© 2015, IRJET ISO 9001:2008 Certified Journal Page 745
A Survey on Uniminer Frame Slog for Data Mining
Ms. Ashwini A. Kale, Prof. S.K.Korde
ME(Student), CSE, PREC,Loni,Maharastra,India
Assit.Professor,PREC,Loni,Maharastra,India
---***---
Absract:
In this paper, we analysis the background and state-of-the-art of large data. We first introduce the general background of big data and appraisal related machineries. Now days Wearable devices and Smart phones produce huge data streams in universal and ubiquitous environments. Usually, big data systems gather all the data at a central data processing system (DPS). These data storage tower are additional analyzed to create approximated patterns for different claim areas. This attitude has one-sided value (i.e. at big data treating end) but two main side-possessions that main towards user’s displeasure and added computational costs. These effects are:1) since all the data is being collected at central DPS, user privacy is compromised and 2) the gathering of vast rawdata streams, most of which could be unrelated, at dominant systems required more computational and packing resources hence rises the overall operative cost. Possession in view these limitations, we are proposing a unified structure that balances between value and cost of big data system with improved user satisfaction. We studied different data mining organisms and planned a new framework, named as UniMiner, to impact datamining systems with wearable strategies, smartphones, and cloud computing technologies. The idea of UniMiner is the scalability of data mining tasks from source-restraint devices to collective and mixture execution models. This accessible unified datamining method differentiates UniMiner from existing systems by enabling maximum data processing near data sources. Finally, we assessed the viability of mobile devices using six common pattern mining algorithms. The outcomes show that mobile devices could be accepted as data mining platforms by alteration some extra parameters.Keywords-cloud computing, data mining, smartphones,
wearable devices.
I.Inroduction:
Now a days we are using great quantity Wearable
strategies, smartphones, Internet-of-Things, and
computing technologies are key-enablers for big data group and inquiry. MIT technology review [1] informed that 95% of the data generated these days rests
© 2015, IRJET ISO 9001:2008 Certified Journal Page 746 Fig.a)Onboard Sensor and Wearable Devicesb)Resource
Constraint Environments
c)Collaborative Data Processing System
d)Cloud enable Data Processing System
II.Related Work:
The idea of procedureing data near the sources is gaining popularity and highlighting the importance of mobile distributed analytics platforms. These stages are required to be capable sufficient to integrate all types of donors as presented within a unified data mining stand. The literature review shows the arrival of multiple platforms used at different stages from on-board sensors to resource forced atmospheres to collaborative and cloud DPSs.
The computational limitations in on-board detecting devices highlight the importance of IDs-founded DPS for Local Analytics (LA). The IDs gather data from native sensors and near-by on-board sensing devices and process it locally. For example, OMM [4] and CAROMM [5] enable LA by actingall KD process inside mobile phones. Similarly, StreamAR [6] procedure data streams locally privileged mobile phones and expose action patterns from on-board accelerometers. Although, IDs are well adopted as LA platforms but resource-restraints bound to the growth of Lightweight algorithms in adaptive atmospheres. Hence, either the correctness or timeliness of the exposed patterns has to be conceded. We are presenting a possibility study in this paper to find the chances of executing full algorithms in addition with light-weight algorithms. Furthermore, the efforts to happen the resource-restraints and expose maximum related patterns are made newly in the literature. Three different design considerations were proposed to manage with these subjects.
First, make a collaborative peer-to-peer ad-hoc network of the strategies in area and offload LA jobs in the network. For example, PDM [7], a multi-agent based data mining systems, works in collaborative environments. Different intelligent mediators are used for resource-findings, data mining, and conclusion making in the PDM workflow to competently utilize the resources in collaborative situation. The agility of devices and assets restraints in collaborative environments can reduce the performance of the system. Hence, resource finds and scheduling are the key issues that need to be bound in collaborative data mining structures.
Second design fear is to perform some LA jobs inside resource-constrained environments (local and/or collaborative) and offload to near-device cloud tools supported architectures. CARDAP [8] uses the same policy. It performs LA as well as uses Fog cloud services [9] to gain more computational controls. CARDAP proposed an effective data uploading plan called Local Analytics + Smart Data Reduction + On-demand Sensing (LA-DR-OS). The purpose of LA-DR-OS is to act LA and upload data to Mist when a significant change is detected. It should be noted that Fog computing is immobile at its first stage providing cloud computing resources near data sources. Hence, there is an chance for creating privacy-preserving data mining schemes in ubiquitous environments that provision both big data mining and LA.
Third design thought is the enablement of cloud built data analytics for mobile devices. Mobile devices upload full rare facts streams to mobile clouds. The KD is done using cloud services and the outcomes are sent back to the device. For example, Mob Safe [10] delivers cloud built data mining services for legal analysis in mobile tenders. Cloud computing skills provide hugely parallel computing structures to analyze big data but the user wants to pay for each computational series. Hence, LAs based system that provision LA-DR-OS could develop the key factors to reduce economic burden of using cloud built analytics.
As we have seen all of these DPSs has some assets and limits as summarized in Table-I. Hence, a corrects ability between all these causative devices and schemes is needed to deliver a actual DPS that guarantee user privacy and LA at user-end and lower computational and economic load for big data systems.
TABLE I MODERN ANALYTICS PLATFORMS
System Strengths Limitations
© 2015, IRJET ISO 9001:2008 Certified Journal Page 747 weight
local analytics stage full
fledged algorithms and
ropes single
device as
a data mining stage
CAROMM The postponement
of OMM
to setting-aware and realtime
analytics
Limitations are
same as
OMM
PDM Adaptive,
collaborative,
light-weight, scalable ,
and analytics
platform,
supports
agent-oriented
data mining
Lack of resources in noble
devices and
mobility are
major limitations. PDM
everything with
devices in
locality only. The need
to harness PDM with
back-end
influential system
arises
CARDAP The extension of
CAROMM
to Fog cloud
services,
support to IoTs
and heterogeneous networks
Privacy concerns essential to
be addressed. In addition,
cost of utilizing cloud services
may outweigh the
available utility cost
We are proposing a unified outline called UniMiner to address the limitations of existing systems and provide a one-piece data mining approach to meet analytic supplies in big data environments.
III. Proposed FrameWork:
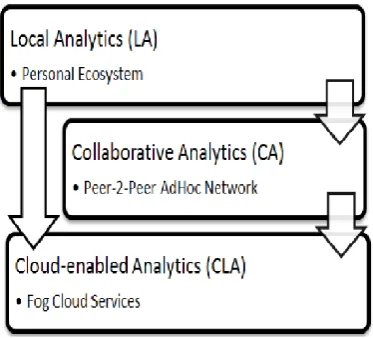
[image:3.595.317.504.260.429.2]This proposed framework system is based on three layers supporting that layers are 1) local analytics, 2) collaborative analytics and 3) cloud allowed analytics. The abstract view of UniMiner is presented in Figure-1.
Fig. 1. Layered Architecture (UniMiner)
There are Different Modules which involved in fig.1 Explain bellow:
A. Local
Analytics(LA):-The LA layer in UniMiner is fictional to be the main funder for privacy and data decrease in big data environments. This layer is depend on Personal Ecosystem (PE), where a user can utilize all computational resources, communication services, and storage elements rendering to P4 strategy. A PE is depend on four modules for 1) knowledge discovery, 2) knowledge management, 3) system management and 4) visualization.
B. Collaborative Analytics(CA):-
© 2015, IRJET ISO 9001:2008 Certified Journal Page 748 mining jobs and PEs in applicant devices whole the KDP
and send the grades to actuator which is the AE in PE of demanding device. In case of no-reply from applicant device in a specific time break, AE destroys the job and re-assigns the errands to other candidate devices. In the nonappearance of any candidate device, AE, at demanding device, schedules/sends the data torrents to Fog cloud.
C. Cloud-enabled Analytic(CLA):-
Fog cloud technology, newly presented by Cisco, is the enablement of cloud services near data sources. Cisco describes Fog as a three tier DPS. The basic motive is to enable Internet of Things (IoTs) based infrastructures to aggressively participate in big data situations. Fog allows to connect with all types of devices, systems and ‘things’ that produce digital data. Moreover, the obtain ability of computational power close data sources enable to process the data originally which lowers the computations and vigour consumption at the central big data system. Fog could be adopted as a whole substitute of UniMiner, as obtainable in CARDAP, but privacy and financial burdens are still the chunks to receive the computing on-the-edge presage. UniMiner utilizes Fog services to meet the extra-ordinary computational wants of sensors’ data stream mining algorithms for processing incessant data streams. Additionally, the CA layer in UniMiner more decreases raw data streams hence dropping overall uploaded data in big data ecosystem. We are highly interested to yoke Fog cloud services in the UniMiner but more details of the proposed layer are not in the scope of this paper.
D.Phases and pattern used in frame :-
We have divided our work in three phases: 1) We have divided our work in three phases: 1) assessing
the feasibility of mobile devices as a data mining stage to leverage data deduction in big data environment, 2) the development of UniMiner’s LA and CA layers and testing with actual data groups and 3) the Fog cloud facilities will be crafted and a actual-world crowed sensing application will be established. We will then check the UniMiner for privacy preservation and data decrease. The tests will be achieved by analyzing data in two modes: a) using UniMiner and b) straight in large data environment. So far, we have finished the first stage andfound adequate results to adopt mobile devices as a data mining stage for weighty algorithms.
We selected six traditional recurrent pattern mining algorithms specifically Apriori and AprioriTid [12], Relim [13], FP-Growth [14], Eclat[15] and dEclat[16]. The algorithms are selected from Sequential Pattern Mining Framework (SPMF) archive [17] and realised in Java. The application is deployed in android
4.2 depend Samsung phone and the tests were frequent for 5 times with each input groups. The input set covers minimum support (minsup) verge value anddata set file containing transactions.
IV. Conclusion:
Big data systems gather raw data stream from handlers in mass sensing applications. A big number of data streams are not valuable that puts a vast computational and economic burden on large data organisms. In addition, the huge collection of data made privacy concerns that are wanted to be addressed by large data systems. To this end, we planned a three layer framework, called UniMiner, for data reduction in big data surroundings and delivery of privacy preserving services to handlers. The framework is planned in such a way that user can perform whole KD process in resident device. In case of resource shortage, data mining jobs could be divested to other devices in nearness or utilize Fog cloud services. In this study, we estimated six recurrent pattern mining algorithms in mobile devices and originate acceptable grades. In future, we will further our work by mounting LA and CA layers for data reduction. Moreover, we will craft fog cloud services for fully yoking privacy-preserved data reduction in big data structures that will provision P4 strategy which is our ultimate goal in this research.
REFERENCES
[1] MIT Review, “A business report on big data gets personal,” SAPBusiness, Tech. Rep., 2013.
[2] M. Chen, S. Mao, and Y. Liu, “Big data: A survey,”
Mobile Networksand Applications, vol. 19, no. 2, pp. 171–
209, 2014.
[3] S. Krishnaswamy, J. Gama, and M. M. Gaber, “Mobile data stream mining: from algorithms to applications,” in
Mobile Data Management(MDM), 2012 IEEE 13th
International Conference on. IEEE, 2012,
pp. 360–363.
[4] P. D. Haghighi, S. Krishnaswamy, A. Zaslavsky, M. M. Gaber, A. Sinha,and B. Gillick, “Open mobile miner: a toolkit for building situationawaredata mining
applications,” Journal of Organizational Computing
and Electronic Commerce, vol. 23, no. 3, pp. 224–248,
2013.
[5] W. Sherchan, P. P. Jayaraman, S. Krishnaswamy, A. Zaslavsky, S. Loke,and A. Sinha, “Using on-the-move
mining for mobile crowdsensing,”in Mobile Data
Management (MDM), 2012 IEEE 13th International
Conference on. IEEE, 2012, pp. 115–124.
© 2015, IRJET ISO 9001:2008 Certified Journal Page 749 learning with evolving sensory datafor activity
recognition,” in Tools with Artificial Intelligence (ICTAI),
2012 IEEE 24th International Conference on, vol. 1. IEEE,
2012, pp.1163–1170.
[7] M. M. Gaber, F. Stahl, and J. B. Gomes, “Pocket data
mining framework,”in Pocket Data Mining. Springer,
2014, pp. 23–40.
[8] P. P. Jayaraman, J. B. Gomes, H. L. Nguyen, Z. S. Abdallah, S. Krishnaswamy,and A. Zaslavsky, “Cardap: A scalable energy-efficientcontext aware distributed mobile data analytics platform for the fog,”
in Advances in Databases and Information Systems.
Springer, 2014,pp. 192–206.
[9] F. Bonomi, R. Milito, J. Zhu, and S. Addepalli, “Fog computing and itsrole in the internet of things,” in
Proceedings of the first edition of theMCC workshop on
Mobile cloud computing. ACM, 2012, pp. 13–16.
[10] J. Xu, Y. Yu, Z. Chen, B. Cao, W. Dong, Y. Guo, and J. Cao, “Mobsafe:cloud computing based forensic analysis for massive mobile applicationsusing data mining,”
Tsinghua Science and Technology, vol. 18, no. 4,
2013.
[11] C. Setz, B. Arnrich, J. Schumm, R. La Marca, G. Troster, and U. Ehlert,“Discriminating stress from
cognitive load using a wearable eda device,”Information
Technology in Biomedicine, IEEE Transactions on, vol.
14,no. 2, pp. 410–417, 2010.
[12] R. Agrawal, R. Srikant et al., “Fast algorithms for mining associationrules,” in Proc. 20th int. conf. very
large data bases, VLDB, vol. 1215,1994, pp. 487–499.
[13] C. Borgelt, “Keeping things simple: Finding frequent
item sets byrecursive elimination,” in Proceedings of the
1st international workshopon open source data mining:
frequent pattern mining implementations.ACM, 2005, pp.
66–70.
[14] J. Han, J. Pei, Y. Yin, and R. Mao, “Mining frequent patterns withoutcandidate generation: A
frequent-pattern tree approach,” Data miningand knowledge
discovery, vol. 8, no. 1, pp. 53–87, 2004.
[15] M. J. Zaki, “Scalable algorithms for association
mining,” Knowledge andData Engineering, IEEE
Transactions on, vol. 12, no. 3, pp. 372–390,2000.
[16] M. J. Zaki and K. Gouda, “Fast vertical mining using
diffsets,” inProceedings of the ninth ACM SIGKDD
international conference onKnowledge discovery and data
mining. ACM, 2003, pp. 326–335.
[17] P. Fournier-Viger, “Spmf: A sequential pattern
mining framework,” URLhttp://www.
philippe-fournier-viger. com/spmf, 2011.