Organized by C.O.E.T, Akola. Available Online at www.ijpret.com190
INTERNATIONAL JOURNAL OF PURE AND
APPLIED RESEARCH IN ENGINEERING AND
TECHNOLOGY
A PATH FOR HORIZING YOUR INNOVATIVE WORK
STUDY OF PARTITIONING TECHNIQUES AND MANAGING SECURITY IN
CLOUD DATABASE
MISS. SONALI. S. DHULE1, PROF. P. L. RAMTEKE2
1.Computer science and engineering department, ME Student, HVPM’S College of Engineering And Technology, Amravati, Amravati University, 2.Department Of Information and technology, Faculty Of Engineering, HVPM’S College of Engineering And Technology, Amravati, Amravati University,
Accepted Date: 12/03/2016; Published Date: 02/04/2016
Abstract: Cloud Computing has been envisioned as the next-generation architecture of IT Enterprise. It moves the application software and databases to the centralized large data centers, where the management of the data and services may not be fully trustworthy. Fears of leakage of sensitive data or loss of privacy make the adoption of cloud services less attractive for organizations.In this paper, we are dealing with data partitioning. An algorithm is presented to protect a table in a database from any leakage. We have developed a model with a view to offer secure data management capability in cloud databases. The model distributes and scatters the data over the cloud or data center in order to protect it from any leakage. Also, it explains the idea of sending the entire domain of the sensitive table into the cloud. In addition, to increase security, the algorithm is designed to store each sensitive data in a different table with a different code and store this code at the client site. Furthermore, a new technique has been designed to collect the data from the cloud by using the bipartite matching algorithm to minimize load costs.
Keywords: Cloud Computing; Sensitive Information; Data Security; Data Encryption; SQL
Corresponding Author: MISS. SONALI. S. DHULE
Co Author: PROF. P. L. RAMTEKE
Access Online On:
www.ijpret.com
How to Cite This Article:
Sonali S. Dhule, IJPRET, 2016; Volume 4 (8): 190-197
PAPER-QR CODE
SPECIAL ISSUE FOR
NATIONAL LEVEL CONFERENCE
"RENEWABLE ENERGY
Research Article Impact Factor: 4.226 ISSN: 2319-507X Sonali S. Dhule, IJPRET, 2016; Volume 4 (8): 190-197 IJPRET
Organized by C.O.E.T, Akola. Available Online at www.ijpret.com191
INTRODUCTION
Organized by C.O.E.T, Akola. Available Online at www.ijpret.com192
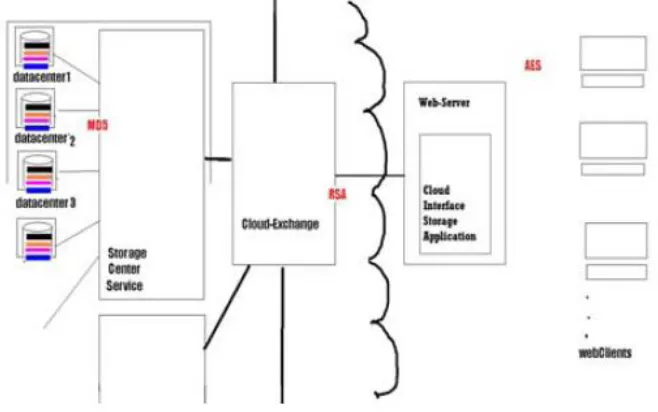
Fig. 1 Cloud data Partitioning
I. TECHNIQUES OF DATA PARTITIONING
1. Horizontal Partitioning ﴾Sharding﴿
Figure 1 shows an overview of horizontal partitioning or sharding. In this example, product inventory data is divided into shards based on the product key ﴾each shard holds the data for a contiguous range of shard keys, organized alphabetically﴿.
Research Article Impact Factor: 4.226 ISSN: 2319-507X Sonali S. Dhule, IJPRET, 2016; Volume 4 (8): 190-197 IJPRET
Organized by C.O.E.T, Akola. Available Online at www.ijpret.com193
Sharding enables you to spread the load over more computers; reducing contention, and improving performance. You can scale the system out by adding further shards running on additional servers.
The most important factor when implementing this partitioning strategy is the choice of sharding key. It can be difficult to change the key after the system is in operation. The key must ensure that data is partitioned so that the workload is as even as possible across the shards— some shards may be very large but each item is the subject of a low number of access operations, while other shards may be smaller but each item is accessed much more frequently. It is also important to ensure that a single shard does not exceed the scale limits of the data store being used to host that shard. The sharding scheme should also avoid creating hotspots
﴾or hot partitions﴿ that may affect performance and availability. For example, using a hash of a customer identifier instead of the first letter of a customer’s name will prevent the unbalanced distribution that would result from common and less common initial letters. This is a typical technique that helps to distribute the data more evenly across partitions. The sharding key you choose should minimize any future requirements to split large shards into smaller pieces, coalesce small shards into larger partitions, or change the schema that describes the data stored in a set of partitions. These operations can be very time consuming, and may require taking one or more shards offline while they are performed. If shards are replicated, it may be possible to keep some of the replicas online while others are split, merged, or reconfigured, but the system may need to limit the operations that can be performed on the data in these shards while the reconfiguration is taking place. For example, the data in the replicas could be marked as read‐only to limit the scope of any inconsistences that could otherwise occur while shards are being restructured.
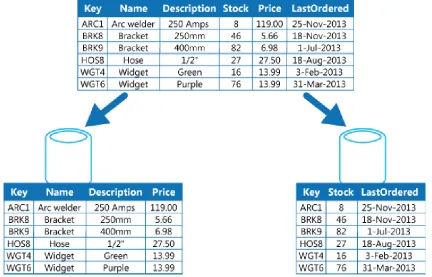
2. Vertical Partitioning
Organized by C.O.E.T, Akola. Available Online at www.ijpret.com194
Fig. 3 Vertical partitioning organizes data by its pattern of use
In this example, the application regularly queries the product name, description, and price together when displaying the details of products to customers. The stock level and date when the product was last ordered from the manufacturer are held in a separate partition because these two items are commonly used together. This partitioning scheme has the added advantage that the relatively slow‐moving data ﴾product name, description, and price﴿ is separated from the more dynamic data ﴾stock level and last ordered date﴿. An application may find it beneficial to cache the slow‐moving data in memory. Another typical scenario for this partitioning strategy is to maximize the security of sensitive data. For example, by storing credit card numbers and the corresponding card security verification numbers in separate partitions. Vertical partitioning can also reduce the amount of concurrent access required to the data.
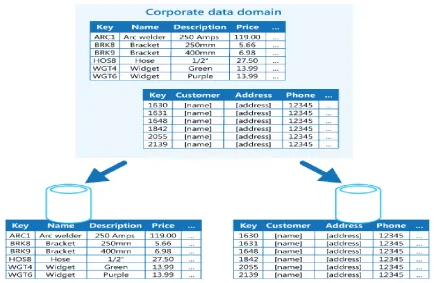
3. Functional Partitioning
Research Article Impact Factor: 4.226 ISSN: 2319-507X Sonali S. Dhule, IJPRET, 2016; Volume 4 (8): 190-197 IJPRET
Organized by C.O.E.T, Akola. Available Online at www.ijpret.com195
inventory data is separated from customer data. This partitioning strategy can help to reduce data access contention across different parts of the system.
Fig. 4 Functional Partitioning separate data by bounded context or subdomain
II. PARTITIONING FOR SQL QUERY
Query performance can typically be boosted by using smaller data sets and parallel query execution. Each partition should contain a small proportion of the entire data set, and this reduction in volume can improve the performance of queries. However, partitioning is not an alternative for designing and configuring a database appropriately. For example, make sure that you have the necessary indexes in place if you are using a relational database.
Follow these steps when designing the partitions for query performance:
1.Analyze the application to identify:
Queries that perform slowly.
Organized by C.O.E.T, Akola. Available Online at www.ijpret.com196
2. Partition the data that is causing slow performance.
3. If an entity has throughput and query performance requirements, use functional partitioning based on that entity. If this is still not able to satisfy the requirements, apply horizontal partitioning as well. In most cases a single partitioning strategy will suffice, but in some cases it is more efficient to combine both strategies.
4. Consider using parallel queries across partitions to improve the performance.
To evaluate query processing performance on the generated partitions, we choose different queries from one benchmark dataset (LUBM2000) and one real dataset (DBpedia) as shown in Table I. Since LUBM provides a set of benchmark queries, we select three among them. We create three queries for DBpedia because there is no representative benchmark queries.
Table 1: SQL Queries
CONCLUSION
Research Article Impact Factor: 4.226 ISSN: 2319-507X Sonali S. Dhule, IJPRET, 2016; Volume 4 (8): 190-197 IJPRET
Organized by C.O.E.T, Akola. Available Online at www.ijpret.com197
REFERENCES
1. Mr. Akash Kanade, Ms. Rohini Mule, Mr. Mohammad Shuaib, Ms. NamrataNagvekar “Improving Cloud Security Using Data Partitioning And Encryption Technique” International Journal of Engineering Research and General Science Volume 3, Issue 1, January-February, 2015 ISSN 2091-2730
2. Swapnil V.Khedkar , A.D.Gawande “Data Partitioning Technique to Improve Cloud Data Storage Security.” Swapnil V.Khedkar et al, / (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 5 (3) , 2014, 3347-3350
3. Kisung Lee, Ling Liu, Yuzhe Tang, Qi Zhang, Yang Zhou “Efficient and Customizable Data Partitioning Framework for Distributed Big RDF Data Processing in the Cloud”
4. Yogesh Shinde, Alka Vishwa “Privacy Preserving using Data Partitioning Technique for Secure Cloud Storage” International Journal of Computer Applications (0975 – 8887) Volume 116 – No. 16, April 2015
5. Osama M Ben Omran, Brajendra Panda “A New Technique to Partition and Manage Data Security in Cloud Databases” The 9th International Conference for Internet Technology and Secured Transactions (ICITST-2014)
6. Chun-Hung Cheng, Wing-Kin Lee, and Kam-Fai Wong, “A Genetic Algorithm-Based Clustering Approach for Database Partitioning” IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 32, NO. 3, AUGUST 2000
7. Siani Pearson and Azzedine Benameur, "Privacy, security and trust issues arising from cloud computing," 2nd IEEE International Conference on Cloud Computing Technology and Science, pp. 693-702, 2010.
8. Qussai Yaseen and Brajendra Panda, "Malicious Modification Attacks by Insiders in Relational Databases: Prediction and Prevention," IEEE Second International Conference on Privacy,
Security, Risk and Trust, pp. 849-856, August 2010.
9. Sunil Sanka, Chittaranjan Hota, and Muttukrishnan Rajarajan, "Secure Data Access in Cloud Computing," In Internet Multimedia Services Architecture and Application (IMSAA), 2010 IEEE 4th International Conference, pp. 1-6, 2010.