Automatic Co-authorship Network Extraction and
Discovery of Central Authors
V. Umadevi
Department of Computer Science and Engineering BMS College of Engineering
Bangalore 560019, Karnataka, India [email protected]
ABSTRACT
Scholarly publications are made available online by individual re-searchers on their home pages. The list of publications reflects the research work carried by individuals collaborating with one or more other researchers. Automatic extraction of author’s name from the list of publications is required to construct a co-authorship network for identification of prominent authors. This will aid the scientific community to identify the works carried out in collabo-ration among the researchers. This paper will discuss the frame-work developed to automatically extract the names of authors from the list of publications to construct a Co-authorship network. Fur-ther the centrality measure analysis was carried out on this Co-authorship network to discover key authors.
General Terms:
Framework, Author’s name, Publication
Keywords:
Co-authorship Network, PERL, GEPHI, Automatic Extraction, Centrality Measure
1. INTRODUCTION
Analyzing co-authorship network to discover scientific collabo-ration among authors is a relatively novel research area.Two re-searchers are considered connected if they have co-authored a pa-per, and these types of connections between two scientists eventu-ally constitute co-authorship networks [1]. Individual researchers increasingly choose to share their research findings by providing lists of their published works on their respective institute home page. Researchers create their own publication lists on the Web for many reasons, such as describing their research work and contri-butions. Construction of co-authorship network by automatically extracting names of the author from the publication list is a chal-lenging task. The aim of extracting the names of the authors au-tomatically from a list of publications is to generate an error free list of authors, effortlessly and in a prompt manner. In this paper, using PERL (Practical Extraction and Reporting Language) pro-gramming language, a framework developed to automatically ex-tract names of author from the list of publications given in the
per-sonal home page of the individual faculties/researchers will be dis-cussed. Further, the framework uses GEPHI, an open source net-work analysis tool for calculation of centrality measure analysis. The objective of the proposed framework is to construct a co-authorship network by automatically extracting names of author from list of publications and carryout centrality measure analysis on the constructed co-authorship network to identify central au-thors. Identification of central authors will help in expert finding and contributors for conferences, journals, workshops etc. This will further be advantageous for institutions, students and funding agen-cies in locating prospective researchers for collaboration, project funding, guidance etc. The words researcher, author and scientist are used interchangeably in this paper.
2. RELATED WORK
International Journal of Computer Applications (0975 8887) Volume 74 - No. 4, July 2013
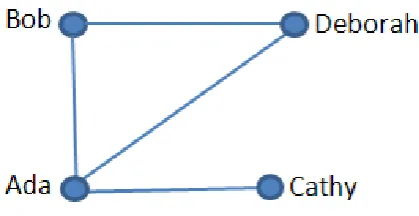
Fig. 1. Sample Co-authorship Network.
external collaboration work among faculties. This work does not discuss the method used to extract names of the authors from the publication list. A deterministic HTML Parser was developed to au-tomatically generate large-scale Brazilian co-authorship networks, based on Lattes curricula belongings to researchers associated to specific academic areas [7]. Team-Beam algorithm has been devel-oped by [8] to provide a flexible tool to extract a wide array of meta-data from scientific articles. But Team-Beam is a supervised machine learning algorithm, where large labeled training examples are required to learn a classification scheme for the individual text elements of an article.
Manual extraction of author names from publication list is time consuming and also it may result in erroneous data. Hence the ob-jective of this work is to develop a framework for automatic extrac-tion of author’s names from the publicaextrac-tion list for construcextrac-tion and analysis of co-authorship network.
3. CO-AUTHORSHIP NETWORK
Co-authorship is one of the most tangible and well documented forms of scientific collaboration [9]. Co-authorship network is rep-resented as a graph. In such a graph, node represents an author or researcher. An edge exist between two nodes if two authors have co-authored a research paper together. For example say paper 1 was written by the authors Ada, Bob and Deborah; and paper 2 was written by Ada and Cathy, then the sample co-authorship network for these authors are as shown in Fig. 1. Some important applica-tions, such as academic author ranking and expert recommendation can be extracted from co-authorship network [10].
4. PUBLICATION DATASET
Available online sources for publication databases are DBLP, Cite-Seer, Google Scholar, etc., journal homepages, conference web-sites, homepages of individual researchers as well as organiza-tional/institutional websites. In this work focus is on considering publication data of faculty members belonging to one single de-partment of an institute. Institute home pages of faculty members is the trustworthy source of publication data. The publication data used in this study has been obtained from the individual faculty home pages working in the Department of Computer Science and Engineering, IIT Madras. The data used for the study was collected during the month of April, 2013. Total number of faculties in the department were twenty four [11]. Format of publication list main-tained by faculty members are of various types. For the study con-sidered two different formats of publication focusing on updated and complete list maintained by the faculty. Seven faculty mem-bers publication list was finally selected for study which were of
two different formats. The sample publication of two different for-mats are as mentioned below.
Format 1:
V. K. Chaithanya Manam, V. Mahendran, and C. Siva Ram Murthy, "Message-Driven Based Energy-Efficient Routing in Heterogeneous Delay-Tolerant Networks," 1st ACM Workshop on High Performance Mobile Oppor--tunistic Systems (MSWIM HP-MOSys), Paphos, Cyprus Island, October 25, 2012.
Format 2:
Michalak, T. P., Aadithya, K. V., Szpzepaski, P. L., Ravindran, B., and Jennings, N. R. (2013) "Efficient Computation of the Shapley Value for Game-Theoretic Network Centrality". In the Journal of Artificial Intelligence Research (JAIR), Vol 46, pp. 607-650. March 2013. AAAI Press.
5. FRAMEWORK TO EXTRACT NAME OF THE AUTHOR, CONSTRUCT AND ANALYSE CO-AUTHORSHIP NETWORK
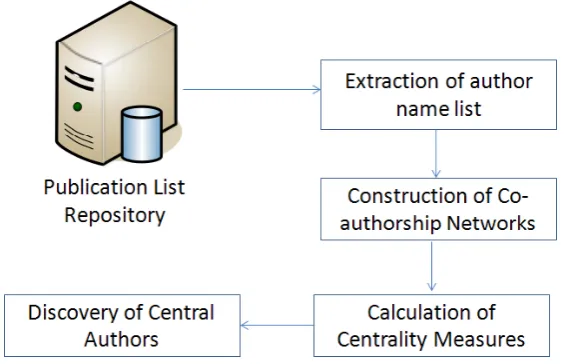
This section will discuss the framework developed for automatic extraction of author’s name from the publication list to generate and analyse co-authorship network. PERL programming language [12] was used for extraction of author’s names and from the extract co-authorship network was constructed. GEPHI, an open source network analysis tool was used for calculation of centrality mea-sures. The work flow of the developed framework is shown in Fig. 2. Details of each module in the framework are discussed in detail in the following subsections.
5.1 Publication List Repository
Publication repository used in the framework was as discussed in section 4. Two different styles of the publication was used for pars-ing names of the authors. The two different formats are referred to as Format 1 and Format 2. Format Sample for the style of these two different formats are given in section 4. Total number of publica-tions (which includes conference and journal publicapublica-tions) under Format 1 was 105 and for Format 2 was 719.
5.2 Extraction of author name list
By using PERL programming language, a Parser was written to ex-tract names of the authors from two different styles of publication list. Parser scans publication record one by one, from left to right, taking from the repository. The parser stops scanning at the stop-word to extract the complete list of authors names from the record. The stop words used for Format1 and Format2 are as shown in Fig. 3 and 4 respectively. The parser uses separator character as shown in Fig. 3 and 4 for extraction of individual author’s name. The to-tal number of author’s names extracted automatically by the parser was 736. Then, in the next module of the framework, one to one mapping on the extracted individual authors names will be carried out to a construct co-authorship network.
5.3 Construction of Co-authorship Networks
Fig. 2. Framework for automatic extraction of author’s names to generate and analyse co-authorship network.
Fig. 3. Separator and Stopword for Publication Style of Format 1.
edge is created between a pair of nodes if two researchers have co-authored an research paper. For example, the name extracted was Author1, Author2 and Author3, then following edges will be cre-ated in the co-authorship network.
Author1 <-> Author2 Author1 <-> Author3 Author2 <-> Author3
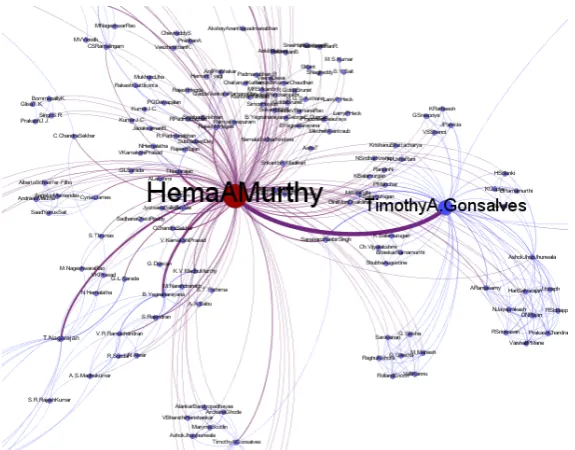
Visualization of Co-authorship network constructed by this module is shown in Fig. 5 and part of this co-authorship network expanded is shown in Fig. 6. The average path length of the constructed co-authorship network was less than 6, which means that this network is like any other social network graph and is like asmall world. 5.4 Calculation of Centrality Measures
Using GEPHI, an open source network analysis tool centrality mea-sures were calculated for co-authorship constructed by the previ-ous module. Centrality is regarded as one of the most important and commonly used conceptual tools for exploring actor roles in social networks [13]. The four centrality measures calculated for the constructed co-authorship network was Degree, Betweenness, Eigenvector and Closeness. Short description of these four central-ity measures [14] are as given below.
Degree Centrality: An important node is involved in large num-ber of interactions.
Closeness Centrality: An important node is typically close to, and can communicate quickly with the other nodes in the net-work.
Betweenness Centrality: An important node will lie on a high proportion of paths between other nodes in the network.
Eigenvector Centrality: An important node is connected to im-portant neighbors.
International Journal of Computer Applications (0975 8887) Volume 74 - No. 4, July 2013
Fig. 4. Separator and Stopword for Publication Style of Format 2.
Fig. 5. Generated Co-authorship Network.
5.5 Discovery of Central Authors
Author Hema A. Murthy is having highest betweenness as well as highest eigenvector centrality; it means that this author is occupy-ing the central position in terms of information flow and also highly connected in the network. Second highest betweenness value was for the author Ravindran. B, but his eigenvector centrality was less when compared to that of author V. Kamakoti, Timothy A. Gon-salves, C. SivaRamMurthy and Krishna M. Sivalingam. This in-dicates that Ravindran. B is less connected in the network when compared to authors V. Kamakoti, Timothy A. Gonsalves, and C. SivaRamMurthy and Krishna M. Sivalingam. Degree, Betweenness and Eigenvector centrality measure for the top eight authors are given in the table 1. Among the seven faculty members publications considered for analysis, only five faculty members were in the top eight ranked authors. The other two faculty members were found
to be junior faculty within the department when compared to the remaining five faculty members. Closeness centrality value for the authors Krishna M. Sivalingam and John Augustine was of value one. Among the publication list of the seven faculty members con-sidered for analysis, Timothy A. Gonsalves publication list was not obtained from his home page. But he has co-authored with Hema A. Murthy, hence he is found to be among the top eight ranked authors as seen from table 1 of centrality measures.
6. CONCLUSION
[image:4.595.175.439.224.483.2]Pro-Fig. 6. Expanded: Part of Co-authorship Network
Table 1. Top eight authors based on centrality measures
Rank Author Name Degree Author Name Betweenness Author Name Eigenvector
Centrality Centrality Centrality
1 Hema A. Murthy 187 Hema A. Murthy 110903 Hema A. Murthy 1.00
2 V. Kamakoti 152 Ravindran. B 91591 V. Kamakoti 0.54
3 C. SivaRamMurthy 131 Chakraborti. S 82781 Timothy A. Gonsalves 0.44 4 Krishna M. Sivalingam 128 Karthik Jayanthi 79182 C. SivaRamMurthy 0.39
5 Ravindran. B 84 V. Kamakoti 72169 Krishna M. Sivalingam 0.36
6 Timothy A. Gonsalves 55 C. SivaRamMurthy 63932 Ravindran. B 0.23
7 John Augustine 38 Timothy A. Gonsalves 57688 Ashok Jhun Jhunwala 0.19
8 B. S. Manoj 25 Krishna M. Sivalingam 7867 A. Ramasamy 0.17
posed framework was applied on the publication list of faculties belonging to the Department of Computer Science and Engineer-ing, Indian Institute of Technology Madras. Here, the framework was adopted only for two different styles of publication list. The style of publication list maintained by individual faculties differ. The focus of future work is to train machine learning algorithm to adopt to all different styles of publications which makes automatic extraction of the list of authors possible, irrespective of the publi-cation format.
7. REFERENCES
[1] S. Uddin, L. Hossain, A. Abbasi, and K. Rasmussen. Trend and efficiency analysis of co-authorship network. Scientomet-rics, 20:687–699, February 2012.
[2] M. E. J. Newman. Co-authorship networks and patterns of scientific collaboration. InProc. of the National Academy of Sciences, pages 5200–5205, 2004.
[3] Wolfgang Reinhardt, Christian Meier, Hendrik Drachsler, and Peter Sloep. Analyzing 5 years of ec-tel proceedings. In Proceedings of the 6th European conference on Technology enhanced learning: towards ubiquitous learning, pages 531– 536, Springer-Verlag Berlin, 2011.
[4] M. E. J. Newman. Scientific collaboration networks - 2 short-est paths, weighted networks, and centrality.Physical Review E, 64:016132–1–7, 2001.
[5] M. E. J. Newman. The structure of scientific collaboration networks. In Proc. of the National Academy of Sciences, pages 404–409, 2001.
[6] Tasleem Arif, Rashid Ali, and M. Asger. Scientific co-authorship social networks: A case study of computer science scenario in india. International Journal of Computer Appli-cations, 52:38–45, August 2012.
[7] Jess P. Mena-Chalco and Roberto Marcondes Cesar Junior. Towards automatic discovery of co-authorship networks in the brazilian academic areas. InIEEE Seventh International Conference on e-Science Workshops, pages 53–60, Stock-holm, 2011.
[8] Roman Kern, Kris Jack, Maya Hristakeva, and Michael Gran-itzer. Teambeam meta-data extraction from scientific litera-ture. D-Lib Magazine, 18, 2012.
[image:5.595.86.526.330.436.2]International Journal of Computer Applications (0975 8887) Volume 74 - No. 4, July 2013 [10] Y. Han, B. Zhou, J. Pei, and Y. Jia. Understanding
impor-tance of collaborations in co-authorship networks. InSIAM International Conference on Data Mining, pages 1112–1123, 2009.
[11] Department of Computer Science & Engineering. Iit madras.
http://www.cse.iitm.ac.in/faculty/, 2013. [Online; accessed April-2013].
[12] PERL. The perl programming language. http://www. perl.org/, 2013. [Online; accessed March-2013].
[13] Chaoqun Ni, Cassidy R. Sugimoto, and Jiepu Jiang. De-gree, closeness, and betweenness: Application of group cen-trality measurements to explore macro-disciplinary evolution diachronically. InProceedings of ISSI, pages 1–13, Durban, 2011.
[14] Centrality Measures. An introduc-tion. https://sites.google.com/site/ networkanalysisacourse/schedule/
an-introduction-to-centrality-measures, 2013. [Online; accessed May-2013].
[15] M. E. J. Newman. A measure of betweenness centrality based on random walks. Cornell University Library arXiv:cond-mat/0309045, pages 1–15, 2003.