Signature Searching Concerning Association Assortment of Files
1N.Srinadh Reddy,2S.Vanaja1
Associ.Prof. & Vice Principal,2M.Tech (Research scholar) in Dep.Of Computer Science & Engineering Visvodaya Engineering College,Kavali.
Abstract:Signature is the example that you search for inside an information parcel. A signature is utilized to recognize one or numerous sorts of assaults. Signatures may be available in distinctive parts of an information parcel contingent on the way of the assault. We can discover signatures in the IP header, transport layer header (TCP or UDP header) and application layer header or payload. Generally IDS relies on signatures to get some answers concerning gatecrasher movement. With the expanded measure of information exchanged by PC systems, the amoun t of the malevolent movement likewise increments and thusly it is important to ensure the system by security framework, for example, firewalls and the Intrusion Detection System. Example coordinating is the time discriminating operation of current Intrusion Detection System. In this venture this example coordinating is in view of the standard expression where as these example of known As saults are put away in the database of Intrusion Detection System. Customary Expressions are regularly used to portray malignant system design.
Keywords: Best-match searching, Full-text documents, Geometric parallelism, Information retrieval Nearest-neighbour searching, Parallel processing, Processor farm, Text signature Transputer network.
I. Introduction:
Late patterns in data era have created a hazardous development in the measure of advanced information to be put away and oversaw [1]. In the meantime, stockpiling administration expenses have get to be predominant – undertakings that were basic in little frameworks have turn out to be substantially more unpredictable and timeconsuming in extensive frameworks. Such undertakings include:
• File situation in layered stockpiling frameworks: Enterprise stockpiling frameworks regularly have various capacity levels with altogether different expenses and capacities. Picking which records to place in every level can be a mind boggling errand, as documents identified with the same application or venture for the most part should be put in the same level.
• Understanding usage of capacity assets: Storage
heads need to know how applications and undertakings use stockpiling limit and data transmission. This learning is vital for planning, charging, and settling on asset provisioning choices taking into account business prerequisites.
• Data union and relocation: Administrators now and
again need to relocate records and applications starting with one server then onto the next, to decommission old frameworks or to merge different servers into one.
• Data documenting: Administrators regularly need to
gets to from document follows [2]. We then group the successive examples that contain gets to comparative arrangements of records [3] to distinguish the work process document signatures, the arrangement of documents connected with a work process.
II. Problem Statement
Our objective is to consequently recognize the arrangement of documents connected with an application work process, which is a procedure or coordinated arrangement of operations adding to a final objective. For example, an activity rendering work process may execute one or all the more rendering applications to deliver a particular shot from an arrangement of representation models. We accept that a work process fulfills three properties: (an) it can happen without anyone else's input in the framework, (b) it has a tendency to reoccur after some time, and (c) every repeat includes some redundancy of work. An event of a work process is called a scene, and the arrangement of documents connected with an application work process is known as the work process record signature. Various work processes may execute in the meantime, and their document signatures may cover. Our methodology is predicated on the perception that work- streams are very repeatable. For instance, amid the generation of an energized film, the same casing may be rendered many times. Table 1 shows edge rendering insights from a business liveliness organization [4]. The table demonstrates that 40% of casings are rendered no less than 9 times, and 10% of edges are rendered no less than 37 times. These measurements propose that true work processes display extensive repeatability. We consider endeavor stockpiling frameworks that involve one or more record servers, and an arrangement of hosts that get to records on the document servers. We concentrate on dealing with the capacity at the record servers, instead of the customer machines, for a few reasons. In numerous situations, vital client records are kept just on servers that are ensured by occasional depictions, reinforcements and infection checking, while customers store just a working framework and a standard arrangement of utilization doubles. Since customer machines might immeasurably dwarf servers in expansive situations, it is simpler to instrument the servers. Besides, in a few situations, for example, generation activity rendering, it might be unreasonable to instrument the customer frameworks, as the customer assets may be completely used for figure escalated undertakings. In
our framework, record servers are NFS servers. We take note of that hints of NFS operations contain less data than the nearby machine follows utilized as a part of former work [5, 6, 7, 8, 9]. Case in point, system document server follows don't contain process rundown data (e.g., process id's, names or summon line contentions), process creation or end data, or unequivocal record lifetime data (e.g., record opens and closes). NFS follow client ID data could help work process mapping, possibly decreasing the obstruction from gets to records from different work processes. Then again, the client ID is not generally dependable for this reason. Case in point, a HTTP server may utilize a typical client ID for distinctive customers. Subsequently, Autograph does not depend on client ID data. Our objective is to concoct an apparatus that can discover work process record signatures without client intercession: clients ought not need to set countless or give indicates and other physically concentr
III. Related Work
mining algorithm to discover correlations of access to data blocks in a storage system. This information is useful for predicting which block will be accessed next, given which blocks have been accessed recently, for the purpose of prefetching, caching, and disk scheduling. In contrast, our system uses frequent sequence mining to find files related by a workflow. Griffioen and Appleton [5] also consider the problem of which files to prefetch in a file system. Their technique tries to estimate which file B has the highest probability to be opened (accessed) after a file A is opened. Then, if A is opened, the system automatically prefetches B. To estimate the probability, they create a graph where vertices are files and there is an edge from A to B if A is opened before B and at most k files were open in the meantime (where k is a system parameter). Weights on edges indicate how many times this happened. Kroeger and Long [6] address the same problem, but use a more powerful technique called Prediction by Partial Match, in which the latest k characters (a character is a file open event) are used to predict the next character. Connections [9] is a file system search tool that uses context information to improve search quality, where context refers to what files are accessed together. To establish context, Connections traces file system calls and creates a graph where vertices are files and edges indicate files accessed at nearby times. This graph is used to augment content-based search. Provenance systems [16] aim to track the lineage of files, so that users can know which files influenced the creation or modification of a given file, or to determine which files are influenced by a given file. This information is obtained by tracing system calls to determine when a process reads a first file and later creates or writes to a second file, indicating that the first file possibly influenced the second file. Doing so requires information that is not available at file servers, such as the process that invokes a system call.
IV. Architecture
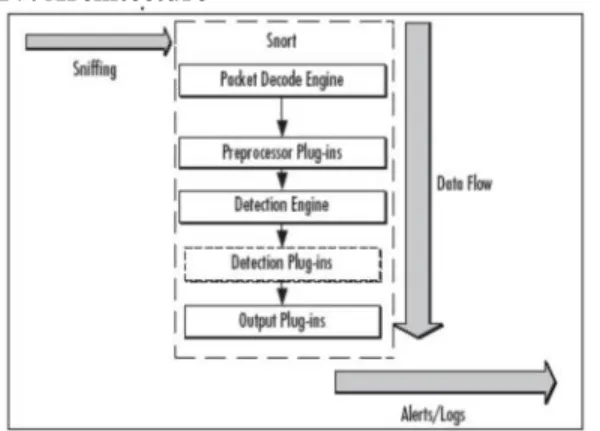
Fig. 3.1 Data flow diagram of IDS
V. Research Design
4.1 Method of Data Collection MarlyRoesch who is a developer of the Snort systems [6] defines a given network at "lightweight network intrusion detection system" when the network traffic and the packets on the IP network can be analyzed and logged in realtime. Like a network snipper who is based on the network packet collecting system library called "libpcap". Since the libpcap will be log into a database for my project and then with the help of pattern matching algorithm compare the content of the packet with the rule set present in the database. 4.2 Source of Data Collection Snort is a Free and open source NIDS. It utilizes the rule driven language to perform the pattern matching. Since the detection process of Snort is heavily depend on the rule set present in the database.
4.3 Structure of IDS Rule All IDS rules have two logical parts: rule header and rule options. This is shown in Figure 3-1.The rule header contains information about what action a rule takes. It also contains criteria for matching a rule against data packets. The options part usually contains an alert message and information about which part of the packet should be used to generate the alert message. The options part contains additional criteria for matching a rule against data packets. A rule may detect one type or multiple types of intrusion activity. Intelligent rules should be able to apply to multiple intrusion signatures.
VI Description of the Signature Files
This section describes the string search mechanism, which is based on the signature files approach. We were looking for a method with the following characteristics: 1- Small space overhead. Since many of the databases were designed to fit on a 360 Kb floppy diskette, space was at a premium. 2-Satisfactory search speed, for databases of the above size. 5 The text retrieval methods that have appeared in the literature form the following large classes: full text scanning, inversion, signature files and clustering. The first three classes are suitable for boolean queries; clustering (7) provides ways of grouping similar documents together. Clustering is suitable for the so-called "keyword searches", i.e., "find the documents that are about 'data', 'retrieval' and 'information', or as close to that as possible." Since we are interested in boolean queries, we concentrate on the first three classes.
Full text scanning
updates, but is slow on large databases unless specialized search hardware is used (8).
Inversion
This method uses an index. An entry of the index consists of a word (or stem or root) along with a list of pointers to the qualifying documents. It is probably the most popular approach in commercial systems (STAIRS (9); MEDLARS, ORBIT, LEXIS (7), etc.). The main advantage is its retrieval speed. The main disadvantages are that it may require large storage overhead for the index (50%-300% of the initial file size, according to Haskin (10)) and that insertions of new documents require expensive updates of the index. For example, if the index is organized as a B-tree, some nodes of the B-tree will eventually have to be split and rewritten when a new word is inserted. Signature file :
The documents are stored sequentially in the "text file". Their signatures (hash-code bit patterns) are stored (usually) sequentially in the "signature file". When a query arrives, the signature file is scanned and many non-qualifying documents are discarded. The text files are checked, so that the false drops are discarded. False drops (or false positives or false alarms) are documents which are initially flagged as qualifying but which do not really match the query. Note that the signature methods never introduce false negatives (or false dismissals), i.e. articles which do contain the search string, but fail the signature test. The secondary search performs full text scanning on the retrieved documents, to discard the false drops. The method is faster than full text scanning but usually slower than inversion on large databases. It requires much smaller space overhead than inversion (approximately 10-20% of the text file (11)) and can handle insertions easily.
Signature files typically use superimposed coding to create the signature of a document. A brief description of the method follows; more details are in (12). For performance reasons that will be explained later, each document (in the case of Hyperties each article) is divided into "logical blocks", that is, pieces of text that contain a constant number D of distinct, non common words. Each such word yields a "word signature", which is a bit pattern of size F, with m bits set to "1" while the rest are "0" (see Figure 3.1). F and m are design parameters.
The word signatures are ORed together to form the block signature. Block signatures are concatenated, to form the document signature. The m bit positions to be set to "1" by each word are determined by hash functions. Using successive, overlapping triplets as hashing elements, queries on parts of words can be handled easily
Word Signature Free 001 000 110 010 text000 010 101 001 Block
signature001 010 111 011
VII. Evaluation Methodology
Our goal in evaluating our system is to determine how effective it is at differentiating the files in each workflow. To quantify the accuracy of results, we use metrics borrowed from information retrieval systems (Section 4.1). We compare Autograph with a simple existing method based on temporal locality graphs (Section 4.2).
4.1 Evaluation metrics
To evaluate accuracy of Autograph, we use the traditional information retrieval metrics of recall and precision [13]. These metrics measure how different the output of Autograph is compared to ground truth
(i.e., the “right” answer). Ground truth is given by a
set of workflows {W Fi}; we use W Fi to denote both the i-th workflow and its file signature. Autograph outputs a set of clusters {Cj}, where each cluster approximates the set of files of a workflow. Clusters need not be disjoint (unlike in traditional clustering) because the workflows themselves may have shared files. Recall (|W Fi∩ Cj |/|W Fi|) is a measure of the
completeness of retrieval, and a perfect score of 1 means that all files in W Fi are also in Cj . Precision (|W Fi∩Cj |/|Cj |) is a measure of the exactness of
retrieval, and a perfect score of 1 means that every
file in Cj belongs to W Fi. We define each “ground truth” set W Fi in two steps: (1) a human expert chooses a set Vi of files associated with the workflow, and (2) we define W Fi to be Vi intersected with the set of files that actually appear in the trace. Intuitively, the second step removes files that cannot be found by any trace-based algorithm.
For example, there may be a “readme.txt” file that is
part of the source code of a program, but which is never read by the compilation process. In Section 5 we briefly evaluate how many such files there are in real workflows.
4.2 Comparison point
temporal locality graph by itself does not indicate the files in each workflow. To do so, we run a post-processing algorithm on the graph that drops edges below a threshold and then computes the connected components of the graph. The final output is a set of clusters, where each cluster consists of all files in a connected component of the graph.
VIII. Conclusions
Automatically identifying and grouping files that are related to the same workflow is important for improving the usefulness and efficiency of management tasks like reporting, file placement, migration, and archiving. We presented Autograph, a system tool that automatically extracts workflow file signatures by examining traces of file accesses, finding repeated and correlated accesses, and inferring files that likely belong to the same workflow. Autograph leverages several techniques from the data mining community, including frequent set mining and clustering using frequent itemsets. Our approach relies only on network file system traces, meaning that it can be deployed at file servers, which may be easier than client-based tracing in large or production environments.
We evaluated Autograph using NFS traces of real workflows and found that workflows are repeatable, in that they access a similar set of files across different episodes. Leveraging this repeatability, Autograph successfully distinguishes between multiple concurrent workflows and between workflows that access overlapping sets of files. It outperforms an alternative approach based on temporal locality graphs, because it tracks more than just pairwise relationships, and because it permits files to be included in multiple clusters, if appropriate. Autograph can be tuned to provide high recall or high precision, to meet the needs of the usage scenario. We describe rules of thumb for
setting Autograph’s configuration parameters to
achieve these results. IX. References
[1] K. Ko and T. Robertazzi, “Signature search time evaluation in flat file databases,” Aerospace and
Electronic Systems, IEEE Transactions on, vol. 44, no. 2, pp. 493–502, 2008.
[2] Y. Kyong and T. G. Robertazzi, “Greedy
signature processing with arbitrary location distributions: A divisible load,” IEEE Transactions
on Aerospace and Electronic Systems, vol. 48, no. 4, 2012.
[3] R. Baeza-Yates, “Algorithms for string searching,” in AcMsIGIR Forum, vol. 23, no. 3-4. ACM, 1989, pp. 34–58.
[4] G. Navarro, “A guided tour to approximate string
matching,” ACM computing surveys (CSUR), vol.
33, no. 1, pp. 31–88, 2001.
[5] P. Michailidis and K. Margaritis, “String
matching algorithms: Survey and experimental
results,” in International Journal of Computer
Mathematics, vol. 76, 2000, pp. 411–434.
[6] Z. Galil and R. Giancarlo, “Data structures and algorithms for approximate string matching,” Journal
of Complexity, vol. 4, no. 1, pp. 33–72, 1988. [7] H. Kitakami, T. Shin-I, K. Ikeo, Y. Ugawa, N.
Saitou, T. Gojobori, and Y. Tateno, “Yamato and
asuka: Dna database management system,” in System
Sciences, 1995. Vol. V. Proceedings of the TwentyEighth Hawaii International Conference on, vol. 5. IEEE, 1995, pp. 72–80.
[8] M. Hoffman and D. Carver, “Reverse engineering data requirements,” in Aerospace Applications Conference, 1996.Proceedings., 1996 IEEE, vol. 2. IEEE, 1996, pp. 269–277.
[9] M. Lubeck, D. Geppert, and K. Nienartowicz,
“An overview of a large-scale data migration,” in
Mass Storage Systems and Technologies, 2003.(MSST 2003).
Guides:
N.SRINADH REDDY,
Assoc.Prof, Departmentof C.S.E, Visvodaya Engineering College, Kavali.