Dialogue Annotation for Language Systems Evaluation
Marcela Charfuel´an, Jos´e Rela ˜no Gil, M. Carmen Rogr´ıguez Gancedo,
Daniel Tapias Merino
1, Luis Hern´andez G´omez
Dep. SSR ETSIT-UPM Ciudad Universitaria Madrid (Spain)
fmarcela,jrelanio,mcarmen,[email protected]
1
Speech Tecnology Group, Telef´onica Investigaci´on y Desarrollo , S.A. C. Emilio Vargas, 6 28043 Madrid (Spain)
Abstract
The evaluation of Natural Language Processing (NLP) systems is still an open problem demanding further research progress from the research community to establish general evaluation frameworks. In this paper we present an experimental multilevel annotation process to be followed during the testing phase of Spoken Language Dialogue Systems (SLDSs). Based on this process we address some issues related to an annotation scheme of evaluation dialogue corpora and particular annotation tools and processes.
1.
Introduction
This paper addresses one of the more recent NLP re-search areas of managing dialogue annotation schemes and data formats during the testing phase of Spoken Language Dialogue Systems. The Spoken Language community has made significant progress towards this goal (Walker et al., 1998; Price et al., 1992; Minker, 1998) and most of the proposals for spoken dialogue evaluation are based on the use of information from properly designed evaluation dia-logue corpora. Generally these corpora are extracted from log files as the evaluated system is working, and no specific nor standardized annotation procedures are used to repre-sent the relevant information (recent works are reported on (DARPA, 1999; Isard et al., 1998; Dybkjoer et al., 1998)).
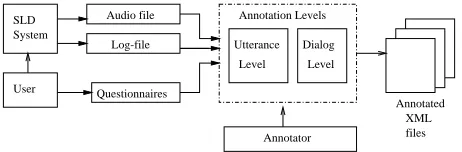
Therefore, from our point of view, two major problems arises: i) For all those important scientific efforts to de-sign standard evaluation procedures, it is very difficult, if not impossible, to test a same SLDS with different evalu-ation approaches. And ii) a huge amount of informevalu-ation that could be used for future adaptations of the system or that could be useful for other research groups is lost.Being aware of the importance of having annotated dialogue cor-pora, specially for the future development of standardized SLDS evaluation procedures and tools, we summarize our experience on this context in three main aspects:
1. An annotation scheme that, starting from log files, the
corresponding audio files and the questionnaires answered for the people involved in the evaluation, provides multiple annotation levels for:
orthographic transcriptions for user and system turns including time marks.
recognizer’s and parser’s outputs for each turn.
task delimitation (or dialogue segments when a dia-logue includes more than one task or function).
and some extra attributes added to each turn and task for correctness, completion and user satisfaction.
We use XML as basic coding language and propose some DTD files for our particular task.
2. An annotation tool for the inclusion of manual
la-bels (time marks and lala-bels for the different turns and di-alogue segments) and additional information in the multi-level XML annotation scheme. The tool let us:
transcript the user’s turns having a controlled access to the audio file.
include the objective evaluation of the human annota-tor about the parsers analysis of the recognizers out-put.
also we can annotate the correctness of the concept (speech act) finally obtained in each turn and the com-pletion and user satisfaction for each task.
The other information, system turns and recognizer’s and parser’s outputs, is extracted automatically by the tool from the corresponding log file.
3. Automatic extraction of dialogue metrics from the
annotated corpora. This is an important point to be con-sidered when designing the sequence of annotation steps. Walker et al. classify most of the commonly proposed dia-logue metrics as objective or subjective.
Objective metrics can be calculated without recourse to human judgment, and in many cases, can be logged by the spoken dialogue system so that they can be calculated automatically (i.e. number of turns or utterances or mean system response time).
Subjective metrics require subjects using the system and/or human evaluators to categorize the dialogue or utterances within the dialogue along various qualita-tive dimensions (i.e. user satisfaction or percentage of contextually appropriate system utterances).
con-</evaluation>
_______________________________________________________
The next scheme shows the DTD structure of the previ-ous XML file.
_______________________________________________________ <!-- Global evaluation DTD file -->
<!-- "Global-EvalAtos.dtd" -->
<!ENTITY % hrefAttr ’href CDATA #REQUIRED xml:link CDATA #FIXED "simple" show CDATA #FIXED "embed" actuate CDATA #FIXED "auto"’> <!ELEMENT evaluation (question*, eval_question*)> <!ATTLIST evaluation
id ID #REQUIRED <!ELEMENT question EMPTY>
<!ATTLIST question
id ID #REQUIRED description CDATA #REQUIRED >
<!ELEMENT eval_question (eval*)> <!ATTLIST eval_question
id ID #REQUIRED %hrefAttr;
>
<!ELEMENT eval EMPTY> <!ATTLIST eval
question_id IDREF #REQUIRED value (1|2|3|4|5|6|7|8|9|10) #REQUIRED >
_______________________________________________________
4.
Processing Methodology and Tools
In the previous Section we have described how infor-mation from different sources are integrated into a dialogue annotation framework. We have also presented the global annotation strategy we propose following two sequential annotation steps at what we have referred to as utterance level and dialogue level. Now we discuss the annotation methodology which combines manual procedures from a human annotator with automatic processing of previously annotated data. This methodological approach allows us to have interactive feedback between different annotation cri-teria and their particular dialogue metrics results. Thus for example we could see on-line the possible impact of the speech recognizer for different segments in a dialogue. In subsections 4.1. and 4.2. we will describe the annotation process and related tools for the first annotation step at ut-terance level and the second annotation step at the dialogue level respectively.
4.1. Annotation process and tools at utterance level
One of the main characteristics of the first annotation stage at utterance level is the requirement of an easy access to the audio speech file. For this we have developed an an-notation tool for the utterance level that we call ULAT (Ut-terance Level Annotation Tool). ULAT has been developed under Tcl/Tk programming language including the freely distributed package SNACK from KTH (KTH, 1997), that provides an easy way to design a proper audio interface.
We can summarize the main processing stages at utter-ance level as the following ones:
Manual transcription of user’s turns having a con-trolled access to the audio file.
Automatic extraction of information related to system turns, recognizer’s and parser’s outputs, and subjec-tive information of the user from log files and external information files.
Inclusion of subjective information from a human evaluator or annotator, for example, whether or not the user’s concept (dialogue act) is lost after the speech recognizer and parser analysis.
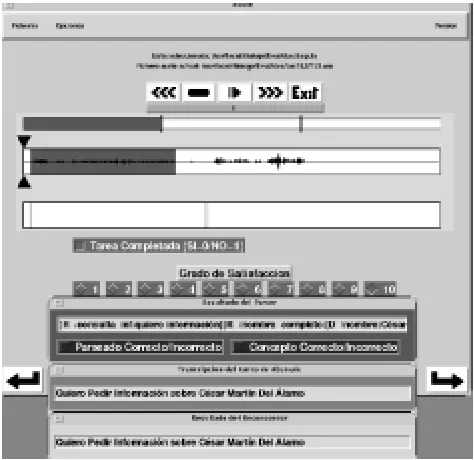
Figure 2: ULAT Annotation Graphic Interface
The inputs to the ULAT tool are: a recorded audio file of the dialogue, a log file provide by the system and an ex-ternal information file (questionnaires). Figure 2 is a view of the graphic interface of the ULAT tool and shows all the information of a user turn. The annotator only has to mark a section of the speech wave, corresponding to a turn, lis-ten to it and check if the information that the ULAT tool has presented for the turn is correct. The beginning and end samples are obtained by the tool and recorded automatically in the output file. Additional features of the ULAT tool are:
During the annotation of a user turn, there are three windows in the graphic interface containing the rec-ognized text, the parsed text and the transcription text. This last window appears with the recognized text, which sometimes is the same or very close to what the person really said (i.e. the correct transcription); in this case the annotator’s tasks consist only of listen to the recording to verify its correctness. In that way the orthographic transcription of utterances become fast and easy.
4.2. Annotation process and tools at dialogue level
Because the files generated by the ULAT tool are in XML format they can be processed directly, previous elabo-ration of stylesheet files, by the MATE Workbench (MATE, 1998) or by a great variety of available XML tools at differ-ent SLDS research cdiffer-enters. We made a stylesheet to anno-tate tasks (dialogue segments) an add the attributes of cor-rectness and completion of these segments. Optionally we also use the query processor of the MateWorbench to gener-ate metrics and statistics (this capability of Mgener-ateWorkbench is still under revision).
In this way we reach one of our objectives: to develop a scheme to annotate evaluation dialogues suitable to au-tomatic extraction of different parameters and metrics like those suggested in PARADISE framework.
5.
Annotation and Evaluation Example
We now present our experience with the dialogue an-notation scheme and related anan-notation tools that we have previously described, for the evaluation of an Automatic Telephone Operator System (ATOS) (Alvarez et al., 1996). The ATOS system provides simple telephonic services like: automatic phone call, multi-conference, voice messaging, automatic telephonic directory etc. The methodology that we have followed for the evaluation process is:
Test scenarios definition and preparation of question-naires for the subjects involved in the evaluation.
Testing the system following the scenarios and com-pleting the questionnaires. Thus audio files, log files and external information files are generated at this test stage.
Annotation of recorded dialogues at utterance level.
Annotation at dialogue level: dialogue segment tag-ging, addition of recognition performance informa-tion, and dialogue metrics for evaluation according to the PARADISE framework.
Analysis of evaluation results.
The evaluation of our ATOS SLDS was done by se-lecting a subset of twelve different telephonic functions or tasks. A different identification code was assigned to each task. In order to have a proper preliminary evaluation of the system, a population of 30 subjects was selected, all of them were novice users of the ATOS system. Thus every subject involved into the evaluation process was informed on the basic functionality of ATOS and on the evaluation procedure.
As an illustration of the possibilities of using the final annotated files for SLDSs evaluation, we present some re-sults for ATOS using the information stored in the Dialogue Database EvalAtos of XML annotated files. This results were obtained applying dialogue metrics for each task in ATOS, but we could also obtain evaluation results for the global behaviour of the system.
Table 1 contains dialogue metrics for the global be-haviour of ATOS taking into account all the different tasks used for evaluation purposes. Here we have calculated the
Task US TT LT
T11 5.9200 0.3000 8.6400 3.2400 T12 6.1400 0.2222 8.0700 3.0500 T13 7.4200 0.4615 7.4200 2.1200 T41 5.6800 0.2727 8.4300 3.5900 T42 6.2800 0.3000 8.0700 2.7900 T51 5.9300 0.2500 13.200 3.8500 T52 3.5300 -1.166 11.690 4.5500 T53 6.3300 0.4231 16.260 4.6500 T61 5.8700 0.3846 10.250 3.5000 T62 5.2500 0.2727 13.870 4.3700 T71 5.5000 0.2000 16.810 4.6600 T81 4.6200 0.3333 16.620 7.7200
Table 1: Performance Metrics for a PARADISE Case Study: US = User Satisfaction,= Kappa coefficient, TT = Turns number for each Task, LT = Percentage of Lost Turns (turns with no correct concept)
coefficient as in (Walker et al., 1998) and we have chosen as cost measures the average number of turns for each task (TT) and the percentage of lost turns (LT), in order to do an analysis of variance (ANOVA) and estimate a performance function. (The analysis of results of this particular system can be seen in (Rela˜no Gil et al., 1999)).
6.
Conclusions
In this paper we have presented a general framework for dialogue annotation in the context of the evaluation of Spoken Language Dialogue Systems. Our emphasis has been on two major issues: The design of a simple annota-tion scheme suitable for the wide range of dialogue evalu-ation methodologies, and a general annotevalu-ation process im-plemented through XML coding and the use of standard tools and programming languages.
The resulting annotation framework is quite open and it can be easily configured or adapted to different approaches for SLDS assessment.
As we can see there are file references among different files, which is important in this kind of data base of multiple levels of annotation.
Following the annotation process both automatic and manual procedures have been presented to include objec-tive and subjecobjec-tive data both from the user who is testing the system and from the human annotator. To examine the viability of the proposed coding scheme and annotation tools, they are being tested while evaluating a real SLDS us-ing different dialogue metrics under the PARADISE frame-work. Although high flexibility is presented in this partic-ular case, it is obvious that more evaluations of different SLDS are needed.
7.
References
J. Alvarez, J. Caminero Gil, C. Crespo Casas, and D. Tapias Merino. 1996. The natural language processing module for a voice asisted operator at telef´onica i+d. In ICSLP
’96, Philadelphia, USA.
L. Dybkjoer, N. O. Bernsen, R. Carlson, L. Chase, N. Dahlback, K. Failenschmid, U. Heid, P. Heisterkamp, A. Jonsson, H. Kamp, I. Karlsson, J. v. Kuppevelt, L. Lamel, P. Paraubek, and D. Williams. 1998. The disc approach to spoken language systems development and evaluation. In Proceedings of First International
Confer-ence on Language Resources and Evaluation, Granada
Spain.
Amy Isard, David McKelvie, and Henry S. Thompson. 1998. Towards a minimal standard for dialogue tran-scripts: A new sgml architecture for the hcrc map task corpus. In Proceeding of International Conference on
Spoken Language Processing, Australia.
KTH. 1997. Snack and tcl/tk scripting language. http://www.speech.kth.se/snack/.
MATE. 1998. Mate. project overview.
http://mate.nis.sdu.dk/.
Wolfgang Minker. 1998. Evaluation methodologies for in-teractive speech systems. In Proceedings of First
Inter-national Conference on Language Resources and Evalu-ation, Granada Spain.
Jos´e Rela˜no Gil, Daniel Tapias, M. Carmen Rodr´ıguez, Marcela Charfuel´an, and Luis Hern´andez G´omez. 1999. Robust and flexible mixed-initiative dialogue for tele-phone services. In Ninth Conference of the European
Chapter of the Association for Computational Linguis-tics, Bergen, Norway. Proceedings of EACL ’99.
Patti Price, Lynette Hirschman, Elisabeth Shriberg, and Elizabeth Wade. 1992. Subject-based evaluation mea-sures for interactive spoken language systems. In
DARPA Proceedings of Speech and Natural Language Workshop.
M.A. Walker, D. J. Litman, C. A. Kamm, and A. Abella. 1998. Evaluating spoken dialogue agents with paradise: Two case studies. Computer Speech and Language, 12:317–347.