Technia-Int Journal of Computer Science and Communication Technology, Vol.1, issue-2, Jan,2009
SH-Struct: An Affirmative
Advance
d Method for
Mining Frequent Patterns
Upasna Singh and G.C. Nandi
Indian Institute of Information Technology, Allahabad-211012
{upasnasingh, gcnandi}@iiita.ac.in
Abstract: Data Mining requires versatile computational techniques for analyzing patterns among large and diversified databases. One of the most influential and typically emerging research area is to develop impinging structures for valid frequent patterns. In this paper, we have formulated a novel data structure known as SH-Struct (Soft-Hyperlinked Structure) which mines the complete frequent itemset using SH-Mine algorithm. This algorithm enables frequent pattern mining with different supports. Fundamentally, SH-Struct is a tree structure which maintains H-Struct (Hyperlinked Structure) at each level of the tree called SH-Tree to improvise storage compression and reserves frequent patterns very fast using SH-Mine algorithm. To validate the effectiveness of our structure here we present the performance study of SH-mine and FP (Frequent Pattern)-growth algorithm highlighting space and time payoffs for two categories of databases: sparse and dense. The experimental results show the prominent behavior of proposed method and incite us to further deploy it in more dense and dynamic databases such as temporal databases for generating more prognostic outcomes.
Keywords: SH-Struct, Frequent Pattern Mining, H-Struct, FP-growth algorithm.
I. INTRODUCTION
Till today, numerous research has shown that data mining is an ontogeneous area, having power to innovate the theory for dealing assorted data and produced effective results in diversified fields. Discovering association rules is one of the significant tasks of data mining. Association rules are discovered to generate patterns in transaction data. This theory seeks attention after it was first introduced by Agrawal R., Imielienski,and A.Swami [1]. Later on many successive refinements, generalizations and improvements of their concept have been discussed in [2, 3, 4]. One such refinement approaches towards the concept of frequent pattern mining [5, 6, 7]. A number of algorithms have been used for improving the run time complexities for generating frequent patterns [8,9].
One of the most popular and fastest algorithm for frequent itemset mining is the FP-growth algorithm [10,11]. Subsequently this approach led to a powerful algorithm known as H-mine algorithm [3, 12]. It uses the simpler data-structure
called H-Struct(Hyper-Linked Structure) which is better than FP-Tree in terms of space compression [3]. FP-growth method uses apriori property. In this method candidate sets are not generated, it partitions the databases recursively into sub-databases and then finds the most frequent pattern accordingly and after then assembles longer patterns by searching the local frequent patterns [7]. On the other hand, H-Struct is used for fast mining on temporal dataset. It has a polynomial space complexity and thus more space efficient than other pattern growth methods like FP-growth and Tree-Projection while mining sparse datasets [3].
Since both the algorithms are fast for generating frequent patterns, many researchers have used hybrid structures such as H-mine using FP-growth [4] to extract advantages of both.
However, in the present investigation, we demonstrate an advanced method for mining frequent patterns. Our approach is based on the algorithm known as SH-Mine algorithm which uses advanced structure called Struct for building SH-Tree. This structure incorporates H-Struct for preserving space and finds frequent patterns. The basic idea behind it is to save time and space for two categories of datasets i.e. sparse and dense datasets. For experimentation we have used retail shop dataset, known as Market-Basket dataset taken from [13] as sparse dataset and Synthetic dataset is fetched from [14] as dense dataset.
The presentation has been arranged in the following way: Section II introduces the basic concepts of association rule mining and frequent pattern mining, Section III addresses both SH-Tree and SH-Mine algorithms for mining frequent patterns, Section IV shows the implementations of the SH-Mine algorithm by comparing the results with that of FP-growth algorithm and section V contains conclusions and recommendations for future research.
II. BASIC CONCEPTS
has to search for those itemsets that are frequently purchased together by regular customers. For example, on any bakery shop, if the shopkeeper has a birthday cake then he must have candles in his shop according to the associative relationship of both the items and the buying habits of the customers. For better understanding of associations and discovering frequent patterns we can discriminate the association tasks as association rule mining and frequent pattern mining.
A. Association Rule Mining
An association is one of the most popular technique of data mining. Association rule mining aims to find useful and interesting patterns in the transactional database. The transactional database is like market-basket database that consists of a set of items and transaction id. Association Rule is indicated as X→Y, where X and Y are two disjoint subsets of all available items in the database. The main significance of the rule depends on two measures known as support and confidence. The support of the rule X →Y is P(XUY) and the confidence is given as P(Y|X). The task of association rule mining is to find all strong association rules that satisfy minimum support and minimum confidence threshold.
B. Frequent Pattern Mining
For mining Association rules between sets of items, the frequent pattern mining problem is introduced by Agrawal, et al. in [1]. The concept of frequent pattern mining can be categorized in several ways depending on the application for which we are mining frequent patterns. Some of them are: (1) to mine closed frequent itemsets, complete set of frequent itemsets, constrained frequent itemsets for dredging completeness of patterns; (2) to mine various dimensions of associations rules like multi-dimensional and multi-level association rules; (3) to mine several kinds of patterns such as sequential pattern mining, structured pattern mining, temporal pattern mining etc.
Till date, hundreds of research papers have been published presenting new algorithms for frequent pattern mining. One of the most popular algorithm is FP-growth (Frequent Pattern growth) algorithm. Its main objective is to use extended prefix-tree (FP-tree) structure in order to store the database in a compressed form. It has also adopted a divide-and-conquer approach to decompose mining tasks and databases. To avoid the costly process of candidate generation it uses a pattern fragment growth method.
III. SH-Struct
The present study shows the development of a new vital data structure called SH-Struct. This structure has to do two things, building SH-Tree and maintaining H-Struct at each level of the tree for every header node. It finds the complete set of frequent patterns as FP-growth but the concept of building prefix tree is different. In our algorithm, prefix tree is known
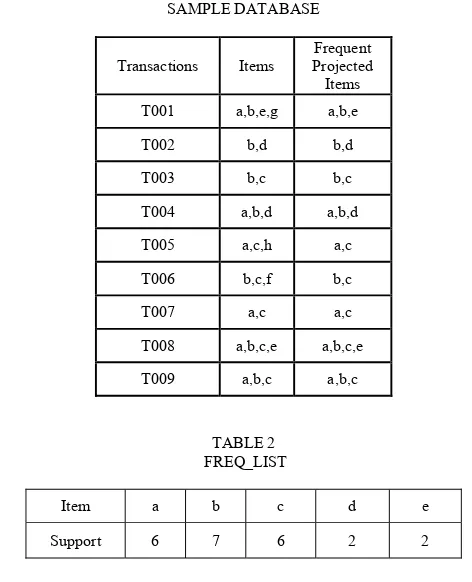
[image:2.612.319.555.259.550.2]as SH-Tree. We use the sample database given in TABLE 1 to illustrate the construction of SH-Tree. In this database, first two columns are given to us as an input and the third column ‘Frequent Projected Items’ is created on the basis of the condition support(item) ≥ minimum_support_threshold. Let us suppose for the given database, the value of minimum_support_threshold is 2. If we see item ‘a’ in all the transactions, its support is 6 i.e. support(a) > minimum_support_threshold. Thus, item ‘a’ should be kept in third column for every transaction. Now if we see item ‘g’ in every transaction, support(g) is 1 which is less than minimum_support_threshold and therefore it is excluded from every transaction in third column. In this way all the transactions are updated accordingly. After that a list called Freq_List, shown in TABLE 2 is created which contains the items and their respective supports throughout the database.
TABLE 1 SAMPLE DATABASE
Transactions Items Frequent Projected Items
T001 a,b,e,g a,b,e
T002 b,d b,d
T003 b,c b,c
T004 a,b,d a,b,d
T005 a,c,h a,c
T006 b,c,f b,c
T007 a,c a,c
T008 a,b,c,e a,b,c,e
T009 a,b,c a,b,c
TABLE 2 FREQ_LIST
Item a b c d e
Support 6 7 6 2 2
A. SH-Tree Algorithm
item ‘b’ and ‘c’ in transactions T001, T004, T008, T009 and T005 respectively, so ‘b’ and ‘c’ are the children of header ‘a’ for level 2. In this way, we can proceed for other header nodes.
FIGURE 1 SH-TREE
From SH-Tree we can see that, we have maintained H-Struct at each level of the tree. H-Struct contains three fields in its structure. First field is for items, 2nd for support of item and 3rd
is for address or link of respective item. In FIGURE 2 and 3 we can see how H-Struct is constructed for level 1 and level 2. As we have just two headers at level 1, thus H-Struct is having two items ‘a’ and ‘b’. Since Support(a) is 6, FIGURE 2 shows how 6 transactions in which item ‘a’ is header are hyperlinked. Similar case is shown for item ‘b’.
FIGURE 2
CONSTRUCTION OF H-STRUCT AT LEVEL-1
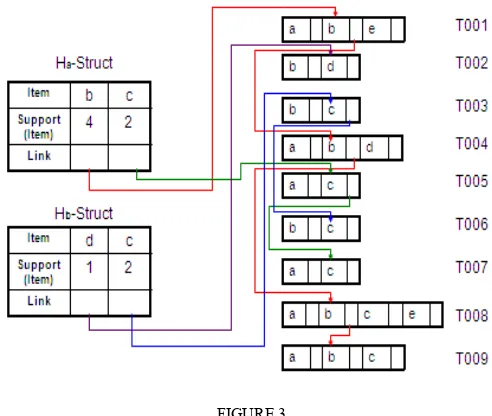
Since the transaction database is partitioned for two headers at level 1, the next level contains H-Struct followed by the name of each header i.e. Ha-Struct and Hb-Struct respectively.
[image:3.612.55.279.106.322.2]FIGURE 3 shows clearly, the linking of the items in respective transaction at level 2.
FIGURE 3
CONSTRUCTION OF Ha-STRUCT AND Hb-STRUCT AT LEVEL-2
[image:3.612.317.566.393.623.2]For level 3 and 4, the same criterion is followed for constructing H-Struct and it is named according to each partition. FIGURE 4 shows the construction of Hab-Struct and Habc –Struct at level 3 and 4 respectively.
FIGURE 4
CONSTRUCTION OF Hab-STRUCT AND Habc-STRUCT AT LEVEL-3 AND LEVEL 4
The overall process is explained in terms of psuedo code of SH-Tree illustrated as:
Build_SH Tree(t) {
{
gettransaction (t); if (t. node== headernode )
Insert_header _nodes(root, item); else
Insert_nodes(t, item);
} }
Insert_header_nodes(tree *root, item ) {
if(t.root == NULL)
t.root=newnode; else
t.root->next = newnode support(item)+=1
}
Insert_nodes(tree *t, item ) {
if(t.child == NULL)
t.child=newnode; else
t.child->next = newnode; support(item)+=1;
}
B. SH-Mine Algorithm
Mining of frequent pattern in SH-tree starts from the root of the tree and proceeds recursively. The pattern is said to be frequent if at each level the items or nodes of the pattern are satisfying the condition, support(item) ≥ minimum_support_threshold. For an example, from FIGURE 1, we may have one of the frequent pattern as {a,b,c}. Item ‘e’ is not satisfying the above condition so the mining stops at level 3. Other patterns are mined from SH-Tree in the same manner. At each level frequent_item_list is maintained for containing frequent patterns. The procedure is explained by the pseudo code of SH-Mine algorithm as:
SH_Mine(t) {
Consider L(i) to be the level of SH-Tree t . Start from the header node at level 1. frequent_ item_list= item at level 1; for(i=1;i<=total no. of levels,i++;)
if (support(item at level L(i+1)) >= min_support_threshold)
frequent_item_list(i+1)= frequent_item _list(i), item at L(i+1); display frequent_item_list;
Repeat the process for all header nodes at level 1. }
After using above algorithm, frequent-patterns for our example can be obtained as: {b,c},{a,c},{a,b,c}.
IV. PERFORMANCE STUDY WITH EXPERIMENTAL
RESULTS
The performance study evaluates efficiency and scalability of SH-Mine algorithm. Our experimental results give the comparative analysis between SH-Mine algorithm and FP-growth algorithm. It shows that many of the times SH-Mine outperforms growth and sometimes it works parallel as FP-growth.
We have performed the experiments on Pentium IV machine with 1GB main memory and 80 GB hard disk having MS Windows/NT operating system. SH-Mine and FP-growth are implemented using Dev-C++ 4.9.9.2. For SH-Mine, our experiments work with gcc-compiler which is advanced version of C/C++ compiler. While dealing with sparse datasets such as Market-basket dataset, FP-growth works quite well and some times more efficient than SH-Mine. But in case of dense datasets such as Synthetic datasets as the size of the dataset grows we have found memory problem for FP-growth. Due to this, many times we have faced the problem of system hang as our implementation is in C++ code. The reason behind the problem is that FP-growth needs lot of space for keeping the items in L-order list. This list contains the items which are sorted according to decreasing support count. At that stage SH-Mine algorithm works in a prominent way as it keeps the items in H-Struct such that the resulting patterns are both time and space efficient and hence it has never faced memory related problems. Though sometimes it takes too long for generating patterns for highly dense datasets, but never interrupts the system to stop its processing. In this way SH-Mine outperforms FP-growth in terms of space payoff.
A. Scalability Analysis
Our experiments measure the scalability of SH-Mine algorithm with respect to number of transactions and with respect to support. Also we have included the comparative study of SH-Mine and FP-growth algorithms for two categories of datasets: sparse datasets such as Market Basket (MB) dataset taken from [13], dense datasets such as Synthetic datasets taken from [14]. The taxonomy of both the datasets can be shown as in TABLE 3. Sparse datasets are those which have large number of records but less number of attributes whereas dense datasets are those which have large number of records and large number of attributes. To deal datasets computationally, dense datasets are more critical than sparse datasets and required sophisticated tools and techniques.
TABLE 3
TAXONOMY OF DATASETS
MB Dataset Synthetic Dataset
Number of
Transactions 80000 2000
Average
Total size of the
dataset 2MB 295 KB
Type of attributes in
the dataset Integer Real
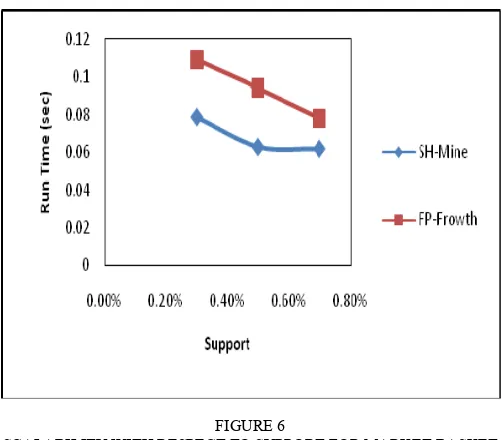
In our investigation, FIGURE 5 and FIGURE 6 show the efficiency of both the algorithms for sparse datasets w.r.t. number of transactions and support respectively.
FIGURE 5
SCALABILITY WITH RESPECT TO NUMBER OF TRANSACTIONS FOR MARKET BASKET (MB) SPARSE DATASET
FIGURE 6
SCALABILITY WITH RESPECT TO SUPPORT FOR MARKET BASKET (MB) SPARSE DATASET
From above analysis, we can say that our algorithm works efficiently for sparse datasets in terms of run-time complexity and hence it is scalable and effective for such datasets
Similar kind of analysis is shown in FIGURE 7 and FIGURE 8 for dense datasets. Sometimes in case of dense datasets it would give the parallel performance as that of FP-growth
shown in FIGURE 8.But we can see that our algorithm is scalable for dense datasets.
[image:5.612.45.302.148.357.2]Thus, the scalability analysis shows that our algorithm is efficient for sparse datasets especially when the minimum support threshold is less
FIGURE 7
SCALABILITY WITH RESPECT TO SUPPORT FOR SYNTHETIC DENSE DATASET
[image:5.612.46.297.389.609.2]..
FIGURE 8
SCALABILITY WITH RESPECT TO NUMBER OF TRANSACTIONS FOR SYNTHETIC DENSE DATASET
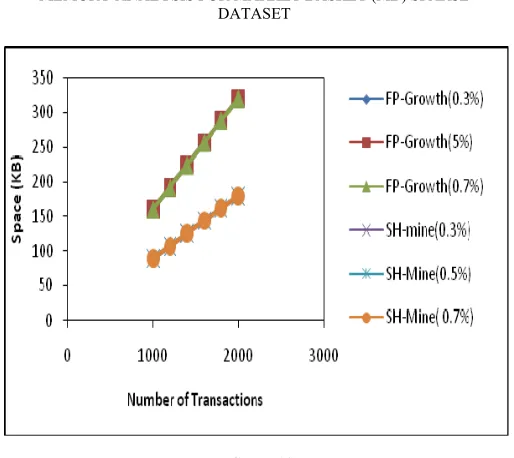
B. Memory Usage Analysis
FIGURE 9
[image:6.612.44.301.286.515.2]MEMORY ANALYSIS FOR MARKET BASKET (MB) SPARSE DATASET
FIGURE 10
MEMORY ANALYSIS FOR SYNTHETIC DENSE DATASET
V. CONCLUSIONS AND RECOMMENDATIONS FOR FUTURE
RESEARCH
We have formulated a novel data structure called SH- Struct for mining frequent patterns. The representation of this structure is found to be promiscuous as thus we can also deploy other characteristics to it. The experimental results and the comparative study of SH-Mine and FP-growth algorithms have shown that our approach is not only scalable but efficient in terms of both space and time for different datasets. We have bench marked the results using separate categories, sparse and dense datasets which make the study more stimulating and useful.
Since we have found SH-mine algorithm to be space efficient, there is ample scope for future improvement of the performance of this algorithm for even more highly dense and dynamic datasets such as temporal and Spatio-temporal datasets. We are continuing our research in applying soft computing based tools for finding temporal patterns in continuum.
ACKNOWLEDGEMENT
We thank our summer trainees Sameer Kolhekar and Kevindra Pal Singh, pursuing B.Tech from RGIIT, a campus of IIIT, Allahabad, for carrying out research under our supervision and the effort they put up for implementations.
REFERENCES
[1] R. Agrawal, T. Imielienski, and A. Swami, “Mining Association Rules between Sets of Items in Large Databases”, Proc. Conf. on Management of Data, 207–216. ACM Press, New York, NY, USA 1993
[2] Jiawei Han, Jian Pei, Yiwen Yin, "Mining Frequent Patterns without Candidate Generation", Intl. Conference on Management of Data, ACM SIGMOD,2000
[3] J. Pei, J. Han, H. Lu, S. Nishio, S. Tang, and D. Yang.” H-mine: hyper-structure mining of frequent patterns in large database.” In Proceedings of the IEEE International Conference on Data Mining, San Jose, CA, November 2001.
[4] O.P. Vyas, Keshri Verma. “Efficient Calendar Based Temporal Association Rule” , ACM SIGMOD ,Vol 34 No.-3 pp 63-71, 2005.
[5] William Cheung, Osmar R. Zaiane, "Incremental Mining of Frequent Patterns without Candidate Generation or Support Constraint", Seventh International Database Engineering and Applications Symposium (IDEAS'03), page-111, 2003
[6] Y. G. Sucahyo, R. Gopalan, “CT-PRO: A Bottom-Up Non Recursive Frequent Itemset Mining Algorithm Using Compressed FP-Tree Data Structure”, Proceedings of the IEEE ICDM Workshop on Frequent Itemset Mining Implementations (FIMI), Brighton, UK, 2004.
[7] Mingjun Song, Sanguthevar Rajasekaran, "A Transaction Mapping Algorithm for Frequent Itemsets Mining," IEEE Transactions on Knowledge and Data Engineering, vol. 18, no. 4, pp. 472-481, Apr., 2006.
[8] Christian Borgelt, “Keeping things simple: finding frequent item sets by recursive elimination”, In Proc. of the 1st international workshop on open source data mining: frequent pattern mining implementations, Chicago, Illinois, pages: 66 – 70, 2005.
[9] Q. Wan and A. An,” Efficient mining of indirect associations using Hi-mine”, In Proceedings of 16th Conference of the Canadian Society for Computational Studies of Intelligence, AI 2003, alifax, Canada, June 2003.
[10] Jiawei Han, Micheline Kamber , Book : “Data Mining Concept & Technique”,2001.
[12] Wan, Q. and An, A., “HI-mine*: Efficient Indirect Association Discovery Using Compact Transaction Database”, IEEE International Conference on Granular Computing (GrC'06), Atlanta, USA, May 10-12, 2006.
[13] URL: http://fimi.cs.helsinki.fi/data/retail.dat
[14] C.L. Blake and C.J. Merz, UCI Repository of Machine Learning Databases. Dept. of Information and Computer Science, University of California at Irvine, CA, USA 1998.
AUTHOR’S BRIEF BIOGRAPHY
Upasna Singh is presently pursuing PhD in Data Mining and Knowledge discovery form Indian Institute of Information Technology, Allahabad. She have completed her M.Tech (Computer Science) from Banasthali Vidyapith, Rajasthan in 2007 and joined research work at Defense Research and Terrain Laboratory, DRDO, Delhi till 2008. Her research area includes Knowledge Discovery, Data Mining, Soft Computing, GIS.
Dr. G C Nandi is currently working as a Professor and Divisional head of Under Graduate Division, at the prestigious Indian Institute of Information Technology, Allahabad. He obtained his BE degree from B E College, Shibpur, Calcutta University, M.Prod.E degree from Jadavpur University, Calcutta and Ph.D degree from Academy of Sciences, Moscow. Dr Nandi worked as visiting researcher at The Chinese University at Hong, Kong, EPFL, Switzerland, Fujitsu company, Japan