Bayesian Change Point Analysis of Copy Number Variants Using Human Next Generation Sequencing Data
148
0
0
Full text
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)(13)
(14)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
(28)
(29)
(30)
(31)
(32)
(33)
(34)
(35)
(36)
(37)
(38)
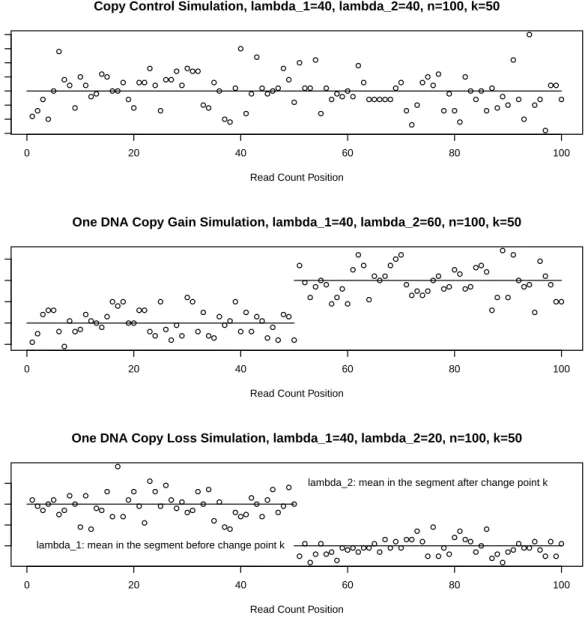
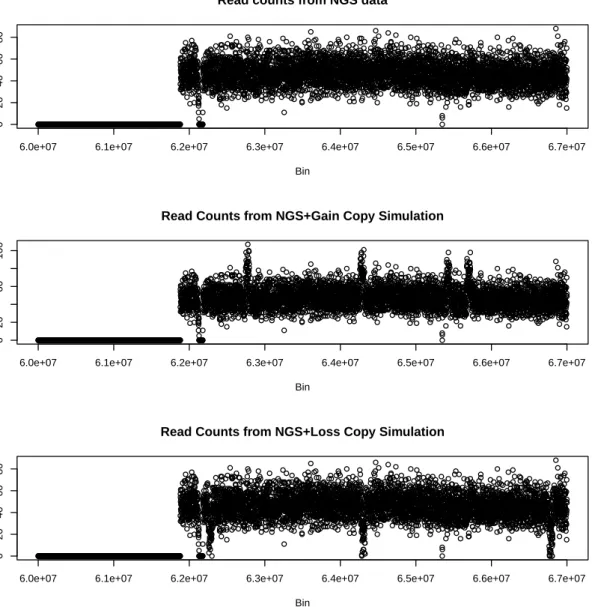
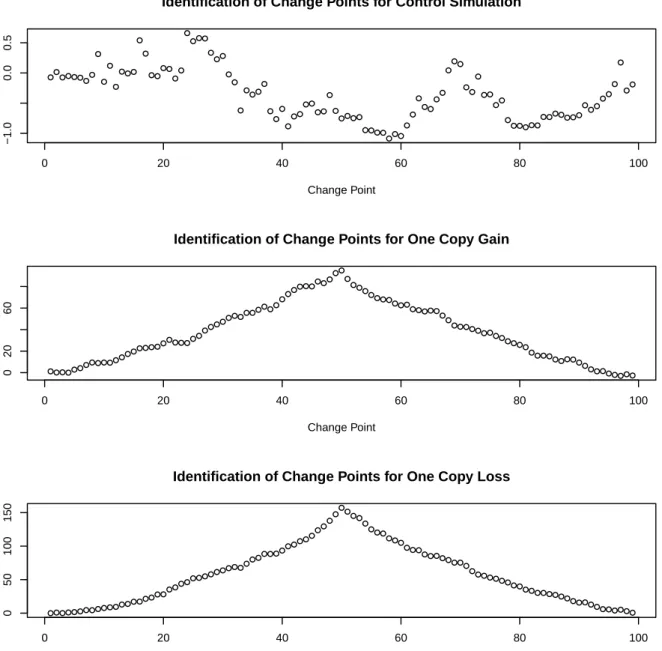
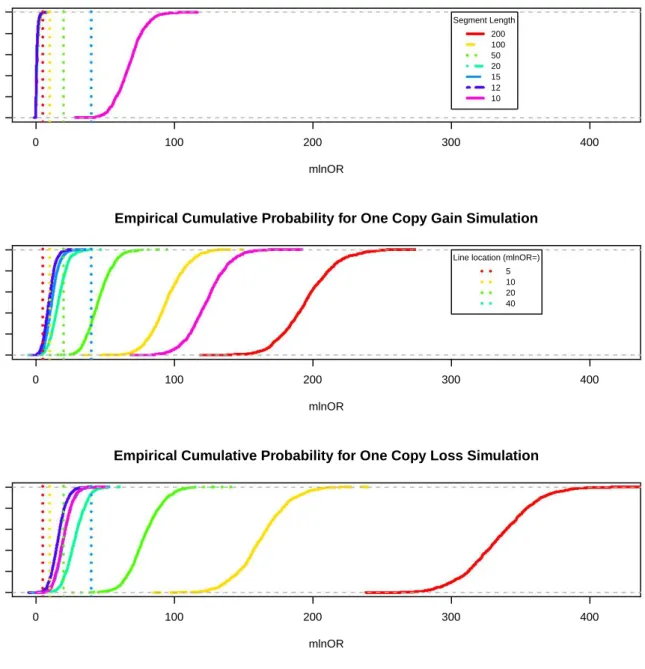
Figure


+7
Related documents
The aim of our study was to analyze two sturgeon species, Huso huso and Acipenser ruthenus and their interspecific hybrid - bester, using nuclear markers, in order to set up
Learning and academic analytics in higher education is used to predict student success by examining how and what students learn and how success is supported by
Prevalence and intensity of helminths found in stenodermatine bats from western Amazonian Brazil, and lick sites from which infected bats were captured.. Helminth Host Prevalence
A sample of 108 women, aged between 35 and 55 years, completed questionnaire measures of body dissatisfaction, appearance investment, aging anxiety, media exposure (television
The Government’s guidelines for external reporting for state- owned companies adopted in November 2007, (see pages 17–18 and 22–31) with special requirements on state-owned companies
Our consolidation solution is a disciplined, systematic approach that allows clients to realize significant operating cost savings in their enterprise contact centers..
Bankruptcy and Creditor Debtor Rights / Insolvency and Reorganization Law Litigation - Bankruptcy.
Beyond the implications outlined above (indications regarding managerial motives; insight into managerial challenges involved with mergers; identification of value-decreasing
