A Universal Framework for Inductive Transfer Parsing across Multi typed Treebanks
Full text
Figure
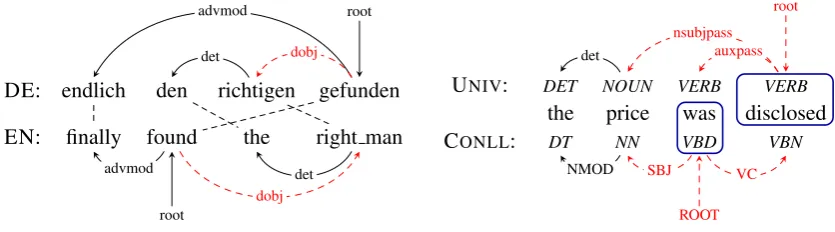
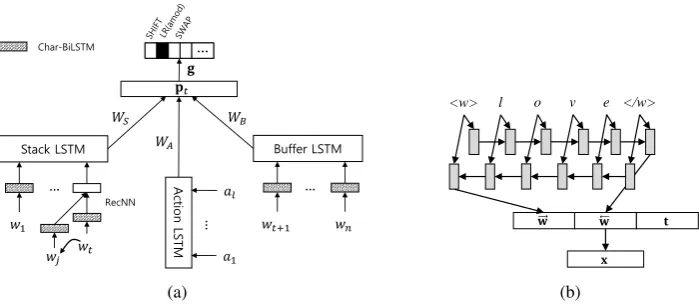
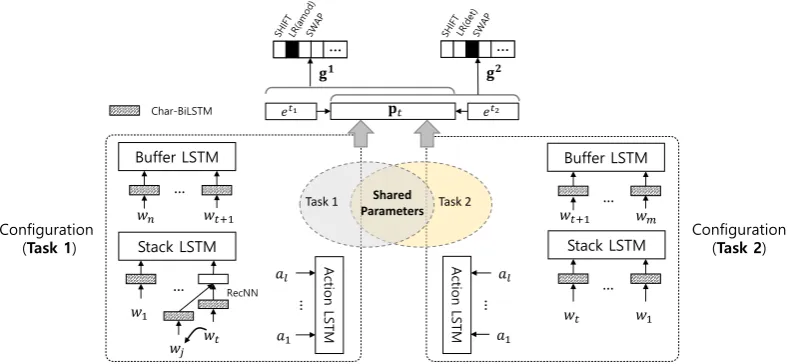
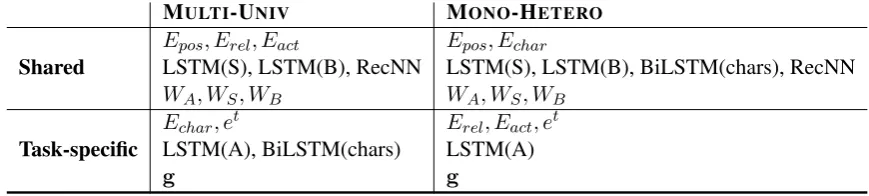
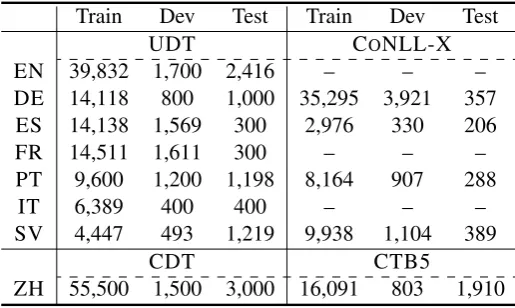
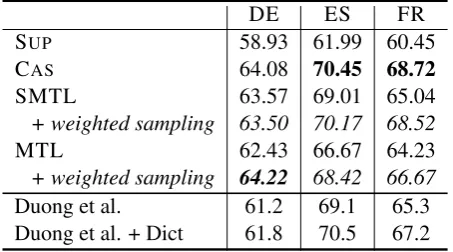

Related documents
Even if a company is not required to have an audit, it must still keep adequate accounting records, prepare annual financial statements, give the financial statements to the
We were paid to find out if people with learning difficulties were involved in the other twelve projects and to share the lessons of what makes good involvement work.. Our project
43-IND.PR0D CONSUMER GOODS 44-IND.PROD MINING + QUARRYING 50-NET PROD ELECTRICAL ENERGY TOTAL 52-NET PROD THERMAL ENERGY 53-NET PROD NUCLEAR ENERGY. 60-INTERNATIONAL
In such a ten year time frame e-Science data will routinely be automatically annotated and stored in a digital library offering the 'usual' digital library services for
Dans la série E «Méthodes», Eurostat publie les nouveaux codes, leur concordance avec l'ancienne nomenclature Nimexe 1987 ainsi que les nouvelles relations avec les
Sequences in different species that are related to each o th er by a speciation event are called orthologues, while sequences w hich are related to each o ther
We tested the effects of photoperiod, water and food availability on body mass, reproductive status and arginine vasopressin receptor 1A (Avpr1a) mRNA expression in males
This correlation between motility and the level of phospho-PKC substrates, as well as the inhibitory effect of chelerythrine, calphostin C and Gö6976 on these two phenomena (Figs ·
