Contents lists available at ScienceDirect
Knowle
dge-Base
d
Systems
journal homepage: www.elsevier.com/locate/knosys
An
efficient
instance
selection
algorithm
to
reconstruct
training
set
for
support
vector
machine
Chuan
Liu
a,∗,
Wenyong
Wang
a,
Meng
Wang
a,
Fengmao
Lv
b,
Martin
Konan
a aSchoolofComputerScienceandEngineering,UniversityofElectronicScienceandTechnologyofChina,Chengdu611731,China bTheBigDataResearchCenter,UniversityofElectronicScienceandTechnologyofChina,Chengdu611731,Chinaa
r
t
i
c
l
e
i
n
f
o
Articlehistory:
Received31July2016 Revised18October2016 Accepted31October2016 Availableonline2November2016
Keywords:
Supportvectormachine Instanceselection Machinelearning
a
b
s
t
r
a
c
t
Supportvectormachineisaclassificationmodelwhichhasbeenwidelyusedinmanynonlinearandhigh dimensionalpatternrecognitionproblems.However,itisinefficientorimpracticabletoimplement sup-portvectormachineindealingwithlargescaletrainingsetduetoitscomputationaldifficultiesaswell asthemodelcomplexity.Inthispaper,westudythesupportvectorrecognitionproblemmainlyinthe contextofthereductionmethodstoreconstructtrainingsetforsupportvectormachine.Wefocusonthe factofunevendistributionofinstancesinthevectorspacetoproposeanefficientself-adaptioninstance selection algorithmfromtheviewpoint ofgeometry-basedmethod. Also,weconductanexperimental studyinvolvingelevendifferentsizesofdatasetsfromUCIrepositoryformeasuringtheperformanceof theproposedalgorithmaswellassixcompetitiveinstanceselectionalgorithmsintermsofaccuracy, re-ductioncapabilities,andruntime.Theextensiveexperimentalresultsshowthattheproposedalgorithm outperformsmostofcompetitivealgorithmsduetoitshighefficiencyandefficacy.
© 2016TheAuthors.PublishedbyElsevierB.V. ThisisanopenaccessarticleundertheCCBY-NC-NDlicense (http://creativecommons.org/licenses/by-nc-nd/4.0/).
1. Introduction
With the exponential growth of online information, finding waysoforganizing dataefficientlyandeffectivelyhasbecome an importantissue.Hence,inrecentyears,machinelearningmethods providesome solutions and haveachieved excellent performance ina wide variety of fields [1] such as data mining, handwritten recognition, information retrieval, face detection, social network, diseasesrecognitionandsoon.
Support Vector Machine (SVM) [2] is an effective machine learningmethodwithasolid theoreticalfoundation. Itachievesa highpredictionaccuracybylearningtheoptimalhyperplanefrom trainingset,whichgreatlysimplifies theclassificationand regres-sionproblems. Generally, SVM has manyexcellent features, such ashighrobustnessandgeneralization abilitywithasmallnumber ofsamples.Thatis,SVM determinesthe finaloptimalhyperplane bytheminoritysupportvectorswithtakingintoconsiderationthe modelcomplexityandlearningability.
However,trainingSVMonlargedatasetsisaveryslowprocess and has become a bottleneck, since the quadratic programming (QP) problem that implies high training time complexity O(n3)
∗ Correspondingauthor.Fax.+8602861830563.
E-mailaddress:[email protected](C.Liu).
andspacecomplexityO(n2) needs tobe solved [1,3,4].Therefore,
speeding up the training of SVM is a notable and significant is-sue.Hence,manymethodshavebeendevelopedtoreducethehigh computationalcomplexityofSVMtrainingonlargescaledatasets, andthesurveyinliterature[5]canbereferred tofordetailed in-troduction.Thewell-knowntechniques[5]aresequentialminimal optimization(SMO)[6],chunking[2],decomposition[7],and sam-pling[8].
The first type of above mentioned approaches speed up the training process by dividing the original QP problem into small pieces to reduce the size of the whole QP problem, such as the methodsproposedbyDong[1]andJ. Platt[9].Although thistype ofmethodssolvethememoryrequirementissueinhugeamounts of data, it still costs long processing time since the time con-sumptionis closely relatedto the number of instances. The sec-ondkindofapproachesmakeuseoflow-rankapproximation,such asgreedyapproximation[10],matrixdecomposition[7]andsoon. The performance ofthesetechniqueshasbeen extensively exam-ined; however theoretically these techniques do not necessarily havehighefficiency. Also, thiskindofmethods are relatively ex-pensive interm ofcomputation resource consumption. The third group ofapproaches consist in scaling down the training set by selecting support vector candidates, thereby using a small sub-set to train SVM [11]. In fact, SVM only relies on a fraction of http://dx.doi.org/10.1016/j.knosys.2016.10.031
samples, i.e. support vectors, thus we can efficiently remove the non-support vectors without affecting the classification accuracy. Hence, instance selection methods are proved to be ones of the mostdirectandeffectivewaysforSVM tosolvelargescale classi-fication problems andhavebeenan attractive topicformany re-searchers.
Although many instance selection methods have been devel-oped to successfully accelerate the training process of SVM on largescaledatasets,mostofthemappeartohavesomedrawbacks. Forexample,ReducedSVM(RSVM) [8]andRandomSampling Al-gorithm(RSA) [12]usearandomalgorithmwhichleadsto uncer-tainresults,whileKMSVM[13,14]usingclusteringtechnology per-forms poorly when theclasses are overlapped. In thispaper, we proposeanewefficientinstanceselectionalgorithmtoreconstruct trainingset,whichsolves manyseriousdifficulties,suchaslackof memoryandlongprocessingtimesufferedbytheexistinginstance selection algorithms in face of millions of records in their com-monapplications.Theproposed algorithm,namedasShell Extrac-tion (SE),extracts theuseless instancesfromtrainingset,thereby preservingthemaximumofsupportvectors. Thatis,theproposed algorithm does not directly select thesupport vectors which are difficultto beidentified, butextractsthe instanceswhichare not likelytobesupportvectors.Meanwhile,wecanadjustthestrength to reconstruct different size of subsets. It should be pointed out that there are manyremarkablepropertiesin theproposed algo-rithm,whicharesummarizedasfollows.
1. It obtains the higher classification accuracy than mostof the competitivealgorithms.
2. Ithasalineartimecomplexity.
3. Itcaneasilydealwithmulti-classproblem.
4. Thereduction intensitycanbe easilyadjusted byits inputting parameter.
The restof thepaperis organizedasfollows.Section 2 intro-duces a brief overview of instance selection methods for scaling downtrainingset.Section3describesthreegeometry-based meth-ods indetail.Section 4explainsthetheory oftheproposed algo-rithmandanalyzesitscomplexity.Theconductedexperimentsand resultsarepresentedanddiscussedinSection5.Finally,conclusion andfurtherworkaregiveninSection6.
2. Instanceselection:abriefreview
The essence ofsupport vector machine is to find the optimal classificationhyperplane. Theoptimalhyperplane balancesaterm offorcing thesepartition betweenclass AandBto maximizethe margin of separation. Considering a set of linear separable sam-ples
(
xi,yi)
,i=1,2,· · ·N,where xi∈RD isthe features,andyi∈{
+1,−1}
is the corresponding label.The classification hyperplane equation in D-dimensional spaceisω
· x+b=0. Accordingto the requirements of optimal hyperplane, the problem is transformed intotheQPproblemasfollows:min
(
ω
)
=1 2||
ω
||
2
(1) s.t. yi[
(
ω
· xi)
+b]≥1,i=1,2,3,· · ·,N.If thetraining datais not linear separable, the formulaabove must be modifiedto allowthe classification violationsamples as below: min
(
ω
,ξ
)
=12||
ω
||
2 +C· N i=1ξi
(2) s.t. yi[(
ω
· xi)
+b]≥1−ξi
,i=1,2,3,· · ·,Nξi
≥0,i=1,2,· · ·,N.By introducing Lagrange multipliers, the dual formula of this problemcanberewrittenasfollows:
max W
(
α
)
= N i=1α
i− 1 2 N i,j=1α
iα
jyiyj xi· xj (3) s.t. 0≤αi
≤C, i=1,2,· · ·,N N i=1 yiαi
=0.Solvingtheproblemabove,weobtainthe classifierasfollows:
f
(
x)
=sign N i=1α
iyi(
x· xi)
+b , (4)where
α
i isthesolutionofQP problem.Infact,thesampleswithα
i > 0 define the optimal separating hyperplane, and the sam-plescorrespondingtotheequalityα
i=0arenon-supportvectors whichdonot affecttheresultsoftrainingSVM. Unfortunately,in thetrainingset,thenumberofsupportvectorsisfarlessthanthe numberofnon-support vectorswhichoccupylarge storagespace andconsumealargeamountofcomputingresourceswithoutany helpforclassification. Therefore,inorderto improvethetraining speedofSVMandreduceunnecessarywasteofresources,Instance Selection(IS)isakindoffeasiblemethod,whichhasattractedthe attentionofmanyresearchers.Instanceselection [15],also knownasPrototypeSelection (PS) [16] or reduction techniques [17], aims to select a subset of samples from the original training set, and it has the capacity to choose relevant samples and remove noisyand/or redundant, withoutgeneratingnewartificialdatawhichisfrequentlyyielded byPrototypeGeneration(PG)orabstractionmethods[18].Awide varietyofISmethodsbasedondifferentmodelsfordifferent appli-cationshavebeenproposed[17,19,20].Theycanbebroadlydivided intothreegroups:condensation,edition,andhybridmethods.The maindifferenceofthemisdependentonthetypeofsearchcarried outbytheISmethods,whethertheyseektoretainborderpoints, centralpoints,orbothofthem.Condensationmethods aimto re-tainborderpointswhichareclosertodecisionboundaries.The in-tuitionbehindthesemethodsisthatinternal pointsdonotaffect classificationasmuchasborderpoints, sincethehyperplanes be-tweenclassesaremainly decidedby borderpoints. Thus,internal pointscanberemovedwithrelativelylittleeffectonclassification. Editionmethods, whichareconsidered theopposite of condensa-tion techniques, obtain smoother boundaries with border points removedwhichshould beseen asnoise.Thatis,such algorithms donot remove internal pointsthat donot necessarilycontribute tothedecisionboundaries.Theeffectofeditionmethodsisto im-provethegeneralizationaccuracyintestingdata.Hybridmethods tryto compute a smallest subset S,which allows the removalof internal andborderpointsbased oncriteriafollowed by thetwo previousstrategies,inordertomaintainorevenincreasethe gen-eralizationaccuracyintestingdata.It shouldbe pointedoutthat thereductioncapabilityofcondensationstrategiesiscomparatively higherthanedition methods, sincethere arefewer borderpoints thaninternalonesinmostofdatasets.
Instance selection has been broadly applied in classification [21],regression [22] andtime seriesprediction [23]. Usually, dif-ferent problems should be dealt withdifferent IS strategies. For instance, condensation methods are probably suitable for reduc-tion for trainingSVM, while edition strategies are more suitable
forthesceneofusingk-NearestNeighbors(kNN)classifier.Aswe know,kNNsuffersfromseveraldrawbackssuchashighstorage re-quirement,lowefficiencyinclassification response,andlownoise tolerance. Thereby, the objective of reduction forkNN rule is to compute asmall consistent subset. The conceptof consistency is formallydefinedasbelow[21,24]:givenanonemptysetX,a sub-setSofX(i.e.S⊆ X)isconsistentwithrespecttoXifthenearest neighbor ruleusing Sastrainingset can correctlyclassify all in-stancesinX.Thus,accordingtothedefinitionofconsistency,ifwe wanttoreconstructasubsetStobeusedasthetrainingsetofkNN rule,editionandhybridstrategiesmaybeagoodchoice.However, theobjectiveofthispaperistodiscussthereductionmethodsfor trainingSVM, thus we will mainly focus oncondensation strate-gies.
Under the condensation taxonomy framework, there are still manyissues,such asthe orderofsearch andthe technologiesof employ,canbeinvolvedinthefurtherdefinitionofthetaxonomy. Whensearchingfora subsetS ofinstancesfromoriginal training setX,thereareseveraldirectionsinwhichthesearchcanproceed [19]: incremental,decrementalandbatch. Theincremental search process startswith an empty subset S, anditeratively adds each instancein X to the subset S ifthis instancesatisfies the prede-fined criteria. The Condensed Nearest Neighbor (CNN) [24] pro-posedbyHartisconsidered tobe theoldest formalproposal un-der this scheme. After CNN proposed, Ullmann’s CNN [25] ap-pearedtobemoresuccessfulthanHart’sCNN.Later,Tomek’sCNN [26]waspresentedtoconsideronlypointsclosetoboundaryand remove the disadvantages of CNN. After that, a two-stage algo-rithmnamedasMutualNeighborhoodValue(MNV)[27]was intro-duced,whichusestheconceptofmutualneighborhoodfor select-ing samples. Recently, modified CNN [28], generalized CNN [29], fastCNN [30] andPrototype Selection based on Clustering (PSC) [31]havebeenproposed one by one.One advantageof these in-crementalschemes isthatthey are suitablefordealingwithdata streamsoronlinelearning.However,thedisadvantageisthatthey arepronetoerrorsunlessmoreinformationisavailable,sincelittle informationcan beobtainedinthebeginning.Furthermore,these algorithmsmostlydependontheorderofpresentationofsamples. ThedecrementalsearchbeginswiththeoriginaltrainingsetX, andthensearchesforinstancestoremove fromS.Also, theorder ofpresentationisimportantforthiskindofmethods.TheMinimal ConsistentSet(MCS) [32] selectsthesamplesintheorderof sig-nificance oftheir contribution forenablingthe consistency prop-erty. Itshould be pointedout that MCSleadsto an unique solu-tion irrespective of the initial order of presentation ofinstances. TheSelectiveNearestNeighbor(SNN)[33]algorithmisa represen-tativeofdecrementalmethods,whichproducesaSelectiveSubset (SS)that canbe seenasaconditionstrongerthanthat of consis-tencyinordertofindanalternatemethodforapproximating near-estneighbor decisionsurfaces.Generally, asubset S ofX isa se-lectivesubset,ifitsatisfiesthefollowingcriteria[33]that(i) sub-set S isconsistent, (ii) the distance betweenany sample andits nearestselectiveneighbor islessthanthedistancefromthe sam-pletoanysampleof theother class,and(iii)subset S shouldbe thesmallestonethatsatisfiesthecriteria(i)and(ii).Basedonthe conceptofSS, theModifiedSelectiveSubset (MSS)[34] primarily triesto finda better approximation to decision boundaries asso-ciatedwiththeSS. Unliketheincremental strategies,decremental schemesneedallthetraininginstances tobeavailablefor exami-nationeachtime.Thus,one disadvantageofdecrementalschemes istheirhighercomputationalcostthanincrementalones.
Another wayto search condensation subset is inbatch mode. That is, each sample should be checked before selecting any of them.Then, allthesamplesthatsatisfy theconsistentcriteriaare retainedtogether.Manyalgorithmsfall intothiscategory. For ex-ample,Patterns by Ordered Projections (POP) [35] is to calculate
whichsetofpatternscouldbecoveredbya“pure” regionandthen eliminatethoseinsidethatarenotestablishingtheboundaries.The improvedkNN[36] aimsat“sparsifing” densehomogeneous clus-tersof patternsof anysingleclass. Thisimplementation involves iteratively eliminating patterns which exhibit high attractive ca-pacities.ThetemplatereductionkNN[37]isbasedondefiningthe chainlistwhichisa sequenceofnearest neighborsfrom alternat-ing class.Then, the authorsset acutoff for the retainedpatterns basedonthefactthatpatternsfurtherdownthechainarecloseto theclassification boundary. Moreover, Shin etal.[38] proposed a NeighborhoodProperty-based Pattern Selection (NPPS) algorithm, which is divided into two steps. First, the label Entropy of each pointiscalculatedaccordingtothekNNpoints;thentheyremove thelabelEntropylessthanthethresholdvalueofthepoint.Ifthe pointisclosertotheseparationboundary,themoreheterogeneous pointsinitsneighborpoints,thegreaterthelabelEntropy. There-fore,this algorithm will retain more pointsat the boundaryand deletepointsaway fromseparationboundary. However,there are differentviewontheroleofboundarypointsforeditionmethods. The NNSVM [39] considered that the intermixed pointsin other classeshavenoeffectonthedecisionplaneofSVMand, addition-ally, lead tooverfitting. Thus, itsearches the nearest neighbor of each point inthe trainingset.Ifthe pointandits nearest neigh-borbelong to thesame class,the point ismarked as“1”.If they belong to differentclasses,the point ismarked as“-1”. Then, all pointsmarkedas“-1” willberemoved.
In fact, most ofthe algorithms describedabove are based on nearest neighbor techniques, which usually take a lot of time to calculate the nearest neighbor of each point. Thus, they suf-fer from involving a higher time complexity. Apart from above neighborhood-based IS methods, we have observed that the al-gorithms proposed are usually employing different techniques which can be sampling-based, clustering-based, decision tree-based,evolutionary-basedandgeometry-basedmethods.
In order to reduce the training set, Balcazar et al. [12] pro-posedarandomsamplingalgorithmtoproduceasubset fromthe wholetrainingset.Basedontheideaofthisapproach,someother methodshavebeenpresentedincludingFerragut’sSSVM[40],Lee’s RSVM[8]andsoon.Although theirexperimentsshow thatthese methodsarefasterthantheoriginalSVM,theperformanceofthese randomly sampling algorithms is uncertain since some support vectorsmaynotbeincludedintherandomlyselectedsubset.Thus, in [41], the authorsexecuted aguided random selection of sam-ples, whichincreasestheprobability ofborderpointsbeing sam-pled.
Besides the randomized sampling algorithms, methods that considermoreaboutdatacharacteristicsareproposedtoselectthe effectivetrainingsubset.Forexample,Lyhyaouietal.[42] put for-ward an instance selection technique via clustering to construct supportvectorsubset.Thisapproachperformsclusteringalgorithm ontrainingset,andfinds thenearest cluster centerfromthe op-positeclasstogetinstancesnearthedecisionboundary.Similarly, Chen etal.[43] given a Multi-ClassInstance Selection(MCIS) al-gorithm based on clustering to selectinstances frommulti-class. However, this method is based on an impractical assumption of no possible class overlap.Also, M.B.Almeida etal. [13]presented aprocedure calledKMSVMwhichis basedonk-meansclustering toacceleratethetrainingofSVM.Specifically,theymakeuseof k-means tocreateclusters ofsamplesin thetrainingset, andthen clusterformedonlybyinstancesthatbelongtothesameclass la-belcanbe disregardandonlyclustercenterare used.Conversely, cluster with more than one class labelare preservedand added to the reconstructed subset. The key idea behind thismethod is to preserve instances near the separation boundaries and disre-gard instances far away from them. However, a problem accom-panying theuse ofk-means algorithm is thechoice of the
num-berofdesiredoutputclusters.Furthermore,differentinitialpoints of k-meanswill lead to acompletely different partition.Thereby, the resultofclustering-based techniqueis unstable.Morerelated studiesofclustering-basedmethodscanbereferredtoKoggalage’s fast SVM[44], Tsai’s outliersdetection andremovalmethodology [45],andLi’sminimumenclosingballapproach[46].
Differentfromclustering-based methodswhichusedistanceor densitymeasure,literature [41]used adecisiontreeto form par-titions that are treatedasclusters. In thiscase, a purityfunction such asGini indexorEntropy gain will be usedto createa tree, thus we do not need to predefine the number of clusters. Also, literature[47]proposed amethodthat usesadecisiontreeto de-compose a given dataspace andtrain SVMs on the decomposed subsets. Doing so, the decision tree is used to replace the clus-tering, whichsimplifies theclustering procedures andavoids the high complexitycomputation of clustering. However, it performs poorlywhendealingwithnon-convextrainingset.Furthermore,it becomesdifficult to createaclassifier for alarge number of fea-tures[48].
Withthedifferentideasofpartition, J.RCanoetal.[49] intro-duceda strategy thatuses evolutionaryalgorithm ininstance se-lection.Also,S.Garciaetal.[50]adoptedevolutionary-based algo-rithm named asEGIS-CHC inimbalancedclassification. Moreover, Kawulok etal.[3] gavea novelidea called DynamicallyAdaptive Genetic Algorithm(DAGA) which dynamicallydetermines the de-siredtrainingsetsizewithoutanypriorinformation.
In addition, the more efficient approaches which analyze the datageometrytodeterminean appropriatesubset ofinstance se-lection are proposed. For example, Linear Fuzzy Support Vector Machine(LFSVM)[51]affordedamethodbasedontheideaofclass centroid. The algorithm can fast pick out some trainingsamples whichareimpossiblesupportvectors.Similarly,Pre-Selection sam-plebasedonClassCentroid(PSCC)[52]andVectorProjection Sup-port VectorMachine (VPSVM)[53] arealso geometry-based algo-rithmsmakinguseofthecentroidofclassforcuttingdown train-ing set.However, in order to deal with the multi-class problem, these methods must transform it into a large number of binary classificationproblems,whichnodoubtdecreasestheefficiencyof thealgorithm.
In order to tackle large scale dataset, the stratification strat-egy (i.e. divideand conquerstrategy)[19] are oftenemployed to split thetraining setintodisjoint subsetswithequal class distri-bution.Forexample,Garfetal.[54]proposedtheCascadeSVM,in which the trainingset is divided intoa numberof subsets, then these subsetsare optimized by multiple SVMs. Also, Wanget al. [55] provided a two-stage approach by first cleaning data based ona bundleofweakSVMclassifiers,andthen appendingtwo in-formative patternextractionalgorithms. As we all know,IS helps dataminingalgorithmstoprocesslargescaledatasetwhichmakes the applicationofclassical algorithms difficult.However, some of ISmethodsalsosufferfromhightimeandspacecomplexity,which makethemnotsuitable for“Big Data” scenario.Hence,theuseof stratificationstrategyalsoallowsustorunanyISmethodoverthe disjointsubsetsoftheentiretrainingset,therebyeasingthe prob-lemofdealingwithverylargetrainingsetbyreducingthenumber ofinstancesthatISmusthandlesimultaneously.However, stratifi-cationstrategycannotreducethehighcomputationalcostofthese ISmethods.
3. Geometry-basedmethods
We give further details of the representative geometry-based methods used in the experiments. These approachesanalyze the datageometryto determinean appropriate trainingsubset. Actu-ally,theproposedmethodalsobelongstothisgroupofmethods.
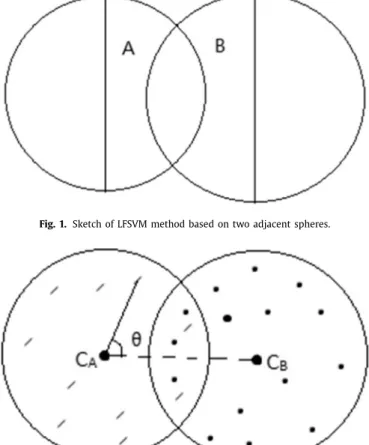
Fig.1. SketchofLFSVMmethodbasedontwoadjacentspheres.
Fig.2. SketchofPSCCmethodbasedontwoadjacentspheres.
TheLinearFuzzySupportVectorMachine(LFSVM)proposedby Caoetal.[51]isatypical geometricinstanceselection algorithm. Thekeyideaisthattheclassdistributionisassumedtobe spheri-cal,andthedecisionplaneisdistributedbetweenthetwospheres. Therefore,theysuggestthatthevectorsdistributedintheadjacent twohemispheresarethesupportvectors,asshowninFig.1.And othervectorpoints,whicharenon-supportvectors,canbedeleted. Thespecificstepsofthealgorithmareasfollows.
1.Thecentroidoftheclassisdefinedasfollows: cA=
NA
i=1xi NA ,
(5) wherexi,i∈[1,NA]arethepointsinclassA,NA isthenumber ofpointsinclassA.
2.For each class, all points that satisfy the condition
(
cA−cB)
·(
xi−cB)
≥0 are kept,here xi is thepoint in classB, cB is the centroidofclassB,andcA thecentroidofclassA.3.SVMistrainedwiththeretainedpoints.
Onthebasis ofLFSVM, Luoetal.[52] proposed an adjustable reductionstrategy named asPre-Selectionsamplebasedon Class Centroid (PSCC). The main difference between this strategy and LFSVMistointroducethecosinepropertyofsample,asshownin Fig.2.ThecosinevalueofsamplexiinclassAiscalculatedas be-low:
cos
θ
= −−→cAcB· −−→cAxi −−→cAcB
×−−→cAxi. (6)
Then,the samplewillbe removedfromtheoriginal set ifits co-sine value is more than the threshold (denoted by
ε
) given by user.Thus,thereductionintensitycanbeadjustedaccordingtothe needsofuserinPSCC.Therefore,PSCCcanbeseenasanupgradedversionofLFSVM.The concretestepsofthisalgorithmare as fol-lows.
1.ThecentroidofeachclassiscalculatedwithFormula(5). 2. ThecosinevalueofeachsampleiscalculatedusingFormula(6). 3. Thesamplewhosecosinevalueislessthanthegiventhreshold
isselectedtotrainSVM.
Similartocosinemeasure,theVectorProjectionSupportVector Machine(VPSVM)methodproposed inliterature[53]selects sam-pleonthebasisofitsprojectionmeasure.Theprojectionofsample xiiscalculatedasfollows: pi= −−−→c AcB· −−−→cA xi
−−−−→c AcB . (7)AndthedistributionradiusofclassAisdefinedasbelow:
rA=max
|
|
xi−cA|
|
. (8)Then,thedetailsofthealgorithmarepresentedasfollows. 1.ThecentroidofeachclassiscalculatedbyFormula(5). 2. TheprojectionofeachsampleisobtainedbyFormula(7). 3. The distribution radius of each class is calculated by Formula
(8).
4. ThepointwillberetainedtotrainSVMifthefollowing condi-tionsaremet.IfrA+rB<
−−−→cA cB,andtheprojectionpiofxiin classAmeetstheconditionrA−δ
≤pi≤rA;ifrA+rB≥−−−→cAcB, and the projection pi of xi in class A satisfies the condition −−−→cA cB
−rB−δ
≤pi≤rA+δ
. Note thatδ
=μ
∗−−−→cAcB+FN (μ
indicatestheabilityofboundaryareacoveringsupportvectors,Fisnoisefactor,andNisnumberofsamples), where
μ
andFaregivenbyuser. 4. Shellextraction
In this section, the principle of the proposed algorithm is in-troduced.Subsequently,thedetailedalgorithmstepsarepresented andfollowedby the pseudocodes. Finally,the complexityofthe presentedalgorithmisanalyzed.
Given trainingset X= xn:n=1,· · ·,N;xn∈RD
, and the cor-responding label set Y={
yn:n=1,· · ·,N;yn∈{
1,· · ·,M}
}
, whereM, N and D are respectively the number of classes, of samples and of features, and each sample has only one category label. Suppose a collectionof samples withthe same class label being
Cm=
{
xn|
yn=m}
,m∈{
1,· · ·,M}
, and cm is centroid vector of Cm. Thetargetoftheproposedalgorithmistoremovethenon-support vectors(i.e. the samples corresponding to the equalityα
n=0 in SVM)fromthetrainingset.As pointedout by Chen [43] that positive instances far away fromcentersofpositiveclassandnegativeinstancesclosetothese centers are near the boundary. That is, the support vectors are mostlydistributedintheboundaryarea, whichare farawayfrom thecentroidpointofeachclass.However,itisinadvisableto con-sideraninstancetobesupportvectoronthebasisoftheabsolute distancebetweentheinstanceandits centroid,since theinstance closeto itscentroidisalsolikelyto besupportvector ifthe cen-troidisnotlocatedinthegeometriccenterofthisclassduetothe unevendistributionofinstancesinthevectorspace.Thus,the sup-portvectorcannotbeextracteddirectlyaccordingtothedistance betweenthisvector andits centroid.In contrast,a large number ofnon-supportvectors, whicharemostlyclosetothe centroidof each class, are easily identified. Thus, the proposed algorithm is toidentifynon-supportvectorsbasedonthecharacteristicsofthe actualpointdistributioninthevector space.In thefollowing,the proposedalgorithmisfirstly expositedinthevector spaceofnon uniformly distributed instances, then it will be discussed in the uniformlydistributedcircumstance.
Supposing that the distribution of class Cm is not uniform, which leads to the centroid not in the geometric center of this class, asshownin Fig.3a. Also, we can mainly findout that the shape of support vectors in bold symbol is irregular. Thus, it is difficult to extract the support vectors directly according to the distanceto thecentroid.Alternatively, wecan obtain thesupport vectors indirectlyby deletingthe non-support vectors, ifthe ex-tractionofnon-supportvectorsiseasierandmoreefficient. Actu-ally,wecaneasilyobtainanddeletethevectorsintheroundarea, whosecenterischosenasthecentroidpointofthisclassasshown inFig.3a.ThisroundareaisreferredasReductionSphere(RS)in high-dimensionalvectorspace.Obviously,a largenumberof non-support vectorswillbe retained iftheradius (i.e.R) of RSistoo small,whilethesupportvectorsnearthecentroidwillberemoved iftheradiusofRSissimplyincreasedasillustratedinFig.3a.
Recall thatthe distributionofvectorsineach classisnot uni-form as mentioned above, which means the newcentroid point ofthisclasswillmove toanotherlocationafterthe vectorsinRS havebeendeleted.Thatis,thenewcentroidcm doesnotoverlap withthe old centroidcm (kindly seebelow forproof), asshown inFig. 3b.Infact, thenew centroidwill firstmove tothe sparse areaofvectordistribution,andthencomebacktothedensearea. Thus,asthemovingofnewcentroid,thenewRScanbeiteratively created by using the new centroid as the centerof this RS, and the vectorsin it can be deleted. Inthis case, it need not initial-izealargeradiusofRSinwhichsome ofthesupportvectorsmay becontained.Generally,differentradiishouldbeusedindifferent categories.ForcategoryCm,theradiuscanbecalculatedasbelow: Rm=
λ
|
Cm|
xn∈Cm
dis
(
cm,xn)
, (9)where
λ
istheparametergivenbyusertocontroltheradius,|Cm| isthenumberofinstancesincategoryCm,anddis(·,·)isthe mea-sureofdistance.However, itisaccompanied witha problemthat thealgorithmusuallystopsbeforetherequirednumberofvectors hasbeenremovedifweuseafixedsmallradius.Inordertodeal withthisproblem,we iteratively increasethe radiusofRSinour algorithmasillustratedinFig.3c,untilthenumberofretained vec-torsfallstothethresholddenotedbyTm=(
1−ξ
)
∗|
Cm|
,whereξ
is thedeletingpercentgivenbyuser.Thus,theradiuscanbeupdated asfollows: Rm(
i)
=λ
+(
i)
|
Cm|
xn∈Cm dis(
cm,xn)
, (10)where
(
i)
=δ
∗i is a function ofiteration numberi,andδ
is a factorgivenbyuser.Anyother monotonicallyincrease functionis also acceptable. Finally, the mainly steps ofShell Extraction (SE) algorithmaresummarizedasfollows:1. Calculatethecentroidcm. 2. Calculatethedis
(
cm,xn)
metric.3. Delete the point xn if dis
(
cm,xn)
<Rm(
i)
,where Rm(i) is com-putedbyFormula(10).4. Repeatstep2to3,untilallpointsinthisRSaredeleted. 5. Repeatstep1to4,untilthenumberofretainedpointsfallsto
Tm.
Withthe centroid moving in each iteration, vectors inRS are constantlyremovedfromthetrainingset.Finally,thevectors dis-tributed at the margin of each class are remained. Thus, the shape oftheremainedvectorsissimilar toa “Shell” inthe high-dimensionalspaceasillustratedinFig.3d.Formulti-classtraining setX,the pseudocodesofSEalgorithmis showninAlgorithm1, wheretheparameter
ξ
determinesthestrengthofreduction.Thus, various sizeoftrainingsubsetscan beproduced byadjusting theFig.3. SchematicofShellExtractionalgorithm.
Algorithm1 ShellExtractionalgorithm.
Require: X:thewhole trainingset;
λ
: theparameterofinitial RS radius;δ
:theparameterofRSincrease;ξ
:thedeletingpercent oftrainingset.Ensure: XS:thereconstructedtrainingset.
1: form=1;m≤Mdo 2: Tm←
(
1−ξ
)
∗|
Cm|
; 3: endfor 4: Repeat i++; 5: form=1;m≤Mdo 6: cm←|C1m |xn ∈Cm xn; 7: Rm(
i)
←λ|+Cm δ∗|ixn ∈Cm dis(
cm,xn)
; 8: forn=1;n≤N &&yn=mdo9: if
|
Cm|
>Tm&&dis(
cm,xn)
<Rm(
i)
then10: DeletexnfromCm; 11: Num++; 12: endif 13: endfor 14: endfor 15: UntilN−Num≤M m=1Tm; 16: ReturnXS=X;
parameter
ξ
.Also,λ
andδ
controlthestrengthoftheRS’s move-ment.Thus,theparameters,i.e.λ
andδ
,haveimportantimpacton theperformance ofSEalgorithm.Explicitly,the experiments con-ductedinSection5showthattheoptimalvalueofλ
fallsintothe regionof[0.8,1]andδ
shouldbesettobeasmallvalue.Generally, alargevalueofλ
(orδ
)mayleadtosomeofsupportvectorsbeing containedinRS, whileasmallvaluemeans aslightmovementof RSandalargenumberofiterations.SE algorithm ineach iteration can be divided into two steps: findingthecentroidwhosetimecomplexityisO(ND)and calculat-ingthedistancebetweenthepointsandthecentroidthatalsohas atime complexityequalstoO(ND).Therefore,ShellExtraction al-gorithmhasalineartimecomplexity.Asitismentionedabove,SE isbasedontheinferencethatnewcentroidwillnotoverlapwith theoldoneifthedistributionofinstancesisuneven.Nowwetake thekthdimension ofinstanceasanexample,andtheproof isas follows:
1.Suppose cmk=N n =m 1x nk
N m ∈[0,1], where cmk is the kth dimension of thecentroidcmandNm=
|
Cm|
.2. Suppose cmk=n N =m 1−N d x nk
N m −N d ∈[0,1], where cmk is the kth dimension ofthenewcentroidcm andNd isnumberofthedeleted non-supportvectors. 3. Assumecmk=cmk,then N m n =1x nk N m = N m −N d n =1 x nk N m −N d ⇒ N d n =1x nk N d = N m n =1x nk N m =cmk ⇒Nd n=1xnk=Nd∗cmk. Actually, theprobability,i.e.P
Nd
n=1xnk=Nd∗cmk
,ofthis con-clusionis closetozero,whenthe distributionofinstances is un-even.Therefore,this isincontradiction withthehypothesis. Fur-thermore, considering all features of instance, the probability of cm=cm is
Dk=1
P
Nn=d 1xnk=Nd∗cmk≈0, which will not hap-pen.
Recall that we made a hypothesis that the instances are un-evenlydistributedinthevector space.Conversely,ifthe distribu-tionofinstances isuniform,theorigincentroidwillbe locatedin thegeometriccenterofeachclass.Inthiscase,thenewcentroidof eachclasswillbe fixedinthecenterpositionafterthevectorsin RShavebeendeleted.AstheradiusofRSgrowsiteratively,thenon supportvectors closeto the centerwill continueto be removed. Therefore,SE algorithmcanalsowork wellinthevector spaceof uniformdistribution.
5. Experiments
InordertojustifytherationalityofSE,wecompareitwithsix representativeISmethods,i.e.NNSVM,CNN,KMSVM,LFSVM,PSCC and VPSVM, based on a number of standard benchmark collec-tions whichcome fromUCI repository. Moreover,the parameters ofSEare alsoanalyzed ina two-dimensionalartificialdataset. In ourexperiments,theitemstobeinvestigatedare(i)theabilityof keepingclassificationaccuracy;(ii)thereductionratio(theratiois definedasthe numberofremovedinstances dividedby thetotal numberofinstances)ofeachmethod;and(iii)theeffectof param-etersonSE.TheexperimentsareperformedonaPCwithIntel(R) Pentium(R)CPUG2030at3.0 GHz8GBRAM,Windows7,64bit OperatingSystem.Notethatthedatasets1 and source codes2
asso-ciatedwiththispaperareavailableonourWebsite.
5.1.Datasets
The experiments are carried out on eleven datasets includ-ingninelowdimensionalandtwohighdimensionaldatasets.The lowdimensionaldatasetsareconciselyintroducedasfollows.Glass
comesfrom USAForensicScience Service whichhas sixtypes of glassesandis definedbyterms oftheir oxidecontent. Heart dis-ease dataset contains 4 classes, i.e.Cleveland, Hungary, Switzer-land and VA Long Beach. The original database contains 76 at-tributes,butall publishedexperiments refer tousing a subset of 13attributes.Ionosphereistheclassificationofradarreturnedfrom ionosphere. This radar data was collected by a system in Goose Bay,Labrador.Theinstancesaredescribedby2attributesperpulse number,correspondingtothecomplexvaluesresultingfrom elec-tromagneticsignal. Dermatology isused todetermine the type of Erythematous-Squamousdisease,whichcontainssixclassesand34 attributes. Segment is an image segmentation database, ofwhich theinstancesweredrawnrandomlyfromadatabaseofseven out-doorimages.Theimagesweresegmentedtocreateaclassification foreverypixel.WaveformisCARTbook’swaveformdomain,which containsthree classes and21 attributes. Isolet is used to predict theletter-namespoken.USPSappearsinthebook“theelementsof
1ftp://nepsnet.com:25601/.
2https://github.com/liuchuan-uestc/ISmethod.
Table1
SummaryoftheinformationandtheparametersforSVMineachdataset. Datasets Siz. Fea. Cls. s t c g n
Dermatology 358 34 6 1 0 27 10−4 0.1 Glass 214 9 6 0 1 27 100 0.2 Heart 270 13 2 0 1 2−2 10−1 0.1 Ionosphere 351 34 2 0 0 25 10−2 0.2 Isolet 7797 617 26 0 1 2−2 10−2 0.1 Letter 20000 16 26 0 1 21 10−2 0.1 Segment 2310 19 7 0 1 2−1 10−2 0.1 USPS 9298 256 10 0 2 27 10−2 0.1 Waveform 5000 21 2 0 1 2−2 10−2 0.1 Newsgroup 13128 29949 20 0 2 27 10−1 0.1 Reuters 9462 8455 58 0 2 27 10−1 0.1
statisticallearning” byFriedman[56].Letterisadatabaseof char-acterimagefeatures,whichisusedtoidentifytheletter.
The high dimensional text collections are 20Newsgroups and
Reuters-21578. 20Newsgroups contains 19,997 messages from 20 kinds of news, including 4% reprint. Reuters-21578 is a group of 1987 reuters news. We combinethe trainingand testing sets of the version of Apte’s split 90 categories which contains 11,406 texts.For text collections, we delete the samplesthat have mul-tiple labels and then remove the categories whose samples are less than ten, since we focus on single-label classification task. Then,astop wordlistisused toremovecommonwords,andthe Portersstemmingalgorithmisadoptedtocomputetherootofeach word. Finally, Term Frequency-Inverse Document Frequency (TF-IDF)[57] weightingtechnology isusedto transformthetext into highdimensionalvectors.Thedetails,includingsize(Siz.),number offeatures(Fea.)andnumberofclasses(Cls.),ofeachdatasetare listedinTable1aftertheabovepre-processingsteps.
5.2. Settingofexperiments
The investigated algorithms can be mainly divided into two categories. One group of algorithms can obtain different reduc-tion ratio by adjusting their parameters, such as PSCC (adjust-ing
ε
),VPSVM (adjustingμ
andF) andSE(adjustingξ
).And the othergroupofalgorithmscannotadjusttheratio,suchasLFSVM, KMSVM, NNSVM and CNN. Therefore, we conduct the following twogroupsofexperimentsbyfirstcomparingSEwithVPSVMand PSCCindifferentreductionratios;andthenwedothecomparison withLFSVM,KMSVM,NNSVM andCNNin approximatereduction ratios.Doingso,itisworth notingthat theso-calledapproximate reductionratiosrefertothedifferencebetweentworatiosbeingin therangeof2% ingeneral,sincetheratioiscontrolledby adjust-ingthe parametersandwecan notguaranteeto obtainthesame ratiointheexperiments.ForSE,λ
issetto0.8inlowdimensional datasets, and 1.0in high dimensional datasets. Also,δ
is chosen as0.01. For KMSVM, the numberof clusters isset to 20 in Der-matology, Glass andHeart, whilethe numberis setto 200 inthe remainingdatasets.Forlow dimensionaldatasets,we useSVMastheclassification model;withrespecttohighdimensionaldatasets,weemploySVM and CBC(Centroid Based Classifier) [57]. LIBSVM3 is used as the
toolofSVMinallexperiments.Inordertoachievethebest perfor-mance, we respectively debug theparameters, i.e. type (-s),type ofkernel(-t),lossfunction(-c),gammafunction(-g)andv-svc pa-rameter(-n),ofLIBSVM,where-s traverses0,1;-t traverses0,1, 2;-ctraverses2−7,2−6,...,27;-gtraverses10−1,10−2,...,10−5;
-ntraverses0.1,0.2,...,0.5.Atotalof2250experimentsarecarried outtoobtainthebestparametersofclassificationperformancefor eachdataset,asalsoshowninTable1.
WechooseMacroF1(m_F1)andMicroF1(
μ
_F1)astheevaluationindices ofclassification.Supposing the numberofsamples classi-fiedcorrectlyinto classCm isa,thenumberofsamples classified incorrectlyintoCmisb,andthenumberofsamplesinCmclassified intootherclassesisc.Theprecision(pm)andrecall(rm),whichare usedtoevaluatetheclassificationperformanceofclassCm,are de-fined asa/
(
a+b)
anda/(
a+c)
,respectively. Usually, thereis an inverserelationshipbetweenprecisionandrecall.Hence,m_F1 andμ
_F1 are used to measure the average performance for the wholecategories, where F1 is a weighted combinationof precision and
recall,anditisdefinedas: F1
(
r,p)
=2pr p+r.
Thereby,m_F1iscomputed byaveragingF1 ofallcategories,while
μ
_F1 is calculated by averaging the precision and recallof allin-stances.Sincem_F1givestheweighttoallcategoriesequally,itwill
mainlybeinfluencedbytheperformanceofrarecategories.In con-trast,
μ
_F1 treatsallinstancesequally,itwillbedominatedbytheperformanceofcommoncategories.Moreover,withrespectto dis-tancemetric,thecosinedistanceisemployedintherealdatasets, whileEuclideandistanceisusedintheartificialdataset.
There are two main methods for evaluating the performance ofISalgorithms,i.e.hold-outandk-fold cross-validationmethods. Thehold-outmethodisunreliablesincetheselectionoftestingset has a direct impact on the whole performance. Hence, the five-foldcross-validationmethodisemployedtoavoidtheinfluenceof randomlyselectedtestingset.Thatis,agivendatasetisrandomly splittedintofivesubsets. Eachtimeone testingsubsetisselected toestimatethepredictiveperformanceofSVM,andtheremaining subsetsareusedtotrainSVMaftertheISalgorithmhasbeen ap-pliedon them.Then,averaging theresultsofmultiplesplittingis commonlyusedtodecreasethevarianceoftheestimation.
5.3. Experimentalresultsandanalyses
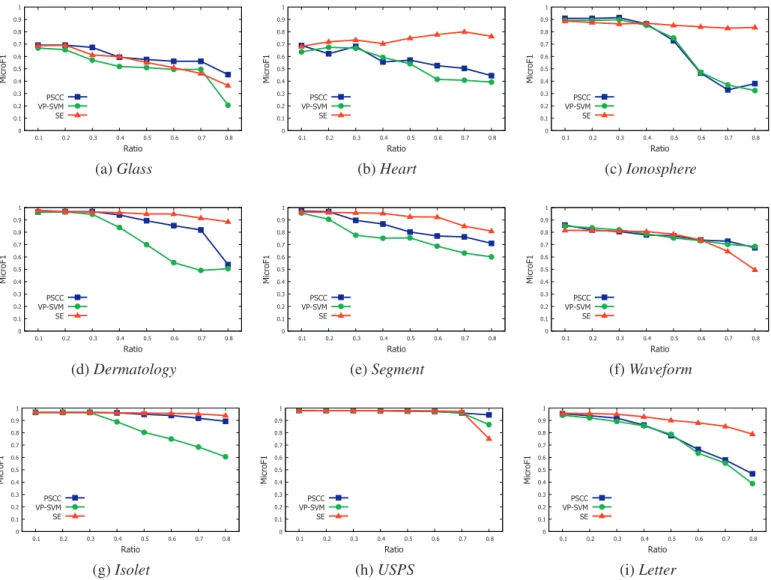
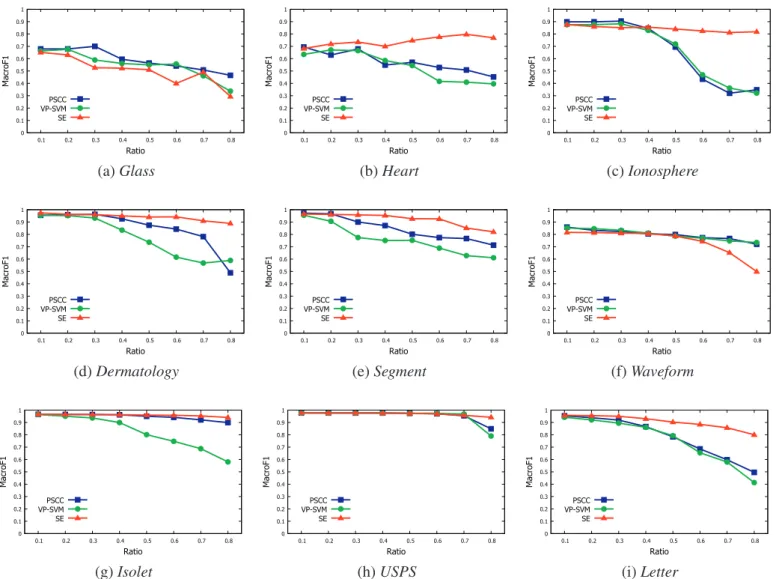
Inthefirstgroup ofexperiments,SEiscompared withVPSVM andPSCCindifferentratiosbasedonthelowdimensionaldatasets asshowninFigs.4and5,whereFig.4isthecomparisonin
μ
_F1,andFig.5isinm_F1.Theabscissaistheratio,andtheordinate is
μ
_F1 orm_F1.Inthefollowing, wefocuson theanalysisofμ
_F1,sincethetrendsof
μ
_F1andm_F1 arebasicallyconsistent.It can be easily seen that SE has an outstanding perfor-mance in Heart(Fig. 4b), Ionosphere(Fig. 4c), Dermatology(Fig. 4d),
Segment(Fig. 4e), Isolet(Fig. 4g), USPS(Fig. 4h) and Letter(Fig. 4i) datasets.Forexample,thoughtheperformanceofSEislowerthan PSCCwhentheratiois10%inHeart(Fig.4b),SEquicklyexceedsthe othertwoalgorithmswhentheratioisgreaterthan20%.Moreover, SE maintains an upward trend andfinally reaches themaximum valueof0.80intheratioof70%.However,thecurvesoftheother twoalgorithmskeepdecliningandfinallyreachtheirlowestvalues in the ratioof 80%.At this time,
μ
_F1 ofSE is about30percenthigherthantheothertwoalgorithms.
Theperformance ofSEislowerthan theothertwo algorithms inIonosphere(Fig.4c)whentheratioislessthan30%.However,the othertwoalgorithmshavethemostseriousdeteriorationwhenthe ratio ismore than30%, whileSE only hasa smallattenuation at this time. Explicitly,
μ
_F1 of SE maintains at0.82in the ratio of80%,whiletheothertwoalgorithmsarelessthan0.40atthistime. Thatis,
μ
_F1 ofSEisatleast0.4higherthan theothertwoalgo-rithmsintheratioof80%.
Similarly,SEalwayshasthesuperiorityperformancein Derma-tology(Fig. 4d), Segment(Fig.4e),Isolet(Fig.4g),USPS(Fig. 4h)and
Letter (Fig. 4i)datasets.Forinstance,in Letter(Fig. 4i),
μ
_F1 of SE,PSCC and VPSVM are about 0.95 in the ratio of 10%; but
μ
_F1of SE still maintains at0.79in the ratioof 80%, while PSCC and
Table2
ThecomparisonresultsofLFSVMandSEineachdataset. Datasets Ratio LFSVM LFSVM SE SE m_F1 μ_F1 m_F1 μ_F1 Dermatology 49.79% 0.875 0.893 0.941 0.948 Glass 59.58% 0.541 0.561 0.403 0.508 Heart 50.37% 0.544 0.541 0.758 0.742 Ionosphere 58.39% 0.607 0.624 0.831 0.852 Isolet 54.30% 0.950 0.949 0.968 0.958 Letter 52.95% 0.783 0.777 0.903 0.894 Segment 54.95% 0.783 0.780 0.920 0.922 USPS 55.47% 0.974 0.977 0.978 0.980 Waveform 49.72% 0.799 0.770 0.793 0.784 Newsgroup-SVM 40.74% 0.863 0.872 0.934 0.933 Newsgroup-CBC 40.74% 0.851 0.849 0.916 0.916 Reuters-SVM 38.23% 0.455 0.723 0.438 0.725 Reuters-CBC 38.23% 0.489 0.653 0.514 0.671
VPSVMareabout0.5and0.42, respectively.Inaddition,itshould bepointedoutthatSEshowsapoorperformanceontwodatasets, i.e.Glass(Fig.4a)andWaveform(Fig.4f).
As showninFig. 6, SEis compared withPSCC andVPSVM in two high dimensional datasets. The results using SVM in News-Group are shown in Fig. 6a and b. In the beginning, SE has the similarperformancewiththeother twoalgorithms.However,itis easytofindout theadvantagesofSEastheratio’sincreasing.For instance,
μ
_F1 ofSEmaintainsat0.93intheratioof20%,whichisabout5percenthigherthan theother twoalgorithms. When the ratioreaches 80%,
μ
_F1 ofSE still maintainsat 0.90, whileμ
_F1ofPSCC is0.51 and
μ
_F1 ofVPSVM is 0.45. Therefore, PSCC andVPSVMappeartosignificantlydeclinewhentheratioismorethan 50%,whichdoesnothappenonSE.
TheresultswithCBCinNewsGroupareshowninFig.6candd. Theperformance of SEremains unchangedwiththerise ofratio. However,PSCCandVPSVMaredecliningfromthebeginning.Thus, theperformancegapbetweenSEandtheother twoalgorithms is graduallyincreasing.Atlast,
μ
_F1 ofSEisabout25and40percenthigherthanPSCCandVPSVMintheratioof80%,respectively. The results using SVM in Reuters are shown in Fig. 6e and f, where
μ
_F1ofSEissimilartoPSCC,andisbetterthanVPSVM.TheresultswithCBCinReutersare showninFig.6g andh.From the beginning,
μ
_F1ofSEisslightlylessthantheothertwoalgorithms.Withthe increasing ratio, theperformance ofall algorithms first increasesandthendecreases.Obviously,
μ
_F1 ofPSCCandVPSVMapproximatetozerointheratioof80%.
Insummary,SEoutperformsPSCC andVPSVMin11out of13 datasets(textdatasetswithdifferentclassifier canbeseen as dif-ferentdatasets).ThereasonisthatPSCCandVPSVMcannot accu-ratelyseparate supportvectorsfromthewholetraininginstances. Thus,alotofnon-supportvectorsarestillremainedinthereduced subset,whileapartofsupportvectorsareincorrectlydeleted.On thecontrary,SEcaneffectivelyextractnon-supportvectors,which maximizes the retention of support vectors in the reconstructed subset. In addition,we can find out that non-support vector not onlyincreasesthe computationcostoflearningbutalsodegrades the performance ofclassification, since the performance of SE in theratioof80%ishigherthanthat intheoriginaltrainingsetas showninHeart.
In the second group of experiments, SE is compared with LFSVM, NNSVM,CNN and KMSVM in each dataset.Since LFSVM, NNSVM,CNNandKMSVMcannotadjusttheratio,werespectively adjusttheparameterofSEinordertoobtaintheapproximateratio ofthe comparedalgorithm. The resultsof thesealgorithms com-paredwith SE are shownin Table 2–5, where the optimal m_F1
Fig.4. Theμ_F1comparisonofPSCC,VPSVMandSEinninelowdimensionaldatasets.
Table3
ThecomparisonresultsofKMSVMandSEineachdataset. Datasets Ratio KMSVM KMSVM SE SE m_F1 μ_F1 m_F1 μ_F1 Dermatology 35.65% 0.952 0.962 0.962 0.967 Glass 25.57% 0.661 0.641 0.561 0.642 Heart 34.15% 0.629 0.630 0.725 0.721 Ionosphere 29.76% 0.871 0.886 0.868 0.884 Isolet 0.12% 0.968 0.967 0.978 0.963 Letter 3.46% 0.952 0.951 0.963 0.962 Segment 27.93% 0.829 0.846 0.971 0.978 USPS 0.11% 0.977 0.979 0.982 0.982 Waveform 21.84% 0.860 0.860 0.809 0.812 Newsgroup-SVM 6.54% 0.933 0.932 0.935 0.934 Newsgroup-CBC 6.54% 0.901 0.900 0.908 0.907 Reuters-SVM 24.82% 0.450 0.731 0.458 0.730 Reuters-CBC 24.82% 0.508 0.651 0.532 0.672
The resultsofLFSVMcomparedwithSEare showninTable2. SE outperforms LFSVM in
μ
_F1 in 12 datasets except Glass. SEbeatsLFSVMinm_F1 in10datasets.Moreover,thedisadvantageof
LFSVMis thatalmost half ofthesampleswere removedforeach dataset,whichresultsinasubstantialdeclineinaccuracy.
SE outperformsKMSVM in
μ
_F1 in 9datasets, andinm_F1 in10 datasets, as shown in Table 3. For example,
μ
_F1 of KMSVMare 9.1 and 13.2 percent lower than SE in Heart and Segment,
Table4
ThecomparisonresultsofCNNandSEineachdataset. Datasets Ratio CNN CNN SE SE m_F1 μ_F1 m_F1 μ_F1 Dermatology 82.52% 0.928 0.937 0.892 0.887 Glass 53.36% 0.613 0.626 0.462 0.523 Heart 44.93% 0.592 0.592 0.731 0.733 Ionosphere 79.10% 0.666 0.670 0.793 0.812 Isolet 72.62% 0.964 0.964 0.952 0.951 Letter 83.38% 0.898 0.897 0.792 0.779 Segment 81.38% 0.948 0.948 0.805 0.784 USPS 88.22% 0.960 0.963 0.910 0.912 Waveform 59.26% 0.852 0.850 0.849 0.849 Newsgroup-SVM 58.04% 0.925 0.924 0.934 0.934 Newsgroup-CBC 58.04% 0.912 0.911 0.924 0.923 Reuters-SVM 47.42% 0.439 0.729 0.415 0.721 Reuters-CBC 47.42% 0.521 0.680 0.494 0.670
respectively. Moreover, in term of reduction ratio, KMSVM per-forms well insome ofthe datasets,butit seems notsuitable for some datasets such as Isolate, Letter, USPS, and Newsgroup, since theratiosaretoosmallinthesedatasets.
Similarly,theresultsofCNNandNNSVMcomparedwithSEare shownin Tables4 and5,respectively. It iseasy to seethat CNN hasahighreductionratioasmorethanhalfofthesamplesare re-movedinmostofthedatasets.Incontrary,NNSVMcannot show
Fig.5. Them_F1comparisonofPSCC,VPSVMandSEinninelowdimensionaldatasets.
Table5
ThecomparisonresultsofNNSVMandSEineachdataset. Datasets Ratio NNSVM NNSVM SE SE m_F1 μ_F1 m_F1 μ_F1 Dermatology 4.30% 0.954 0.964 0.968 0.972 Glass 28.50% 0.598 0.649 0.611 0.640 Heart 32.01% 0.768 0.770 0.760 0.762 Ionosphere 11.58% 0.882 0.891 0.885 0.892 Isolet 10.38% 0.953 0.952 0.966 0.965 Letter 4.25% 0.950 0.950 0.958 0.958 Segment 6.27% 0.960 0.960 0.956 0.954 USPS 3.09% 0.973 0.976 0.982 0.982 Waveform 22.92% 0.864 0.864 0.861 0.861 Newsgroup-SVM 20.44% 0.918 0.916 0.935 0.935 Newsgroup-CBC 20.44% 0.889 0.888 0.914 0.914 Reuters-SVM 36.90% 0.389 0.708 0.434 0.730 Reuters-CBC 36.90% 0.365 0.641 0.519 0.673
the normal reduction ability asthe ratiois less than 10% in Iso-let, Letter, Segment and USPS. This observation is consistent with thepreviousanalysesthatthereductioncapabilityofcondensation strategiesiscomparativelyhigherthaneditionmethods.Intermof accuracy,CNNisbetterthanSE,butNNSVMisworsethanSE.
In order to perform a comprehensive comparison of all algo-rithms in each dataset, we adopt the same data analysis tech-nique asused in[58]. Fig.7depictseachpair (ratio,accuracy) of
algorithmsintwo-dimensioncoordinate,wherethenormalised Eu-clideandistancebetweeneach pointandtheidealpoint (1,1)can beemployedtoassessthecomprehensiveperformanceofeach al-gorithm. Inthis case, the“best” one is deemed asthe one near-est to (1,1). Withrespect to the adjustable approaches, i.e.PSCC, VPSVMandSE,thepointsforthiscomparisonarethebestpoints (nearesttoidealpoint)chosen fromtheresultsinthefirstgroup ofexperiments.Regardingtheapproachesthat cannot adjustthe ratio,thepointscomefromthesecond groupofexperiments.We can easily see that SE remains the leader with six datasets (i.e.,
Heart,Ionosphere, Isolet,USPS, NewsgroupandReuters), whileCNN takes the crown for three datasets (i.e., Dermatology, Letter, Seg-ment).Moreover, PSCCandVPSVMare thebestonesinGlassand
Waveform,respectively.
Specifically,the timeconsumption ofeach algorithm isshown inTable6.ConsideringthatthecomputationconsumptionofSEis proportional to the reduction ratio. Thus, the parameter
ξ
is set to 0.5 in SE. Apparently, SE has a remarkable superiority in the large scale datasets, such as Isolet, USPS, Newsgroup and Reuters. For instance, SE takes only 5822 ms in Isolet, while the second ranked algorithm (i.e. LFSVM) consumes 34196 ms. Similarly, inNewsgroup,thetimeconsumption ofSE(consuming22996ms)is 1/80timesofVPSVM(consuming1833814ms)whichistheclose runner-up, and is 1/161 times of CNN (consuming 3709599 ms) whichistheslowestalgorithm.Indeed,thetimeconsumedbyCNN isfar beyondthetime of trainingSVM withtheoriginal dataset.
Fig.6. TheF1comparisonofPSCC,VPSVMandSEinNewsGroupandReuters.
Table6
Thetime(ms)consumptionineachdataset.
Datasets SE VPSVM PSCC LFSVM NNSVM KMSVM CNN Dermatology 25 32 48 72 284 6895 109 Glass 31 15 16 31 98 140 94 Heart 32 16 16 47 109 187 124 Ionosphere 31 31 31 93 437 937 124 Isolet 5822 37,143 34,897 34,196 3,564,787 1,935,437 3,370,709 Letter 1007 921 858 1030 329,863 54,423 173,309 Segment 406 78 78 156 5320 5478 2403 USPS 2529 6459 5257 6271 1,892,628 636,411 619,904 Waveform 405 78 94 219 22,309 15,128 15,682 Newsgroup 22,996 1,833,814 1,875,194 1,910,789 2,665,037 2,867,117 3,709,599 Reuters 3672 361,498 369,112 361,395 205,982 246,979 144,133
Also, NNSVM hasa similar disadvantage asCNN in face oflarge size datasets,since thetime complexityis O(N2) for seeking the
nearestneighborofeachinstance.
Insummary,wecandrawthefollowingconclusionsfromabove experiments.Intermofkeepingaccuracy, SEcanachieve thegoal ofreducingthetrainingsetwithoutdegradingtheclassification ac-curacysignificantly.Explicitly,SE canreduce 80%oftheinstances without degrading the classification accuracy in some datasets such asHeart, Isolet, USPS, andNewsgroup, andwith a slight de-gradinginIonosphere,Dermatology,Segment,LetterandReuters.The performanceofSEisbetterthanPSCCandKMSVM,andfarbetter
thanVPSVM,LFSVMandNNSVM.Moreover,CNNalsoproveitself tobe thebestone.Intermofspeed,SEhasa greatadvantagein timeconsumptioninfaceoflargescaledatasets.Thesecond rank-ing are VPSVM, PSCC, and LFSVM due to their linear time com-plexity.Furthermore,CNNisprovedtobetheslowestonesinceits timecomplexityisapproximatelyO(N3).Intermofcomprehensive
performance,SEisthewinner,andCNNisaverycloserunner-up. NNSVM islikely to be the worst one since it is always far away fromtheidealpoint.Thus,SEoffersfasterandmoreeffective train-ingsetoptimizationthanmostcompetitivealgorithms.
Fig.7. Thecomprehensivecomparisonofallmethodsineachdataset.
5.4. Parameteranalysesinshellextraction
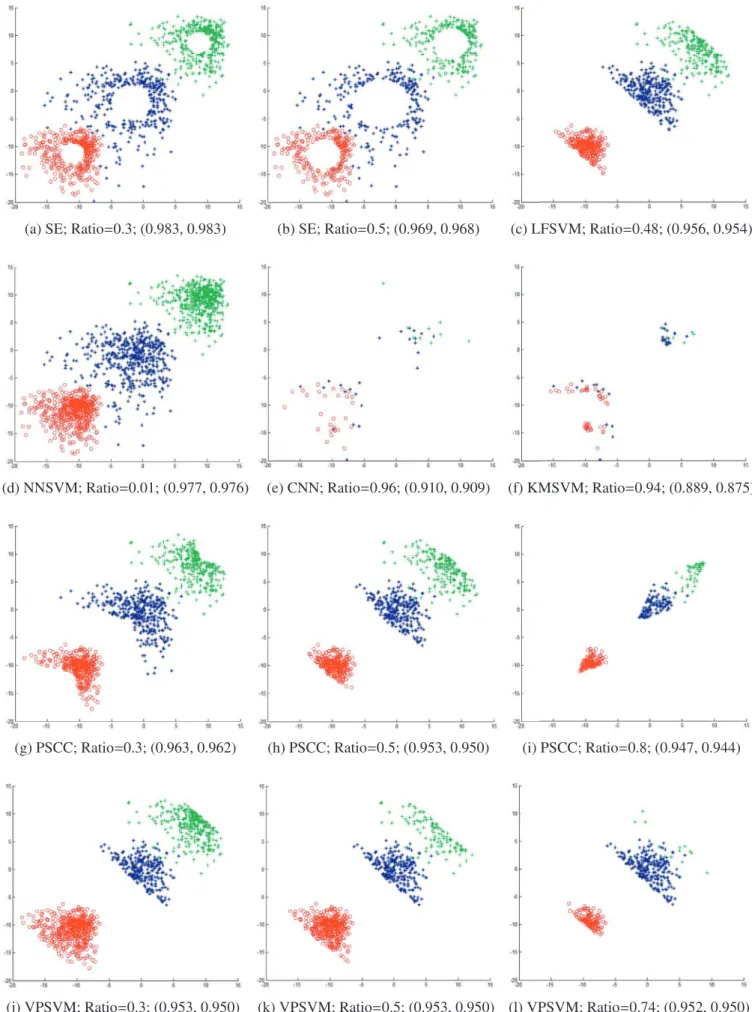
Inthissection,wearedevotedtoillustratingtheselected sub-setsresultingfromSE.Todothis,weproduceatwo-dimensional ar-tificialdataset,whichcontainsthreeclassescomposedof1500 in-stances,basedonExtremevaluedistribution.Thecompletedataset isillustratedinFig.8a.Fig.8b–dshow theselectedsubsetsinthe iteration process ofSE, which could helpto visualize and under-stand the wayofworkingandthe results obtainedinthisstudy. It should be appreciatedthat all margin pointsareremained but interiorpointsareremoved.
Inordertodeepunderstandhowtheparameters(i.e.
λ
andδ
) impact ontheperformance (including accuracyandspeed)ofSE, we presenta detailedanalysisbasedon theartificialdataset andNewsgroup. Fig. 9 illustrates the selected subsets by SE with dif-ferent
λ
in the artificial dataset, where the two values specified inparenthesesforeachsubgraph arerespectivelym_F1 andμ
_F1,which arecalculated intestingthewhole instancesbased onthe SVMmodeltrainedbyeachselectedsubsets.Inthebeginning,as
λ
isequalto0.5,all borderpointsareperfectlypreservedasshown inFig.9a.However,withtheincreaseofparameterλ
,SEperforms amoreaggressiveremovalofinstancesinthedecisionboundariesasobservedfromFig.9a–d.Consideringthepolarizationcasethat
λ
reaches1.5,most of the borderpoints are removedas illustrated inFig.9d.Fig.10revealstheaccuracyanditerationswiththe in-creaseofparameterλ
andδ
onNewsgroup,whereλ
variesfrom 0.4to3.0withstep0.01asshowninFig.10aandb,andδ
varies from0.002 to 0.08 with step 0.002as shown in Fig. 10cand d. Withtheincrease ofλ
,theiterationsgraduallydecline.The accu-racy, however,maintains an upward trendand reachesthe max-imum value of 0.91 whenλ
is equal to 1.0, and then declines severely. The reason is that with the increase ofλ
, the moving strengthof RSgradually increases.Thereby,the non-support vec-tors faraway fromthe original centroidpoint are more likely to beremoved. However, ifλ
exceedsthethreshold,e.g.λ
> 1.0,as showninFig.10b,themostofsupportvectorswillbe deletedin thefirstiteration.Thereby,theaccuracydecreasesrapidly.Finally,theselectedsubsetsbydifferentmethodsareshownin Fig.11.RegardingSE,theselectedsubsetswithdifferentratios(i.e., 0.3,0.5and0.8)arerespectivelyshowninFigs.11a,band9b. Ob-viously,theoptimalclassificationhyperplanesintheselected sub-sets ofSE always keep fixed asin the original dataset.However, it is not true with respect to PSCC in Fig. 11d–i and VPSVM in Fig. 11j–l. In fact, in order to deal with themulti-class problem,
(a) Original (b) 1thiteration
(c) 33thiteration (d) The last iteration
Fig.8. TheselectedsubsetsintheiterationprocessofSEwithλ=0.5,δ=0.01
andξ=0.8. Fig.9. TheselectedsubsetsbySEwithdifferentλ,whenδ=0.01andξ=0.8.
PSCCandVPSVMmusttransformitintoalargenumberofbinary classificationproblemswithoneclass asthepositiveandtherest asthe negative. Inthis case, the identificationof positive border pointsneedsthehelpofnegativepoints.However,itwillbe diffi-cultforPSCCandVPSVMtofindouttheborderpointsifthe nega-tiveclassesaredistributedaroundthepositiveclass.Furthermore, wecanalsofindoutthat CNNandKMSVM retainasmallpartof supportvectors, while NNSVMonly removes few instances over-lappedwitheachother.
6. Conclusionandfurtherstudy
Thispaperpresentsanewalgorithmforsupportvector recog-nition to reduce training set without significantly degrading the classificationaccuracyofSVM.TheideaofSEalgorithmisan inge-niouswaytomakeuseofthecharacteristicthatthecentroidpoint wouldbeshiftingaftertheunevendistributedvectorsareremoved off,whichistotallydifferentfromtheexistingIS methods. More-over,SEcanbeeasilyusedinmulti-classproblemsinceitreduces a singleclass without the help of other classes. A large number ofexperimentson eleven realdatasets show that SEhas the ad-vantagesofflexiblesetting,stableperformanceandhighefficiency. Currently,theneedoffastmethodsforinstanceselectionhas be-guntodrawintensiveattentionamongresearchers.SEselects in-stances withoutrequiringthe whole datasetto be fittedintothe memory.TheadvantagesofSE,suchashighspeedandlow mem-oryconsumption,indicatethatitissuitableforbigdataprocessing inallfieldsofmachinelearning.
Although SE iseffective,there are still some places to be im-provedinthefuture.Onewayistoexpand SEtomakeitsuitable formoredatasets.AsthepreconditionofSE,eachclassdistribution shouldbe spherical inthefeature space.Thus, iftheclass distri-butionisnon-convex, SEwill removesome ofsupportvectorsby mistake.Anotherwayis tobuildorcreatea newcenterofRSby selectingthemedoids orcumuli geometriccentroid (CGC)[57] of each class. Moreover, a future research line is trying to combine SE withCBC to improve the performance of classification. Recall thatthecentroidpointofeachclassisnotlocatedinthegeometric centerofthisclassin theoriginal trainingset.Thus,the samples thatarefarawayfromtheircentroidcaneasilybeassigned incor-rectlytoitsadjacentclasses.ThisisthereasonthatCBCmodelhas thepoorperformanceintheoriginaltrainingset.However,SEcan makethecentroidofeach classclosetoitsgeometricalcenterby deletingsamplesnearthecentroidconstantly.Thereby,the perfor-manceofCBCshouldbeimprovedinthereducedtrainingset. Acknowledgements
Theauthorswouldliketothanktheanonymousrefereesforthe valuablecommentsandsuggestionswhichhelpustoimprovethis paper.This work hasbeen supported by MoE-CMCC (Ministry of Educationof China - China Mobile Communications Corporation) JointScienceFundundergrantMCM20130661.
References
[1] J.-x.Dong,A.Krzyzak,C.Y.Suen,FastSVMtrainingalgorithmwith decompo-sitiononverylargedatasets,IEEETrans.PatternAnal.Mach.Intell.27(4) (2005)603–618.
[2] V.N.Vapnik,V.Vapnik, StatisticalLearning Theory,vol.1,WileyNew York, 1998.
[3] M.Kawulok,J.Nalepa,Dynamicallyadaptivegeneticalgorithmtoselect train-ingdataforSVMs,in:AdvancesinArtificialIntelligence–IBERAMIA,Springer, 2014,pp.242–254.
[4] L.Guo,S.Boukir,FastdataselectionforSVMtrainingusingensemblemargin, PatternRecognit.Lett.51(2015)112–119.
[5] H.G.Jung,G.Kim,Supportvectornumberreduction:surveyandexperimental evaluations,Intell.Transp.Syst.IEEETrans.15(2)(2014)463–476.
[6]S.S.Keerthi,S.K.Shevade,C.Bhattacharyya,K.R.K.Murthy,Improvementsto platt’sSMOalgorithmforSVMclassifierdesign,NeuralComput.13(3)(2001) 637–649.
[7]A.J. Smola, B. Schölkopf, Sparse greedy matrix approximation for machine learning,12,MorganKaufmann,2000,pp.63–74.
[8]Y.-J.Lee,O.L.Mangasarian,RSVM:reducedsupportvectormachines.,in:SDM, vol.1,SIAM,2001,pp.325–361.
[9]J.C.Platt,12fasttrainingofsupportvectormachinesusingsequentialminimal optimization,Adv.kKrnelMethods(1999)185–208.
[10]S.Fine,K.Scheinberg,EfficientSVMtrainingusinglow-rankkernel represen-tations,J.Mach.Learn.Res.2(2002)243–264.
[11]X.Yang,J.Lu,G.Zhang,Adaptivepruningalgorithmforleastsquaressupport vectormachineclassifier,Softcomput14(7)(2010)667–680.
[12]J. Balcázar, Y. Dai, O. Watanabe, A randomsampling technique for train-ingsupportvectormachines,in:AlgorithmicLearningTheory,Springer,2001, pp.119–134.
[13]M.B.DeAlmeida,A.dePáduaBraga,J.P.Braga,SVM-KM:speedingSVMs learn-ingwithaprioriclusterselection andk-means,in:Neural Networks,2000. Proceedings.SixthBrazilianSymposiumon,IEEE,2000,pp.162–167.
[14]X.-L.Xiao,L.-Y.Li,X.Zhang, CM-SVMmethodforimprovingtrainingspeedof VMC,Comput.Eng.Design22(2006)3–9.
[15]N.Jankowski,M.Grochowski,ComparisonofinstancesseletionalgorithmsI. algorithmssurvey,in:InternationalConferenceonArtificialIntelligenceand SoftComputing,Springer,2004,pp.598–603.
[16]E.Pekalska,R.P.Duin,P.Paclik,Prototypeselectionfordissimilarity-based clas-sifiers,PatternRecognit.39(2)(2006)189–208.
[17]D.R.Wilson,T.R.Martinez,Reductiontechniquesfor instance-basedlearning algorithms,Mach.Learn.38(3)(2000)257–286.
[18]W.Lam,C.-K.Keung,D.Liu,Discoveringusefulconceptprototypesfor classifi-cationbasedonfilteringandabstraction,IEEETrans.PatternAnal.Mach.Intell. 24(8)(2002)1075–1090.
[19]S.Garcia,J.Derrac,J.Cano,F.Herrera,Prototypeselectionfornearestneighbor classification:taxonomyandempiricalstudy,IEEETransPatternAnalMach In-tell34(3)(2012)417–435.
[20]J.C.Bezdek,L.I.Kuncheva,Nearestprototypeclassifierdesigns:anexperimental study,Int.J.Intell.Syst.16(12)(2001)1445–1473.
[21]Á.Arnaiz-González,J.-F.Díez-Pastor,J.J.Rodríguez,C.García-Osorio,Instance selectionoflinearcomplexityforbigdata,Knowl.BasedSyst.000(2016)1–13.
[22]Á.Arnaiz-González,J.F.Díez-Pastor,J.J.Rodríguez,C.I.García-Osorio,Instance selectionforregressionbydiscretization,ExpertSyst.Appl.54(2016)340–350.
[23]M.B. Stojanovi´c, M.M. Boži´c, M.M. Stankovi´c, Z.P. Staji´c, A methodology for trainingsetinstanceselection usingmutualinformationintimeseries pre-diction,Neurocomputing141(2014)236–245.
[24]P.Hart,Thecondensednearestneighborrule,IEEETrans.Inf.Theory14(3) (1968)515–516.
[25]J.Ullmann,Automaticselectionofreferencedataforuseinanearest-neighbor methodofpatternclassification(corresp.),IEEETrans.Inf.Theory20(4)(1974) 541–543.
[26]I.Tomek,TwomodificationsofCNN,IEEETrans.SystemsManCybern.6(1976) 769–772.
[27]K.C.Gowda,G.Krishna,Thecondensednearestneighborruleusingthe con-ceptofmutualnearestneighborhood,IEEETrans. Inf.Theory25(4)(1979) 488–490.
[28]V.S.Devi,M.N.Murty,Anincrementalprototypesetbuildingtechnique, Pat-ternRecognit.35(2)(2002)505–513.
[29]F.Chang,C.-C.Lin,C.-J.Lu,Adaptiveprototypelearningalgorithms:theoretical andexperimentalstudies,J.Mach.Learn.Res.7(10)(2006)2125–2148.
[30]F.Angiulli,Fastnearestneighborcondensationforlargedatasetsclassification, IEEETrans.Knowl.DataEng.19(11)(2007)1450–1464.
[31]J.A.Olvera-López,J.A.Carrasco-Ochoa,J.F.Martínez-Trinidad,Anewfast pro-totypeselectionmethodbasedonclustering,PatternAnal.Appl.13(2)(2010) 131–141.
[32]B.V.Dasarathy,Minimalconsistentset(MCS)identificationforoptimalnearest neighbordecisionsystemsdesign,IEEETrans.Syst.ManCybern.24(3)(1994) 511–517.
[33]G.Ritter,H.Woodruff,S.Lowry,T.Isenhour,Analgorithmforaselective near-estneighbordecisionrule,IEEETrans.Inf.Theory21(6)(1975)665–669.
[34]R. Barandela,F.J.Ferri,J.S.Sánchez,Decisionboundarypreservingprototype selectionfornearestneighborclassification,Int.J.PatternRecognit.Artif.Intell. 19(06)(2005)787–806.
[35]J.C.Riquelme,J.S.Aguilar-Ruiz,M.Toro,Findingrepresentativepatternswith orderedprojections,PatternRecognit.36(4)(2003)1009–1018.
[36]Y.Wu,K.Ianakiev,V.Govindaraju,Improvedk-nearestneighborclassification, PatternRecognit.35(10)(2002)2311–2318.
[37]H.A. Fayed,A.F.Atiya, Anovel templatereductionapproachforthe-nearest neighbormethod,IEEETrans.NeuralNetw.20(5)(2009)890–896.
[38]H. Shin, S.Cho,Neighborhoodproperty–basedpattern selectionfor support vectormachines,NeuralComput.19(3)(2007)816–855.
[39]H.-L.Li,C.Wang,B.Yuan,AnimprovedSVM:NN-SVM,Chin.J.Comput. Chi-neseedition26(8)(2003)1015–1020.
[40]E.M. Ferragut,J. Laska,Randomized samplingfor largedata applicationsof SVM,in:MachineLearningandApplications(ICMLA),201211thInternational Conferenceon,vol.1,IEEE,2012,pp.350–355.
[41]A.Lopez-Chau,L.L.Garcia,J.Cervantes,X.Li,W.Yu,Dataselectionusing de-cisiontreeforSVMclassification,in:ToolswithArtificialIntelligence(ICTAI), 2012IEEE24thInternationalConferenceon,vol.1,IEEE,2012,pp.742–749.