International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)253
Review of Attacks on Databases and Database Security
Techniques
Mr. Saurabh Kulkarni
1, Dr. Siddhaling Urolagin
2 1M.Tech (CSE) Student, Department of Computer Science and Engineering,Manipal Institute of Technology, Manipal-576104.
2
Department of Computer Science and Engineering,Manipal Institute of Technology, Manipal-576104.
Abstract —Data is most important in today’s world as it
helps organizations as well as individuals to extract information and use it to make various decisions. Data are generally stored in database so that retrieving and maintaining it becomes easy and manageable. All the operations of data manipulation and maintenance are done using Database Management System. Considering the importance of data in organization, it is absolutely essential to secure the data present in the database. In this paper, concise review of major database security techniques along with their usage is presented.
Keywords — Database, SQL injection attack, Access Control, Encryption, Data Scrambling.
I. INTRODUCTION
Data is the major component on which entire organization depends. This dependency is so intense that success and failure of organization’s goals relies on the quality and quantity of data. So naturally organizations can’t afford to lose vital data present about the organization and its business. Major chunk of data are stored in the repository called database [6][17]. The data stored in databases will be structured and generally stored in the form of relational tables as most of the organizations use relational databases. As relational data model is used, data stored in different relational tables are related to each other. Database Management System (DBMS) is a set of applications which help in managing data present in the database [1]. It helps to organize data for better performance and faster retrieval by maintaining indices. It helps preserving logs of transactions which help in recovering data. DBMS performs the function of concurrency control. DBMS also performs data recovery operations of database.
As data stored in databases may be critical, it is important to secure it. Database can be attacked in many
ways. There is a possibility of attacking data stored in
databases as databases are interfaced with some applications and by hampering the applications; it is possible to attack databases.
The situation becomes critical when users of database are leaking the information to outside world. Computer Security always addresses three important aspects of computer related system namely Confidentiality, Integrity and Availability. Confidentiality ensures that computer related assets are accessed only by authorized users. Integrity means computer assets can be modified by authenticated users in the authorized ways. Availability ensures that assets are accessible to authorized users at appropriate times [1]. Database is a computer asset so confidentiality, integrity and availability should be considered before applying any security policy on database systems.
There are some security requirements for a database like physical, logical and element integrity along with auditablity, access control, user authentication and data availability [1].Physical database integrity deals with physical problems related to database like power failure. So a database should be recovered from such kind of failures. Logical database integrity deals with maintaining and preserving structure and relations in a database. Element integrity preserves the accuracy of data elements. Auditablity ensures tracking of changes done in the database along with the users who did them is possible. Access Control means a user is allowed to access only authorized data. There are different modes of access on different data items. User authentication deals with verifying the user’s credentials before giving access to any of the data objects present in the database. Once authenticated, data should be available to users of the system as per their access rights. This feature is called data availability [1].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)254 II. TYPES OF ATTACKS ON DATABASE
[image:2.612.100.256.238.623.2]Databases today are facing different kind of attacks. Before describing the techniques to secure databases, it is preferable to describe the attacks which can be performed on the databases. The major attacks on databases can be categorized as shown in Fig. 1, which is inference, active and passive attacks in databases and SQLIA. These attacks are further elaborated in the following sections.
Figure 1: Types of Attacks on Databases
A. Inference
Inference is a major attack on database systems. Inference is a way to derive sensitive data from non sensitive data [1]. There is a direct attack possible on database.
The query fired is very much specific in this type of attack. The query matches exactly one data item. Indirect attacks on database under inference include use of statistical data to get the sensitive information. There are many ways to have this attack. An attacker may try to infer sensitive information from sum of some values usually used in the reports. Count can be used to along with Sum function to get sensitive information. These two are commonly used functions as DBMS provides them by default as aggregate functions. Attacker can use medians as statistical measure to determine the actual sensitive value. But this process is slightly difficult. So attacker finds selections having one point of intersection which is exactly in the middle. There is another possible attack under inference and that is called Tracker attack. In tracker attack, a desired data can be recorded using additional queries that produce small results. Attacker adds additional records to be retrieved for two different queries such that two sets of records cancel each other out and only desired data is left. There is a more general form of a tracker attack called linear system vulnerability. This attack requires little algebra and logic to find the data distribution in a database and use it to find the desired elements. So instead of using two opposing query sets, a series of query sets are used which will cancel each other and finally desired information is found [1].
B. Passive Attacks on Databases
Attacks on database can also be classified into passive and active attacks [2]. In passive attack, attacker only observes data present in the database. Passive attack can be done in following three ways:
Static leakage: In this type of attack, information can be obtained from a database by observing snapshot of it.
Linkage leakage: Here, information about plain text values can be obtained by linking table values to position of those values in index.
Dynamic leakage: In this, changes performed in database over a period of time can be observed and information about plain text values can be obtained.
C. Active Attacks on Databases
In active attack, actual database values are modified. This is a serious kind of attack. There are some ways of performing such kind of attack which are mentioned below:
Spoofing: In this type of attack, cipher text value is replaced by a generated value.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)255
Replay: Replay is a kind of attack where cipher text value is replaced with old version previously updated or deleted [2].
D. SQLIA (SQL Injection Attack)
Today, databases serve as a backend for many applications including web applications. One of the major attacks with such applications is SQL Injection Attack. This type of attack is often abbreviated as SQLIA or SIA. Many web applications use on the fly SQL queries without applying proper user input validation. This is the basic reason for SQLIA. Attackers can make server run malicious SQL queries and can manipulate the database. Therefore SQLIA is considered as dangerous type of attack on databases [3].
SQLIA can be classified into following five types:
Bypassing web authentication: Here, attacker uses the input field which is used in the query’s where condition. Such as attacker writes a query similar to ―Select name from User_tbl where user_nm=’ ’ or 1=1- - ' and pwd=’ ’ ‖. Because of - - text after that will be commented and 1=1 is always true so user will be logged with privilege of first user stored in the User_tbl [4].
Database Fingerprinting: In this type of attack, attacker generates logically incorrect queries or illegal queries. This causes DBMS to throw error messages. These error messages usually contain names of database objects used like tables, stored procedures, views etc. From the error message attacker can guess the database used by the application as different databases have different style of reporting errors [4].
Injection with the union query: Here, attacker gets data from a table which is different from one that was intended by developer. E.g. Select * from User_tbl where user_nm=' ' UNION select address from user_dtl where user_id=123-- and pwd='1t@d'. So here, address of user_id 123 is displayed [4].
Damaging with additional injected query:In this type of attack, attacker enters input such as additional query along with the original query is generated. Example of such attack can be use of queries like drop table table_nm or delete from table_nm etc. in the input fields which will generate these queries along with the original query [4].
Remote execution of stored procedures: Here, attacker executes some stored procedures which may have some harmful effect after execution [4].
Apart from these major attacks, legitimate user can take the advantage of the access rights given to him/her can expose the sensitive information to attacker or illegal users of the system either within or outside the organization. Such kinds of database attacks are dangerous in case of defense organizations as the data stored are extremely sensitive and can trigger large amount of destruction. Even commercial organizations like manufacturing firms, financial firms and banks etc. have large amount of sensitive information which can be used by attacker for illegal means. It may cause harm to organization from profit perspective as well as it may be harmful to the customers of such organizations. The following section reviews some of the database security techniques generally used to tackle or avoid such kind of attacks on databases.
III. DATABASE SECURITY TECHNIQUES
To implement any security solution for a computing system, organization must ensure three aspects namely policy, mechanism and assurance. The requirements that must be implemented in hardware, software and outside the computing system are defined under policy. Proper mechanism to implement the requirements discussed in the policy is indispensable for an organization to have good computing security solution. Assurance is to ensure that mechanism meets the policy requirements of the organization [5].
International Journal of Emerging Technology and Advanced Engineering
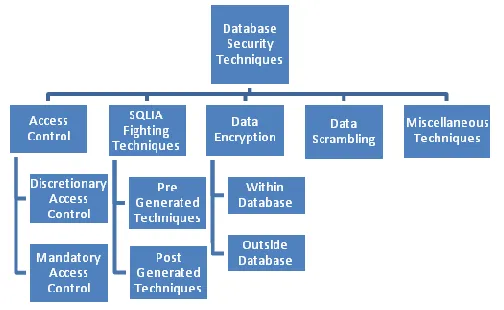
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012) [image:4.612.46.298.169.324.2]256 Figure 2 Database Security Techniques
A. Access Control Mechanisms
Access Control Mechanism is a technique to maintain data confidentiality. When someone tries to access data object, Access Control Mechanism checks the rights of the user against set of authorizations. They are generally specified by security administrator or security officer. Authorizations are given as per the security policy of the organization. Along with Access Control Mechanism, A strong Authentication mechanism is also required to authenticate the valid user of a database system. After that access control will help defining different access permissions on different data objects of a database [6].
There are some proposed models for access control in relational database systems. These models give approaches for implementing access control in databases.
1) Discretionary Access Control Models: In this approach, depending on user’s identity and authorization rules, access is given to data objects as per some discretionary policies. Main advantage here is users can grant authorization on data objects to other users. Because of such flexibility, this is widely used technique in many organizations. Active entities like users in security system are also called subjects.
Authorization administration is the function of granting
and revoking authorizations. So by authorization
administration, authorizations are entered into or removed from access control mechanism. There are two main types of such administrations.
Centralized administration is the type of administration in which some privileged subjects or users can grant or revoke authorizations. Ownership administration is the one in which creator of the object grants and revokes access to object. Owner can give other users right to grant or revoke some or all the access on the object in ownership administration [5][6].
System R authorization model : The data objects which can be protected under this model are tables and views [5][6]. Associated access modes with this model may be select, insert, update and delete. This model is extended in today’s environment to include additional data objects like triggers. Authorization administration in this model is based on
ownership authorization along with authorization
delegation. The creator of table becomes its owner and he can authorize other users using grant options. Revoke operation considers timestamp changes associated with granted authorizations [5] [6].
There are some extensions to this model. System R authorization model is based on closed world policy so when user tries to access table and no authorization is present in the system catalog, then access is denied for the user. But the drawback of this approach is that lack of authorization at any point of time cannot guarantee any authorization in the future. To overcome this drawback, the concept of negative authorization was introduced. So negative authorization means denial of access to specific data object under given mode. Therefore user with negative authorization won’t get the access in future. Negative authorizations override positive authorizations. Negative authorizations can be used to temporarily block the positive authorizations [6].
In system R model, whenever an authorization is revoked from a user, recursive revocation occurs. So if there is a user having access to a particular table and his access is revoked, then recursively all the users to whom he granted access even their access will be revoked. This is overhead on access mechanism as user can change the role or functionality very often. So this recursive revoke takes place very often. To overcome this drawback, another approach called non- cascading revoke is used. In this approach, after revoking authorizations from a particular user, authorizations granted by that user are not revoked. So with the use of cascading as well as non- cascading authorization options, access control systems become more flexible and can support large number of applications.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)257 Normally, the access is given to user from the time it is granted till the time it is revoked. To allow time based access to users, context based access models can be used. Access is given to user based on time when data are required by the user. The time can also be periodic in nature [6].
Content based access control: In this model, access control decisions should be based on contents of the data [6]. E.g. Customer table has information of all the customers of company. So only those employees, who are related to projects about those customers, should have access to those customers. This approach is generally implemented using views. Protection views are used to support content based access control. Shorthand views are used to simplify query writing. Access policies here can be expressed in high level language. Modifications performed in the data do not require changes in the access control policies. If new data is inserted which satisfies some policy, then it will be automatically as part of data returned by corresponding view [6].
Fine grained access control: This mechanism supports access control at tuple level [6]. Therefore the name is Fine grained access control. It allows granular level of access control. To implement such a scheme, it requires specialization of views. Oracle virtual private Database and Truman model are the examples implementing such access mechanism [6].
RBAC Models: RBAC means Role Based Access Control [6]. RBAC is based on the concept of Roles. Role is a specific function in an organization. In this model, all the authorizations required to perform specific activity or job are granted as per the roles associated with that activity or job. Roles group number of related authorizations, managing authorizations is very much simple in this model. When the user changes function in the in organization, only the permission to play the role associated with previous function needs to be revoked.
Some RBAC contain role hierarchy which allows defining role-sub role relationships. It also allows Separation of Duty constraints so that a user can be prevented from getting many access rights. There are two types of Separation of Duty constraints. Static constraints impose restrictions on role intersections. Dynamic constraints are based on history of role usage by users [6].
2) Mandatory Access Control Model: Mandatory access control is based on the classification of data objects and users [5][6]. Classification is based on the partially ordered set of classes called access classes.
Access class contains Security level and set of categories. Security level represents sensitivity of information [5][6].
Access control in this access model is based on following two principles.
No read-up: User can read only those data objects whose access classes are dominated by access class of user.
No write-down: User can write only those data objects whose access classes dominate access classes of the user.
These principles restrict the flow of sensitive data into data objects at lower or incomparable access classes [6].There are advanced database concepts like object relational and object based databases. These access control mechanisms are modified to suite these databases. Even some models are proposed for XML data [5][6].
B. Techniques to fight with SQLIA
As discussed earlier, SQLIA is the most dangerous attack on databases. This section discusses some of the techniques to detect and prevent SQLIA. The detection approaches for SQLIA can be categorized broadly into pre-generated and post-pre-generated approaches. Post-pre-generated approaches are generally useful while analyzing dynamic SQL which is generated by web application. Pre-generated approaches are generally used during the testing phase of the web application. Some post generated approaches are [4]:
Positive tainting and Syntax aware evaluation: Here, valid input strings are initially provided to system for detection of SQLIA. It categorizes input strings and propagates non trusted strings on fly. Syntax aware evaluation is done on the propagated strings in order to decide the non trusted strings. Syntax evaluation is performed at the database interaction point. There are some issues with this method. Initialization of trusted strings depends on developer and storage of trusted strings may lead to another attack.
Context Sensitive String Evaluation: Here any user given data are considered as non-trusted and application given data are considered as trusted. Non-trusted metadata is used for syntax analysis. This syntax analysis differentiates string and numeric constants. Then all the unsafe characters are removed from alpha numeric identifiers. Some issues in this approach are initialization of unsafe characters is developer dependent and removal of unsafe characters restricts application functionality.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)258 Special literals are used to mark beginning and end of a string. The drawback here is that attacker can manipulate input string by using the special characters.
Some Pre-generated approaches are:
Pixy: Pixy is static analysis tool used to find out the vulnerabilities in web application. It uses data flow analysis to form statistical information for each program point. Parse trees are developed and taint analysis tool is used to identify the points where malicious data can enter the application. The drawback with this tool is it is open source so attacker can attack by exploring the features and finding the vulnerabilities in the tool [4].
Program Query Language: This language is used by web developers to find the attack related queries. It is language having pre-defined grammar. A translation is done from PQL (Program Query Language) to data logs. These logs help the programs to provide support for detecting malicious queries. Again detection of the malicious queries depends on developer input which is used in data logs as well [4].
1) Some new techniques to detect SQLIA: This section describes some of the new approaches to handle SQLIA. DUD [Debasish, Utpal and D.K. Bhattacharya] is one such approach which is categorized under post-generated approach. It has some user defined threshold say e. It has SQL master file (SQLMF) which has list of all the legal queries.
Approximate Matching () algorithm computes the difference between XSQL query and legal queries in SQLMF and compares the difference with threshold e. If it is within threshold, it will allow the query to pass to database server [4].
There are some reasons for the DUD mechanism to be effective [4].It avoids initialization of trusted and non-trusted strings. Matching logic in DUD is easy. SQLMF can be updated. It is Developer independent.
Another interesting approach is SAFELI which stands for Static Analysis Framework for discovEring SQL Injection, its working is represented in Fig. 3.
Figure 3: SAFELI Framework [3]
SAFELI contains following components [3].
Java Symbolic Execution Engine (JavaSye) has two modules. Java byte code instrumentor module inserts additional logic into target java byte code. Symbolic execution engine module is made up of java reflection packages. When a query is fired library of pre set attack patterns is used. From this hybrid string constraint is formed and that is sent to constraint solver. All the pre-defined attack patterns are stored in Library of attack patterns. Attack patterns contain syntax trees of SQL query before and after the attack. Hybrid String Solver tests satisfiability of the constraints. It evaluates the variables satisfying the constraints. Initial valuations of the variables are passed to Test case generator. This module will fill the values in the fields in HTML forms and post back that to server.
JavaSymbolicExe
cutionEngine
Byte CodeInstrument
al
Symbolic
Execution
Engine
Byte
Code
Instrum
nted
byte
code
Test case
generator
String solver
X+"zbc"+y
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)259 It analyzes the response from server. When there is vulnerability detection, a tracing of the errors is performed. Generally SQLIA are done by attaching malicious query to valid query or by commenting some part of valid query and executing malicious query. Symbolic execution gives equation based on the values passed to the query form the web control. String solver uses some heuristic algorithms to evaluate the strings present in the query are attack prone or not. In the figure 3, the query is broken into the equation form as X+ ―zbc‖+ y and each part of the equation can be tested for attacks in the string solver [3].
There is one more approach called application layer intrusion detection which breaks data into buckets as done in network intrusion detection system. Relative frequencies of those buckets are used to compare with the historical data to decide about the intrusion. This model gives weights to unexpected constructs used in the SQL query and which can cause harm to database server or can be seen as intrusion. Those constructs include sub-queries, literals and previously unused keywords in SQL, unquoted values in place of quoted values and unexpected character set.
Even general statistics can be used to identify the malicious query. Those statistical measures include length of the query, frequency of the use of keywords, data types used for particular parameters.
This sub section gave idea about some of the commonly used techniques to handle and detect SQLIA. It also gave some of the new techniques proposed to handle SQLIA. Some of these techniques are under research and require some enhancements. Next sub section gives overview of the most common technique used for data or information security that is encryption.
C. Data Encryption
[image:7.612.47.291.579.639.2]This is the basic technique used for securing any kind of information or data. So this technique can even be applied to databases.
Figure 4: Basic encryption processes
Encryption is a process of translating plain text to encoded form called cipher text. This is usually carried out using secret encryption key and cryptographic cipher.
Figure 2 illustrates the basic process of encryption. Data are encrypted using encryption keys and encryption algorithms. Encrypted data are then stored in the database and decrypted when need to be used for processing purpose. There are two basic types of encryption commonly used. Symmetric Encryption is the type of encryption where a single secret key is used for both encryption and decryption. Asymmetric encryption is the type of encryption where a pair of secret keys is used. One of the keys is used for encryption and the other used for decryption.
While performing database encryption, a decision about whether to perform the encryption inside or outside the database must be taken. Some of the issues involved in this technique are How to secure keys from attacker of the system? How to give administrative rights of manipulating data using keys? And How to provide limited access for keys?
It is also important to provide proper authentication mechanisms because without them, it is easy to get access to keys using social engineering techniques [7].
The important aspects which need to be considered while encrypting database is how to manage the encryption keys. Some of the aspects related to this issue are Number of encryption keys required, storage of keys, protection for the access of keys, and frequency of change of keys
Recommended approach for storing the keys is, separate the keys and data residing in the database. Generally the keys are stored in hardware like access restricted files or hardware storage modules. The process of encryption can be performed either within the database or outside the database. If encryption is performed within the database, then there is less impact on application environment. But there are performance and security tradeoffs which need to
be considered while implementing this policy.
Understanding the encryption algorithm supported by DBMS also plays key role while devising strategy to implement this technique. The drawback of this approach is encryption keys also are stored in the same database.
Another way to implement encryption in database is performing it on separate encryption servers. Encryption and decryption computations are performed encryption server. So here overhead of encryption is removed from DBMS and moved on to separate encryption servers to maintain the performance of DBMS. Encryption keys and data can also be separated. This approach is usually followed while encrypting database [7].The algorithms which are generally used for database encryption and often supported by DBMS are DES, Triple DES, RC2, RC4, DESX and AES.
Data
Encryption key+
Encryption
Algorithm
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)260 The database encryption scheme can be implemented using different approaches. There are two main things to consider while considering database encryption. First thing is granularity of the data to be encrypted or decrypted. Granularity can be field level, row level or page level. Row or page level granularity may lead to encrypting large amount of data which can be overhead on the system. So generally column level encryption of only sensitive data is performed. The second thing is choice of encryption algorithm which is suitable for encrypting given data in database [8].
One encryption system approach describes two phases called initialization phase and run phase. In the initialization phase, all the metadata like the columns to be encrypted, the type and length of the columns, encryption algorithm and encrypted columns on which index is required. Such metadata is stored in the Security Dictionary. It will be loaded into memory first time it is used.
In the run phase of this scheme, the application does the normal activities performed on the database without thinking about encryption. Encryption/decryption engine performs data encryption and decryption based on metadata stored in Security Dictionary [8].
There are various configurations available for encrypting and decrypting databases. Some of them are listed below [2].
File System Encryption: Here the physical disk where database resides is encrypted. Entire database is encrypted using single encryption key so discretionary access control cannot be implemented.
DBMS Level Encryption: There are many schemes for this kind of encryption. One scheme is based on Chinese Remainder theorem in which every row is encrypted using different sub keys for different cells. So encryption at row level and decryption at cell or field level is possible by this scheme.
There are some schemes based on Newton’s interpolation polynomials which are used for database encryption.
There is a SPDE scheme which encrypts each cell I the database with its cell coordinates like table name, column name and row id etc. So in this scheme static leakage attacks and splicing attacks are prevented.
Application level Encryption: In this technique, a middleware is suggested which translates queries fired by user into new bunch of queries which will execute on encrypted database.
This technique was implemented in Data Protector System.
Client-side encryption: This technique is generally used in case of ―Database as a service‖ scenario where the entire database is outsourced by the organization to reduce the maintenance costs. So here data privacy is the major concern. Encryption is the basic solution in this scenario.
Indexing encrypted data: There are many indexing mechanisms proposed. B tree index structure is prepared over plain text values in the table and then encryption of the table is performed at the row level. Encryption of the B-tree is done at the node level.
Another scheme involves constructing index on plain text values and then encryption of each page of the index is done separately. One more modification is suggested which involves encrypting different index pages with different keys depending on page number.
There is another scheme suggested which computes XOR of plain text values with sequence of pseudo random bits which are generated by the client according to plain text value and a secure encryption keys.
A database encryption system must adhere to some characteristics such as it should be secure enough so that it requires high work factor to break, encryption and decryption should be performed fast without compromising DBMS performance, encrypted data should be small compared to unencrypted data, it should be possible to perform encryption and decryption of records without taking into consideration their physical or logical position in database, encryption scheme must support logical sub schema concepts of databases, encrypted record should be one value which is function of all fields, the encryption scheme should be as flexible as possible with respect to combinations of read and write operations, encryption system should not force DBMS to keep duplicate copies of data so that sub schema should be supported [9].
D. Data Scrambling
Data Scrambling is a process of making sensitive information in non-production databases safe for wider visibility [10][11]. Data scrambling is also known as data sanitization, data masking and data obfuscation.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)261 The main secure methods of scrambling are extract data through scrambling functions on either live copy or preferably on the reporting copy of production data, build a set of views which can be used to mask the data and create a secure environment, take copy of production data, update data and then complete copy to development [12].
Traceability is one of the benefits of scrambling which is important in case of data loss. Scrambling is more through and more useful to testing teams. Scrambling for new releases of software is automatically upgraded as a part of normal life cycle [12].
While scrambling database data, it is necessary to understand foreign key constraints, relationships between different columns of database tables, proper documentation of methods used for scrambling. Different scrambling methods are Simple independent functions to put random text, dates and numbers, multi table column values and offset values [12]. Some sources of scrambling methods are database functions which are built in functions in DBMS, some tools for scrambling like Data Maker, customized code for the system under consideration and some information sources like books, journals and internet
Using Seed Tables is also an effective technique for scrambling data. These tables can be static or dynamic in nature. Advantages of static tables are seed tables contain data familiar to the testers; it can be added easily and can be customized easily. These tables should be populated before scrambling begins and should be verified that they don’t contain production data. Dynamic tables are the tables exclusively built for scrambling process. Next time when data are extracted, simply these tables are dropped and recreated [12]. There are some independent scrambling functions like adding small increments to existing values, lookup in seed tables, hash functions and a simple text replace function.
There are some issues in data scrambling. The scrambled data must resemble original data. Contents in one column in row are related to contents in other column in same row. Scrambled values should also maintain same relationships. Rows in the table are de normalized and contain information that is identical among many rows. Scrambled values should also maintain the same relationships. Sometimes data which is masked can be used as join key to columns in many other tables. So data masked in one table must be synchronized with data changes in number of other tables. It is combination of Row internal, table internal and table-table data synchronization. The keys should be scrambled in intelligent ways so that constraints should not be violated. Textual data, memos and letters etc. are difficult to scramble. So for such cases intelligent ways of scrambling should be adopted.
A care should be taken that a scrambled value should not overflow previously defined limit of data. Data across all tables should remain consistent. Sometimes individual data is not attributable but collection of data may be sensitive. Decision about what data should be scrambled and what not to be scrambled is important. Generally variance techniques are used if distribution of data needs to be preserved. Not every data in the rows is filled. So after scrambling also that data should not be filled. Some tables are very big. So care must be taken while designing masking function so that masking operation is not lengthy [10][11].
Encryption can also be used for the same purpose scrambling is used. But in large databases and data warehouses, encryption involves overhead on the system. There are costs involved in such cases with encryption like extra storage space is required for storage of encrypted data which is overhead, time and resources required to encrypt sensitive data are large and reduction in query response time as data decryption is required before executing query [13].
There was a technique called MOBAT (Modulus Based Technique) is proposed for masking data in data warehouse. In this approach, there are three parts. One part is the user application itself. This module will fire queries to database. The second module is using modulus based technique to mask the third part which is database itself [13].
Before applying scrambling on databases, some things should be known which include relationships among tables in databases, documentation of the database system, user’s knowledge about the key and sensitive data and naming standards used in the organization [12]. Documentation of scrambling should include information about sensitive columns and need to scramble them, who has access to scrambling functions, a report of change in data before and after scrambling and list of users who have access to working schemas or files used in scrambling process [12].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)262 Similarly values like order date should be handled with precaution. If order date is shifted then ship date should also be shifted by similar amount.
Thus scrambling is helpful in the scenarios where sensitive data must be available in realistic format as such data are required for development and testing environments but still should not be disclosed as it is. But at most care should be taken before performing scrambling and knowing data and relationships can be helpful in such cases.
E. Miscellaneous techniques for database security
To avoid inference problems in databases, poly instantiation technique can be used. In this method, multiple instances of the same data are allowed but the classification of such data should be different. It has effect on relations, tuples and data elements. The relations with poly instantiation are relations with different access classes. There are two types of poly instantiations namely visible and invisible poly instantiations. When a higher user inserts data in field having low data, the high data is entered as new tuple in visible poly instantiation. When low user inserts data in field that already has high data, low data is entered as new tuple. This is called invisible poly instantiation [14].
Auditing is another technique which can be used to fight with inference attack on databases. A history of all the queries fired by users is maintained in this approach. Analysis of such queries can help in finding inference attack and can be avoided in later stage. But this approach detects very limited inference attack instances and difficult to implement practically [14].
IV. DISCUSSION
There is a lot of scope to improve the techniques used for database security. One such area of improvement is autonomic approach for database security. SPIDER (Self ProtectIng DatabasE Research) is a research approach suggested by IBM research center whose focus is on autonomic database security. The architecture of this system contains query monitor, Intrusion Detection System, alert log, query log and backlog tables [15].
Another research area is detection of sensitive information in database automatically. Some approaches based on semantic rules and statistics are proposed in [16].
Industry is growing in the area of cloud computing where computer resources including databases are shared. So security is major issue in such cases. So security in cloud computing is recent research area.
V. CONCLUSION
Databases form the backbone of many applications today. They are the primary form of storage for many organizations. So the attacks on databases are also increasing as they are very dangerous form of attack. They reveal key or important data to the attacker. Various attacks on databases are discussed in this paper. Review of some important database security techniques like access control, techniques against SQLIA, encryption and data scrambling are discussed. Even some future research areas in the field of database security are also discussed in this paper. This research will lead to more concrete solution for database security issue.
REFERENCES
[1 ] Pfeeger ,‖Security in Computing‖, third edition,2004, Pearson education
[2 ] Shmueli, Erez, Vaisenberg, Ronen, Elovici, Yuval and Glezer, Chanan(2009)Database Encryption- An Overview of Contemporary Challenges and Design Considerations SIGMOD Record vol38, No 3.
[3 ] Xiang Fu, Kai qian, ―SAFELI-SQL Injection Scanner Using Symbolic Execution‖, TAV-WEB, Workshop on testing, Analysis and verification of Web software, July 21, 2008, ACM 978-1-60558-052-4/08/07
[4 ] Debasish Das, Utpal Sharma, D.K. Bhattacharyya, ―An Approach to detection of SQL Injection Attack Based on Dynamic Query Matching, International Journal of Computer Applications (0975-8887),vol 1 –No 25,page no 28-34.
[5 ] SushilJajodia, ―Database security and Privacy‖, ACM Computing Surveys, Vol. 28, No.1, March 1996
[6 ] Elisa Bertino, Ravi sandhu, ―Database Security- Concepts, Approaches and Challenges, IEEE Transactions on Dependable and Secure Computing, Vol 2, No 1, January-March 2005
[7 ] RSA Security Inc., “Securing Data at Rest: Developing a Database Encryption Strategy, A White Paper for developers, e-business
managers and IT‖, Website, September 7 2012,
http://www.rsa.com/products/bsafe/whitepapers/DDES_WP_0702.p df
[8 ] Lianzhong Liu, JingfenGai, ―A new lightweight database encryption scheme transparent to applications‖, Piscataway, NJ USA, IEEE international conference 2008, page 135-140.
[9 ] George I. Davida, David L. Wells, ―A database encryption system with sub keys‖, ACM transactions on database systems, vol.6, No.2, June 1981, page 312-328
[10 ]A NET 2000 Ltd., “Data Sanitization techniques‖, A White
Paper(2010), Website, September 21 2012,
http://www.datamasker.com/datasanitization_whitepaper.pdf [11 ]A NET 2000 Ltd., “Data Scrambling Issues‖, A White Paper(2010),
Website, October 10 2012,
http://www.datamasker.com/datascramblingissues.pdf
[12 ]Huw Price, “A Short Guide to Scrambling, Masking and Obfuscating Production Data, Grid Tools‖ White Paper, Website,
October 15 2012,
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)263 [13 ]Ricardo Jorge Santos, Jorge Bernardino, Marco Vieira, ―A data
masking technique for data warehouses‖, ACM 978-1-4503-0627-0, 2011 page 61-69
[14 ]Ravi S Sandhu, SushilJajodia, ―Data and database security and controls‖, Handbook of security management ,Auerbach publisher, 1993, pages 481-499
[15 ]HakanHacigumus, ―SPIDER: An Autonomic Computing Approach to Database Security Management‖, SDM 2006, LNCS 4165, page 175-183
[16 ]Cedric du Mouza, Elisabeth Metais, NadiraLammari, Jacky Akoka, Tatiana Aubonnet, Isabelle comyn- wattiau, Hammoufadili, Samira Si-Said Cherfi, ―Towards an automatic detection of sensitive information in a database‖, IEEE computer society ,978-0-7695-3981-2, 2010, page 247-252
[17 ]Cristina Ribeiro, Gabriel David, ―Database Preservation‖, briefing
paper, Website, June 6, 2012,