Image Retrieval System by Automatic Annotation
Muhamad Saleem P PG scholar Sree Venkateswara Hi-Tech
Engineering College [email protected]
R. Senthilkumar Assistant Professor Sree Venkateswara Hi-Tech
Engineering College
Dr.T.Senthil Prakash Head /Department of CSE Sree Venkateswara Hi-Tech
Engineering College [email protected]
Abstract—Automatic image annotation is the process by which a computer system automatically assigns metadata in the form of captioning or keywords to an image. This application of computer vision techniques is used in image retrieval systems to organize and locate images of interest from database. Most of the existing work such as Latent Semantic Indexing and Markovian Semantic Indexing (MSI) has been presented for online image retrieval system. By extending these methods, the proposed system uses Semantic annotated Markovian Semantic Indexing(SMSI) for retrieving the images. The proposed system automatically annotates the images using hidden Markov model. To annotate images, concepts are represented as states by using Hidden Markov model. The parameters of the model are estimated from a set of manually annotated (training) images. Each image in a large test collection is then automatically annotated with the a posteriori probability of concepts present in it. After annotating these images, semantic retrieval of images can be done. This can be done by using Natural Language processing tool namely WordNet and also measuring semantic similarity of annotated images in the database using MSI.
Index Terms— Image Retrieval, Hidden Markov model, Markovian Semantic IndexingSemantic annotated Markovian Semantic Indexing,.
I. INTRODUCTION
Image retrieval procedures can be divided into two approaches: query-by-text (QbT) and query-by-example (QbE). In QbT, queries are texts and targets are images. That is, QbT is a cross-medium retrieval. In QbE, queries are images and targets are images.Thus, QbT is a mono-medium retrieval. For practicality, images in QbT[19] retrieval are often annotated by words. When images are sought using these annotations, such retrieval is known as annotation-based image retrieval (ABIR). In contrast, annotations in a QbE setting are not necessary, although they can be used. The retrieval is carried out according to the image contents. Such retrieval is known as content-based image retrieval (CBIR). A basic difference between ABIR and CBIR is related to the values of textual and visual information in image retrieval.
An image retrieval system is a computer system for browsing, searching and retrieving images from a large database of digital images. Most traditional and common methods of image retrieval utilize some method of adding metadata such as captioning, keywords,or descriptions to the images so that retrieval can be performed over the annotation words. Manual image annotation is time consuming, laborious and expensive; to address this, there has been a large amount of research done on automatic image annotation. Additionally, the increase in social web applications and the semantic web have inspired the development of several web-based image annotation tools. Image search is a specialized data search used to _nd images. To search for images, a user may provide query terms such as keyword, image _le/link, or click on some image, and the system will return images similar to the query. The similarity used for search criteria could be meta tags, color distribution in images, region/shape attributes, etc._ Image meta search - search of images based on associated metadata such as keywords, text, etc.
Annotation based image retrieval (ABIR) the application of computer vision to the image retrieval. ABIR aims at avoiding
the use of visual information and instead retrieves images based on user text queries.
Image collection exploration - search of images based on the use of novel exploration paradigms.
(training) collection. of image+caption pairs, and then automatically annotate a collection of test images using this generic vocabulary of keywords.
2. RELATED WORK
Learning the Semantics of Words and Pictures[1] present a method which organizes image databases using both image features and associated text. By integrating the two kinds of information during model construction, the system learns links between the image features and semantics which can be exploited for better browsing, better search, and novel applications such as associating words with pictures, and unsupervised learning for object recognition. The system works by modelling the statistics of word and feature occurrence and co-occurrence. We use a hierarchical structure which further encourages semantics through levels of generalization, as well as being a natural choice for browsing applications. An additional advantage of our approach is that since it is a generative model, it implicitly contains processes for predicting image components, words and features from observed image components. The Story Picturing Engine[2] present an unsupervised approach to automated story picturing. Semantic keywords are extracted from the story, an annotated image database is searched. Thereafter, a novel image ranking scheme automatically determines the importance of each image. Both lexical annotations and visual content play a role in determining the ranks. Annotations are processed using the Wordnet. A mutual reinforcement based rank is calculated for each image.
2.1 Hidden Markov Models
Hidden Markov Models for Automatic Annotation[4] introduces a novel method for automatic annotation of images with keywords from a generic vocabulary of concepts or objects for the purpose of content-based image retrieval. An image, represented as sequence of featurevectors characterizing low-level visual features such as color, texture or oriented-edges, is modeled as having been stochastically generated by a hidden Markov model, whose states represent concepts. The parameters of the model are estimated from a set of manually annotated (training) images. Each image in a large test collection is then automatically annotated with the a posteriori probability of concepts present in it. Annotation of Images Using Spatial Hidden Markov Model is a 2D generalization of the traditional HMM in the sense that both vertical and horizontal transitions between hidden states are taken into consideration. The two most crucial problems with this approach are how to build a statistical model[5] for each concept class, and how to propagate annotations from keywords associated with some specific classes. In this a new spatial-HMM to describe the spatial relationships of objects and investigate the semantic structures of concepts in natural scene images.
2.2 Latent Semantic Indexing (LSI)
Latent semantic indexing (LSI)[7] is an indexing and retrieval method that uses a mathematical technique called singular value decomposition (SVD) to identify patterns in the relationships between the terms and concepts contained in an unstructured collection of text. LSI is based on the principle
that words that are used in the same contexts tend to have similar meanings. A key feature of LSI is its ability to extract the conceptual content of a body of text by establishing associations between those terms that occur in similar contexts. When Latent Semantic Indexing (LSI) is used for Image retrieval, Singular Value Decomposition (SVD) is used to decompose the term by Image matrix into three matrices: T a term by dimension matrix, S a singular value matrix (dimension by dimension), and D a Image by dimension matrix. After computing the SVD using the original term by document matrix, we calculate term-to-term similarities. LSI provides two natural methods for describing term-to-term similarity. First, the term-to-term matrix can be created using TkSk(TkSk)T Second, the term by dimension (TkSk) matrix can be used to compare terms using a vector distance measure, such as cosine similarity. In this case, the cosine similarity is computed for each pair of rows in the TkSk matrix. After the term similarities are created, we need to determine the order of co-occurrence for each pair of terms. The order of co-occurrence is computed by tracing the co-occurrence paths.
2.3 Markovian Semantic Indexing (MSI)
The Markovian Semantic Indexing (MSI)[8], a new method for automatic annotation and annotation based image retrieval. The properties of MSI make it particularly suitable for ABIR tasks when the per image annotation data is limited. The characteristics of the method make it also particularly applicable in the context of online image retrieval systems. The proposed approach (MSI) is presented in together with a proximity measure (distance). In geometric interpretation and the optimal properties of the proposed distance are examined a statistical model with hybrid text/visual characteristics also based on the aspect model. The approach proposed here in, while stochastic in nature, raises the reasoning aspect of probabilities, as it defines explicit relevance relationships between keywords. Using network representations for capturing semantics is common in AI systems.
3. PROPOSED SYSTEM
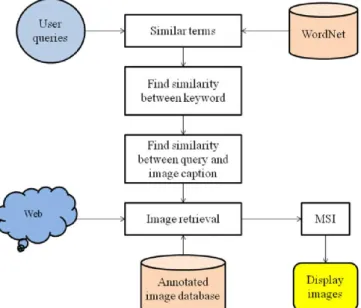
In proposed system, Semantic annotated Markovian Semantic Indexing(SMSI) is introduced in the framework of an image retrieval system where users search for images by submitting queries that are made of keywords. This system carries out two major tasks.
1. Automatic image annotation 2. Annotation based image retrieval
Automatic image annotation phase makes use of a manually annotated training set taken to generate an annotated image database.
Annotation based image retrieval phase gets a user query, then find similar terms for the query with the help of WordNet. Also discover the similarity between the query and images in annotated image database. Then find the similarity between matching images.
Figure 3.1 System Architecture
3.2 System Modules
The collection of valuable user generated posts and their summary generation process is done by dividing the task into four different modules. These modules are implemented[10] in the order as they are given in the following section. Details of this implementation process is given in next section of this chapter.
3.2.1 Document collection Module
Before implementing A Forum crawler some forum sites are deeply studied. Based on these studies , document collection module was started;[11] This step includes finding the best forums and threads for the posts that is required. Forums selection is done after fixing the domain of the discussions carrying out. Most of the data mining projects utilize the data warehouse to collect the required data. Here we need to extract from online forums and we need online analytical processing to collect required data. For this purpose pattern matching technique is used. Pattern is written in regular expression and is made possible by continuous analysis of the forum sites.
3.2.2 Document collection Module
The extracted posts [12] are selectively discarded before making their contents as a single file for making summary. Discarding posts by the forum etiquettes and by considering the sentence. All these elimination is done by constructing regular expression corresponding to each rules [13] in the forum etiquette.
3.2.3 Information Extraction Module
The posts are extracted and saved in temporary file [14] because the queries are different each time. This temporary file is used by the summarization Module
3.2.4 Summarization Module
Fuzzy logic is a form of knowledge representation suitable for notions that cannot be defined precisely, but which depend upon their contexts. It deals with reasoning that is approximate rather than fixed and exact. Fuzzy logic has been extended to handle the concept of partial truth, where the truth value may range between completely true and completely false. It can also use with linguistics. Linguistics is the scientific study of language. There are broadly three aspects
to the study, which include language form, language meaning, and language in context. Fuzzy logic provides an alternative way to represent linguistic and subjective attributes of the real world in computing. Here for the summarization purpose I considered the two existing methods Latent Semantic Analysis and Latent Dirchilet Allocation.
4. IMPLIMENTATION DETAILS
The image annotation phase of the system was implemented using MATLAB and image retrieval part was implemented by Dot net programming language. A dataset with 1,200 images above , in 6 classes of about 200 images in each class, annotated with keywords, each annotation being a text string of up to 25 keywords is created manually. Use this data set to make an annotated image database and is used for the experimental analysis of these different methods namely LSI, MSI, and SMSI on the basis of Precision and Recall values. Experimental result of automatic image annotation system is shown in figure 4.1. And figure 4.2 shows the experimental result of SMSI image retrieval system.
4.1
Performance Matrices
The proposed method is compared with the Markovian
semantic indexing and Latent Semantic Indexing.
Comparison with MSI and SMSI in the application area
of Annotation Based Image Retrieval with Precision
versus Recall diagrams on ground truth databases
reveal that the proposed approach achieves better
retrieval scores.
Figure 4.2: Top 6 Retrieved Images from annotated image database
Precision
The precision rate is de_ned as the ratio of the number of relevant images retrievedto the total number of images in the collection.
Precision =((relevant images) &(retrieved images))/retrieved images.
Recall
Recall rate is de_ned as the ratio of number of relevant images retrieved and to the total number of relevant images in the collection
.
Recall =((relevant images) & (retrieved images))/ relevant images
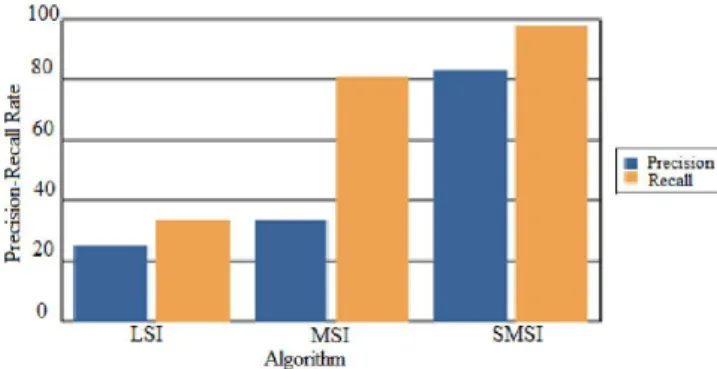
The experimental results for proposed system are plotted on graphs based on these formulas. The graphs shown in the figure 4.3 gives better analysis perspective on the Automatic annotated online image retrieval task.
Figure 4.3: Precision-Recall comparison graph
The above graph in figure 4.3 compare the Precision-Recall parameter between LSI(Latent Semantic Indexing), MSI(Markovian Semantic Indexing) and SMSI (Semantic annotated Markovian Semantic Indexing). These measures are mathematically calculated by using formula. From the graph can see that, Precision-Recall of the system is reduced somewhat in LSI, MSI than the SMSI (Semantic annotated Markovian Semantic Indexing).So it is concluded that the Precision-Recall rate of SMSI is increased which will be the best one.
6. CONCLUSION AND FUTURE WORK
The present work proposes Semantic annotated Markovian Semantic Indexing (SMSI) a semantic image retrieval is doneand its performance improved by incorporating an automatic annotation system. Automatic annotation of images in database has been done by using a proposed Hidden Markov
model which uses the extracted features (color and texture) where all states represent the concepts. Semantic similarity based image retrieval can be done with the use of Natural language processing tool namely WordNet where conceptual
similarity between natural language terms were done. Comparative analysis of proposed Semantic annotated Markovian Semantic Indexing (SMSI) has been done with the
LSI annotated image retrieval and MSI annotated image retrieval. Experimental results of Precision versus Recall for the proposed system achieves better scores than LSI and MSI. There is still a long way to go. The ultimate goal of image annotation is to process tens of thousands of images of various concepts precisely and efficiently, not a single query case. Hence in the future, we will work on reinforcing the labels of images inside a large scale database. Moreover, we are interested to tackle the problem of how to annotate query images without any associated keywords.
5. Acknowledgements
An endeavor over a long period may be successful only with advice and guidance of many well wishers. I take this opportunity to express my gratitude to all who encouraged me to complete this work. I would like to express my deep sense of gratitude to my respected Principal for his inspiration and for creating an atmosphere in the college to do the work. I would like to thank Head of the department, Computer Science and Engineering .
REFERENCES
[[1] K. Barnard and D. Forsyth, \Learning the semantics of words and pictures," in
Computer Vision, 2001. ICCV 2001. Proceedings. Eighth IEEE International Con-
ference on, vol. 2. IEEE, 2001, pp. 408{415.
[2] D. Joshi, J. Z.Wang, and J. Li, \The story picturing engine|a system for automatic
text illustration," ACM Transactions on Multimedia Computing, Communications,
and Applications (TOMCCAP), vol. 2, no. 1, pp. 68{89, 2006. [3] J. Li and J. Z. Wang, \Real-time computerized annotation of pictures," Pattern
Analysis and Machine Intelligence, IEEE Transactions on, vol. 30, no. 6, pp. 985{
1002, 2008.
[4] A. Ghoshal, P. Ircing, and S. Khudanpur, \Hidden markov models for automatic
annotation and content-based retrieval of images and video," in Proceedings of the
28th annual international ACM SIGIR conference on Research and development in
information retrieval. ACM, 2005, pp. 544{551.
[5] F. Yu and H. H.-S. Ip, \Automatic semantic annotation of images using spatial hid-
den markov model," in Multimedia and Expo, 2006 IEEE International Conference
[6] S. Wan and R. A. Angryk, \Measuring semantic similarity using wordnet-based
context vectors," in Systems, Man and Cybernetics, 2007. ISIC. IEEE International
Conference on. IEEE, 2007, pp. 908{913.
[7] M. W. Berry, S. T. Dumais, and G. W. O'Brien, \Using linear algebra for intelligent
information retrieval," SIAM review, vol. 37, no. 4, pp. 573{595, 1995.
27
References 28
[8] K. A. Raftopoulos, K. S. Ntalianis, D. D. Sourlas, and S. D. Kollias, \Mining user
queries with markov chains: Application to online image retrieval," Knowledge and
Data Engineering, IEEE Transactions on, vol. 25, no. 2, pp. 433{447, 2013.
[9] H. Cunningham, D. Maynard, K. Bontcheva, and V. Tablan, \A framework and
graphical development environment for robust nlp tools and applications." in ACL,
2002, pp. 168{175.
[10] S. Santini and R. Jain, \Similarity measures," Pattern analysis and machine intel-
ligence, IEEE transactions on, vol. 21, no. 9, pp. 871{883, 1999. [11] L. Rabiner, \A tutorial on hidden markov models and selected applications in speech
recognition," Proceedings of the IEEE, vol. 77, no. 2, pp. 257{286, 1989.
[12] F. Monay and D. Gatica-Perez, \On image auto-annotation with latent space mod-
els," in Proceedings of the eleventh ACM international conference on Multimedia.
ACM, 2003, pp. 275{278.
[13] D. M. Blei, A. Y. Ng, and M. I. Jordan, \Latent dirichlet allocation," the Journal
of machine Learning research, vol. 3, pp. 993{1022, 2003. [14] M. Wallace, Jawbone Java WordNet API, 2007. [Online]. Available: http:
//mfwallace.googlepages.com/jawbone.html
[15] Z. Zivkovic and B. Krose, \An em-like algorithm for color-histogram-based object
tracking," in Computer Vision and Pattern Recognition, 2004. CVPR 2004. Pro-
ceedings of the 2004 IEEE Computer Society Conference on, vol. 1. IEEE, 2004,
pp. I{798.
[16] J. Han and K.-K. Ma, \Fuzzy color histogram and its use in color image retrieval,"
Image Processing, IEEE Transactions on, vol. 11, no. 8, pp. 944{952, 2002.
[17] C. Mohankumar, J. Madhavan, P. Chauhan, G. Upadhyay, D. Shastri, M. Ibrahim,
S. Raj, N. Jose, N. K. Srivastava, A. K. Jaiswal et al., \Content based image
retrieval using 2-d discrete wavelet with texture feature with di_erent classi_ers,"
International Journal of Computer Science and Network Security, vol. 9, no. 5,
2009.
Department of Computer Science & Engineering MEA Engineering College
References 29
[18] H. S. Bhatt, S. Bharadwaj, R. Singh, and M. Vatsa, \On matching sketches with
digital face images," in Biometrics: Theory Applications and Systems (BTAS), 2010
Fourth IEEE International Conference on. IEEE, 2010, pp. 1{7.
[19] M. Inoue, \On the need for annotation-based image retrieval," in Proceedings of
the workshop on information retrieval in context (IRiX), She_eld, UK, 2004, pp.
44{46.
AUTHORS BIOGRAPHY