8
A Systematic Approach for Analyzing the Patient’s Future Diseases Using
Incremental Semi Supervised Clustering
Mr.A.M.RAVISHANKAR
(ASSISTANT PROFESSOR),
Ms.M.R.RAMYA
(PG SCHOLAR),
(DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING, JAY SHRI RAM GROUP OF INSTITUTION,TIRUPUR,INDIA,TAMILNADU)
Abstract:
- In many machine learning domains (e.g. Text processing, bioinformatics), there is a large supply of
unlabeled data but limited labeled data, which can be expensive to generate. Consequently, semi-supervised
learning, learning from a combination of both labeled and unlabeled data, has become a topic of significant recent
interest.It Overcomes the three limitations of the Traditional cluster ensemble approaches: They do not make use of
prior knowledge of the datasets given by experts. Most of the conventional cluster ensemble methods cannot obtain
satisfactory results when handling high dimensional data. All the ensemble members are considered, even the ones
without positive contributions. In this project First include our normal data. Then include our diabetic patient data in
our dataset. After that compare our data and to show result is positive or negative. The incremental ensemble
member selection process is newly designed to judiciously remove redundant ensemble members based on a newly
proposed local cost function and a global cost function, Finally, a set of nonparametric tests are adopted to compare
multiple semi-supervised clustering ensemble approaches over different datasets to produce the satisfactory report.
Keywords: -
clustering analysis, diapetic profile, Incremental Ensemble, semi supervised clustering1. INTRODUCTION
In this area, we have overcome the three limitations of the cluster ensemble approaches.It consider the prior knowledge of the data by the exports .It handles the high dimensional data by keeping satisfactory results. It process both positive and negative results by the experts for considering the ensemble members .As a result we can decide that what diseases are attacked the members in high dimensional data clustering by using Incremental semi supervised clustering. After deciding process completed it spitted the people in manner of the systematic approach .this approach categorize who people belongs to what diseases (diabetic) and also detect what diseases will be attacked in future .it has been developed by the exports for people who should not allowed for the further troubling situation because it may causes the depth of the effects for the people. This process will be done by produce the module report and its goes for the exports for satisfactory results.
2. PROBLEM DESCRIPTION
2.1 EXISTING SYSTEM
In Existing System We can use supervised clustering Algorithms .So, The output of the clarity is low
percentage.They do not consider how to make use of prior knowledge given by experts,Which is Represented by Pairwise constrains.Pairwise constraints are often defined as the Must-link constraint and the Cannot-link constraints.The Must-link constraints means that two features vectors should be assigned to the same cluster,While the cannot-link constraint means that two features vectors cannot be assigned to the same cluster.Most of the cluster ensemble methods cannot achieve the satisfactory results on high dimensional datasets.clustering can be therefore be formulated as a Multi-objective optimization problem
2.1.1 DISADVANTAGES
In this Existing System, the output quality of the process is very low at the end of the process it clearly explains that the consumption of the time is high. so its very struggle to operate the dataset on high dimensional data.
.
2.2 PROPOSED SYSTEM
In this project propose a new
9
development of an incremental ensemble member selection process based on a global objective function and a local objective function. In order to design a good local objective function, we also propose a new similarity function to quantify the extent to which two sets of attributes in the subspaces are similar to each other. It is overcome the existing method. Then we can use the high dimensional data.2.2.1ADVANTAGES
The Systematic approach of the incremental semi supervised clustering makes the Time consumption is low. At the end of the process it has been state that Output quality is high after consolidated by the exports of the area so it allows the High dimensional data is being used for the people when critical problem happened for human health.
3. MODULE DESCRIPTION
This Project has four main modules to demonstrate the Entire process will produce the satisfactory results .These modules are follows
3.1 ADD PATIENT’S FILE
In this module the patient medical details are added using Weka tool. The uploaded patient detail is uploaded in arff format. The uploaded patient file is then used for further process. After the patient details detected it will get started to predict the attribute for the relevant information of patient with future disesases
3.2 ATTRIBUTE SELECTION
The patient’s diseases are viewed in this module. The list of diseases affected to the particular patient is viewed in detail. This attribution will be help in the stage of the analyzing the patient completely. The patient’s attributes are related to the some diseases relevant information which gives the details to compare the stage of the patient diseases.
3.3 COMPARISON
The Patient report is compared with other patient’s in order to predict the possibilities of occurrence other diseases. This makes the patient to be aware of other diseases. The prediction analyzed by the attributes and patient’s module with the help of the high dimensional data for producing the satisfactory results.
3.4 RESULT
The entire history of the patient is viewed in this module. The patient report is viewed in graph format. This is final process for analyzing the patient’s health stage and can be provided the awareness like what the patient should have to follow the instructions of the Experts and this illustration will be help to research the further enhancement.
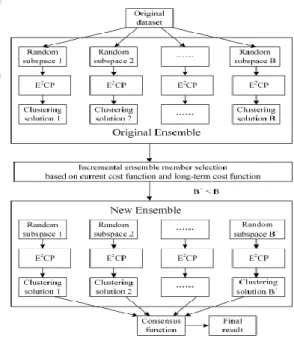
4.ARCHITECTURE
Fig. 4.1 Architecture Diagram for ISSCE
framework
10
the two cost function that is incremental ensemble member selection based on current cost function and long term cost function. The new ensemble gives the satisfactory result. The new Ensemble derived from the original ensemble. The original ensemble gets the input from the original data set which contains the important process that is Random subspaces, Constraint propagation approaches and clustering solution. The cluster ensemble approaches have gained more and more attention, due to useful applications in the areas of pattern recognition, data mining, bioinformatics, and so on. When compared with traditional single clustering algorithms, cluster ensemble approaches are able to integrate multiple clustering solutions obtained from different data sources into a unified solution, and provide a more robust, stable and accurate final result.5. DATA FLOW DIAGRAM
The data flow diagram shows that how the data are interconnected with the database via different module of the patient’s details.level-0 depicts that how the user and cluster process access the database of the hospitality which accesses this method by the process of bidirectional. In the next level of the data flow diagram depicts that how the module are performed by their user into the different process of the module .The user process the add file with the help of the file database. The user process the analyze the attribute module with the help of the Fields database and the user process the computation method with the help of the computer database similarly the user process the result module to produce the result whether positive or not by the result database of the database hospital.
Fig.5.1 Data flow diagram
6. ALGORITHM
Semi-supervised learning is a class of
11
7. RESULT
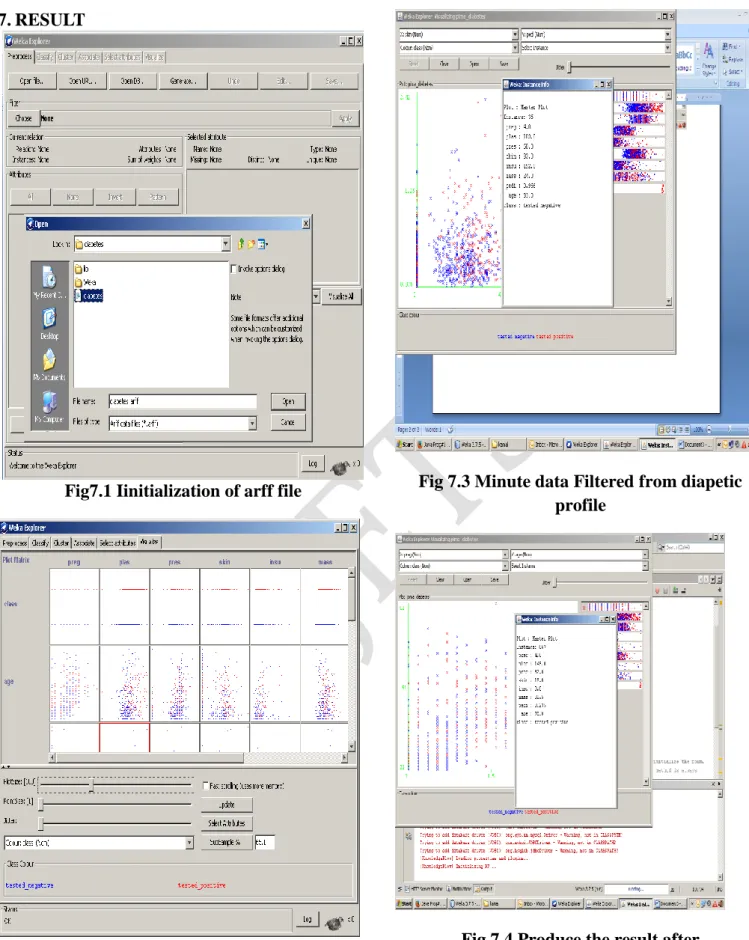
Fig7.1 Iinitialization of arff file
Fig 7.2
Attribute selection report after include
the diapetic profile
Fig 7.3 Minute data Filtered from diapetic
profile
Fig 7.4 Produce the result after
comparision
12
8.CONCLUSION
In the proposed thesis, our research focus is on semi-supervised clustering, which uses a small amount of supervised data in the form of class labels or pair wise constraints on some examples to aid unsupervised clustering. Semi-supervised clustering can be either search-based, i.e., changes are made to the clustering objective to satisfy user – specified labels/constraints, or similarity-based, i.e., the clustering similarity metric is trained to satisfy the given labels/constraints. Our main goal in the proposed thesis is to study search-based semi-supervised clustering algorithms and apply them to different domains. In our initial work, we have shown how supervision can be provided to clustering in the form of labeled data points or pair wise constraints. We have also developed an active learning frame work for selecting informative constraints in the pair wise constrained semi-supervised clustering model, and proposed a method for unifying search- based and similarity-based techniques in semi-supervised clustering. In this thesis, we want to study other aspects of semi-supervised clustering. Some of the issues we want to investigate include: (1) effect of noisy, probabilistic or incomplete supervision in clustering; (2) model selection techniques for automatic selection (3) ensemble semi-supervised clustering.
9.FUTURE ENHANCEMENTS
In our work so far, we have mainly focused on generative clustering models, e.g. KMeans and EM, and ran experiments on clustering low-dimensional UCI datasets or high-dimensional text datasets. In future, we want to study the effect of semi-supervision on other clustering algorithms, especially in the discriminative clustering and online clustering frame work. We also want to study the effectiveness of our semi-supervised clustering algorithms on other domains,e.g, websearch engines (clustering of search results), astronomy (clustering of Mars spectral images) and bioinformatics (clustering of gene microarray data).
10. REFERENCES
[1] A. P. Topchy, A. K. Jain, W. F. Punch, "Cluster ensembles: Models of consensus and weak partitions", IEEE Trans. Pattern Anal. Mach. Intell., vol. 27, no. 12, pp. 1866-1881, Dec. 2005.
[2] T. K. Ho, "The random subspace method for constructing decision ", IEEE Trans. Pattern Anal. Mach. Intell., vol. 20, no. 8, pp. 832-844, Aug. 1998.
[3] Z. Lu, Y. Peng, "Exhaustive and efficient constraint propagation: A graph-based learning approach and its applications", Int. J. Comput. Vis., vol. 103, no. 3, pp. 306-325, 2013.
[4] J. Shi, J. Malik, "Normalized cuts and image segmentation", IEEE Trans. Pattern Anal. Mach. Intell., vol. 22, no. 8, pp. 888-905, Aug. 2000.
[5] H. Wang, T. Li, T. Li, Y. Yang, "Constraint neighborhood projections for semi-supervised clustering", IEEE Trans. Cybern., vol. 44, no. 5, pp. 636-643, May 2014. [6] N.X. Vinh, J. Epps, J. Bailey, "Information theoretic measures for clustering comparison: Variants properties normalization and correction for chance", J. Mach. Learn. Res., vol. 11, pp. 2837-2854, 2010.
[7] M. C. de Souto, I. G. Costa, D. S. de Araujo, T. B. Ludermir, A. Schliep, "Clustering cancer gene expression data: A comparative study", BMC Bioinformatics, vol. 9, no. 497, 2008.
11. AUTHORS BIOGRAPHY
Ms.M.R.Ramya received her B.E degree in Jay shriram group of Institution, Avinashipalayam,Tirupur, India and currently pursuing M.E degree in jay shriram group of institutions, Avinashipalayam, Tirupur, India. Her research include data miming, pattern recognition, Machine learning.