Keyword Query Suggestion Using
Document Proximity
Kajal P. Davange, Prof. P. N. Kalavadekar
Department of Computer Engineering, SRES COE, Kopargaon, Maharashtra, India
ABSTRACT: Keyword recommendation in internet search helps user to access nearest information without having to known how to express their queries. Past catchphrase prescribe techniques do not consider the area of client and the inquiry result the spatial nearness of client to the recovered result is not taken as a calculated in the proposal. The related of search information in numerous application area based administrations is known to be related with report to the inquiry client. The related of search information in many application location based services is known to be correlated with document to the query user. Each query is related to one of topics identified in the conversion fragments preceding the recommendation and is submitted to a search engine over the English. In this paper a KD-Graph fetch the related information of user query and location with the document.
KEYWORDS: query suggestion,spatial databases,document proximity.
I. INTRODUCTION
Keyword suggestion (also known as query suggestion) has become one of the most essential features of business web hunt engines. Then afterward submitting a keyword query, the client may not be fulfilled with the outcome, so the keyword suggestion module of the search engine prescribes a z set of m keyword queries are generally to the users scan in the right manner [1].Viable keyword suggestion strategies are based on click majority of the data from inquiry logs and inquiry session data, or inquiry subject models new keyword suggestions can be determined according to their semantic importance to the original keyword inquiry. The previous techniques give location-aware keyword query suggestion (LKS), such that the recommended queries retrieve documents not only related to the user information needs but also located close to the client area [2].Many operation of a spatial database are advantageous from multiple points of view over suitable data. For object, in a geography information system, range search can be utilization to discover all restaurants in a certain area, same time nearest neighbor retrieval can find the restaurant closest to a provided address. The previous keyword suggestion systems do not consider the areas of the clients and the inquiry outcomes. Clients frequently bring challenges in expressing their web scan needs they might not think those keywords. After pro-viding a keyword query, the client may not be fulfilled those outcomes. This data gather due to the popularity of spatial keyword search Google transformed a daily average of 4.7 billion queries in 2011 a considerable portion of which have local function and target spatial web objects.
II. REVIEW OF LITERATURE
suggestion Method based on random concepts of walks and themes (QuS-RWTC). The method is based on data of registration of queries and suggestions for other mature searchers, who could give suggestions more, complete and get higher coverage. Further, the document also performs concepts procedures to be reordered the candidate’s questions, which make the suggestions more exactly, since they are more satisfied with the user’s initials Intention. The results demonstrate the excellent performance of QuS-RWTC method compared to traditional methods and validate the importance of the subject concepts [1].
later a long time, it has been watched that the always interesting and up and coming distribution medium is the World Wide Web. Much of the internet substance is unstructured in order to accumulate and make sense of said information It is exceptionally boring web servers around the world produce a huge sum of information approximately the browsing exercises of web users. Several analysts have considered these so-called networks access the enrollment information to get it and way better characterize the web clients The information can be improved with data about content of the pages gone by and the root (eg geographical, organizational) of the demands. The objective of this project is Analyze client behavior by extricating wealthy web access registration information.The diverse mining strategies of utilizing the Net to the extraction of valuable highlights
is talked about and utilizes all of these strategies for gathering space clients to consider them Total behaviors The commitments of this Theses are an enhancement of information that is substance and beginning visualization based on three trees and visit route arrangements. This see effectively permits Interpretable tree see of models with highlights important data. The comes about of this venture can be connected for distinctive purposes; counting promoting, web consultancy on substance, (re) organizing of diverse websites other e-business forms, such as suggestions and advertiser systems. It moreover classifies the finest pertinence records based on the successful meeting Best K e proficient information recuperation framework. Channel web archives give pertinent substance in the look motor Comes about page (SERP) [2].
In recent years, the independent economy has been a novelty normal. In the independent market of service providers, people sell your skills or labor as an Internet service platform to help others with some special micro-activities. As this kind of human service ecosystem is in the rapid growth phase, it is flooded with a variety of services whose quality is irregular. Very often, in front of these services, customers hesitate to make the decision. The causes of this doubt they are: (a) customers do not know these services well, including description and category of explicit service;
(b) Customers do not know their requests well. Most of time, customers only have a general / widespread goal, but they do not have sense of the requirements in detail. Therefore, this study aims to proposing a method of recommending human services for Fuzzy customer requirement Experimental data of this the study is collected by Fiverr.com, which is one of the most important Human services market driven by the offer. When analyzing the transaction data, any details of services, independent workers, customers, and their relationships will be extracted to build a bid request graphic report. In this study, the client is blurred the description of the requirement will be transferred to a query sub graph, which is the voice of an evolved sub graph that corresponds algorithm. This algorithm will help to recover the recommended services (combinations). Furthermore, a guide The Q A approach is designed to integrate customer focus requirement, so that the matching algorithm of the sub graph can recover better results [3].
component. Test outcomes show that the recommended strategy it exceeds the reference strategy when two or more can be used consultations in a difficult session [4].
Similarity computation among queries is a central step of query recommendation based on click information in search log. In this step, weights of clicked URLs or clicked document terms, which may have a large influence on similarity computation results, are mostly counted based on occurrence. However, counting weights based on co-occurrence are unusually disturbed by irrelevant feedbacks in search log, which may decrease the accuracy of the query similarity computation. Este paper proposes to technique that computes comparability among queries dependent upon ”Query - Clicked Sequence” model, which counts weight of clicked document term by density of documents holding this expression with respect to clicked sequence, and filters content of unimportant documents during comparability calculation. A series of experiment results show that this method can precisely count the weights of terms, and increase the accuracy of query comparability calculation, accordingly increase the precision of query recommendation [5].
The data on the web has different Patterns and exam-ining this pattern is a challenging task. Accuracy and memory evaluate the performance of search engines. The precision can only be achieved with greater functionality of relevant comments. Today large number of users sends queries to search engines broadband, subjective and ambiguous in na-tures. Objective and facilitates refining the relevance of search engines and filtering noises results Relevance procedure for assigning comments has been widely used in the information retrieval research community to increase the accuracy and recovery of the system. The feedback procedure is it has been classified as implicit feedback and explicit feedback. This research recommend (Pseudo) Explicit: one-click feedback system to map user search goals. The analysis of search records helps discovering search for ambiguous queries, for which proposals for system clusters, comment sessions. One click of user in feedback included that present the information has been searched by the user. The pseudo text documents are created for the grouping of sessions. The improved k-means cluster has been improved incorporated to reduce the search time clusters. Inverted indexing is used in a supervised manner to Sort information from the web and create object classes. The evaluation of this research has been done in MAP (average average) Accuracy) CAP (cumulative average accuracy) VAP (voted Average precision) with the comments of the users as evaluation method [6].
In this paper another inquiry suggestion paradigm, inquiry Suggestion with broadening and Personalization that adequately incorporate broadening and personalization under one unified framework. In the QS-DP, the suggested queries are effectively diversified to cover separate facets of the input inquiry and the positioning of the suggested queries are personalized to guarantee that the highest ones that align with a users personal inclination. They recommend another rep-resentation for inquiry log. The recommended multibipartite-chart representation comprehensively captures different sorts of relations between search queries in query log. Based on the multi-bipartite-graph representation,they plan two methodolo-gies to identify the most relevant suggestion candidate[7].
It is common that the objects in a spatial database (e.g., restaurants/hotels) are related with keyword(s) to indicate their businesses/services/features. An curiously problem known as Closest Catchphrases look is to inquiry objects, called catch-phrase cover, which together cover a set of query keywords and have the minim minter-objects remove. In recent a long time, we watch the expanding accessibility and importance of catch-phrase rating in protest assessment for the better decision mak-ing. This propels us to examine a generic version of Closest Catchphrases look called Best Keyword Cover which considers inter-objects separate as well as the keyword rating of objects. The standard calculation is inspired by the strategies of Closest Catchphrases look which is based on exhaustively combining objects from distinctive inquiry keywords to create candidate catchphrase covers.When the number of inquiry watchwords increments, the execution of the pattern calculation drops drastically as a result of gigantic candidate catchphrase covers created. To assault this disadvantage, this work proposes a much more adaptable calculation called watchword closest neighbor extension (keyword-NNE). Compared to the standard calculation, keyword-NNE calculation altogether diminishes the number of candidate watchword covers created. The in-depth
Data space is one of the emerging approaches to man-aging heterogeneous data sources. However, data spaces differ from conventional data integration approaches. Heterogeneous data sources with a pay-per-use integration approach. When data spaces meet unstructured data, indexing is the only way to answer queries based on the best effort. As far as we know, we have not worked on the provision of relevant results for a query beyond those provided by the indexation without manual efforts. The approach proposed in this document stores. The relationships between the users queries. These relationships are used to improve the search results in the data space environment. The stored relationships are AND, OR and subsequent relationships (one keyword after the other). The proposed work is based on the way in which the search engines handle the same problem [9].
In this paper an inquiry suggestion algorithm based on ranking queries with the hitting time on a extensive scale bipartite graph. This system captures the semantic consistency between the suggested inquiry and the inquiry provided by user. Experiments show time is effective to produce seman-tically reliable inquiry suggestions. The suggested algorithm and its variations can effectively execute enormous queries, accommodating inquiry suggestion[10].
III. SYSTEM OVERVIEW
Framework giving keyword suggestions that are important to the client data required and during the same period can retrieve important documents close ideas, but aims at optimizing distinctive objective functions. Keyword prescribes in internet search aides clients to access closest data without having to know how to decisively express their queries. A baseline algorithm enlarged from algorithm BCA is acquainted to solve the issue. Partition-based algorithm (PA) which computes the scores of the candidate keyword queries at the segment level and uses a lazy mechanism to incredibly decrease the computational cost.
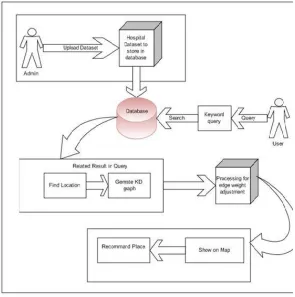
Phase 1: Admin upload the hospital dataset. Then Preprocessing on this dataset and store all information into database.
Phase 2: User enters the query for searching the any hospital location. Our system find the distance between the users enter query keyword and document location. Find the distance of keyword and document.
Display Result: This distance display on map and we recommend the place of the user.
IV. SYSTEM ANALYSIS
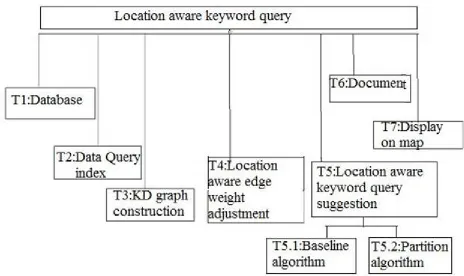
Following figure shows the breakdown structure of the system
Fig. 2. Breakdown Structure
T1: Database: Database construction and selection.
T2: Data Query Index: System will get query and provide index of query.
T4: Location Aware Edge Weight adjustment: Conform the edge weights in the KD graph built on the spatial connections the middle of the area of the query backer and the hubs of the KD-graph.
T5: Location-Aware Keyword Query Suggestion: Figure for every keyword queries a graph proximity score with admiration to kq, based on the random walk with restart procedure.
T5.1: Baseline Algorithm: A baseline algorithm (BA) used for location-aware suggestions. Steps of baseline algorithm are as follows:
1.To find the RWR based top-m inquiry recommend.
2.Start from one unit of active ink injected under hub Kq and the request in descending request.
3.Find the weight of every edge e is balanced based on q.
4.The algorithm returns the top-m candidate suggestions other than kq in C as the outcome.
T5.2: Partition Algorithm: A partition-based algorithm that isolates the keyword queries and the documents in the KD-graph G under aggregations. Steps of partition algorithm are as follows:
1. Toward every iteration, special case hub is processed, the active ink drops gradually and the end states met after too much cycle.
2. Provided for the vast number of iterations, the overhead of administering queue Q is huge.
3.Priority queue Q supports the partitions to be transformed in descending request of their keys.
4. For values of n from 500 on 10000, run a amount of examinations on randomly-ordered arrays size n and search the average number of comparisons for those examinations.
5.The algorithm returns the top-m candidate suggestions in C as the outcome.
6.Graph the average number of comparisons as a function of n Repeat the above things 14, utilizing an elective pivot selection strategy.
T6: Documents: Matched documents display to the user.
T7: Display On Map: Matched location display on map with distance.
V. CONCLUSION
more information and planning a benchmark. In expansion, subject to the accessibility of information, will adapt and test LKS for the case where the areas of the query backers are accessible in the inquiry log.
ACKNOWLEDGEMENT
I would like to thank to my esteemed guide, Prof.P. N. Kalavadekar, whose interest and guidance helped me to com-plete the work successfully. Also under the valuable help of Dr .D. B. Kshirsagar(HOD Comp.Dept.) This experience will always steer me to my work perfectly and professionally and Prof.P. N. Kalavadekar (PG Co-ordinator) who has provided facilities to explore the subject with more enthusiasm.
REFERENCES
[1] Shuyao Qi, Dingming Wu, and Nikos Mamoulis, “Location Aware Keyword Query Suggestion based on Document Proximity”,in IEEE,2015,pp.82-97.
[2] M. P. Kato, T. Sakai, and K. Tanaka, “A query suggestion log analysis”, Inf. Retr., vol. 16, no. 6, pp. 725746, 2013.
[3] Bo Long, Jiang Bian, Olivier Chapelle, Ya Zhang, “Active Learning for Ranking through Expected Loss Optimization”, in Information Science Vol. 220, 2013, pp. 269291.
[4] D. Wu, G. Cong, and C. S. Jensen, “A framework for efficient spatial web object retrieval”, vol. 21, no. 6, pp. 797822, 2012.
[5] A. Anagnostopoulos, L. Becchetti, C. Castillo, and A. Gionis “An optimization framework for query recommendation, ”, in Proc. ACM Int. Conf. Web Search Data Mining, 2010, pp. 161170.
[6] Y. Song and L.-W. He, “Optimal rare query suggestion with implicit user feedback ”, in Proc. 19th Int. Conf. World Wide Web, 2010, pp. 901910..
[7] Paolo Boldi, Francesco Bonchi, Carlos Castillo,“Query Suggestions Using Query-Flow Graphsrq’, Knowledge Based System Vol. 82, 2015, pp. 2940.
[8] Q. Mei, D. Zhou, and K. Church “Query suggestion using hitting time”, in Proc. 17th ACM Conf. Inf. Knowl. Manage, 2008, pp. 469478. [9] R. Baeza-Yates, C. Hurtado, and M. Mendoza, “Query recommendation using query logs in search engines”, in Proc. Int. Conf. Current Trends Database Technol., 2004, pp. 588596.