PAPER • OPEN ACCESS
Features of the database implementation for materials for industry and
medicine
To cite this article: A Litvinenko and R Karotkiyan 2021 IOP Conf. Ser.: Mater. Sci. Eng. 1029 012073
View the article online for updates and enhancements.
Features of the database implementation for materials
for industry and medicine
A Litvinenko1* and R Karotkiyan2
1Southern Federal University, Rostov-on-Don, Russia 2Don State Technical University, Rostov-on-Don, Russia *e-mail: [email protected]
Abstract. The paper discusses issues related to the creation of a database of materials for industrial and medicine applications. This database is developed to accumulate information about the mechanical and other properties of materials under study and the corresponding sources of information. The paper mainly focused on organizing the change log of the described database. The change log allows one to store, display and analyse all changes made in the database. The technical solutions are presented allowing to implement universal models for logging changes that are invariant with respect to the composition and structure of the tables used.
1.Introduction
The database described in this work is intended to store information obtained in the course of research on materials used for industry and medicine. Such a database can become a powerful tool for solving problems of optimization and characterization of natural [1,2] and synthesized materials [3–7]. The database is also aimed at helping clinicians to collect the reference material for different methods of treatment of hard tissues such as dentine and enamel of human teeth [8]. Another benefit is an easy access to the reference data for the researchers and engineers working on modelling of multi-layered or functionally graded materials [9-15]. Thus, the data collected can be used for prediction of behaviour of mechanical properties of the surfaces of details, parts of the machines or different kinds of medical devices (such as implants). It should be noted, that generally, all decisions on the structure of the database and on the developed application interface for working with the database are quite classic. In general, all decisions on the structure of the database and on the developed application interface for working with the database are quite classic.
The database is based on a number of reference books (actually materials, material properties and types of such properties, sources of information about materials). It should be noted that the reference material may contain links to itself. This allows you to organize a hierarchical way of presenting information about materials. Information on material properties and related sources of information is used as basic documents. In addition, there are also auxiliary directories, for example, a list of users, a list of rights to work with various objects of the database and client application.
A rapidly growing material database with frequently modified structure is a dynamic technical information system.
2
There is one peculiarity in the approach to the implementation of the materials database, which is non-standard. This feature is associated with the ability to keep a log of database changes. This means that all changes made to the database are logged and stored in some additional database (change log).
This feature has been operating on a number of databases for enterprise applications for several years, and based on this experience, it was decided to add this feature to the materials database. Experience shows that this functionality is in great demand. From time to time there is a need to determine who and when added, edited or deleted this or that document or reference book element in the database. You can draw such an analogy ¬ the change log is a derivative of the main base, which at any moment of time stores the current information about stored objects. But the history of changes, information about who, when and what exactly changed in the database is usually not available. The change log is just intended for solving problems when it is important to understand the sequence of database changes.
The relevance of the approaches described in this work is confirmed by the real experience of maintenance and technical support of databases. The scientific novelty of the implementation of the database change log described here lies in the combined use of relational and hierarchical data organization models and original software solutions in the Transact SQL language.
2.Statement of the problem for maintaining the history of changes to the database of materials
The statement of the problem of organizing the database change log must necessarily take into account a number of key points and considerations.
The change log should keep the following information about the database change:
the fact of actually changing some element of the database: who, when, from where
(from which computer or from which program) changed the data
;
the state of the database item after this change
;what exactly was changed (which attributes changed, for each changed attribute - the old value before the change and the new value after the change).
When setting the task of maintaining and analysing the log of changes, the following points can be noted:
The database is constantly changing (tables are added / removed, the composition and types of columns in tables change)
Database documents, the history of which is kept in the change log, can have a simple structure (that is, the corresponding information is stored in one table), but they can also have a very complex structure (data from such documents are stored in several tables linked by some key or be in one to many relationship)
Changes to documents in the database can be made in a regular, standard way through a developed special client application, but they can occur in an irregular way, for example, using queries executed, for example, from the MS SQL Management Studio environment by a programmer or some special program.
The basic need for users is to see the revision history of a selected document. At the same time, by selecting some change, it will be possible to view either the state of the document after this change, or what attributes were modified in this change.
There is another very important need when analysing the change log. This is the ability to create complex queries using the change database. To do this, it is desirable to use a high-level declarative query language that is similar to the SQL or XQUERY query languages.
it is desirable to have uniform universal modules that allow you to keep a log of changes. Moreover, such universal modules should be invariant to the structure of documents and not change with each change in the structure of this document;
the database (log) of changes is very fast growing. Its volume is growing several orders of magnitude faster than the volume of the production database. Therefore, a special apparatus is needed to control the volume of the change log. It is important to be able to archive the "old" changes, but if necessary, restore and analyse these "old" changes;
3.Key issues in technical implementation of the change log
Key decision about storing document state and "delta" changes as XML in a relational table.
One of the most important issues that had to be solved when designing the structure of the change log was the decision about the structure of the corresponding data. Here it was necessary to take into account that since the database is implemented on a classic relational DBMS, many tables with fundamentally different structures were used to store various content components of the database. To keep the history of these components, following the traditional approach, it was necessary to have a similar set of tables with the same structure. Another factor influencing this decision was the frequent modification of the table structure, which is inevitable during the maintenance of almost any real database.
The solution to this issue was to use a familiar relational table in which there are two fields with the XML type (Fig. 1).
Figure 1. Basic table structure for the change log
One such field is needed for information about the state of the document after this change, and the second XML field for information about which attributes were modified. On the one hand, we wanted to preserve the power and performance of the relational data model, and on the other hand, we needed a single universal format for storing documents of various structures. It is in the XML field that you can write data of a complex structure, since, in fact, it is a representation of an attributed tree.
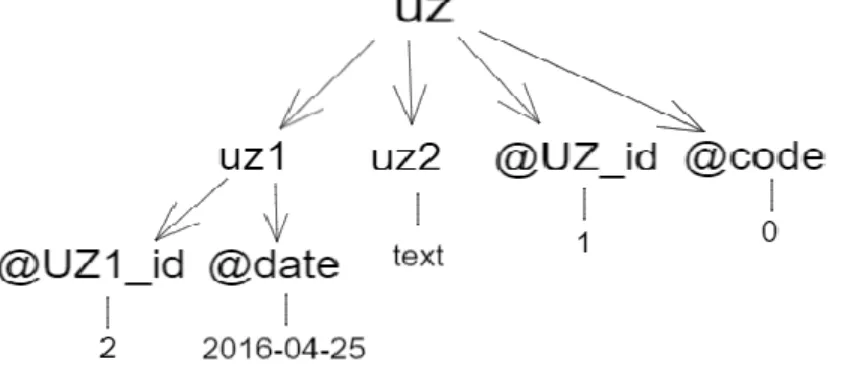
An XML document is generally thought of as a tree, where nodes are the names of tags or attributes, edges are the child's membership in the parent node, and leaves are the contents of tags or attribute values. Figure 2 shows an example of a tree view of an XML document
4
The XML type is not like other valid types that exist. Because it is not possible to access custom tags and attributes because they are not predefined, you must use processing tools and functions that are designed specifically for working with XML. The most popular of these tools are XQuery and XSLT, query languages designed for transforming XML documents. Many DBMSs, including MS SQL Server, provide XML data type and many functions to work with, along with such types.
Figure 3. Textual representation of XML object
This solution was possible and proved to be effective due to the fact that modern versions of SQL servers began to accept the XML data type. Together with this data type language, the latest versions of SQL server allow using such powerful and flexible tools as the declarative high-level query language XQUERY [16].
Following the logic used for the changelog table with XML-type fields, it was necessary to develop a basic generic stored procedure that converts the relational (tabular) representation of documents in the database to XML objects. Therefore, one of the key points in the implementation of the change log is a technical solution for converting tables into an XML object. It was also necessary to implement a solution to the inverse problem on the SQL server - converting an XML object into a table. For such basic transformations, the Transact SQL language running on MS SQL server has all the necessary basic primitives.
Another basic need for the implementation of universal program modules of the change log was to create a stored procedure that solves the DIFF XML problem (this is the name of the problem of determining the difference between two XML objects) [17]. This is necessary in order to be able to calculate which set of document attributes was modified with a given document change.
There are many different modules available to handle the DIFF XML problem. However, as a rule, these modules solve the problem of comparing two XML files in a too general way. The specifics of the XML comparison task for the change log does not allow the pure use of these existing modules.
Therefore, a specialized module for comparing XML objects was developed, tailored specifically for the specifics of use when implementing the change log.
Another interesting feature of the change log implementation is the optimization by the amount of change log data, which allows not to store all the states of the changed documents and to calculate the document state on the fly based on the last state and full history of the corresponding "deltas".
The changelog is a very fast growing table. To significantly reduce the size of this log, you can store not the state of documents after each change, but only the delta. Experience shows that instead of storing document states and dynamically calculating the delta between them, it is much more convenient to store only the delta and calculate the document state on the fly. This kills two "hares" at once: firstly, the volume of information stored in the log sharply decreases and, secondly, storing the delta in the log allows solving a fundamentally new class of problems. This new class of tasks can be described as "what has changed" queries. For example, find changes in a given period concerning a given attribute for a given set of documents.
For the optimization described above, it is necessary to have a module that solves the inverse problem of the DIFF XML problem. This task is traditionally called PATCH XML. And here is the same situation with the existing standard modules. These existing modules do not take into account the specifics of working with the change log. Therefore, a custom module was developed that solves the PATCH XML problem. It is assumed that any state of the document will be calculated by "backtracking" based on the
current state of the document and the sequence of deltas of changes applied in order from the last change to the very first change.
An interesting feature of the implementation of the change log modules is the use of metadata to connect new types of documents to the journalisation. The metadata table stores meta information about the tables used for all types of documents, as well as the types of relationships between these tables. This information contains the table names, the primary keys for each table, and the xref names for the relationships between the tables.
Based on this metadata, a SELECT query is formed for each type of document in the database, which converts the table representation of the document into an equivalent XML representation. This SELECT query is formed according to a single universal algorithm, which allows you to dynamically connect and modify this query by making the necessary changes and additions to the table with metadata. Thus, to connect a new type of documents to logging, you just need to add a new row to the table with metadata. It also allows you to replace the use of a cumbersome selection statement in the stored procedure code by calling a dynamically generated query based on information from the corresponding row in the metadata table.
One of the key points in the implementation of the change log is the mechanism for displaying document states and the actual changed attributes. Various techniques can be used to implement this mechanism. Good results can be obtained using XSLT transformation technology.
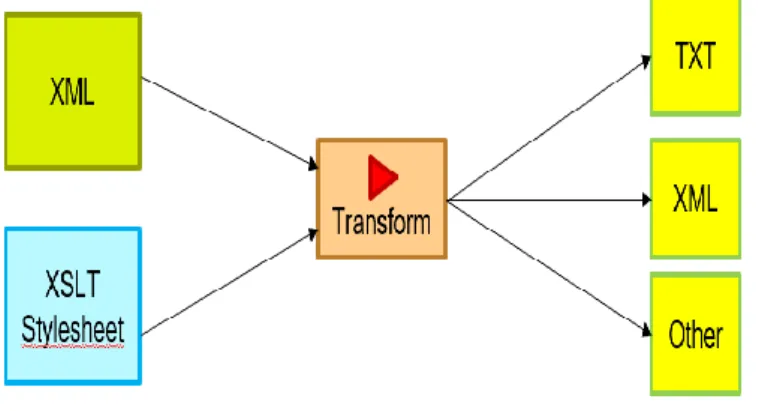
XSLT (eXtensible Stylesheet Language Transformations) is a declarative language for transforming an XML document (creating, deleting, sorting nodes) and outputting the results as XML, HTML, SVG, or plain text [18]. Figure 4 shows a schema for converting XML objects to text or some other format.
Figure 4. XML object transformation schema
An XSLT stylesheet is an XML document that defines the rules for transforming and displaying XML to the document to which it is applied.
Because XSLT is a declarative programming language, part of its job is that templates are not applied from top to bottom in the file. What happens instead is that program execution is passed from template to template, because the <xsl: apply-templates> element inside the template rule tells the system what to process next. One of the implications of this model is that the order of the template rules within the style sheet does not matter, because they are not applied in that order. Rather, they are applied whenever the <xsl: apply-templates> element, or its equivalent, indicates that a specific type of node should be processed. When this happens, for every element or other object in the input document, if there is a template anywhere in the stylesheet that matches it, the stylesheet will find it and the template will work. Another option for converting XML objects to text or HTML representation is to use the XQUERY language.
6 query is designed to extract individual fragments;
value is used to retrieve node values;
exist checks their existence;
node extracts a subtree from the XML structure;
modify modifies the content of the xml document.
Using the value method, we retrieve the node values. An example of getting the internal integer value of the “sort” tag, which we find using XPath in the xml tree:
select @sort = @meta.value('(/meta/sort)', 'int'); (1)
The query method is applicable to build your own xml tree based on extracting individual fragments from the original xml. In the following code, we will go through each element in the tree from top to bottom and take only what satisfies the necessary conditions. For example, local-name () returns the name of the current tag or attribute, denoted by @, and data () gets the value of the element. XQuery allows you to complicate the structure, which can have any nesting, using a large number of operators and functions. @xml. set @xml = query('for $b in //*, (2) $attr in $b/@* return <node tag="{local-name($b)}"></node>'); (3)
Based on the work done, the following conclusions can be drawn.
XSLT and XQUERY use the same data model that is used to formally define all values. In other words, they have the same concepts of sequences, atomic values, and nodes.
However, both technologies include the use of XPath and many equivalent built-in functions and operators, the use of which leads to the same result.
At the same time, XQuery has a less cumbersome syntax, it is convenient for embedding into the program code. XSLT is faster with small amounts of data. XQuery is faster with large amounts of data. XSLT implementations are usually created to transform one entire document. They load the entire input document into memory and perform one or more complete passes through the document. This is an appropriate behavior when converting an entire document, since you need to access the entire document anyway. Additional input documents are also loaded into memory.
XQuery is optimized for fetching chunks of data - perhaps across many documents - from a database, for example. When content is loaded into the database, it breaks up into chunks that are usually smaller than all documents. These chunks are indexed so that they can be found quickly. XQuery queries can access these parts without having to load all the documents that contain them.
To choose between these two languages, you need to define your goals, as they have different advantages. However, you might consider pipelining two processes: an XQuery to retrieve the appropriate content from the database, and an XSLT stylesheet to transform it for presentation or other purposes.
4.Conclusion
When creating and maintaining a database of materials for industry and medicine, it is useful to keep a history of changes in all content components stored in this database.
Many users have access to change information in the database. To resolve all issues related to who is responsible for the information entered into the database, it is necessary to keep a log of database
changes. The organization of such a journal is not a trivial task, given that the composition and structure of the database tables undergoes inevitable modifications.
To effectively solve these problems, it is convenient to combine the relational and hierarchical data organization model. The use of modern XML technologies within the framework of a multi-user database server allows you to effectively solve this problem.
Acknowledgments
This work was supported by Russian Foundation for Basic Research (grant Nos. 18-07-01397-а, 20-58-53045-GFEN-a)
References
[1] Sadyrin E, Swain M, Mitrin B, Rzhepakovsky I, Nikolaev A, Irkha V, Yogina D, Lyanguzov N, Maksyukov S and Aizikovich S. 2020 Characterization of enamel and dentine about a white spot lesion: mechanical properties, mineral density, microstructure and molecular composition
Nanomat. 10(9), 1889
[2] Sadyrin E, Kislyakov E, Karotkiyan R, Yogina D, Drogan E, Swain M, Maksyukov S, Nikolaev
A and Aizikovich S 2020 Influence of citric acid concentration and etching time on enamel
surface roughness of prepared human tooth: in vitro study Plast. Dam. Fract. Adv. Mater. 135–
50
[3] Vasiliev A, Sadyrin E, Mitrin B, Aizikovich S and Nikolaev A 2018 Nanoindentation of ZrN
Coatings on Silicon and Copper Substrates. Rus. Engin. Res. 38(9), 735–37
[4] Sadyrin E, Mitrin B, Aizikovich S and Zubar T 2016 Effect of temperature on the mechanical
properties of multi-component Al-Mg-Si alloys during nanoindentation test Mater. Phys.
Mech, 28 6–10
[5] Sadyrin E, Mitrin B, Krenev L, Nikolaev A and Aizikovich S 2017 Evaluation of mechanical
properties of the two-layer coating using nanoindentation and mathematical modeling Int.
Conf. Phys. Mech. New Mater. Appl.. 495–502
[6] Nikolaev A L, Mitrin B I, Sadyrin E V, Zelentsov V B, Aguiar A R. and Aizikovich S M 2020 Mechanical properties of microposit s1813 thin layers Model. Synth. Fract. Adv. Mater. Ind. Med. Appl 137–46
[7] Burlakova V E, Tyurin A I, Drogan E G, Sadyrin E V, Pirozhkova T S, Novikova A A, and Belikova M A 2019 Mechanical properties and size effects of self-organized film J. Tribol.141(5) 051601
[8] Kislyakov E A, Karotkiyan R V, Sadyrin E V, Mitrin B I, Yogina D V, Kheygetyan A V and Maksyukov S Yu 2020 Nanoindentation derived mechanical properties of human enamel and dentine subjected to etching with different concentrations of citric acid Model. Synth. Fract. Adv. Mater. Ind. Med. Appl. 75–83
[9] Kudish I I, Pashkovski E, Volkov S S, Vasiliev A S and Aizikovich S M 2020 Heavily loaded line EHL contacts with thin adsorbed soft layers Math. Mech.Solid25(4) 1011–37.
[10] Vasiliev A S, Volkov S S, Sadyrin E V and Aizikovich S M 2020 Simplified analytical solution of the contact problem on indentation of a coated half-space by a conical punch Math., 8(6), 983
[11] Argatov I I, and Sabina F J 2020 Contact stiffness indentation tomography: Moduli-perturbation approach Int. J. Eng. Sci.146 103175
[12] Volkov S S, Vasiliev A S, Aizikovich S M and Mitrin B I 2019 Axisymmetric indentation of an electroelastic piezoelectric half-space with functionally graded piezoelectric coating by a circular punch Acta Mech.230(4) 1289–302
[13] Volkov S S, Vasiliev A S, Aizikovich, S M, and Sadyrin E V 2018 Contact problem on indentation of an elastic half-plane with an inhomogeneous coating by a flat punch in the presence of
8
[14] Vasiliev A S, Volkov S S and Aizikovich S M 2018 Approximated analytical solution of contact problem on indentation of elastic half-space with coating reinforced with inhomogeneous interlayer Mater. Phys. Mech.35 175–80
[15] Kudish I I, Volkov S S, Vasiliev A S and Aizikovich S M 2018 Lubricated point heavily loaded contacts of functionally graded materials. Part 1. Dry contacts Math. Mech. Solids23(7) 1061– 80
[16] https://docs.microsoft.com/ru-ru/sql/xquery/xquery-language-reference-sql-server?view=sql-server-ver15 (date of access 05/01/2020)
[17] https: //github.com/Shoobx/xmldiff Shoobx / xmldiff: A library and command line utility for diffing xml (access date 04/01/2020)
[18] XSLT 3.0 W3C Recommendation. - URL: https://www.w3.org/TR/xslt-30 (date of access 04/01/2020)
[19] XQuery and SQL Server. - URL: https://docs.microsoft.com/ru-ru/sql/xquery (date of treatment 04/01/2020)