Using LSA and Noun Coordination Information to Improve the Recall and Precision of Automatic Hyponymy Extraction
8
0
0
Full text
Figure

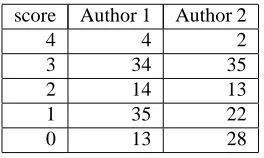
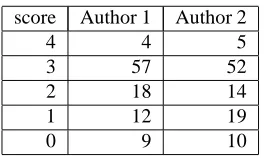
Related documents
