105 Available online at www.ijiere.com
International Journal of Innovative and Emerging
Research in Engineering
e-ISSN: 2394 – 3343 p-ISSN: 2394 – 5494
HADOOP ARCHITECTURE: A distributed file system
Ruchira A. Kulkarni, Manisha K. Damade, Shahista Bano
TE, Computer Science & Engineering, SSGBCOET, Bhusawal, India
ABSTRACT:
Hadoop is an open-source software framework which stores and process big data in distributed manner for cloud computing.Hadoop is originated from Apache Nutch, which is an open source search engine, itself is a part of the Lucent project. Hadoop was invented by Doug Cutting and Mike Cafarella in 2005 in java. It was mainly
developed to support distribution for the Nutch search engine project. Yahoo has developed and contributed
80% of the core of Hadoop. All modules in Hadoop are designed with basic assumption that hardware failures of machines are common hence should be automatically handled in software by the framework.
Keywords: Hadoop, HDFS, Map Reduce, Nodes, Clusters
I. INTRODUCTION
Apache Hadoop core has a storage part (Hadoop Distributed File System (HDFS)) and a processing part (MapReduce). Hadoop divide files into large blocks (64MB or 128MB) and send that blocks to the nodes in the cluster [1]. To process the data, Hadoop Map/Reduce sends code (specifically Jar files) to nodes which contains required data, which the nodes process them in parallel.
The base Apache Hadoop framework is made up of the following modules:
Hadoop Common – it contains libraries and utilities used by other Hadoop modules;
Hadoop Distributed File System (HDFS) –it is a distributed file-system that stores data on commodity machines, and provide very high aggregate bandwidth across the cluster;
Hadoop YARN – it is a resource-management platform which is responsible for managing compute resources in clusters and using them for scheduling of users' applications; and
Hadoop MapReduce –it is a programming model for large scale data processing. Hadoop can be run in 3 different modes which are:
1. Standalone mode 2.Pseudo-distributedmode 3. Fully distributed mode
A) Need for Large Data Processing
We Live In The 21”St Century. It Is Difficult To Calculate The Total Data Stored Electronically, But An Idc Estimate The Size Of The Digital Universe At 0.18 Zettabytes In 2006, And Increasing At 10 Times By 2011 To 1.8 Zb [6].
Large Data Processing Needed In The Areas Which Include:-
• The New York Stock Exchange Creates About One Terabyte Of New Trade Data Per Day. • Facebook Hosts Generate Approximately 10 Billion Photos, Taking Up One Petabyte Of Storage. • Ancestry.Com, Which Is Genealogy Site, Stores About 2.5 Petabytes Of Data.
• The Internet Archive Stores About 2 Petabytes Of Data, And Is Increasing At A Rate Of 20 Terabytes Per Month. • The Big Hadron Collider near Geneva, Switzerland, Creates about 15 Petabytes of Data per Year
106 II. HADOOP ARCHITECTURE
There are various components of Hadoop: MapReduce job process, handling of the data, and architecture of a file system. Hadoop is having master-slave architecture for both distributed storage and distributed computation. [3] In distributed storage condition, NameNode is master and DataNodes are slaves. In the distributed computation Jobtracker is master and Tasktrackers are the slaves.
A) MapReduce Job Processing
An Hadoop execution of a client request is called a job. Users may submit job requests to the Hadoop framework, and the framework processes the job. Before the framework can process a job, the user must send the following information: Location of input and output files in a distributed file system.
Input and output formats.
Classes containing map and reduce functions.
Hadoop has four entities used in the processing of a job:
1. The user, who submits the job and specifies the configuration.
2. The JobTracker, a program which co-ordinates and handle the jobs. It receives job submissions from users, provides job managing and control, and manages distribution of tasks in a job to the TaskTracker nodes. Generally there is one JobTracker per cluster.
3. The TaskTrackers manage the tasks in the process, such as to reduce the task etc. There may be one or more TaskTracker processes per node in a cluster.
4. The distributed file system, like HDFS.
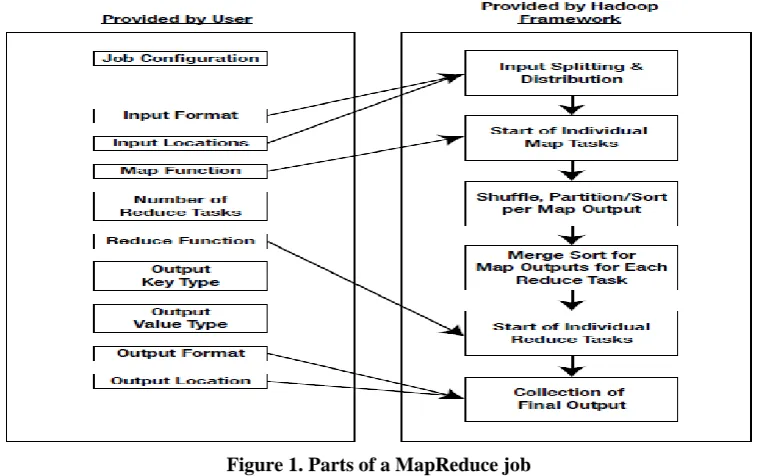
Figure 1. Parts of a MapReduce job
The user indicates the job configuration by setting different parameters to the job. The user also indicates the number of reduced tasks and reduced function. The users also need to specify the format and the locations of the input. The framework of hadoop uses this information to divide of the input into different pieces. Each input piece is inserted into a user-defined map function. The map tasks of Hadoop process the input data and remove the intermediate data. The output of the map phase is collected and a default or custom partition may be applied on the intermediate data. Accordingly, the reduce function of Hadoop processes the data in each partition and combines the intermediate values or performs a user-specified function. The user is expected to give the types of the output key and the output value of the map and reduce functions [1]. The output of reduce function is collected to output files on the disk by the Hadoop framework.
Hadoop Map-Reduce is a software framework which is used to easily writing the applications which access large amount of data in parallel manner. Map-Reduce divides the big data into small blocks and then it processed by the map tasks in parallel manner.[5] This Map-Reduce framework sorts the output of the map, and then these maps are input to the reduce task. Usually input and output of the job are stored in the file system. This framework mainly concern about scheduling tasks, monitoring and re-execute failed tasks.
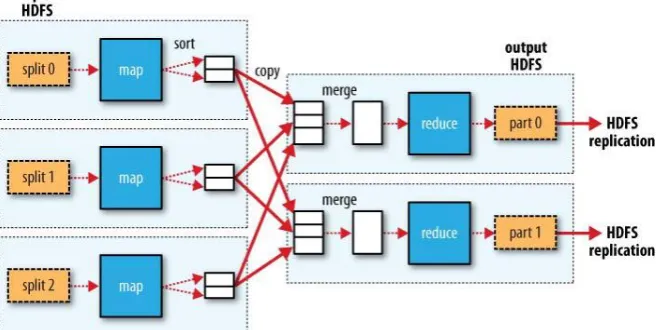
107 Figure 2. Map reduce data flow with a single reduce task
When there are multiple reducers, the map tasks creating one partition for each reduce task. There can be various keys in each partition. The records for every key are in a single partition. This partitioning can be controlled by a user-defined partitioning function. The default partitioner is which buckets keys using a hash function work very well. The following diagram makes it clear why the data flow between map and reduce tasks is colloquially called as “shuffle,” as each reduce task is fed by many map tasks.[5] The shuffle is more difficult than this diagram. Tuning it can have a big impact on job execution time. It is also possible to have zero reduce tasks. This is useful when you do not need the shuffle since the processing can be carried out entirely in parallel.
Figure 3. MapReduce data flow with multiple reduce tasks
B) Hadoop Distributed File System (HDFS)
Hadoop can work with any mountable distributed file system, but most common file system used by Hadoop is the Hadoop Distributed File System (HDFS). It is a distributed file system that is designed for commonly available hardware. It is suited for large data sets due to its high access to application data. [2].
Features of HDFS:
5. Hadoop is developed to run on clusters of machines. 6. HDFS may handle large data sets.
7. Since HDFS deals with large amount data, it supports thousands of machines. 8. HDFS supports a write-once-read-many access model.
9. HDFS is made using the Java language which is portable across various platforms.
The main problem while dealing with large amount of data is moving data while performing computations which requires much more bandwidth [2]. This can be overcome by shifting the computation nearer to the data location, rather than moving the data nearer to the application.
III. APPLICATIONS A) AMAZON S3
Amazon S3 is a simple data storage service. You are billed every month for storage and data transfer. Transfer in between S3 and AmazonEC2 is free of cost. This makes use of S3 useful for Hadoop users who run clusters on EC2. Hadoop gives two file systems that use S3.
S3 Native File System (URI scheme: s3n):
108 The disadvantage is that 5GB limit on file size is imposed by S3. For this reason it is not useful as a replacement for HDFS.
S3 Block File System (URI scheme: s3):
A block-based file system which is backed by S3. Files are maintained as blocks, just like they are in HDFS. This permits useful implementation of renames. This file system requires that you dedicate a bucket for the file system - you should not use an previous bucket containing files. The files stored by this file system may be greater than 5GB, but they are not interoperable with other S3 tools.
There are two methods that S3 can be used with Hadoop's Map/Reduce, one as a replacement for HDFS using the S3 block file system or as a convenient way for data input to and output from MapReduce, using S3 file system. In the second case HDFS is used for the Map/Reduce phase.
B) FACEBOOK
Facebook’s engineering team has given some details on the tools it’s using to analyze the large data sets it collects. One main tools it uses is Hadoop that makes it easy to analyze large amounts of data.
Some of the early projects have matured into public released features like the Facebook Lexicon or are used in the background to improve user experience on Facebook by improving the relevance of search results. Facebook has number of Hadoop clusters developed now - with the biggest having nearabout 2500 cpu cores and 1 PetaByte disk space. They are introducing over 250 GB of compressed data into the Hadoop file system every day. The list of projects that are using this infrastructure has increased rapidly from those generating statistics about site usage, to others used to fight spam and determine quality of application. Over time, classic data warehouse features like partitioning, sampling and indexing are added to this environment. This data warehousing layer over the Hadoop is called as Hive.
C) YAHOO
Yahoo has launched the world's largest Apache Hadoop production application recently. The Yahoo Search Webmap is a Apache Hadoop application that runs on a more than about 10,000 core Linux cluster and introduces data that is now used in every Yahoo query.
Some Webmap size data contains:
Number of links between each pages in the index: nearly 1 trillion links Size of output: over 300 TB, in compressed form.
No. of cores used to run single Map-Reduce job: over 10,000 Raw disk used in the cluster production: over 5 Petabytes
IV. HADOOP ADVANTAGES AND DISADVANTAGES A) Advantages
1) Scalable: Hadoop is highly scalable storage platform because it can store and distribute very large data set across hundreds of inexpensive servers that operate in parallel.
2) Cost Effective: Hadoop also offers a cost effective storage solution for business exploding data sets.
3) Flexible: Hadoop enable business to easily access new data sources and tap into different type of data to generate value from that data.
4) Fast: Hadoop’s unique storage method is based on a distributed file system that basically ‘maps’ the data wherever it is located on a cluster.
5) Resilient to failure: A Key advantage of using hadoop is its fault tolerance.
B) Disadvantages
1) Security Concerns: just managing a complex application such as hadoop can be challenging.
2) Vulnerable by Nature: Speaking of security the very makeup of hadoop makes running it a risky proposition. 3) Not useful for Small Data: while big data is not exclusively made for big business, not all big data platforms are
suited for small data nodes.
4) Potential Stability Issues: hadoop is an open source platform.
5) General Limitation: one of the most interesting highlights of the Google article referenced earlier mentions that when it comes to making the most of big data hadoop may not be the only answer.
CONCLUSION
109 ACKNOWLEDGMENT
It is a great opportunity for us to express our profound gratitude towards our H.O.D, Prof. Dinesh. D. Patil who gave us the innovative idea of making this seminar & whose zeal & enthusiasm are source of inspiration for us. Also, We can't ignore the innumerable efforts undertaken by Prof. Dinesh. D. Patil, our Seminar Guide, Department of Computer Science & Engineering and we also would like to thank Prof. R.A. Agrawal, Seminar Incharge for his guidance and motivations. we would also like to thank all the staff members of Department of Computer Science & Engineering, Hindi Seva Mandal’s, Shri Sant Gadge Baba College of Engineering & Technology, Bhusawal, for their valuable assistance and support at all times.
REFERENCES
[1] 2004 MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat from Google. This paper inspired Doug Cutting to develop an open-source implementation of the Map-Reduce framework. He named it Hadoop, after his son's toy elephant.
[2] K. Shvachko, Hairong Kuang, S. Radia and R Chansler – The Hadoop Distributed File System. Mass Storage Systems and Technologies (MSST), 2010 IEEE 26th Symposium 3-7 May 2010
[3] Hadoop: The Definitive Guide, Third Edition by Tom White (O’Reilly - 2012)
[4] W. Lang and J. M. Patel, “Energy management for mapreduce clusters,” Proceedings of the VLDB Endowment, vol. 3, no. 1-2, pp. 129–139, September 2010.
[5] A. F. Gates, O. Natkovich, S. Chopra, P. Kamath, S. M. Narayanamurthy, C. Olston, B. Reed, S. Srinivasan, and U. Srivastava, “Building a High- Level Dataflow System on top of Map-Reduce: The Pig Experience,”
in Proceedings of VLDB, 2009.
[6] F. Chang, J. Dean, S. Ghemawat, W. C. Hieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber, “Bigtable: A Distributed Storage for Structured Data,” in Proceedings of the 7th Symposium on Operating
System Design and Implementation, 2006, pp. 205–218.