Computing Based Effort Estimation in Software
Development of Global Project
Kiran Ahsan
Tasleem Mustafa (HOD computer science department)
Abstract
The aim is to analysis of software development effort. It needs hold up of a well defined analysis plan to rank each conjecture technique. This paper is bases on the analysis of the estimation models that are helpful make to the project managers for the estimation. Estimation software program development has always recently been characterized by certain variables. In this case global software is developed this is certainly one among important challenges for application software developers that predicting the expansion effort of software on with the distribution upon the basis of particulars, size, complexity, time, cost and additional different measures level. The standard research topic relates to the effort of web based application development with the size base technique which is covered the use case and function point analysis. The method is concerning with the size of software project which is enhanced the existing model of effort estimation with the analysis of function points. A proposed model is improved the performance of the cost estimation in allocated given away and combined software tasks. This paper is helps to estimate the effort of the early stages of distributed software to improve the correctness and to avoid the dependency of the hassle and value estimation. That is removed the repeat work in the developing and help to low the cost of the project from the saving of errors and repeated work of the project.
Keywords: Conjecture, new formed. Variable, Adjustable. Predicting, Consequence of something.
I. INTRODUCTION
A. Effort Estimation
Programming advancement exertion estimation is the way toward anticipating the most sensible measure of exertion (communicated as far as individual hours or cash) required to create or keep up programming taking into account deficient, dubious and uproarious info. Creator expressed the exertion estimation that is the forecast of worldwide programming advancement ventures. The product improvements is worry with the central point cost as it others which is extremely trying for worldwide programming. In particular, data driven methodologies abuse certain data wanders remembering the deciding objective to survey the effort required in the midst of another appropriated programming endeavor being worked. (Abdukalykov et al., 2011)
Results demonstrates that the estimation of MMRE (Mean of Magnitude of Relative Error) and acquired by method for applying fluffy rationale is vastly improved than of MMRE of algorithmic model. The acceptance of results is done on COCOMO dataset. (Sandee 2001)
B. Importance of Effort Estimation
Exertion estimation is important for various persons and diverse division in an association. Additionally, it is required at various phases of a venture lifecycle. Programming deal groups require exertion estimation with a specific end goal to give the
cost of custom programming and venture supervisors need it so as to asset designation and time administration of the product venture. Regularly programming improvement cost taking into account the rate. Exertion estimation likewise help the venture chiefs to stream line the task assets as indicated by the anticipated time. Exertion estimation at early periods of programming advancement lifecycle (SDLC) helps the undertaking chiefs to distinguish the labor accessible is the adequate or not to build up the product as indicated by assessed exertion. (Jorgensen, 2004)
C. Effort Estimating Approaches
There are number of techniques that are utilized for exertion estimation. Every one of them has upsides and downsides and all relies on upon the data the exertion estimators has his experience and his judgment. There are three fundamental methodologies for exertion estimation:
• Expert estimation: • Formal estimation model: • Combination-based estimation:
D. Common Effort Estimation Methods
1) Work Break-Down Structure:
specialist gives 3 estimations for each errand. Best Case, Most Probable, and most pessimistic scenario. The exertion for ever assignment is the result of a weighted normal of the three estimations where the most likely exertion gets a higher weight. Delphic Oracle implies that we get 3 distinct individuals to gauge the undertaking exertion. The last errand exertion is the normal.
2) Analogy/Comparison:
It is formal estimation strategy. With this strategy we are hunting down activities with comparable attributes and we pick the nearest to the one we are evaluating. Relationship based estimation is another procedure for early life cycle full scale estimation. Similarity based estimation includes selecting maybe a couple finished tasks that most nearly match the qualities of your arranged undertaking. It is the current programming estimating calculation developed by consistent arrangements. The same number of precursors' estimation strategies use source lines of code (SLOC) to quantify programming size, WMFP utilizes a parser to comprehend the source code separating it into miniaturized scale works and infer a few code many-sided quality and volume measurements.
3) COCOMO
It is another formal technique that utilizations different parameters and a characterized equation to gauge exertion (parametric model) Constructive cost model (COCOMO) is the most recent significant augmentation to the first (COCOMO) model distributed in 1981. COCOMO acknowledges as info quantitative and subjective weighted qualities and produces exertion estimation. Bunch estimation (wideband Delphi) the wideband Delphi estimation strategy is an accord based method for assessing exertion. Individuals in group meeting submit mysterious exertion estimation structures and afterward talk about the focuses where estimation differs a great deal.
4) Estimating Size
Most formal techniques require by one means or another characterizing venture size. A large portion of them use SLOC (single lines of code) or unadjusted capacity focuses (e.g. database tables, information screens), while master judgment strategies concentrate on separating the task to little part that are anything but difficult to straightforwardly foresee exertion. Keeping in mind the end goal to utilize formal strategies and since, epically at early stages, you don't know SLOCs, you ought to utilize your experience on past ventures and on a decent investigation of the necessities. In the event that you continue assessing and after that check the genuine size with your underlying appraisal you
will turn out to be increasingly precise with venture measuring.
E. Common Mistakes in Effort Estimation:
Steve McConnell, in "10 Deadly sins of programming estimation, "notice, 10 botches (sins) on evaluating extension, I will simply specify these here albeit some as of now examined.
• Do not mistake gauges for targets
• Do not submit too soon with heaps of instabilities
• Do not accept underestimation has no effect on task result
• Do not assess in the "unimaginable zone"("impossible zone" is a packed timetable with a zero shot of progress)
• Do not utilize one and only estimation strategy • Use estimation programming
• Include hazard sway
F. Avoid Irrelevant and Unreliable Estimation Information
It is anything but difficult to acknowledge that insignificant and inconsistent data ought to be maintained a strategic distance from. Nonetheless, we have yet to see an agenda or estimation handle viably executing this estimation standard. This may mirror the conviction that master estimators can sift through immaterial and untrustworthy data when confronting it. There are, nonetheless, a few human judgment thinks about that propose this is not generally the situation, and that master assessments might be emphatically affected by superfluous data, notwithstanding when the estimators realize that the data is unessential. For instance
• In report that individuals are pretty much in the same class as models to give money related gauges when given the same exceptionally applicable data, however less precise when unimportant data is incorporated. (Whitecotton et al., 1998)
• Report from business related time arrangement forecasts that a conformity of an assessment for new data was not adequate when the underlying appraisal was very mistaken, that the untrustworthy starting evaluation emphatically affected the consequent assessments. The product improvement estimation study depicted by (Abdel-Hamid et al., 1993).
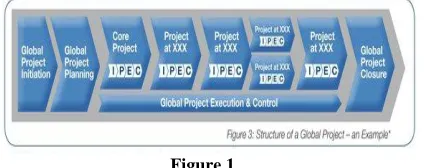
G. Global Project
topographically and working in various destinations. The undertaking troughs confront the distinctive difficulties on it as they have to adjust diverse interests, organization culture and working practices and a large portion of correspondence happen over a separation. There are diverse sorts of worldwide ventures these are. • Number of separation areas
• Number of various associations • Country society
• Different dialects • Time zones
II. REVIEW OF LITERATURE
Simon (2006) was to begin with, apparent effort appraisal is obtained by using a formula gathered by Boehm through least square. This is the vital level of COCOMO. Second, the apparent effort evaluation is expanded by a composite multiplier limit m(X). Using LOC, a couple of affiliations simply use homogeneous framework tongues, for instance, COBOL, to predict the effort with no genuine screw up. In any case, we ought to put emphasis on that particular task vernacular can show the best way to deal with estimation or under estimation process.
Abdukalykov and Kassab (2011) was the observational investigation are performed by using two industry data sets. The aftereffect of Experiments affirms the change of programming exertion estimation. For the limit of MRE and MER, we prescribe to pick the worth somewhere around 0.1 and 0.5, the careful quality can be chosen by checking on the product venture information in the association by information administrators. Introducing with grouping recorded information from the earlier activities that create the issue space for that produce the issue area for exertion estimation, each fusing the effect of NFR on exertion by sets of impartially measured ostensible elements and after that lessen the multifaceted nature of these models utilizing a component subset determination calculation.
Sharma and Kushwaha (2012) the outcome performed well by extend the association coefficient and lessening the blunder rate of the make exertion estimation techniques and fulfilling more exact effort gages for the new exercises. More over us tried estimation model generous by effectively diminishing the component space using particular methods. Our strategy proposed in this paper is semi-motorized.
Bardsiri and Khatibi (2012) demonstrated result accepts that the exertion estimation values got from RBDEE adjusts that are understood measure. The proposed measure can be drawn up at a first period of programming advancement on SRS. Another is extension the rightness of change effort estimation in
perspective of combo estimation and accuracy the combo estimation and rightness ABE and ANN procedures. The effect of insignificant and different endeavors on assessments framework is low as a result of is low because of new techniques, in which every one of the undertakings are bunched. The proposed strategy beat interchange techniques and generally upgraded the precision of evaluations in both datasets.
Attarzadeh and Mehranzadeh (2012) proposed an account made neural framework (ANN) conjecture model circuits Constructive Cost estimation Model COCOMO and ANN-COCOMO(2), to give more exact programming gages at the early time of programming progression. This model uses the compensation of reenacted neural frameworks, for instance, learning limit and extraordinary interpretability, while keeping up the advantages of the COCOMO model. The results exhibited that using recreated neural frameworks for arrangement of the COCOMO II programming credits can provoke more correct programming gages.
K Sandee (2011) This mistake was estimation prompts financial misfortune also postpone in conveyance of the item. In this paper, a delicate figuring based method is investigated to defeat the issues of instability and imprecision bringing about enhanced procedure of programming improvement exertion estimation. In doing as such, fluffy rationale is connected to various parameters of Constructive Cost Model (COCOMO) II. Results demonstrates that the estimation of MMRE (Mean of Magnitude of Relative Error) and acquired by method for applying fluffy rationale is greatly improved than of MMRE of algorithmic model. The acceptance of results is done on COCOMO dataset.
Manal and Bajta (2015) was the programming change exertion estimation for GSD concerns the desire of the effort anticipated that would add to an overall programming wander. Datasets have been used as a reason to do a relationship based estimation using similarity limits and measures. We have taken after and shown a comparability based model within cost drivers related to scattered endeavors. This approach allows the estimator to urge the surveyed qualities to since effort estimation procedures dependably defame the measure of effort time required to complete a given programming headway broaden, the makers suggest for the change of effort estimation of errands in the association of Globally Distributed Software Development.
improvement approach. Be that as it may, the cost investment funds, assuming any, from this globalization, is regularly balanced by shrouded costs, for example, handoffs between destinations, synchronization of improvement among locales, mix of programming created at disseminated destinations, dialect/social issues, travel costs, correspondence costs, and so forth. Albeit a few experimental studies have been led on this issue, because of the absence of a coordinated formal model, such studies have not created reliable and usable results. To that end, in this paper, we display a coordinated formal model for breaking down worldwide programming improvement. Our model involves two sections. To start with, we consider all assignments in a product venture that can be topographically circulated, and the conceivable destinations where they can be designated. We build up an ideal errand site designation model. Our methodology then produces an exertion gauge for the new portion, which depends on the accompanying elements: expected general rate distribution of general exertion evaluation to every errand in the advancement lifecycle, and exertion gauge for executing an undertaking at a specific site (as far as the exertion gauge for executing the same assignment at the home site, viz., without globalization). The last exertion assessment is accordingly determined as a component of the exertion gauge for executing the general programming venture in the home site; this evaluation gives venture administrators a more precise comprehension of expected cost investment funds from globalization. That demonstrated an essential issue in Global Software Development (GSD), viz., an incorporated model for ideal and exact exertion estimation in GSD ventures, particularly within the sight of heretofore concealed costs, for example, handoffs between locales, advancement synchronization among destinations, reconciliation of programming relics created at dispersed destinations, dialect issues, travel and correspondence among destinations. Propelled by the absence of any such formal model in the writing in this way, we created and introduced a two section approach. In the initial segment, we introduced a diagram based ideal undertaking assignment model for dispensing errands to different geologically circulated destinations in the task. With the ideal errand site portion close by, we displayed an exertion estimation approach for the designation, as an element of the exertion gauge for executing the task at a solitary area. The consequence of this estimation would give the estimator a smart thought of the real investment funds - if any - because of GSD. It would likewise give the estimator a way to precisely gauge the shrouded costs connected with GSD. We likewise accepted our methodology by means
of semi-organized meetings with four undertaking chiefs at IBM whose tasks are GSD ventures.
Lindströma (2014) was The developed pattern of utilizing cloud administrations e.g. Programming as-a-Service (SaaS), Platform-as-as-a-Service (PaaS), or Infrastructure-as-a-Service (IaaS), has achieved the assembling business and appears to be engaging for suppliers of cutting edge offerings, for example, Service Systems (PSS), Industrial Product-Service Systems (IPS2), Functional Sales (FS) and Functional Products (FP). In any case, as the majority of the previously stated ideas can be or are sold, entirely or mostly, with a predefined level of accessibility, one critical issue that should be tended to is the thing that suggestions the utilization of cloud administrations may have for the general accessibility. To confine the degree, this paper will just address the potential use of cloud administrations, and specifically SaaS, in a FP connection, where FP are sold as capacities with a predefined level of accessibility.
Lopen (2005) Engineers have the capacity to accomplish working on containing exertion estimation taking into account their own projects. New ideal models as Fuzzy Logic may offer an option for programming exertion estimation. This paper portrays an application whose outcomes are contrasted and those of a different relapse. Programming estimation has been distinguished as one of the three extraordinary difficulties for half-extremely old software engineering. No strategy or model of estimation ought to be favored over all others. This paper shows the act of estimation at an individual level utilizing little projects and gives the outcomes acquired a fluffy rationale framework and a conventional numerous relapse. Results show that fluffy rationale can be utilized as an option for evaluating the product advancement exertion.
circumstances when basic estimation methodologies give precise evaluations. Essentially, there are circumstances where the utilization of models may decrease vast situational or human predispositions, e.g., when the estimators have a solid individual enthusiasm for the result.
Andrew (2001) Information diggers can construed rules demonstrated to enhanced either the exertion evaluations of an undertaking or the imperfection forecasts of a product module. Such concentrates regularly display conclusion unsteadiness in regards to what is the best activity for various ventures or modules. This flimsiness can be clarified by information heterogeneity. We demonstrate that exertion and imperfection information contain numerous nearby districts with especially distinctive properties to the worldwide space. At the end of the day, what seems, by all accounts, to be helpful in a worldwide connection is regularly superfluous for specific nearby settings. This outcome brings up issues about the all inclusive statement of conclusions from observational SE. At any rate, SE analysts ought to test if their as far as anyone knows general conclusions are legitimate inside subsets of their information. At the most, experimental SE ought to wind up a quest for nearby areas with comparable properties (and conclusions ought to be obliged to only those districts). What was sudden was exactly how diverse where the nearby medicines, and how critical where those distinctions. This paper has looked at the learning of medications (changes that are planned to enhance some quality measure) utilizing Just the neighborhood information as a part of nearby group all the worldwide information found in all bunches in the wake of bunching with WHERE, and learning medicines.
Damir (2013) there was no accords as to which procedure creates the most exact appraisals; an issue shared by exertion estimation in the general programming estimation space. A past study in this space has demonstrated that utilizing troupes of estimation procedures can be utilized to address this issue. The past study manufacture gatherings utilizing solo exertion estimation methods that were esteemed predominant. So as to distinguish these predominant strategies two methodologies were researched: The initially included imitating the technique utilized as a part of the past study, while the second approach utilized the Scott-Knott calculation. Both methodologies were done utilizing the same 90 solo estimation strategies. This finding for all intents and purposes implies that regardless of the way that the multi models can give precise expectations of the cost capacity, there are likewise a couple solo-learners, which accomplish comparative forecast execution.
Khoshgotaar and Abran (2002) was the fundamental explanations behind wariness about neural system were their tendency of being secret elements. It infers that it is hard to clarify the reason about specific yield given by neural system. This is a critical shortcoming as without the capacity to deliver conceivable choices, it is impractical to believe the unwavering quality of neural systems that arrangement with true issues. The proposed utilized of techniques that maps the neural system to a fluffy standard based framework. So if these principles are intelligible then the neural system may likewise be effectively deciphered. They have considered a three layer recognition neural system with the sigmoid capacity for the concealed units and character capacity for yield unit. In the wake of preparing and testing the system with COCOMO'81 dataset, they have connected the Benitez's strategy to extricate the if-then fluffy standards from the system. These principles express the data encoded in the engineering of the system.
Attarzadeh and Hock (2010) was likewise proposed another cost estimation model in light of simulated neural systems. The proposed structure of system is tweaked for COCOMO-II Post-engineering model. The proposed model was assessed both by utilizing unique information from COCOMO dataset and simulated dataset. The outcomes have demonstrated that proposed neural system model indicated better programming exertion gauges Fuzzy rationale has additionally been utilized to evacuate unclearness in inputs to cost estimation issue.
estimation model execution is Mean Absolute Relative Error (MARE).
Cherng and Tzengb (2010) was connected Particle Swarm Optimization to assessed programming exertion by different elements programming venture bunching. While
utilizing PSO to streamline the parameters of COCOMO, every molecule contains two measurements X and Y facilitates. X and Y are An and B parameters in the COCOMO model condition separately. PSO helps in finding ideal estimations of An and B parameters as the forecast venture parameters. To start with, X and Y directions are arbitrarily created 40 particles of reach somewhere around 0 and 1 in a two-dimensional space, and every molecule has irregular introductory rate. At that point the X and Y directions of particles go about as indicator parameters, and use MMRE as wellness Value. Every molecule must gain an ideal quality on their way; this arrangement is known as the neighborhood ideal arrangement (Pbest). Every molecule should likewise have social conduct so that every molecule finds the ideal arrangement in the momentum seek, which is known as a worldwide ideal arrangement (Gbest). In spite of the fact that this work was first in applying connection and savvy registering for programming cost gauge, yet it was hard to execute and no solid results were accounted.
A. Highlight of the Model
The main element in managing a global project is to distinguish a core activity from an activity in the business unit. As a simple rule of thumb, the aim is to incorporate in the core project whatever you can reasonably get into it. If we envisage a project involving integration of the corporation’s vision. The core project would include any organizational provisions common to all the units. Although it is important that the definition is broad and results in a common and consistent set of goals, it is equally vital that the units identify with this vision by adding their own individual provisions, specific to their “culture” and character. To ensure the success and high performance of your program, we recommend defining a standard process for management of it. This could
include a common language, syntax for managing a global program and supporting infrastructures, resulting in better communication, which itself fosters understanding, consent and commitment.
When you estimate each task’s duration and cost, do you:
Ask a bunch of experts
Use a similar project’s estimates Apply top-down planning
Spend more time building a top-down estimate Variables
B. Enhanced Top-Down Estimation Model
The top-down approach to defining project tasks involves starting with the project goal or final deliverable, and breaking it down into smaller planning chunks. We call them work packages. Each of these work packages or “chunks” is further refined into greater detail, and then work items are assigned to team members.
The benefit of top-down is that the major tasks are quickly identified, and the details are later refined by the project team. However, the downside is that details might be missed without a detailed review by the project team.
In a top-down approach an overview of the system is formulated, specifying but not detailing any first-level subsystems. Each subsystem is then refined in yet greater detail, sometimes in many additional subsystem levels, until the entire specification is reduced to base elements.
The challenge is in all those pesky details that impact your project. To give the proper example of the top-down structure which is merged with the SDLC phases and apply on the global project which is start from the requirement gathering and end on the delivery of the product or project.
For the effort estimation of the project uses this way and apply the multiplication method where the work packages are divided in to the parts that parts are equal and we can estimate the total project effort by estimating the single part we where the one part effort are assuming and calculating then the other part are multiply with the number of parts.
Variable Description
Time Duration to complete the task of single unit
Size size of unit
Total Effort = Effort of one part * Number of part
In this way the large project is easily compute the effort and estimate the early level of effort all the project manager assume the early level effort then they first create the structure top-down that come to high level to low and start to end process then its
effort are easily calculate in that way we are interpret form the survey that collect the responses from people.
C. Software Accuracy Estimating
Many software managers struggle with estimating projects. On the other hand, large projects are very difficult to estimate, but the required accuracy is very important.
Size
The greatest impact on productivity is the size of the project.
As size increases productivity falls.
As the software project becomes larger and larger marginal cost begins to rise.
When planning the two most common questions
1. What type of tasks?
2. How much time requires for completion?
These are relatively simple questions, yet the project management field has developed many different techniques to answering these questions.
D. Assumptions to Estimate the Time
When I create an estimate for an organization I may have a list of assumption. For example, I recently worked with an organization that did not specify inquiries, drop down lists, but select data tables were included in data model. I made the assumptions that there would be at least one simple inquiry used.
It is important to develop upper and lower bounds for a project estimates. The chart above represents how estimates need to converge on the actual as the project goes on.
E. Estimating User Documentation
Function Points multiplied by the estimates the number of pages of user documentation. As the application gets larger the number of pages (Pages/FP rise). The reason for this is not only is the functionality of a particular part of the application described, but also how it relates to other functionality.
III. RESULTS AND CONCLUSIONS
In this study we explored whether technique was material or not we discovered this system appropriate. Since as indicated by the outcomes we got, the used arrangements of exertion in our system appear to be appropriate for the organization, strategy came about better investigation of tasks and exact exertion estimations and it gave control over execution of activities. Amid the exertion gathering and size estimation process, it gave input to the engineers by assessing the SRS records.
The examination results on "Supporting and Extra endeavors" demonstrate that we absolutely need to include additional used or squandered exertion Figure 2
values for particular exercises or sudden circumstances since their contributing impact is high. These outcomes likewise give general perspective on execution of different procedures.
In the other side the one of association are taken a shot at the worldwide undertaking the versatile application which is portable application that give the administrations on the all around that are associated the general population with the bank as essentially for this anticipate the general population worked and oversaw in the organization that are show in part 3 then investigate the exertion of the created application with the top-down structure and decipher about the model from the general population with the survey that demonstrates the outcomes. With this interpretation with the people that are given the response about the questionnaire where the people half are satisfied with this model and half are not who say this is not helpful for the developers.
On the other side the analysis are show where sized estimated in early stage they says 70% people are not agree to early stages sized estimation.
According to the generic solution patterns 70% people are agree with this statement that design being generic solutions to the common design problem for easily or commonly use for the estimation.
Global project are not easy to implement as we think with this estimation analysis that shows global projects are take more time to gather the requirement 40% people are disagree and 35% are agree with high percentage.
The implementation of the global project is easy with the people interpretation they are think it is not easy because of the percentage of disagree is 50% who are think this it is right they also people are strongly are on the disagree side to the implementation of global project.
The top-down model is easily understandable to the software engineer that are easy to understand for the work and step by step working for the managers to the end user where the people are says that the model are average because the percentage according to the answers are shows 20% strongly agree and 35%
agree where the 40% are disagree in this model.
Summary
This paper is about the product exertion estimation which is the examination on the exertion strategies furthermore the forecast of the worldwide
0 50
Strongly agree
Agree Disgree Strongly
disagree Are the design pattern are helpful to
the developers
Series1
0 20 40 60 80
Strongly Agree
Agree Disagree Strongly
disagree Are patterns being generic solutions
to the common design problem
Series1
0 20 40 60
Strongly Agree
Agree Disagree Strongly
disagree Is the global projects are take more
time to gather the requirement
Series1
0 20 40 60
Strongly Agree
Agree Disagree Strongly
disagree Is the top-down model is easily understandable to the software
engineer
programming endeavors. These outcomes are appeared in the outcomes section where the changed information are appeared in task exertion estimation. Exchange is all base on the worldwide venture all inquiries depend on the worldwide undertaking. The most effective method to appraise and when the administrators need to gauge and why the estimation vital is talked about.
A proposed model is enhancing the execution of the cost estimation in dispensed given away and joined programming assignments. This paper is evaluations the exertion of the early phases of circulated programming to enhance the rightness and to maintain a strategic distance from the reliance of the bother and esteem estimation. This examination give the best approach to viable exertion estimation for the venture to exactness of the undertaking and give the great execution of the tasks.
This paper is on the SDLC phases with top-down structure which is with the flow of the all phase that is use in software development that is also used for the global software development effort estimation analysis that helps the project managers to save cost and time for development.
LITERATURE CITED
[1] Abdukalykov, R., Hussain, I., Kassab, M., & Ormandjieva, O. (2011, August). Quantifying the accuracy of software development effort estimation using projects clustering.IETsoftware,6(6), 461-473.
[2] Aljahdali, S., & Sheta, A. F. (2010, May). Software effort estimation by tuning COOCMO model and locality: Insight on improving software effort estimation. Information and Software Technology.
[3] Alweshah, M., W. Ahmed and H. Aldabbas.2015. Evolution of Software Reliability Growth Models. A Comparison of Auto-Regression and Genetic Programming Models. Evolution, 125 (3)20-25
[4] Aleem, S., L.F. Capretz, and F. Ahmed.2015. Benchmarking Machine Learning Technologies for Software Defect Detection, 6 (3): 11-23
[5] Aggarwal, G., and V.K Gupta.2014. Software reliability growth model. International Journal of Advanced Research in Computer Science and Software Engineering, 4 (1):475-479. [6] Amin, A., L. Grunske and A. Colman.2013. An approach to
software reliability prediction based on time series modeling. Journal of Systems and Software, 86 (7): 1923-1932. [7] ALRahamneh, Z., M. Reyalat, A.F. Sheta, S.B. Ahmad and S.A
Oqeili.2011. A New Software Reliability Growth Model.Genetic-Programming-Based Approach. Journal of Softwar Engineering and Applications, 4 (8): 476. [8] Afzal, W., and R. Torkar. 2008. Suitability of genetic
programming for software reliability growth modeling. In International Symposium on Computer Science and its Applications,2(1) 114-117.
[9] Ando, T., H. Okamura and T. Dohi. 2006. Estimating Markov modulated software reliability models via EM algorithm. In Dependable, Autonomic and Secure Computing, 2nd IEEE International Symposium on Dependable, Autonomic and Secure Computing, 1(1): 111- 118. [10] Aljahdali, S.H., A. Sheta and D. Rine. 2001. Prediction of
software reliability: A comparison between regression and
neural network non-parametric models. In Computer Systems and Applications, ACS/IEEE International Conference,1(5): 470-473.
[11] Beck, A., J. Trumper and J. Dollner, 2012. A Visual Analysis and Design Tool for Planning Software Re-engineerings. Journal of IEEE Computer Society, 23(5):92-96.
[12] Bianchi, A., D. Ciavano and G. Visaggio, 2003. Iterative Reengineering of Legacy Systems. Journal of IEEE Computer Society, 29(3):225-226.
[13] Baloian, N., J. A. Pino, C. Reveco and G. Zurita, 2013. Mobile Collaboration for Business Process Elicitation from an Agile Development Methodology Viewpoint. e-Business Engineering (ICEBE), 2013 IEEE 10th International Conference, IEEE Computer Society, 5(9): 306-311.
[14] Bardsiri, V. K., Jawawi, D. N. A., Hashim, S. Z. M., & Khatibi, E. (2012). Increasing the Applications (SITA), 2015 10th International Conference on (pp. 1-6). IEEE. Braga, P. L., Oliveira, A. L., & Meira, S. R. (2007, October). Software effort estimation using Communication Systems and Networks (CICSyN), 2012 Fourth International Conference on(pp. 167-172). IEEE.
[15] Batool, A., Y. Hafeez, S. Asghar, M. A. Abbas and M. S. Hassan, 2013. A Scrum Framework for Requirement Engineering Practices. Proceedings of the Pakistan Academy of Sciences, 50(4):263–270.
[16] Batool, A., Y. H. Motla, B. Hamid, S. Asghar, M. Riaz, M. Mukhtar and M. Ahmed, 2013. Comparative Study of Traditional Requirement Engineering and Agile Requirement Engineering. Advanced Communication Technology (ICACT), 2013 15th International Conference, IEEE Computer Society, 5(9): 1006-1014.
[17] Cagnin, M. I., J. C. Maldonado, F. S. R. Germano and R. D. Penteado, 2003. PARFAIT: Towards a Framework-based Agile Reengineering Process. Journal of IEEE Computer Society, 29(9):22-31.
[18] Cagnin, M. I., J. C. Maldonado, F. S. R. Germano and R. D. Penteado, 2004. An Agile Reverse Engineering Process based on a Framework. Journal of IEEE Computer Society, 12(6):240-254.
[19] Chawla, G. and S.K. Thakur. 2013. A Fault Analysis based Model for Software Reliability Estimation. International Journal of Recent Technology and Engineering (IJRTE), ISSN: 2277-3878.
[20] Costa, E.O., A.T.R. Pozo and S.R. Vergilio.2010. A genetic programming approach for software reliability
modeling. Reliability, IEEE Transactions on, 59(1): 222-230. [21] Chiu, K.C., Y.S. Huang and T.Z. Lee.2008. A study of
software reliability growth from the perspective of learning effects. Reliability Engineering & System Safety, 93 (10):1410-1421.