Duplicate Detection in Hierarchical Data Using Improved Network Pruning Algorithm-(Result Paper)
Full text
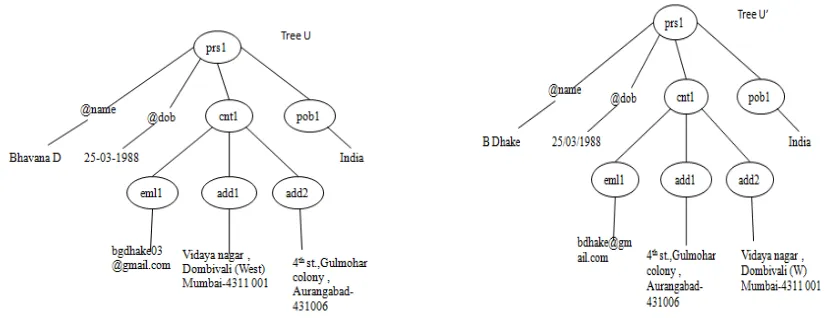
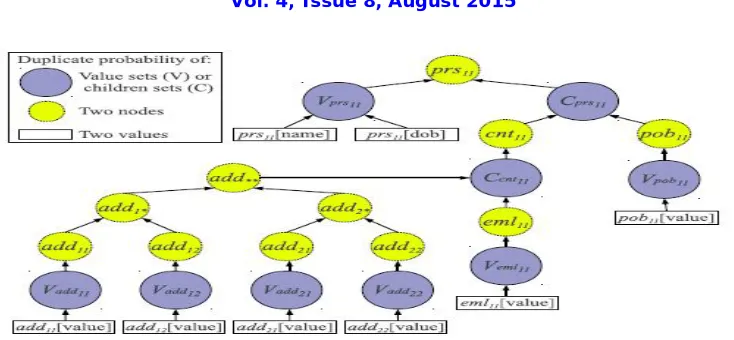
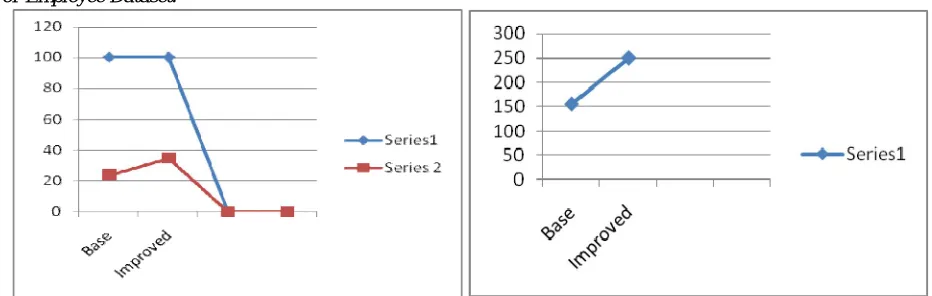
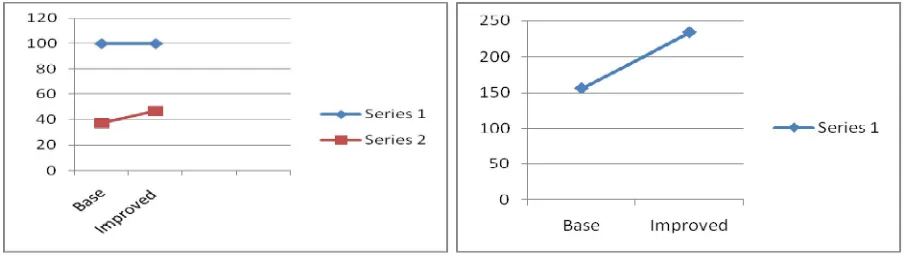
Figure

Related documents
considered this study especially useful for the desired purpose because Martin and col- leagues used latent indices scaled under the assumption of cross-national measurement
The laser heat treatment applied to high martensite content steels locally and signi fi cantly reduces the yield stress and multiplies the uniform plastic elongation by a factor 3..
Note: When using the batch send facility for delivering Unicode messages, it is not possible to substitute variables into the message content.. This is only possible with
There is no study in the field of sports sciences especially sport physiology research so far that has examined the factors that transfer results to the community and has
Only veterans who left military service under honorable or general conditions are eligible to receive health care from the VA, leaving a wide swath of former military servicemen and
Conclusion: As the depression and anxiety levels of mothers in the postpartum period increased, the psychological, physical, social and national sub-scales of the Quality
In accor- dance with previous reports [27,15], the present study showed that microglial cell activation and increased TNF-a cytokine levels were involved in ALS pathologies
The feather fragment in DIP-V-17232 (Fig. Its broad ra- chis is deeply concave in cross-section, and it bears a prominent rachidial ridge. The dark, mottled appearance of the
