Near Real-Time Data Warehousing Using
State-of-The-Art ETl Tools
Minakshi & Happy Sharma Department of Information Technology
Dronacharya College of Engineering,Khentawas, Farukh Nagar, Gurgaon, Haryana, India
[email protected] ; [email protected]
Abstract -
Information distribution centers are customarily revived in an intermittent way, regularly every day. Accordingly, there is some deferral between a business exchange and its appearance in the information stockroom. The latest information is caught in the operational sources where it is occupied for examination. For opportune choice making, today's business clients requests ever fresher information. Close continuous information warehousing addresses this test by shortening the information stockroom refreshment interims and thus, conveying source information to the information stockroom with lower idleness. One result is that information stockroom refreshment can never again be performed in o®-top hours just. Specifically, the source information may be changed simultaneously to information stockroom refreshment. In this paper we demonstrate that peculiarities may emerge under these circumstances prompting a conflicting condition of the information stockroom and we propose methodologies to maintain a strategic distance from refreshment oddities.
Keywords: Near constant information
warehousing, Change Data Capture
1 Near Real-Time Data Warehousing
operational sources and the information stockroom experience low load conditions, e.g. during the evening time. In synopsis, the conventional information outlet center chronicled information as of recently while current information is accessible in the operational frameworks just. Today's business clients, on the other hand, interest for a la mode information investigations to sup- port auspicious choice making. A workable answer for this test is shortening the information distribution center stacking cycles. This methodology is alluded to as close genuine time information warehousing or microbatch ETL [4]. Rather than \true" ongoing arrangements this methodology expands on the experienced and demonstrated ETL framework and does not require the re-usage of the change rationale. The major chal- lenge of close constant information warehousing is that information distribution center refreshment can never again be put off to o®-top hours. Specifically, changes to the musical dramational sources and information distribution center refreshment may happen simultaneously, i.e. the ETL framework can't accept the source information to stay steady all through the extraction stage. We demonstrate that irregularities may happen under these circumstances bringing about the information stockroom to wind up in a mistaken state. Accordingly, unique forethought must be taken when endeavoring to utilize conventional ETL employments for close ongoing information warehousing. In this paper, we propose a few methodologies to avert information stockroom refreshment peculiarities and examine their individual points of interest
and downsides. The rest of this paper is organized as takes after: In Section 2 we examine related deal with information distribution center refreshment inconsistencies. In Section 3 we brie°y clarify the idea of incremental stacking and present illustrations for refreshment aberrances. In Section 4 we examine properties of operational sources and present a classi¯cation. In Section 5 we then propose a few methodologies to anticipate refreshment abnormalities for speci¯c classes of sources close in Section 6.
2 Related Work
is performed. ECA depends on payment inquiries that are sent again to the sources to o®set the e®ect of changes that happened simultaneously to information stockroom refreshment. Interestingly, Strobe performs com- pensation by regional standards, abusing the way that the stockroom perspective incorporates all key qualities of the source relations. Both calculations are customized for a speci¯c class of information sources: It is expected that the sources effectively tell the information distribution center about changes they happen. Besides, for ECA the sources need to be capable (and eager) to assess SPJ questions issued by the information distribution center for payment purposes.
In this paper, we broaden the discourse on information distribution center refreshment abnormalities to different classes of information sources with di®erent properties. The ECA calculation and the Strobe group of calculations are noticeably perplexing. It is important to track unanswered questions sent to the sources, locate source changes that happened simultaneously to question assessment, develop adjusting questions, or perform neighborhood payment of past inquiry results.1 specifically, the calculations are intended for a message-situated information trade with the source frameworks. Condition of-the-workmanship ETL devices, on the other hand, consider the usage and execution of rather basic information °ows just. The hidden model is frequently a regulated, non-cyclic chart where the edges demonstrate the °ow of information and the hubs speak to different change
administrators gave by the ETL instrument. Furthermore, ETL instruments are not manufactured for message-arranged information trade yet rather for preparing information in extensive groups. Consequently, we don't see any plausibility to actualize either ECA nor Strobe utilizing a condition of-the-craftsmanship ETL instrument. Future continuous ETL instruments may well o®er such praiseworthy peculiarities, if there will be a joining in the middle of ETL and EAI innovations. Nonetheless, for now different methodologies need to be considered to accomplish close ongoing capacities. In this paper we examine methodologies to close ongoing information distribution center refreshment that can be acknowledged with condition of-the-workmanship ETL apparatu.
3 Data Warehouse Refreshment
Anomalies
the town they board whereas table S stores the names of our sales representatives and also the city they're answerable for. Name values square measure assumed to be distinctive in each tables. Suppose we would like to trace the relationships between sales representatives and customers at the information warehouse mistreatment the table V . For this purpose, we employ associate ETL job E that performs a natural be a part of of C and S, i.e. E : V =C onC:city=S:city S. The ¯rst population of an information warehouse is named as initial load. throughout associate initial load, information from the sources is absolutely extracted,
1 A pseudo code define is conferred in [7] and [8].
2 Taking the IBM InfoSphereDataStage ETL tool as associate example, the relative al- gebra roughly covers simple fraction of the transformation operators (so known as
stages) available.
transformed, and delivered to the information warehouse. Thus, the warehouse table Vinitially contains one tuple [adam; kl; bob].
As supply information changes over time, the information warehouse gets stale, and hence,needs to be reinvigorated. information warehouse refreshment is often performed
on aperiodical basis. The naive approach is to easily rerun the initial load job, col-lect the ensuing information, and compare it to the information warehouse content to noticechanges.3 This approach is cited as full reloading and is clearly ine±-cient. most frequently simply a fraction of supply information has modified and it's fascinatingto propagate simply the changes to the information warehouse. This approach is thought asincremental loading. ETL jobs for intial loading can not be reused for progressiveloading. In fact, progressive loading needs the planning of extra ETL jobsdedicated thereto purpose.
relations 4S and OS that contain the insertions anddeletions to S, severally. we have a tendency to talk to information concerning changes to base relations aschange information. progressive loading will be performed exploitation 2 ETL jobs: The¯rst job E4 is employed to propagate insertions and might be de¯ned as E4 : 4V =(Cnew on 4S) [ (4C on Snew) wherever Cnew and Snew denote this state ofC and S, severally, i.e. the changes took e®ect in these relations. the thought is3 Note that it's impractical to drop and reload the target tables as a result of the informationwarehouse usually keeps a history of knowledge changes. This side of knowledge depositionis, however, not relevant to the discussion of refreshment anomalies and thusignored during this paper.
to look for every inserted tuple 4C and 4S if matching tuples square measure found within the
respective base relations Snew and Cnew. Note that it's not needed to hitch 4C
with 4S since the changes already took e®ect within the base relations.
In a similar manner, associate ETL job to propagate deletions will be designed. Inthe expression higher than we tend to may
merely replace 4C by OC, 4S by OS, Cnew byCold, and Snew by oversubscribed, wherever Cold and oversubscribed denote the initial state of C and S,i.e. the changes failed to take e®ect in these relations however. However, operationalsources sometimes cannot give relations in their initial state, therefore the ETLjob should do while not. The ETL job EO to propagate deletions will be de¯ned asEO : terrorist organization = (Cnew on OS) [ (OC on Snew) [ (OC on OS). Note that we tend to generally\overestimate" the deletions terrorist organization during this manner, however this doesn't cause a haulhere, since super°uous deletions of such tuples that don't seem to be in V don't takee®ect. The ETL jobs for progressive loading square measure represented in Figure a pair of.
Example 1. information warehouse refreshment while not anomalies.
kl; bob]g. V is invigorated by adding 4V and sub-tracting terrorist organization from its current state Vold. The new state of V is so Vnew = f[carl; kl; bob]g. this can be the right result, i.e. no anomalies occurred.
Example 2. information warehouse refreshment with a deletion anomaly. Again, suppose the initial states of the bottom relations square measure Cold = f[adam; kl]g and oversubscribed = f[bob; kl]g. currently suppose that the tuples [adam; kl] and [bob; kl] square measure deleted from C and S, severally. That is, C and S square measure empty in their current states Cnew = fg and Snew = fg. For reasons we'll discuss intimately within the subsequent sections, there could also be some delay between the purpose in time changes a®ect the bottom relations, and also the purpose in time changes ar captured and visual in the corresponding amendment relation. Therefore, the ETL system could already see the ¯rst deletion OC = f[adam; kl]g however it's going to not see the second deletion yet, i.e. OS = fg. once the ETL job EO is dead it returns Associate in Nursing empty set OV = fg. the explanation is that an identical tuple for OC = f[adam; kl]g is neither found in Snew nor in OS since each relations ar empty once the ETL job is executed. At some later purpose in time, the remaining deletion can get visible, i.e. OS can communicate f[bob; kl]g. However, as a result of OC is currently empty, the execution of EO can once more lead to Associate in Nursing empty set terrorist group = fg. Relation V at the information warehouse is thus left unchanged in each loading cycles. This result's incorrect andwe
speak of a deletion anomaly. Deletion anomalies arise once base tables are affected by deletions that haven't been captured by the time progressive loading is performed.
within the resultant loading cycle. Note that this is often not the case for inconsistencies arising from deletion anomalies. After having seen Associate in Nursing example for deletion and update anomalies one could raise if there ar insertion anomalies moreover. within the strict sense, insertion anomalies do exist. They arise from insertions that a®ected the bottom table however haven't been captured by the time progressive loading is performed. Insertion anomalies cause identical tuple to be sent to the information warehouse multiple times in sequentloading cycles. beneath set linguistics, however, this doesn't result in Associate in Nursing inconsistentdata warehouse state. thus anomalies caused by insertions might not be regarded as actual anomalies.
4 Properties of Operational Data Sources
Incremental loading is that the most popular approach to information warehouse refreshment because it typically reduces the quantity of information that needs to be extracted, trans- formed, and loaded by the ETL system. ETL jobs for progressive loading need access to supply information that has been modified since the previous loading cycle. For this purpose, therefore referred to as amendment information Capture (CDC) mechanisms at the sources can be exploited, if on the market. in addition, ETL jobs for progressive loading potentially need access to the general information content of the operational sources.Operational information sources di®er within the method information may be accessed. Likewise, di®erent authority mechanisms is also on the market. within the
remainder of this section we gift a classi¯cation of operational sources with relevance these properties based on [4] and [6].
Snapshot sources gift and custom applications typically lack a general purposequery interface however provide marketing information into the ¯le system. The ensuing ¯les give a photo of the source's state at the time of information extraction. Change information may be inferred by comparison serial snapshots. This approach is stated as photo di®erential [5]. Logged sources There square measure operational sources that maintain a amendment log thatcan be queried or inspected, therefore changes of interest may be retrieved. Severalimplementation approaches for log-based authority exist: If the operational supply provides active information capabilities like triggers, amendment information may be written to dedicated log tables. victimisation triggers, amendment information is also logged as a part of the original dealings that introduced the changes. as an alternative, triggers will be speci¯ed to be postponed inflicting amendment information to be written in an exceedingly separate transaction.
Database log scraping or log sni±ng square measure 2 a lot of authority implementationapproaches value being mentioned here [4]. the thought is to use the dealingslogs unbroken by the information system for backup and recovery. victimisationdatabase-speci¯c utilities, changes of interest may be extracted from the dealings log. The idea of log scraping is to analyse archive log ¯les. Log sni±ng, in distinction, polls the active log ¯le and captures changes on the °y. whereas these techniques have very little impact on the supply information, they involve some latency between the original dealings and therefore the changes being captured. Obviously, this latency is higher for the log scraping approach.In the remainder of this paper we'll see those sources that log changes as a part of the first dealings as synchronously logged sources whereas we have a tendency to refer to sources that don't
have this property as
asynchronousllogTimestampedsupplys Operational source systems typically maintain timestampcolumns to point the time tuples are created or updated, i.e. when-ever a tuple is modified it receives a contemporary timestamp. Such timestamp columns are spoken as audit columns [4]. Audit columns could function the choice criteria to extract simply those tuples that are modified since the last loading cycle. Note that deletions stay undetected tho'.
Lockable sources Operational sources could o®er mechanism to lock their information to prevent it from being modi¯ed. for example, information table locks or ¯le locks may be used for this purpose.ged sources.
5 Preventing Refreshment Anomalies
In Section three we've shown that refreshment anomalies cause the information warehouse
to become inconsistent with its sources. Analysis supported inconsistent information canlikely result
in wrong choices being created, so Associate in nrsing inconsistent informationwarehouse is of no use. In this section we tend to discuss approaches to stop refreshment
anomalies and
keep the information warehouse consistent. Refreshment anomalies occur for 2 rea- sons.During
a modified state however it doesn't see the complete modification information that resul t in this state. Thus, there's a mate be-tween the bottom table and its modification information. Such a modification information matecould
occur for 2 reasons. First, for many office techniques there's some la- tency between the initial modification within the base relation and also the modification being
captured. Second, even just in case the modification is captured as a part of the initialtransaction, the ETL system should still see a mismatch: ETL
jobs for incre-
mental loading typically assess joins between base relations and alter information in a nested loop fashion. That is, the modification information is ¯rst extracted thenused in the outer loop. later on, the operational supply is queried for
matching tuples. once the
bottom relation isn't barred, it's going to be modified in the meanwhile and also the ETL system e®ectively sees
a mate between the
Section three square measure supported traditional modification propagation
principles. specifically, a mate between
the base relations and
its modification information isn't anticipated .
Considering the 2 reasons that cause refreshment anomalies, there square measure 2
basic approaches to stop them: Either the ETL jobs will be prevented from seeing a mate between a base relation and its modification information or advanced ETL
jobs for progressive loading will be developed that job properly in spite of the change information mate. we are going to discuss each choices within the remainder
of this
section.
5.1Preventing
a modification information mate
There area unit many approaches to forestall the ETL jobs from seeing a modification information
mismatch. that approach is applicable is essentially determined by the properties of the operational sources. we tend to discuss choices for every of the supply categories
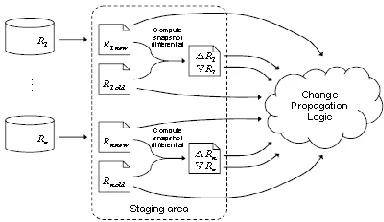
introduced in Section four. Snapshot Sources For exposure sources the matter is trivially solved: In
each loading cycle, the ETL system request a exposure of the sources' current state, i.e. the supply information is extracted fully. The exposure is hold on at the
ETL
tool's operating space, usually cited as count
ry. The exposure taken
during the previous loading cycle has been unbroken within the country and also the ETLsystem will currently work
out the exposure di®erential by examination the ordered
snapshots. the method is delineate in Figure three.
For progressive loading the ETL system doesn't question the operational sources directly. Instead, queries area unit issued against the snapshots within the stag-
ing area. Once taken,
snapshots clearly stay unchanged. Therefore, the
ETL
jobs won't see modification information mis matches and information warehouse refreshment
anomalies won't occur.
In the discussion on progressive loading in Section three we tend to assumed that the base relations area unit accessible in their current state solely. Hence, we tend
to designed ETL
that the specified modification propagation logic is usually easier during this case, i.e.
the ETL job may
be enforced mistreatment fewer operators as recommended in Section three. Computing exposure di®erentials is
easy and prevents refreshment anomalies. However, this approach has severe drawbacks: Taking snapshots is ex- pensive; massive volumes of
knowledge have to be compelled to be extracted and sent over the network. This may be acceptable in o®-peak hours however isn't AN possibility once the oper-
ational systems area unit busy. what is more the ETL system is needed to work out snapshot di®erentials that is once more costly [5] and also the storage price at the
staging area is high; roughly double the scale of all relevant base relations is re-
quired. In summary,
the exposure di®erentials
approach doesn't scale well to short loading cycles that facilitate close to period of time information deposit.
Logged Sources Logged sources maintain a modification log which will be queried
by the ETL system. during this means, the ETL system will extract the changes that occurred since the previous loading cycle. As we've got seen, refreshment anomalies arise from a mate between the state of the bottom relations and also the modification information within the log. That is, therearea unit 2
options to avoid
a modification information mate and so rule
out refreshment anoma-
lies: It will either be ensured that 1) the operational sources don't seem to be modified
during progressive loading, or 2) a duplicate of the bottom relation may be maintained
in the country.
The ¯rst approach is possible once the logged supply is lockable. Special care should be taken once the supply is logged asynchronously. Then there's
some latency between the
first modification and also the corresponding
log entry. Thus,
simply lockup the bottom table cannot avoid a modification information mate as a result of
changes that occurred before the lock was placed might not are written to the modification capture log however. If there's no mechanism to \°ush" the modification log
after the bottom relations are latched, this approach cannot avoid refreshment anomalies within the general case. the disadvantage of lockup operational sources is
obvious: For
transactions at the sources area unit blocked. this could not be acceptable except for o®-peak hours. The second strategy to avoid a modification information mate for logged
sources is to
maintain copies of the relevant base relations within the country. This comes at the cost of extra space for storing however minimizes the impact on
the operational
sources.
At the start of a loading cycle the ETL system queries the sources for change information.
No different queries area unit issued towards the sources for the remainder of
the loading cycle.
The modification information is
employed by the ETL system in 2 ways that as
shown in Figure four. First, it is the input for the ETL jobs for progressive loading. Second, it's wont to maintain the native copy of the bottom relation. The maintenance will either be performed at once before the ETL jobs area unit started or once the ETL jobs area unit ¯nished. within the former case the ETL
jobs see a duplicate of
the initial state of the bottom relations, within the latter case the ETL jobs see a duplicate of the present state of the bottom relations. The ETL jobs ought to be tailored to one or the opposite case.
Keeping copies of base relations within the area avoids refreshment anomalies for each, synchronous and asynchronous logged sources. within
the asyn-
chronous case there could also be some
latency between the
bottom relation modification and
the corresponding log entry. Consequently, changes that haven't been logged by the time the loading cycle begins won't be thought-about for
maintaining the
staged copy. That is, the state of the copy might lag behind the state of the bottom
relation. However, the copies ar forever in line with the extracted modification data, therefore a modification knowledge pai
r cannot occur.
In several cases it's not needed to stage copies of entire base relations: The base relations might contain attributes that aren't enclosed within
the knowledge ware-
house schema. Such
columns ar born throughout ETL process by
means that of
a projection operator. what is more, solely supply tuples that satisfy given predi-
cates could also be relevant to the information warehouse. during this case, the
ETL job contains
a selection operator that discards tuples not satisfying the predicate. To save storage space within the area the copies of base relations are often restricted to relevant attributes and tuples. Therefore, the ETL job's projection and choice operators ar \pushed down" and directly
applied to
the modification knowledge whereas it is transferred to the area as pictured in Figure four.
The staged copies ar
Select-Project (SP) views within the sense of [1]
the sources. In [1] it's been shown that SP views ar forever self-maintainable
with relevancy insertions. A su±cient con- dition for self-maintainability of SP views with relation to deletions is to retain the key attributes within the read. so any staged copy ought to contain the key
attributes of its base
relation notwithstanding they're not a part of the information warehouse schema.
Comparedto alternative approaches mention ed to this point, staging copies of base rela- tions has many advantages: most significantly, the impact on the operational sources is lowest. solely tiny volumes of knowledge got to be extracted in every load-
ing cycle and also
the sources aren't burdened in the other method. The disadvantage is the further cupboard space needed at the area.
Timestamped Sources In timestamped sources, changes ar captured by querying for tuples with a timestamp later than the most recent timestamp, seen dur- ing the last loading cycle. Recall that deletions can not be detected during this method.
Thus, solely insertions (and updates4) are
often propagated to the
information warehouse.
This restriction is well acceptable once historical knowledge is unbr oken within the knowledgeware- house as is most frequently the case. A modification knowledge pair will occur o nce the
ETL system has to question the operational sources throughout progressive loading. The ETL system might then see changes to the bottom relations that occurred when the modification knowledge was extracted. If the timestamped supply is lockable, the modification knowledge pair are often
avoided by lockup the
bottom relations whereas progressive loadin
g is performed.
Locks should be nonheritable before
the modification knowledge is extracted
and should not be re-
leased till all queries towards the individual base relation are answered. As mentioned before, lockup operational systems seriously interferes with busi- ness group action process. To minimize the impact on the operational systems and avoid refreshment anomalies at identical time we tend to projected to stage copies of the
bottom relations in
the discussion on logged sources before. This approach, however, poses issues for timestamped sources. Recall that deletions stay unseen once audit
columns ar used
for modification capture. therefore deletions can not be propagated to the staged copies and also the staged copies
grow steady. Even
worse, modification prop-
agation is skew in a very delicate way: Tuples that are deleted from the bottom relations stay within the staged copies and therefore in°uence
the modification propagation.
In this method, changes propagated to the warehouse might part arise from tuples that do now not exist within the sources. If the information warehouse keeps a history of
changes this is often undesirable. We tend to illustrate this e®ect with AN example. Example 4. Rethink the sample supply and target schemas introduced in Section 3. Again, suppose the initial states of the bottom relations ar Cold = f[adam; kl]g and oversubscribed = f[bob; kl]g. currently suppose that the tuple [adam;
kl] is
warehouse. this is often alright if the
warehouse is meant to
stay historical knowledge.
Say, a replacement tuple 4S = f[charly; kl]g is inserted into S. Then the ETL job E4 will end in 4V = f[adam; kl; charly]g as a result of the deleted tuple is preserved in the staged copy of C. However, Adam was ne'er accountable for Charly, thus the data warehouse's history is falsi¯ed. In summary, staging copies of timestampIn summary, staging copies of timestamped sources ought to be used with caution.
First, the staged copies grow in size steady and second, modification propagation could
be skew in a very delicate manner.
5.2 creating modification Propagation Anomaly-Proof
In the starting of this section we tend to identi¯ed 2 reasons that cause refreshment anomalies. First, anomalies could arise from a modification knowledge mismatch; we tend todiscussed approaches to avoid this within the previous section. Second, the ETL jobsfor progressive loading suppose ancient modification propagation mechanisms. In this section we tend to propose \anomaly-proof" modification propagation approaches thatwork properly in spite of a modification knowledge match and may be enforced us-ing progressive ETL tools. specially, we tend to have an interest in solutions thatneither lock operational sources nor maintain knowledge copies within the country.
All solutions mentioned within the previous section guarantee that knowledge warehouserefreshment is completed properly. while not having de¯ned it
expressly, by correctness we tend to mean that progressive loading continuously ends up in an equivalent knowledge warehousestate as full reloading would do. Some approaches projected during this section donot come through this levels of correctness. reckoning on the information deposit ap-plication, lower levels of correctness is also acceptable. thus we tend to de¯neahierarchy of correctness levels supported [7] that permits US to classify the ap-proaches projected within the remainder of this section.
for every sequence of supply changes and every sequence of in-cremental masses, finally changes are captured and no alternative changesoccurred within the meanwhile, a ¯nal progressive load ends up in an equivalent knowledgewarehouse state as a full reload would do. However, the information warehouse couldpass through mediator states that will not seem, if it had been totally reloadedin every loading cyclefor every knowledge warehouse statereached when progressive loading, there area unit valid supply states specified fullreloading crystal rectifier to the present state of the information warehouse.
for every sequence of supply changes and every sequence of loadingcycles, progressive loading ends up in an equivalent knowledge warehouse state as fullreloading would do.
and area unit resolved in sequent loadingcycles. To satisfy the weak consistency property a refreshment approach shouldnot yield update anomalies. As incontestable in Example three in Section three ANupdate anomaly could result in an information warehouse state that doesn't correspondto any valid state of the sources. this can be contradictory to the de¯nition on top of.Note that each one knowledge warehouse refreshment approaches mentioned within the previoussection satisfy the consistency property.
Logged Sources Synchronously logged sources capture changes as a part of the original group action. A modification knowledge match should still occur, once the ETLsystem runs separate transactions to extract modification knowledge and question the bottomrelations. exploitation world transactions instead, the modification knowledge match may beavoided. However, world transactions acquire locks on the bottom relations forthe length of progressive loading. we tend to mentioned this approach within the previoussection and identi¯ed the drawbacks of protection.
Reconsider the sample ETL job for progressive loading conferred in Sec-tion 3, E4 : 4V = (Cnew on 4S)[(4C on Snew). Since 4C and 4S area unit usuallymuch smaller than C and S, it's acceptable to guage the joins in a very nestedloop fashion.5 during this manner solely matching tuples have to be compelled to be extracted from thebase relations. once the ETL job is started, the ETL system ¯rst extracts thechange knowledge 4C and 4S. These datasets area unit employed in the
outer loop of the be a part ofoperators. Hence, for every tuple in 4C and 4S, one question is issued towardsthe base relations S and C, severally. every question is evaluated in a very separatetransaction, i.e. the locks nonheritable at the operational sources area unit discharged early.Changes to C and S that occur when the modification knowledge has been extracted andbefore the last question was answered, lead to a modification knowledge match and will
lack tuples deleted For this approach to be possible, the supply system has got to meet many prerequisites: It should be capable of evaluating the compensation expression domestically and in a single dealing. moreover, the supply should be logged synchronously and it should be attainable to \browse" the modification log rather than reading it in a very destructive manner. If these conditions are met, the printed approach avoids refreshment anomalies and stashes the consistency property. For synchronously logged sources that don't meet these conditions or asynchronously logged sources, we have a tendency to don't see any risk to attain consistency mistreatment progressive ETL tools, unless staging copies of base relations is Associate in nursing choice. However, there's how to attain convergence. Recall that the convergence property precludes deletion anomalies whereas it permits for update anomalies. Thus, creating the deletion propagation anomaly-proof is su±cientto achieve convergence. No medications with relevance the propagation of in-sections are needed. Contemplate the sample ETL jobs for progressive loading presented in Section three once more. to attain convergence, we want to change EO in way specified deletions are properly propagated in spite of a modification informationmismatch.In [1] it's been shown that a su±cient condition for SPJ views to be self-maintainable with reference to deletions is to retain all key attributes within the read. Thus, deletions will be propagated to a knowledge warehouse relation V, mistreatment solely the change information and V itself, if V contains all key attributes of the bottom
keep historical data instead. Deletion anomalies don't seem to be a difficulty during this case. However, update anomalies may occur once ancient modification propagation techniques are used as showman Section three. Recall that update anomalies arise from base relation updates that occur mediate the time modification information is totally extracted and therefore the time modification propagation is completed. Throughout modification propagation, the ETL system problems queries towards the bottom relations and such updates could impudence the question results in Associate in Nursing sudden means and cause update anomalies. Update anomalies will be avoided by exploiting timestamp data during modification propagation. Say, the previous progressive load was performed at time t1 and therefore the next progressive load is started. The ETL system ¯rest extracts all tuples with a timestamp larger than t1. These tuples structure the modification data. The largest timestamp seen throughout the extraction determines this time t2. Once the ETL system queries the bottom relations, the answers could in-clued tuples that are updated once t2. Mistreatment timestamps, such \dirty “tuples will simply be detected however it's unimaginable to ¯ND out concerning the state of these tuples before t2. However, ignoring dirty tuples already avoids update anomalies. Note that ignoring dirty tuples doesn't forestall any changes from being propagated. In fact, the propagation is simply delayed. All dirty tuples carry a timestamp larger than t2 and can so be a part of the modification information in the subsequent progressive
load. However, as a result of changes could also be propagated with a delay, this approach stashes the weak consistency property solely.
6: Conclusion
mentioned their impact on the opera-tonal sources, storage price, level of consistency, and conditions with relevancechange information capture properties. We have a tendency to believe that our results are valuable for ETLarchitects going to migrate to information warehouse refreshment in close to time period. When t2.
References:
[1] Gupta, A., Jag dish, H. V., Muick, I. S.: Data Integration using Self-Maintainable Views. EDBT, 1996, 140-1442. Jog, T., Declutch, S.: Towards generating ETL processes for incremental loading. IDEAS, 2008, 101-1103. Jog, T., Declutch, S.: Formalizing ETL Jobs for Incremental Loading of Data Ware-houses. BTW, 2009, 327-3464. [2] Kimball, R., Caserta, and J.: The
Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data. John Wiley & Sons, 20045.
[3] Labia, W., Garcia-Molina, H.: Ancient Snapshot Deferential Algorithms for Data Warehousing. VLDB, 1996, 63-746. Wisdom, J.: Research Problems in Data Warehousing. CIKM, 1995, 25-307. [4] Huge, Y., Garcia-Molina, H.,
Hammer, J., Wisdom, and J.: View Maintenance in a Warehousing Environment. SIGMOD Conference, 1995, 316-3278.
[5] Huge, Y., Garcia-Molina, H., Wiener, J. L.: Consistency Algorithms for Multi-Source