e-ISSN: 2278-067X, p-ISSN: 2278-800X, www.ijerd.com
Volume 13, Issue 11 (November 2017), PP.13-17
Enhanced Ranking Model
*Dr.V.V.S.S.S.Balaram
1,Sunil Bhutada
2,Maderi Lavanya
31,2Department of IT, SNIST, Hyderabad, India.
3M.Tech(CNIS), SNIST, Hyderabad, India.
Corresponding Author:*Dr.V.V.S.S.S.Balaram
ABSTRACT:
-In this paper, a reworking process is characterized to adjust a ranking model worked for a widerange search with the end goal of utilizing an area particular ranking model. It is hazardous to apply the full range ranking model straight away to various regions because of contrasts in the domain, to build an only and improved ranking model for each space is time taking for setting up the models. Along these lines, in this paper, we report the troubles by recommending a calculation entitled Ranking Adaptation Support Vector Machine (RA-SVM). This algorithm needs only the prediction of the standing ranking models, relative to their inner image or data from secondary domains. Ranking model modified for the use of searching for different fragments used for the institute purpose for example files like images, documents, videos for a specific topic i.e., video lectures of the staff in the institution. An enhanced ranking model moderates the search results to the data from a particular domain which apply to the search terms given by the user who search in local database developed. Ranking order determined by placing a statistical score and numerical score the judgment was done which is relevant or not. In this enhanced ranking model we fabricate a model application for the institution purpose which is utilized to test the estimation of the domain. The observed comes about uncovered that the proposed enhanced ranking model process is fit for adjusting the outcomes to the new domains.
Keywords:
-Ranking, search result, Video lectures, Local database server, views of file type.---
Date of Submission: 06 -11-2017 Date of acceptance: 16-11-2017
---I.
INTRODUCTION
Basically searching is a process of identifying some user intended topics from a wide set of documents. Here specific topics are searched from a set of documents which return to a list of recordswhere the keywords are set up. By giving a word or domain which is only a keyword, the web search will gives the pages of that particular topic. The large related documents are at the first of the rundown of a query item. However, it is dependable not the right one. The data has in the wide range search results are might be the master in site pages, pictures. The enhanced ranking model is a learning-based information reclamation strategy, which is expertise in giving the ranking to the records with their appropriate input feedback, comments and views from the user to some file types like images, documents, videos and other file types for the purpose of institute or organization. Before there is only a domain which is a copy of the image is given a ranking, but in the enhanced ranking model we are ranking to different file types like images, documents, and videos especially the video lectures of the staff which is stored in database of the institution.
utilized for ranking adjustment. For example, an enhanced ranking model adapting is more proficient for ranking from the feedback and views of the users in the organization.
II.
LITERATURE SURVEY
Before understanding the enhanced ranking model, we should know the background of the ranking models how they are developed and worked. Though there is already a wide literature on ranking models, there are distinct parts of work. However, most of them had a mutual thread, i.e., all are almost either broad-based or domain specific search. The broad-based search services cannot cope with the new domain quickly, and the approach to particular domain search cannot adapt to new domains. In this section explores the various expansions and inventions on ranking models for search in local database. Every one of those web search manages the data recovery typically [1], [2]. These ranking models have certain limits. Due to this reasons, they cannot adjust & adapt to new domains. Thus, this is the reason because there is a need for specific parameters which ought to change and the past logic doesn't work with the new datasets. There are many ranking algorithm and algorithms as for ranking were found in writing [1], [3], [4], [5] and [6]. As of late [25] displayed a system which had worked in ranking model adaptation component which changes to the distinctive domains without altering the essential ranking model. The new datasets are utilized to work with that input for ranking. That doesn't mean for the users who can switch amongst domains and with a similar work for the particular space hunt.
A. Ranking Model Survey
There have already taken significant works on ranking model adaptation. A considerable lot of the web users rely upon search for mining data by giving a catchphrase of any region. In this section, we find the wide literature survey on the current data based image retrieval strategies based on concerning the highlights enhancement methods and descriptor. Thus, search process for those keywords and provides a specific information retrieving or by mining algorithms applied to attain a cluster of documents which are related to the query or keyword given by the user. After the mining or recovering from the reports and materials, there is a list where the documents are the best ones, and topmost which considered as more significant records of the rundown is called ranking of the papers.
Mainly there are two sorts of ranking models already named as static ranking models and the second one is dynamic ranking models. Earlier days the ranking algorithms were depended on past data about websites. Few examples of static ranking models algorithms are Salsa, List Net, Hits, Rank net, and Frank. These models used only the static information of web pages and termed as Static Ranking Algorithms. The dynamic ranking is a way of the combine or recalls the high goals of results to provide the results. These two algorithms interact with the users and know the intent of various possible purposes, or also they try to reorder the first retrieved results and provide the superior results to the users. It has an emphasis on both the diversity and relevance’s.
For different applications, the ranking applied for example. [7] Had proposed a system that uses only content and image-based attention ranking. Similarly [8] has invented a model for the web as Hubs based upon an eigenvector computation on the network of an internet.
B. Learning To Rank
There was a significant methodology called Learning to rank was proposed by [9] in (2001), [10] in (2002) & [11] in (2002) which are few examples of work on Learning to rank model. There is a technique which alluded to Ranking SVM is proposed by [12] in (1998) which performs the duty same yet by Boosting. [13] In (1999) had suggested contracting the approach and utilize the SVM techniques to manufacture the arrangement ranking model. [14] In (2005) had likewise actualized the method and created Rank Net method. [15] [16] in (1999, 2002) has established Ranking SVM to report recovery. [17] In (2006) likewise adjusted the Ranking SVM for archive recovery by changing the capacity. In the same way [18] in (2007) also developed on Ranking SVM model which is a method of preparing a document paired for training by the clicks of users through data.
C. Probability of Ranking Models
The probability models in statistics used for representing the list of ranking the methods and objects for estimating the models have been developed by [19] in (1975) and [20] in (1959) which described on probability models on the list of ranking the objects. Further they proposed for estimating the ranking models. They represented a list wise approach for the document retrieval. Using super script denote the keyword and the subscript which indicates the identifier of a document or a report.
called List Net. Here, [21] in (1979) proposed F-measure or F-score which is used to measure the current evaluation where ass also used to measure IE algorithms such as a search developed by [22] in (2006). [23] In (2009) researcher often also uses mean the standard, accurate method which is used to define as the mean of multiple information retrieval lists of results. [24] In (1938) also invented a correlation measure which is used to measure and evaluate ranking order results. In this, the method is used to measure the number of elements which are paired with the references and hypothesis list and check whether the element position correlated with the formula and functions. Kendall's primary choice is to rank evaluation. But there are some drawbacks in this for evaluating measures of the ranking to a particular document and there results. But this survey covered the various researches and the information based image retrieval but faced the same problem between the image query and the retrieved image and the similar results.
D. Ranking SVM
Here the Support Vector Machines(SVM) for the gathering issue [25], the motivation of Ranking SVM is to build up the one-dimensional linear subspace, where every one of the focuses can set requested into a solitary ideal positioning rundown which under specific criteria. At last the positioning capacity continues as straight model by which the culmination of the positioning rundown is organized by the expectations of the function capacity f which is invariant to the inclination.
Here the function capacity F is the straight model by which we can determine and mean the contrast between the archive sets. On the off chance that we present the double name for match of records the Ranking SVM issue can be seen as an SVM for deciding the report sets into rank outcomes. Along these lines, the measure of the marked trials taken from the new area is little and if we prepare and mastermind the model by utilizing the new domain and there measures in the new space. To settle the SVM it requires the super-quadratic computational cost of making tests as an esteem or result, and it is time taking and hard to prepare the models by utilizing the prepared information from the spaces. Therefore the issue is higher via preparing the positioning SVM which depend on the sets thus the effect is quadratic to gauge the span of the test.
Proposed methodology
Architecture:
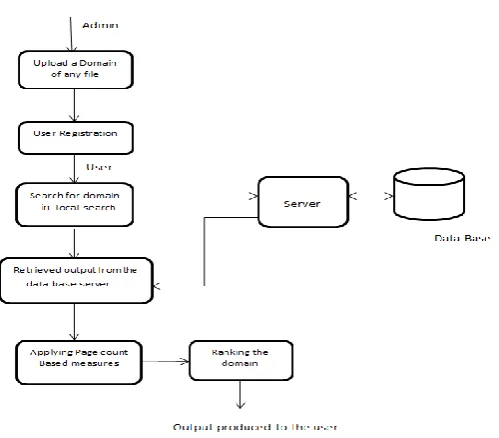
Figure 1
Fig. 1 demonstrates the proposed model, which depicts the approach and system of the model. At the point when a user inputs a keyword to searcher, the user gets the outcomes from index database server which are the consequences of positioned comes. The positioned rundown of the issues may have diverse responses for an only question or catchphrase which are not applicable to the user. In any case, the proposed demonstrate gives the positioned or ranked outcomes and apply proposed arrangement, which offers the labelled findings to the user in less time and that is more important and relevant.
There is the ranking of file types like image, document and also videos.
Applying the page count based measures.
Output results from the database server search to the user.
The proposed algorithm exceptionally assessed on communicated video lectures. The Ranking models can apply to a domain-specific search that is of any file. Due to the volatile need of specific search domains, applications of the wide-range ranking model straightforwardly to various domains is not any more attractive because of the space contrasts, so working of a single ranking model for every domain is both difficult for marking the information and furthermore tedious to preparing the models. To address these difficulties [26], Bo Geng proposed a regularization-based algorithm called ranking adaptation SVM. In this paper, over which we can adjust a current ranking model to another new domain ranking model, with the goal that the amount and nature of named information and the preparation cost lessened amid the execution is positive and ensured. In this upgraded enhanced ranking model the algorithm requires the predictions from the current ranking models, as opposed to their information from secondary domains. What's more, we observe that the archives having similitudes in the area particular component ought to have steady and dependable rankings, and include a few impediments for controlling the outcome which ought to be limited. At last, upgraded, the enhanced ranking model is proposed to quantitatively assess if a current ranking model can adjust to another new domain by the expectations and predictions.
A. Proposed Algorithm Methodology
The Proposed algorithm demonstrates the total procedure of getting the domain from the obscure dataset. Stage 1: Input the obscure domain as search content.
Preparing Phase: Step 2: Select the domain which needs to develop.
Stage 3: Upload the linked words and sentences (phrases) to an individual domain.
Testing Phase Step 4: Calculate the no of views or perspectives and the recurrence of a term and which is stated separately on given database record or archive.
Stage 5: Apply the Prediction based algorithm to get the likelihood of an event of various terms and stated. Stage 6: Compare just those domains, which are having the high likelihood of the event with preparing domain. Stage 7: Display the grouped domain in light of some perspectives by the user count and check.
Here we think about the proposed RA-SVM construct technique concerning different individual scores, checks and no of perspectives from the informational collection. We also utilize polynomial, i.e., quadratic, linear and radial base functions (RBF) kernels for the positioning SVM. Likewise, the Mean Reciprocal Rank (MRR) and AP [27] are utilized to assess the unique systems. By and large, the proposed strategy separates most information search results from the no of views and counts measured manually from the users from the dataset.
IV.FRAMEWORK OUTCOME ANALYSIS
The given area gives the depiction of the working or utilitarian viewpoints and results that show productivity of the framework of the system. A UI Simple query output page which demonstrates the ordered outcomes, that uses the predictable algorithm. Here, we illustrate the basic output pages, when a user gives a question or a keyword to the framework, another JSP page is showing up on the screen. The Java server page demonstrates the outcome for the keyword or a domain java in equipment grouping. This page contains a sidebar with the classifications. The entire framework planned in two unique modules, i.e., first the preparation procedure and afterward the following is the testing procedure. Pre-preparing is likewise fragrant to play out the new operation in the proposed framework.
V.CONCLUSIONS
REFERENCES
[1]. R. Herbrich, T. Graepel, and K. Obermayer, "Large Margin Rank Boundaries for Ordinal Regression," Advances in Large Margin Classifiers, pp. 115-132, MIT Press, 2000.
[2]. Y. Freund, R. Iyer, R.E. Schapire, Y. Singer, and G. Dietterich, "An Efficient Boosting Algorithm for Combining Preferences," J. Machine Learning Research, vol. 4, pp. 933-969, 2003.
[3]. C.J.C. Burges, R. Ragno, and Q.V. Le, "Learning to Rank with Nonsmooth Cost Functions," Proc. Advances in Neural Information Processing Systems (NIPS '06), pp. 193-200, 2006.
[4]. C.J.C. Burges, T. Shaked, E. Renshaw, A. Lazier, M. Deeds, N. Hamilton, and G. Hullender, "Learning to Rank Using Gradient Descent," Proc. 22th Int'l Conf. Machine Learning (ICML '05), 2005.
[5]. Z. Cao and T. Yan Liu, "Learning to Rank: From PairwiseApproach to Listwise Approach," Proc. 24th Int'l Conf. Machine Learning (ICML '07), pp. 129-136, 2007.
[6]. W. Dai, Q. Yang, G.-R. Xue, and Y. Yu, "Boosting for Transfer Learning," Proc. 24th Int'l Conf. Machine Learning (ICML '07), pp. 193-200, 2007.
[7]. Huang-Chia Shih, Jenq-Neng Hwang, Fellow, and Chung-Lin Huang, "content-based attention ranking Using Visual and Contextual Attention Model for Baseball Videos," IEEE Transactions on Multimedia, vol. 11, NO. 2, Feb 2009.
[8]. Jon Kleinberg. Authoritative sources in a hyperlinked environment. In Proceedings of the Ninth Annual ACM-SIAM Symposium on Discrete Algorithms., 1998.
[9]. Crammer, K., & Singer, Y. (2001). Pranking with ranking Proceedings of NIPS 2001.
[10]. Shashua, A., & Levin, A. (2002). Taxonomy of large margin principle algorithms for ordinal regression problems. Proceedings of NIPS 2002.
[11]. Lebanon, G., & Lafferty, J. (2002). Cranking: Combining rankings using conditional probability models on permutations. Proceedings of ICML 2002.
[12]. Freund, Y., Iyer, R., Schapire, R. E., & Singer, Y. (1998). An efficient boosting algorithm for combining preferences. Proceedings of ICML 1998 (pp. 170–178).
[13]. Herbrich, R., Graepel, T., &Obermayer, K. (1999). Support vector learning for ordinal regression. Proceedings of ICANN 1999.
[14]. Burges, C., Shaked, T., Renshaw, E., Lazier, A., Deeds, M., Hamilton, N., & Hullender, G. (2005). Learning to rank using gradient descent. Proceedings of ICML 2005.
[15]. Joachims, T. (1999). Making large-scale support vector machine learning practical. Advances in kernel methods: support vector learning.
[16]. Joachims, T. (2002). Optimizing search engines using clickthrough data. Proceedings of KDD 2002. [17]. Cao, Y. B., Xu, J., Liu, T. Y., Li, H., Huang, Y. L., & Hon, H. W. (2006). Adapting ranking SVM to
document retrieval. Proceedings of SIGIR 2006.
[18]. Qin, T., Liu, T.-Y., Lai, W., Zhang, X.-D., Wang, D.-S., & Li, H. (2007). Ranking with multiple hyperplanes. Proceedings of SIGIR 2007
[19]. Plackett, R. L. (1975). The analysis of permutations. Applied Statistics, 24(2). [20]. Luce, R. D. (1959). Individual choice behavior. Wiley.
[21]. Rijsbergen, C. J. V. (1979). Information Retrieval. Butterworth-Heinemann, Newton, MA, USA, 2nd edition.
[22]. Peng, F. and McCallum, A. (2006). Information extraction from research papers using conditional random fields. Inf. Process. Manage., 42(4):963–979, July.
[23]. (2009). Mean Average Precision. In LING LIU et al., editors, Encyclopedia of Database Systems, pages 1703– 1703. Springer US.
[24]. Kendall, M. G. (1938). A New Measure of Rank Correlation. Biometrika, 30(1/2):81–93, June. [25]. V. N. Vapnik. Statistical Learning Theory. Wiley-Interscience, 1998.
[26]. Bo Geng, Linjun Yang, Chao Xu, and Xian-Sheng Hua, "Ranking Model Adaption for Domain-Specific Search," IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 24, NO. 4.
[27]. R. Baeza-Yates and B. Ribeiro-Neto, Modern Information Retrieval. ACM Press/Addison-Wesley, 1999.