13
Plagiarism Detection for Malayalam
Documents
Nidhinraj P P
1, Jamsheedh C V
2, Neethu Subash
31,2,3
Department of CSE, MA College of Engineering Kothamangalam, Kerala, India.
ABSTRACT
Plagiarism is an illicit act which has become a prime concern mainly in educational and research domains. This deceitful act is usually referred as an intellectual theft which has swiftly increased with the rapid technological developments and information accessibility. Thus the need for a system/ mechanism for efficient plagiarism detection is at its urgency. The most general form of detecting plagiarism is by computing similarity between a source document and a possibly plagiarized document. Existing plagiarism detection systems are mainly designed for detection in English. Moreover, plagiarism detection systems using natural language processing techniques are still very limited. Automated plagiarism detection systems so far have involved minimal syntactic and semantic linguistic techniques. Even though, in some systems shallow techniques have been included as part of the preprocessing stage, studies involving deep techniques are less. Very negligible research has been done for plagiarism detection in Malayalam text documents. A method for plagiarism detection in Malayalam documents based on computing similarity between documents to detect plagiarism is developed. The technique can detect documents created by direct copy methods, replacement of words with similar ones, changing the order of words or restructuring the sentences and also converting the sentence from active/ passive to passive/active.
Index Terms: Semantic Role Labeling ( SRL ), Part Of Speech ( POS )Tagging, Plagiarism Detection, Sentence Similarity.
I. INTRODUCTION
Several kinds of plagiarism detection systems have been developed for the English language documents but hidden plagiarism such as paraphrasing and structure change cannot be detected. Plagiarism detection systems are mainly belonging to external or extrinsic detection systems. External or extrinsic plagiarism detection systems compare a suspected document with a set of original or source documents. Intrinsic plagiarism detection systems use statistical methods to examine the linguistic features of a text. In this method, no comparison is done with other documents. These systems report plagiarism when a change in writing style is identified in the same document and this process is known as stylometry.
Motivation: Increased use of the internet has brought a lot of influence in social lifestyle. Plagiarism is one of the misuse of information from the internet in which a part or whole document that have been copyrighted has been reproduced without mentioning the author in the correct way. Academics know that student valuable learning experience is supported with the help of information, but by the use of plagiarism these experience get demolished. Regarding project based activities for academics it is believed that plagiarism cannot be done easily but still some students try to plagiarize by copying the work done by the other students which is difficult for the faculty to find out.
Scope and Objectives: The objective of this work is to build a consistent system for plagiarism detection in Malayalam text. The system aims to identify whether an input text file is plagiarized or not, and also the amount of plagiarism. The plagiarism detection tool presented here has the mechanism of detecting similarity beyond exact words match of Malayalam documents. The tool is based on a new comparison algorithm that uses some NLP techniques to compare suspect documents which may not be identified using existing methods for Malayalam document plagiarism detection.
14 The next case of word by word plagiarism is also known as copy–paste or verbatim copy. It consists of the exact copy of a part or the entire text from a source document into the plagiarized document. In paraphrase plagiarism, content from the source document is paraphrased and used in the plagiarized document. Hence, automatic plagiarism detection has significant importance in identifying the different types of plagiarism caused due to the easy accessibility of text over the internet. This work is an extrinsic monolingual plagiarism detection approach which identifies whether the suspected documents are plagiarized versions of a given source document.
A plagiarism detection tool for plagiarism detection in Malayalam documents is presented. Many language-sensitive tools for detecting plagiarism in natural language documents have been developed, particularly for English. Detecting plagiarism in Malayalam documents is particularly a challenging task because of the complex linguistic structure of Malayalam. The plagiarism detection tool presented here has the mechanism of detecting similarity beyond exact words match of Malayalam documents. The tool is based on a new comparison algorithm that uses some NLP techniques to compare suspect documents which may not be identified using existing methods for Malayalam document plagiarism detection.
II. RELATEDSTUDIES
Plagiarism Detection Methods:
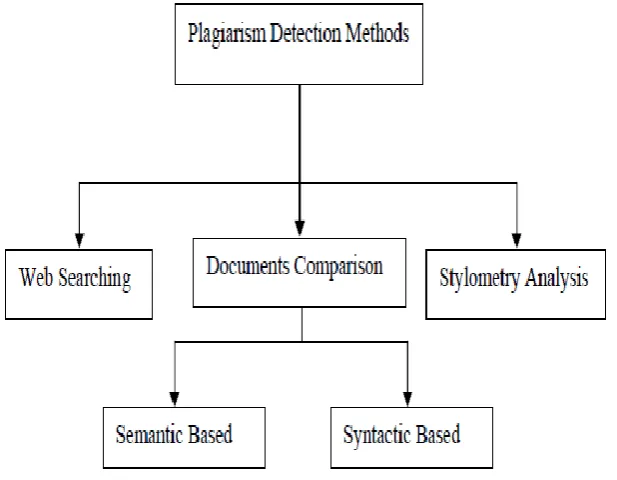
Plagiarism detection methods can be broadly classified into three main categories; the first category tries to capture the author style of writing and find any inconsistent change in this style. This is known as stylometry analysis. The second category is more commonly used which is based on comparing multiple documents and identifying overlapping parts between these documents. The third category takes a document as input and then searches for plagiarism patterns over the Web either manually or in an automated manner.
Figure 1: Plagiarism Detection Methods
Detection Based on Stylometry Analysis:
Detection methods that are applied to one or more documents belong to the same author, and without external sources, are referred as intrinsic plagiarism detection methods. The most well-known methods are Stylometry methods. Stylometry is a statistical approach to determine the authorship of literature. This approach requires well defined quantification of linguistic features (known as Stylometric features) which can be used to determine inconsistencies within a document.
15 Detection Based on Document Comparison:
Violation can occur when a fragment of text of whatever size and distribution is duplicated between two or more documents belonging to different authors, in this case the system syntactically searches for any such overlaps. However, due to the complexity of natural languages, it is possible that the same content are presented in different semantics (e.g., paraphrasing), or the same words or phrases could have different meanings in different contexts, in this case a deep analysis must be used by the system, and some Natural Language Processing (NLP) techniques could be employed. In both cases it is required that a referential collection of documents (corpus) exist. This section briefly discusses methods for both semantic and syntactic plagiarism detection.
Semantic Based Detection-
Most copy detection system can only compare syntactically similar words and sentences, thus if the copied materials are modified considerably it is difficult to detect plagiarism in such systems. The modification can range from replacing words by their synonyms, to introducing the same concept under different semantics. By using WordNet thesaurus for retrieving synonyms the problem of word substitution could be handled, however because word senses are ambiguous, selection of the correct term is often non-trivial. For more complex plagiarism patterns such as sentence structure changes, a deeper analysis is required. Kang et al. introduced the system PPChecker that calculates the amount of data copied from the original document to the query document, based on linguistic plagiarism patterns.
Since they used sentences as comparing units between documents, they identified five patterns; the exact sentence copying, word insertion, word deletion, word substitution between sentences, and the whole sentence change pattern. Those patterns are identified based on three decision conditions; word overlap, word difference, and size overlap. For each pattern, they identified different similarity measure and achieved impressive results over some syntactic-based systems. Tachaphetpiboon et al. proposed a novel linguistic analysis method for plagiarism detection, using syntactic-semantic analysis. Syntactic analysis was carried out by the use of a parser to identify grammar rules in the texts and determine the structures of the texts. Then, the structures of the texts are compared by grammar rules. Their system as well as PPChecker used WordNet for retrieving synonyms.
Syntactic Based Detection-
Unlike semantic-based, syntactic-based methods do not consider the meaning of words, phrases, or sentence. Thus the two words “exactly” and “equally” are considered different. This is of course a major limitation of these methods in detecting some kinds of plagiarism. Nevertheless they can provide significant speedup gain comparing to semantic-based methods especially for large data sets since the comparison does not involve deeper analysis of the structure and/or the semantics of terms.
Web Based Detection Tools-
This section reviews some existing plagiarism detection tools and highlights some weaknesses of these tools based on a comparative study on 10 abstracts selected from ACM digital library and manually plagiarized by synonym replacing. Most Web-based plagiarism detection tools use search engine APIs. An example of such tools is DocCop which is one of the most simple and basic tools. The tool chunks the query document into N-grams (consecutive words of length N) and then uses the N-grams as queries. It then measures the degree of plagiarism by the percentage of queries with non-empty response from the search engines divided by the number of all queries.
Semantic Networks-
16
III. PROPOSEDMETHODOLOGY
The semantic related approach will be adopted in measuring the similarity between sentences by adding supports for other part-of-speeches in particular for adjectives and adverbs. This approach will be evaluated against Ngrams representation with three symmetric measures namely Cosine, Jaccard, and Dice coefficients in an inverted index implementation.
A. Corpus Preparation
Ten movie review documents in Malayalam, will be downloaded from mathrubhumi.com. From those 10 documents, 5 query documents will be constructed by manually selecting a number of sentences (to be plagiarized) and a record about each sentence will be kept in an information table. Each record in the table has four fields namely, the source document identifier, query document identifier, source sentence identifier, and the query sentence identifier (the identifier of a sentence is its order in a document). This table will be used as a reference in the evaluation phase.
Each query document will be differently plagiarized from the others and carries out some or all of the following instances of plagiarism:
Changing the order of words within a sentence, the structure of sentences.
Changing words’ part-of-speeches (e.g., in computing/the computation...), and inflected forms (e.g., complexity/complexness).
Removing some of the contents of the original sentence, adding other words in the same context, or adding noisy words.
Replacing some or most words by their synonyms and antonyms.
Restating the contents or the idea of a sentence in different meaning, different semantics. Only a few numbers of sentences will be left without any change.
B. Document Preprocessing
This stage is applied for all query documents as well as the corpus documents. There are four steps in this stage:
Non-essential tokens such as punctuation, numbers, and parenthesis are excluded. Sentences are extracted during this process by taking all words up to a period or a question mark. Sentences that are less than three words are omitted.
Stop-words are excluded. Note that the list consists of a small number of words, this is essential since the comparison is between sentences, and sentences are of small length. Those are the words that occur with highest frequency in the Brown corpus. All remaining words are then lowercased. In case of semantic relatedness between sentences, this step is postponed after the part-of-speech tagging step since the tagger will need all information about the processed sentence including the functional words. The tokenized, non-stop words are stemmed. Stemming is applied only to N-grams-based representation.
Stemming is not applying when measuring the semantic relatedness between sentences for two reasons. First stemming may reduce words to inflected form so that they might not be found in WordNet. The second reason is to preserve the original meaning of words. Furthermore WordNet has its own morphological analyzer to handle words inflected forms so that they can still be found in WordNet. Before measuring the semantic relatedness between sentences, the tokenized words are tagged using
Amrita Malayalam Tagset. Some of those tags are mapped to the basic part-of-speech tags that are used in WordNet (noun, verbs, adjectives and adverbs) and the rest of them are discarded.
C. Applying Plagiarism Detection Techniques
The procedure of representing documents and the definition of the similarity measure(s) for each technique is detailed in this section.
Semantic Relatedness Approach:
17 N-Grams Approach:
This representation is defined as follows. The set of N-grams is obtained from the pre-processed query document, each N-gram then correspond to one dimension in the space. Given the set of N-grams G={g1,g2,…,gm}, each sentence s that either belongs to the query document or a corpus document is an m-dimensional binary vector v such that v[i]=1 if gi � s, and v[i]=0 otherwise.
IV. PROPOSED ARCHITECTURE
Figure 2: System Architecture
The system architecture used is described according to the block diagram. Normalization: In the Normalization phase the following preprocessing steps are done. In the Tokenization phase the input text from both the suspicious document and the original document are broken up into tokens. Tokens are usually words and are taken as a continuous string of characters which are separated by a space, line break, or punctuation characters. In the Stopwords removal phase the commonly occurring words in documents like some verbs, adverbs and adjectives are treated as stop-words. They are removed in order to get more significant results. It reduces the size of the document. A list of stopwords in Malayalam was identified. These stopwords are removed from the text. In the Lemmatization phase, the normalized form of a word is found. Lemmatization is similar to word stemming but it does not require to produce a stem of the word but to replace the suffix of a word, appearing in free text, with a different word suffix to get the normalized word form.
Lemmatization reduces the variants of the same root word to a common concept. No algorithm is readily available for lemmatization of Malayalam words. The main difficulty of word lemmatization of Malayalam is that Malayalam is a highly inflected natural language, having up to 56 different word forms for the same normalized verb.
The root form of each word is identified as follows: -Check for suffix starting from the right end of the word using a suffix table. -remove the longest suffix found and make necessary changes to obtain the correct root form.
Word Matching: In this phase each normalized word is checked with the normalized word from text input box two. And a potential match is counted as weight of one
Synonym match: When a non-matching word is found, it is replaced with its synonym to see whether a match is found.
Calculate percentage of matching: In this phase a ratio between the two documents over the similarity and number of words is made. The comparison between documents can be then performed on the basis of standard similarity measures such as the Jaccard coefficient and the containment measure.
V. EXPERIMENTALRESULTS DESIGN:
18 in implementing the candidate system. In system design, there is a movement from the logical to the physical aspects of the life cycle.
This is the phase in which the details of the system selected in the study phase is designed. Software design is the preliminary step and is also building block of software engineering. The efficiency software is promoted through design phase. The design phase begins when the requirement specification document for the software to be developed is available. Design is the first step to moving from the problem domain to the solution domain. Design is essentially the bridge between requirement specification and the final solution for satisfying the requirements. Design of input and outputs are important features of design specification. The input design is the links that tie the system to the world of its users. Output generally refers to the results that are generated by the system.
The first step is to determine how the output is to be produced and in what format. Then input data and master files have to be designed at the next step and finally the impact of the candidate system on the user and organization are documented and evaluated by the management. After identifying the problem and the limitations of the existing system, a detailed design of the proposed system is conducted. Free flow personnel interview and reference to previous records prepared manually were the only methods taken to collect necessary information. At present, the all organizations are on the path of computerization process.
Design is the phase that indicates the final system. It is the solution, the translation of requirements into ways of meeting them. In this phase the following elements were designed namely, dataflow, data stores, processes, procedures. Firstly the logical design was done where the outputs, inputs, databases and the procedures was formulated in a manner that meet the project requirements. After logical design physical construction of the system is done. The database tables, Input screens, output screens, output reports are designed. After analysing the various functions involved in the system the database, labels a dictionaries designed. Care is taken for the field name to be in self-explanatory form. Unnecessary fields are avoiding so as not affecting the storage of the system. Care must be taken to design the input screen in the most user-friendly way so as to help even the novice users make entries approximately in the right place. This is being accomplished by the use of giving online help messages, which are brief and cleanly prompts users for the appropriate action. The characteristics of a well-defined system are: accessibility, decision making capability, economy, reliability, simplicity.
Input Design:
Input data of a system may not be necessarily a raw data captured in the system from scratch. The design of inputs involves identifying the data needed, specifying the characteristics of each data item, capturing and preparing data for computer processing and ensuring correctness of data.
Figure 3: Sample of initial dataset
Input data for plagiarism detection system involves 20 documents were extracted from the online Malayalam newspaper Mathrubhumi. From the original documents, plagiarized documents were created. It is really tough to find journals in Malayalam Unicode encoding. That was the reason for using contents from online newspaper Mathrubhumi.
Output Design:
19 The output from a system is the justification for its existence. If the outputs are inadequate in any way, the system itself is inadequate. The basic requirements of output are that it should be accurate, timely and appropriate, in terms of content, medium and layout for its intended purpose. Hence it is necessary to design output so that the objectives of the system are met in the best possible manner. The outputs are in the form of reports.
When designing output, the system analyst must accomplish things like, to determine what information to be present, to decide whether to display or print the information and select the output medium to distribute the output to intended recipients. External outputs are those, whose destination will be outside the organization and which require special attention as the project image of the organization.
In this project the output is a graphical user interface displaying the percentage of plagiarism.
Figure 4: Sample of output
VI. IMPLEMENTATION
Working Principle:
The working principle of plagiarism detection system:
Comparison Methodologies:
The system takes trigrams in the experiments, as trigrams are found to be the balance between efficiency and effectiveness (Clough & Stevenson 2009) Overlapping trigrams in sentences can be show as follows:
Original sentence
“Make hay while the sun shines.”
Trigrams {Make hay while}, {hay while the}, {while the sun}, {the sun shines}
Similarity between texts is measured by computing sets of trigrams for the suspicious and original texts and comparing these to determine the degree of overlap. A similarity function is used to measure the degree of overlap between the two texts represented by the set of trigrams and a threshold is chosen above which the texts are considered as plagiarised. The similarity measures used the detection system are the following:
Jaccard similarity coefficient: (𝐴,𝐵)=⎸S A ∩S(B)⎸⎸S A ⋃ S(B)⎸
Where S(A) and S(B) represent the sets of trigrams in the suspicious and original documents respectively. The measure calculates the intersecting trigrams, and normalises it by the trigrams in the union which is the set of all trigrams in those documents. The containment measure was used by Clough & Stevenson (2009)
(𝐴,𝐵)=⎸S A ∩S(B)⎸⎸S A ⎸
Where S(A) and S(B) represent the sets of trigrams in the suspicious and original documents respectively. The containment measure calculates the intersecting trigrams, but normalises by the trigrams in the suspicious document only. This measure is more suitable when document pairs are of different document lengths. (Broder, 1997) The original documents are usually longer than the plagiarized ones.
Algorithm to calculate similarity: Similarity:
20 Output-the similarity decision.
1. Get n-grams list of the two texts. 2. Perform w-shingling.
3. Get the number of tokens common in the lists. 4. Get the total number of tokens.
5. Divide the output of step 3 and step 4.
6. Store the output of step 5 to the resemblance measure R. 7. If (R > threshold)
7.1 Output „the documents are similar‟. 8. Else
8.1 Output „the documents are dissimilar‟. 9. Stop
VII. EVALUATION METRICS
A set of standard performance measures that are widely used in information retrieval and text mining including confusion matrix and measures calculated from it, such as the percentage detection accuracy, precision, recall and F-measure are calculated.
Figure 5: Interface for selecting test document
The confusion matrix shows the number of expected versus the obtained cases for each category. Accuracy is the percentage of correctly identified cases but it is not a good measure when the dataset is unbalanced. Recall is defined as the number of relevant documents retrieved by a search divided by the total number of existing relevant documents, while precision is defined as the number of relevant documents retrieved by a search divided by the total number of documents retrieved by that search. F-measure combines precision and recall using their geometric mean. This section gives the result of plotting the dataset and clustering of categorical time series in the form of tables.
Figure 6: Interface to display plagiarism percentage
21 The results of the experiments presented in this paper are considered satisfactory for classifying the documents in the corpus into two categories: plagiarized and non-plagiarized. 46 out of 50 plagiarized documents were correctly classified and only 5 non plagiarized documents were classified as plagiarized. The system obtained 92% precision, 90% recall and 90% F-measure. Experiments have proven that using this method can detect plagiarism by direct copying and also plagiarism by synonym replacement. But still final human judgment is essential to correctly judge the results obtained from the plagiarism detection system.
Dataset:
20 documents were extracted from the online. Malayalam newspaper Mathrubhumi. From the original documents, plagiarized documents were generated as follows:
Fig.7: Comparison of results
- Half of the total number of words in each document was replaced randomly with their similar words. Stop-words were avoided.
- By changing the sentence structure of some sentences. Such sentences amount to half of the entire number of sentences.
- By copying randomly selected sentences, substituting some words with one of their synonyms, and changing the structure of selected sentences.
EVALUATION MEASURES:
Fig. 8: Comparative results
A classification system can be used to evaluate a plagiarism detection system as belonging to either of the categories: copied or original. The measures such as precision, recall and F-measure are used to evaluate the system. Recall is defined as the number of the plagiarized sentences that are actually detected. Precision is defined as the number of detected sentences are actually plagiarized. F-measure is the harmonic mean of precision and recall.
22 VIII. COMPARATIVE RESULTS
The different fingerprinting techniques- k-gram , 0 mod p, and winnowing were evaluated with the value of k was chosen as 3 for k-gram, the value of p was chosen as 6 for 0 mod p, and the value of w was chosen as 10 for winnowing. It is found that k-gram generated too many fingerprints, but gave most accurate results. So k-gram method can be considered best when the document collection is small. For detecting near-duplicate copies, winnowing gives better results.
CONCLUSION
Information technologies bring the issue of digital plagiarism along with the benefits. This work aimed to develop a computer system to discover plagiarism in Malayalam document submissions. In this paper, a framework for automatic plagiarism detection for Malayalam documents has been proposed. Till date, no tool is available for checking for plagiarism with synonym replacement in Malayalam language. A contribution made as part of this work is a similarity checker module which can used as part of any Malayalam language processing task. The results of the plagiarism detection system indicate that this system has the capability to detect exact copy and also changes caused due to synonym replacement. One of the problems the system face is the non-availability of possible sources to compare with the suspected documents. This limits the potential of algorithms that compute document-to-document similarity. As future work, it is intend to improve the detection accuracy by including other semantic and contextual features. Also the proposed method can be improved by using more documents.
REFERENCES
[1]. Sindhu.L, Sumam MaryiIdicula, "Fingerprinting based Detection System for Identifying Plagiarism in Malayalam Text Documents" 2015 Intl. Conference on Computing and Network Communications (CoCoNet'15), Dec. 16-19, 2015, Trivandrum, India
[2]. Vani K and Deepa Gupta," Investigating the Impact of Combined Similarity Metrics and POS tagging in Extrinsic Text Plagiarism Detection System" 2015 International Conference on Advances in Computing, Communications and Informatics (ICACCI)
[3]. “Defining and Avoiding Plagiarism”. The WPA Statement on Best Practices.
http://www.princeton.edu/writing/university/resources.
[4]. Sindhu L, Sumam Mary Idicula, "SRL based Plagiarism Detection System for Malayalam Documents", IJCSI International Journal of Computer Science Issues, Volume 12, Issue 6, November 2015 ISSN (Print): 1694-0814 | ISSN (Online): 1694-0784 www.IJCSI.org.
[5]. Sindhu. L, Bindu Baby Thomas and Sumam Mary Idicula., "Automated Plagiarism Detection System for Malayalam Text Documents", International Journal of Computer Applications (0975 – 8887) Volume 106 – No. 15, November 2014.
[6]. Lancaster, T., Culwin, F. Classification of Plagiarism Detection Engines. Ejournal ITALICS, vol. 4 issue 2, ISSN 1473-7507., 200
[7]. Ahmed Jabr Ahmed Muftah, "Document Plagiarism Detection Algorithm using Semantic Networks, a project report submitted in partial fulfillment of the requirements for the award of the degree of Master of Science.
[8]. Lukashenko R., Graudina V., Grundespenkis J. Computer-based plagiarism detection methods and tools: an overview. In Proceedings of the International Conference on Computer Systems and Technologies, Bulgaria, 2007.
[9]. “Plagiarism:What is it ?”. University of Kentucky.http://www.uky.edu/Ombud.
[10]. Khan Muhammad, Abdul Aleem, Abdul Wahab, and M. Nasir Khan, „Copy detection in Urdu Language Documents
using n-grams Model‟, Department of Computer Science, University of Peshawar, Pakistan.
[11]. Peter David and Latha R Nair, „Development of a Rule Based Learning System for Splitting Compound Words in Malayalam Language‟.
[12]. Varma A.R.R.R, „Kerala Paniniyam‟, DC. Books, Kerala, India, 2000.
[13]. Narayana Pilla K.S, „Aadhunika malayala vyakaranam‟, Kerala Bhasha Institute, 2nd Edition, 2003,pp.30-35. [14]. Kasprzak Jan, Michal Brandejs, and Miroslav Kipaal, „Finding Plagiarism by Evaluating Document Similarities‟