A Survey Paper on
Data retrieval from multiple
heterogeneous databases using Content aggregation
1
Mangesh S. Khode &
2Mayur Dhait
Computer Science and Engineering, RTMNU University, Agnihotri College of Engineering,
Nagthana Road, Sindi(Meghe), Wardha, Maharashtra, India
[email protected]
Abstract:
Remembering with an assortment of substance decisions, purchasers are displaying differing inclinations
for substance; their inclinations frequently rely on upon the connection in which they devour content and
also different exogenous occasions. To fulfill the customers' interest for such assorted substance, sight and
sound substance aggregators (CAs) have developed which accumulate content from various interactive
media sources. A key test for such frameworks is to precisely anticipate what kind of substance each of its
shoppers favors in a sure connection, and adjust these expectations to the developing customers
inclinations, settings, and substance attributes This paper locations create content based record information
sets, for example, word, content documents, picture document information sets, and video record
information sets, It likewise separate information from different databases, assess client inclination based
question, diminish time unpredictability by using so as to group information, and expand bringing rate
inquiry arrangement.
Keywords: Content aggregators; data sets; query classification
1. Introduction
An amount more prominent than required of interactive media applications (online TV customized video recovery customized news total and so forth.) are developing which require coordinating mixed media substance created by disseminated sources with purchasers showing distinctive hobbies. Sight and sound gives customized video recovery, news
collections. They are rising which require
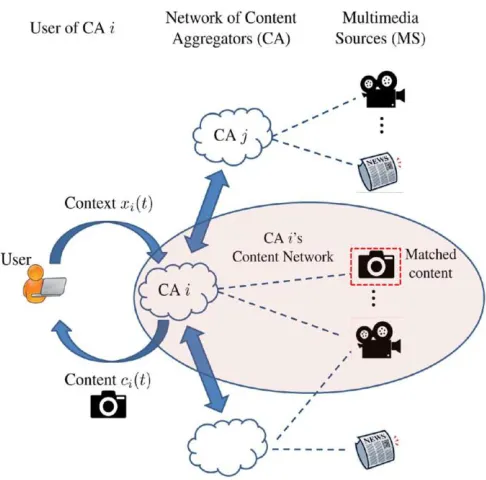
coordinating mixed media substance produced by dispersed sources with buyers showing distinctive hobbies. The coordinating is frequently performed by CAs that is in charge of mining the substance of various sight and sound sources looking for discovering content which is fascinating for the clients. Every client is portrayed by its setting, which is a genuine esteemed vector that gives data about the clients' substance inclinations. A case of the framework with clients, CAs and mixed media sources is given in taking after Fig.1.
Content Aggregator (CA)i . (b) CA chooses a matching action [1]
We expect a model where clients arrive successively to a CA, and in view of the sort (setting) of the client, the CA solicitations content from both of the interactive media sources that it is associated with or from another CA that it is joined with. The CA's part is to coordinate its client with the most suitable substance, which can be refined by asking for substance from the most suitable sight and sound source.1 Since both the substance created by the mixed media sources and the client's qualities change after some time, it is obscure to the CA which mixed media source to coordinate with the client. This issue can be figured as a web learning issue, where the CA takes in the best exploring so as to coordinate matchings of clients with diverse substance suppliers. After a specific substance coordinating is made, the client "expends" the substance, and gives input/rating, for example, as or abhorrence. [1]
A general meaning of connection was proposed by Chen and Kotz: "Setting is the arrangement of natural states and settings that either decides an application's conduct or in which an application occasion happens and is intriguing to the client." Considering the IPTV administration, connection can be considered as any data that can be utilized to describe the circumstance of a substance identified with the IPTV administration. An element could be the client, gadget, and system and administration itself. Consequently we characterize four sorts of settings for IPTV chain including client, gadget/terminal, system and administration spaces. Keeping in mind the end goal to empower connection mindful IPTV for improved administrations personalization, mixed bag of data communicating current circumstance of client, gadget, system, substance and administration should be gathered and prepared. Such data is called logical data and should be proficiently accumulated and handled progressively amid administration access. [3]
The term social mixed media to allude to sight and sound assets accessible through online networking channels or all the more formally: online wellsprings of
interactive media con-tent posted in settings that cultivate huge individual investment and that advance group span, discourse and re-utilization of substance. Social media displays a noteworthy open door for Multimedia applications and administrations. Such data may incorporate numerous aspects: printed descriptors, data about the content's area catch the camera properties metadata, and even client data and informal organization information. These extra metadata can be utilized to progress and increase sight and sound and substance investigation methods. Moreover, social sight and sound catches and influences group movement around mixed media information, utilizing express client data like labels and remarks and in addition verifiable information from clients like mass survey designs in thing and sub-thing levels. Without a doubt, social mixed media likewise offers the chance to outline intuitive frameworks that inspire new unequivocal and understood metadata from client collaboration. Such association and client info is frequently determined by social inspirations and can enhance the information accessible for sight and sound applications. Accordingly, social sight and sound offers a few open doors that go past or more other \Web media" sources where huge numbers of these open doors are not accessible. [7].
2. Content Aggregation Concerns
For implementing content aggregation of multiple heterogeneous databases, we use two basic algorithms and one technique:
2.1 K-means clustering algorithm for data classification for query based results
It is a system for vector quantization, initially from sign handling, that is well known for bunch examination in information mining. K-means grouping intends to parcel perceptions into k bunches in which every perception has a place with the bunch with the closest mean, serving as a group's model. This outcomes in an information's apportioning space into cells. The issue is
notwithstanding, there are effective heuristic calculations that are regularly utilized and focalize rapidly to a nearby ideal. These are normally like the desire boost calculation for blends of Gaussian appropriations through an iterative refinement methodology utilized by both calculations. Also, they both use bunch focuses to show the information; nonetheless, k-means grouping tends to discover bunches of practically identical spatial degree, while the desire augmentation system permits bunches to have distinctive shapes. The calculation has nothing to do with and ought not be mistaken for k-closest neighbor, another prevalent machine learning strategy. It helps in transferring of information over the server.
2.2KNN classification (K-Nearest Neighbor) for query on to different databases
It is a non-parametric technique utilized for arrangement and relapse. In both cases, the info comprises of the k nearest preparing cases in the element space. The yield relies on upon whether k-NN is utilized for order or relapse:
a. In k-NN characterization, the yield is a class enrollment. An article is grouped by a greater part vote of its neighbors, with the item being doled out to the class most regular among its k closest neighbors (k is a positive whole number, commonly little). In the event that k = 1, then the article is just relegated to the class of that solitary closest neighbor.
b. In k-NN relapse, the yield is the property estimation for the article. This worth is the values' normal of its k closest neighbors.
K-NN is a kind of occasion based learning, or languid realizing, where the capacity is just approximated locally and all calculation is conceded until grouping. The k-NN calculation is among the easiest of all machine learning calculations. Both for order and relapse, it can be helpful to allot weight to the neighbors' commitments, so that the closer neighbors contribute more to the normal than the more removed
ones. For instance, a typical weighting plan comprises in giving every neighbor a weight of 1/d, where d is the separation to the neighbor. It helps in inquiry fire while managing information.
2.3Data extraction or fetching
Information extraction or bringing of information from numerous sources needs to utilize inquiry based web search tool. It is finished by substance total.
3 Literature Review
CemTekin and Mihaela van der Schaar [1] proposed a novel, circulated, online media content collection system, which accumulates substance created by numerous heterogeneous makers to satisfy its buyers' interest for substance. To fulfill the buyers' interest for such differing content, interactive media content aggregators (CAs) have risen which assemble content from various sight and sound sources. A key test for such frameworks is to precisely foresee what sort of substance each of its buyers inclines toward in a sure connection, and adjust these expectations to the advancing customer's inclinations, settings, and substance qualities. We propose subsequent to both the sight and sound substance qualities and the shoppers' inclinations and settings are obscure, the ideal substance collection methodology is obscure from the earlier. Our proposed content accumulation calculation has the capacity realize online what substance to assemble and how to match substance and clients by abusing likenesses between buyer sorts.
Conventional TV television model is supplemented and regularly even supplanted by computerized content dissemination administrations over the Internet. As an aftereffect of this pattern, a scope of administrations and substance accessible for clients is quickly extending. As a symptom, planning proficient client interfaces for finding the substance, and in addition for controlling related intelligent administrations, turns out to be more bulky. Pervasive registering and setting mindfulness standards appear to be encouraging for making client collaboration with the framework more consistent and liquid.
S. Roy, T. Mei, W. Zeng, and S. Li [6] proposed learning for forecast of video prevalence socially. Cross space ongoing exchange learning structure is utilized which uses information from social streams (e.g., Twitter) and enhance fame forecast in the video area. OSLDA model is utilized to distinguish points from social streams. Social Transfer calculation is utilized for arranging recordings with points which is then used to compute the social conspicuousness lastly prompting the enhanced notoriety forecast in the video space. The structure can scale with approaching tweets progressively. Learning picked up from social streams can be utilized to address numerous mixed media issues which can't be fathomed by utilizing conventional sight and sound strategies alone.
PM. Naaman [7] proposed different Web-based sharing and group administrations, for example, Flickr and YouTube have made an incomprehensible and quickly developing measure of sight and sound substance accessible on the web. This article displays a methodology for "social mixed media" applications. The methodology depends on the experience of building various effective applications that depend on mining interactive media content examination in social mixed media connection. Lately, different Web-based sharing and group administrations, for example, Flickr and YouTube have made an endless and quickly developing measure of media substance accessible on the web.
M. van der Schaar, J. Xu, and W. Zame [8] proposed and broke down conventions that depend exclusively on the trading of fiat cash or tokens. The examination has much in a similar manner as take a shot at pursuit models of cash yet the earth's necessities additionally prompt numerous distinctions from past investigations and a few astonishments; specifically, presence of balance turns into a prickly issue and the ideal amount of cash is diverse. In numerous online frameworks, people give administrations to one another; the administration's beneficiary gets an advantage however the administration's supplier acquires an expense.
M. Saxena, U. Sharan, and S. Fahmy [10] proposed diverse DNS resolvers to acquire the IP location of the video server. We concentrate how the DNS determination affects the video's execution download, along these lines the video playback quality. As the apparatus is expected to keep running on numerous ISPs, we have found some fascinating results in YouTube conveyance strategies. These outcomes can be connected to any substance conveyance systems (CDN) building design and ought to help clients to better comprehend what the key execution variables of video spilling are. Online video administrations represent a noteworthy piece of broadband movement with gushing recordings being a standout amongst the most famous video administrations. We concentrate on the client saw nature of YouTube recordings as it can serve as a general list for consumer loyalty.
G. Linden, B. Smith, and J. York [13] proposed suggestion calculations to customize the online store for every client. The store profoundly changes in view of client intrigues, indicating programming titles to a product specialist and infant toys to another mother. The navigate and change rates two essential measures of Web-based and email publicizing adequacy immensely surpass those of untargeted substance, for example, pennant notices and top-vender records. There are three basic ways to deal with taking care of the suggestion issue: customary collective separating, bunch models, and hunt based techniques. Here, we contrast these techniques and our calculation, which we call thing to-thing synergistic separating. Not at all like conventional community oriented sifting, our calculation's online calculation scales freely of the quantity of clients and number of things in the item index. Our calculation produces suggestions continuously, scales to huge information sets, and creates fantastic proposals.
D. Bouneffouf, A. Bouzeghoub, and A. L. Gançarski [14] proposed area and time setting for samples are
vital in versatile processing suggestions, because of the way that a client may require a suggestion at a specific area in a specific time. Such situations have presented Context-Aware Recommender Systems (CARS) for further open examination issues and difficulties. This paper at first shows Background of CARS, particularly from the point of view of connection sorts, setting displaying architectures and calculations. Moreover, the paper, shows an outline of the best in class research in the zone of CARS, lastly talks about significant open issues of CARS. Recommender Systems have been/are being investigated and conveyed broadly in different teaches, for example, tourism and instruction. Most conventional recommender frameworks, for example, Collaborative Filtering (CF) and Content-Based Using so as to filter (CBF) produce suggestions two primary qualities, to be specific; clients and things i.e. proposals are produced in view of a client having a hobby or inclination of a specific thing asset.
4 Proposed System
The proposed work is planned to carry out in the following manner.
Fig.2. System Architecture
In this proposed system, then client from client space will be able to fetch data from multiple databases which contain different media. The user will be provided with search engine to search text, image or video based files. The proposed system will provide functionality of distributed system in virtual centralized view approaches shown in above figure.
We will be using three different databases or folder for separate search. It removes ambiguity of sources having different web servers by providing common web server. For that, data preprocessing plays vital role.
5 Conclusion
Content accumulation of a novel, disseminated, online interactive media system assembles substance created by numerous heterogeneous makers. For Example, Personalized music, video recovery, news
totals evacuates issue of various substance. The coordinating is frequently performed by CAs that are in charge of mining the substance of various interactive media sources looking for discovering content which is fascinating for the clients. In this paper, we said to produce content based record information sets, for example, word, content documents, to create picture document information sets, to create video record information sets. Likewise we remove information from different databases. We will expand using so as to get velocity question characterization. Our philosophy is expected to be executed in a multi nature.
References
for Multimedia Content Aggregation”. IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 17, NO. 4, APRIL 2015
[2] S. Ren and M. van der Schaar, “Pricing and investment for online TV content platforms,” IEEE Trans. Multimedia, vol. 14, no. 6, pp. 1566–1578, Dec. 2012.
[3] S. Song, H. Moustafa, and H. Afifi, “Advanced IPTV services personalizationthrough context-aware content recommendation,” IEEE Trans.Multimedia, vol. 14, no. 6, pp. 1528–1537, Dec. 2012.
[4] P. Kohli, M. Salek, and G. Stoddard, “A fast bandit algorithm for recommendationsto users with heterogeneous tastes,” in Proc. 27th Conf. AI, Jul. 2013, pp. 1135–1141.
[5] S. D. Roy, T. Mei, W. Zeng, and S. Li, “Empowering cross-domaininternet media with real-time topic learning from social streams,” inProc. IEEE Int. Conf. Multimedia Expo, Jul. 2012, pp. 49–54.
[6] S. Roy, T. Mei, W. Zeng, and S. Li, “Towards cross-domain learningfor social video popularity prediction,” IEEE Trans. Multimedia, vol.15, no. 6, pp. 1255–1267, Oct. 2013.
[7] M. Naaman, “Social multimedia: Highlighting opportunities for search and mining of multimedia data in social media applications,” Multimedia Tools Appl., vol. 56, no. 1, pp. 9–34, 2012.
[8] M. van der Schaar, J. Xu, and W. Zame, “Efficient online exchange viafiat money,” Econ. Theory, vol. 54, no. 2, pp. 211–248, 2013
[9] L. Li, W. Chu, J. Langford, and R. E. Schapire, “A contextual-banditapproach to personalized news article recommendation,” in Proc. 19th
Int. Conf. World Wide Web, 2010, pp. 661–670.
[10] M. Saxena, U. Sharan, and S. Fahmy, “Analyzing video services inweb 2.0: A global perspective,” in Proc. 18th Int. Workshop Netw. OperatingSyst. Support Digital Audio Video, 2008, pp. 39–44.
[11] R. Mohan, J. R. Smith, and C.-S. Li, “Adapting multimedia internetcontent for universal access,” IEEE Trans. Multimedia, vol. 1, no. 1,pp. 104–114, Mar. 1999.
[12] A. Slivkins, “Contextual bandits with similarity information,” in Proc.24th Annu. Conf. Learn. Theory, Jun. 2011, vol. 19, pp. 679–702.
[13] G. Linden, B. Smith, and J. York, “Amazon.com recommendations:Item-to-item collaborative filtering,” Internet Comput., vol. 7, no. 1,pp. 76–80, 2003.
[14] D. Bouneffouf, A. Bouzeghoub, and A. L. Gançarski, “Hybrid-greedy for mobile context-aware recommender system,” inAdvances in Knowledge Discovery and Data Mining. New York,NY, USA: Springer, 2012, pp. 468–479.
[15] E. Hazan and N. Megiddo, “Online learning with prior knowledge,” inLearning Theory. New York, NY, USA: Springer, 2007, pp. 499–513.
[16] A Text Book of “Aggregation Network Design for offering multimedia services to fast moving users”