: Effects of associative context. Journal of Experimental Psychology, 87, 116-124.
https://doi.org/10.1037/h0030186
Tulving, E., & Thomson, D. M. (1973). Encoding specificity and retrieval processes in episodic memory. Psychological Review, 80, 352-373.
https://doi.org/10.1037/h0020071
Unity [Computer Software]. (2017). Retrieved from https://unity.com
Waterman, A. H., Atkinson, A. L., Aslam, S. S., Holmes, J., Jaroslawska, A., & Allen, R. J. (2017). Do actions speak louder than words? Examining children’s ability to follow instructions. Memory & Cognition, 45, 877-890. https://doi.org/10.3758/s13421-017-0702-7
Weldon, M. S., & Roediger, H. L. (1987). Altering retrieval demands reverses the picture superiority effect. Memory & Cognition, 15, 269-280.
https://doi.org/10.3758/BF03197030
Yang, T. X., Allen, R. J., Yu, Q. J., & Chan, R. C. (2015). The influence of input and output modality on following instructions in working memory. Scientific Reports, 5.
https://doi.org/10.1038/srep17657
Yonelinas, A. P., & Jacoby, L. L. (2012). The process-dissociation approach two decades later: Convergence, boundary conditions, and new directions. Memory & Cognition, 40, 663-680. https://doi.org/10.3758/s13421-012-0205-5
Zacks, J. M., Speer, N. K., Swallow, K. M., Braver, T. S., & Reynolds, J. R. (2007). Event perception: A mind-brain perspective. Psychological Bulletin, 133, 273-293. https://doi.org/10.1037/0033-2909.133.2.273
Zacks, J. M., & Tversky, B. (2001). Event structure in perception and conception. Psychological Bulletin, 127, 3-21. https://doi.org/10.1037/0033-2909.127.1.3 Zacks, J. M., & Tversky, B. (2003). Structuring information interfaces for procedural
Zimmer, H. D., & Engelkamp, J. (1989). One, two or three memories: Some comments and new findings. Acta Psychologica, 70, 293-304.
Appendix A: Words and Icons for Actions and Objects
(a)
(b)
Figure A1. Words and Icons for Actions and Objects.
The six actions (a) were crossed with the six objects (b) to form 36 possible instructions.
Appendix B: Example Draggable Items, Drag-Handles, and Hand-Cursors
(a)
(b)
(c)
Figure B1. Example Draggable Items, Drag-Handles, and Hand-Cursors
The draggable action word (a) includes a long-action drag-handle. The draggable object icon (b)
includes drop, flip, lift, and long-action drag-handles. Font Awesome by Dave Gandy (2017)
Appendix C: Computer Windows for Input Sequences
(a)
(b)
Figure C1. Computer Windows for Input Sequences
Appendix D: Illustration of a Text-Input Sequence
Figure D1. Illustration of a Text-Input Sequence
Appendix D
Figure D2. Illustration of a Text-Input Sequence (Continued)
Appendix D
Figure D3. Illustration of a Text-Input Sequence (Continued)
Appendix E: Illustration of a Demo-Input Sequence
Figure E1. Illustration of a Demo-Input Sequence
Appendix E
Figure E2. Illustration of a Demo-Input Sequence (Continued)
Appendix E
Figure E3. Illustration of a Demo-Input Sequence (Continued)
Appendix F: Illustration of a Verbal Output Task
Figure F1. Illustration of a Verbal Output Task
Appendix F
Appendix F
Figure F3. Illustration of a Verbal Output Task (Continued)
Appendix G: Illustration of an Enactment Output Task
Figure G1. Illustration of an Enactment Output Task