ONE PASS INCREMENTAL
ASSOCIATION RULE DETECTION
ALGORITHM FOR NETWORK
INTRUSION DETECTION SYSTEM
VIJAY KATKAR
Depart of Computer Engineering, Bharti Vidyapith, Pune, Maharashtra, India
REJO MATHEW
Depart of Information Technology, NMIMS University, Mumbai, Maharashtra, India
Abstract :
Association rule mining is widely used to discover malicious activities by analyzing network traffic data. Apriori algorithm is the most popular association rule mining algorithms, but it has major deficiencies like, requires multiple scan of database, generates large number of frequent item sets repeatedly. This paper presents One Pass Incremental Association Rule Detection algorithm for Network Intrusion Detection System (NIDS). Experimental results are provided to support effectiveness and efficiency of proposed algorithm.
Keywords: Incremental mining, Association rule discovery, Intrusion Detection system, Feature selection
1. Introduction
Almost every organization stores and manipulates their sensitive information on network. Thus, Intrusion Detection Systems (IDSs) are widely used to protect these networks from intruders. In recent years, data mining is used as important component in IDSs. The motivation behind designing IDS using data mining is automation. Patterns of the normal network users and intruders discovered using data mining can be used to detect Intrusive activities. To use data mining for intrusion detection, data collected from network must be preprocessed and converted into the suitable format for mining. Various data mining techniques like classification, clustering, association rule can be used to analyze network data and discover intrusion patterns.
The Association rule mining [1, 2] is used to discover hidden associations in database. It scans the complete database to find large item sets (Patterns) those appear frequently in network data. These large item sets are then used to generate Association rules to identify intrusive behavior. These rules are probabilistic in nature and provide information using "If-Then" statements. (e.g X=>Y; If ‘X’ Then ‘Y’) These rules use two numbers which express the degree of uncertainty of each rule. The first number is support and second is confidence of the rule. Support is the number of transactions that include “If” part (i.e. ‘X’) of the Association rule and Confidence is the ratio of the number of transactions which include both “IF” and “Then” part (i.e. ‘Y’) of rule to the number of transactions that include “If” part of the rule.
In real world data is growing continuously. This new data can give birth to some new association rules which are not known currently and makes some old association rules useless. Thus, updating association rules with newly generated data is important. A simple approach to solve this problem is; reapply association rule mining algorithm to the entire database, but this is time, recourses consuming and impractical for large databases. Mining association rule from continuously growing databases is more complicated compared to mining association rules from static databases. Incremental association rule mining algorithm must verify whether the old large item sets remained large after addition of new transactions in the database and detect new large item sets.
Section 3 presents brief review of Network data feature selection for Data Mining based IDSs. Section 4 describes proposed algorithm and section 5 presents experimental results to support the proposed algorithm. Section 6 compares the proposed algorithm with other association rule detection algorithms and section 7 concludes the paper.
2. Association Rule Mining For Intrusion Detection
If constant value is used as Support parameter to discover frequent pattern using Apriori algorithm, it will generate large number of intrusive patters and most of them will have less number of network traffic features. Such patterns are not suitable to detect Intrusions with high accuracy. Lei Li et al [3] argued that, patterns which contains less number of features should be considered as interesting if they have a high support and patterns which contains large number of features should be considered as interesting even if they have small Support value. They proposed a concept of length-decreasing Support constant which allows discovery of long intrusive patterns with low support as well as short patters with high support. This algorithm increases the accuracy of Intrusion Detection mechanism but it still requires many iterations of Database to detect useful patterns.
Wang Taihua and Guo Fan [4] proposed non-iterative improved Apriori algorithm to discover IDS alerts. They used intersection of two distinct rows of network traffic database (DARPA 99) to detect recurring patterns. If same pattern is recurring in many intersection operations, then it is considered as interesting pattern and used as IDS alert. It requires only one scan of the database but the complexity of algorithm is O (nlog2 n), where ‘n’ is number of records in the database and thus processing time required is too high.
Zhang yanyan and Yao Yuan [5] presented partition-based association rule detection algorithm for IDS rule generation. During first scan of database they partitioned training database in such a way that each partition of database can be entirely copied into a main memory of processing device. Then Large Item sets for each partition are identified independently. The union of these large item sets is then used as candidate large item sets for complete database. During second scan of the database, large item sets for complete database are identified. This algorithm cannot be efficiently converted into incremental association rule detection algorithm and time complexity of it is very high.
Ming-Yang Su et al [6] proposed incremental fuzzy association rules mining algorithm for Network Intrusion Detection System. They used link list of link list to store all possible candidate item sets and their support count in main memory. This information is updated periodically using network traffic data collected. Updated information is then used by incremental algorithm to identify large and interesting item sets, which are used as rules for NIDS. The major drawback of this algorithm is huge main memory requirement to sore all candidate item sets of every size. Instead of database this algorithm scans link list of possible large item sets repeatedly to identify large item sets.
Ratchadaporn Amornchewin and Worapoj Kreesuradej [7] proposed Probability-based incremental association rule discovery algorithm. They divided the algorithm into three steps:
(1) Update support count of existing frequent item sets.
(2) Remove existing frequent item sets whose support count is below minimum support threshold. (3) Identify new frequent item sets whose support count is above a minimum support threshold
Limitations of this algorithm are; they assume that, statistics of newly inserted records are slightly different from old database records and maximum number of new records that can be inserted into database is known in advance. If any of the assumption fails then this algorithm will not work properly.
3. Selecting Features For Intrusion Detection
Before applying Data mining algorithms, raw network traffic data must be transformed into records containing number of network traffic features such as service, duration, protocol and so on. Identification of important network traffic features for intrusion detection is very crucial step and determines the success of Data mining algorithm. Proper feature selection results in simplified, faster and more accurate Intrusion Detection process. Adetunmbi A.Olusola et al [8] performed experiments on KDD 99 dataset. They proved that two network traffic features, ‘outbound command count for FTP session’ and ‘hot login’ have no relevance in Intrusion Detection. Features namely ‘number of compromised conditions’, ‘su attempted’, ‘number of file creation operations’, ‘is guest login’, and ‘dst host error rate’ are of little significance for Intrusion Detection process. If these features are eliminate while applying data mining algorithm, it will increase speed of Data mining algorithm and reduce the resource requirements without affecting the accuracy.
performed experiments using KDD 99 data set and showed that number of features required for detecting DoS attack can be reduced to 7 features. The reduction in number of attributes results in 83% reduction of input data and approximately 90% reduction in mean squared error of detecting novel attacks. It significantly reduced memory and CPU time required to detect attacks.
H. Güneş Kayacık et al [10] performed experiments on KDD 99 data set and expressed the Feature relevance in terms of information gain. Their results showed that normal, neptune and smurf attacks are highly related to certain features. If only these are used to detect those attacks, it makes attack detection task easier and provides good results.
Wei Wang et al [11] performed experiments on KDD 99 dataset and showed that, even though only 10 relevant features with highest information gain are used for attack detection instead all 41 features then also we can achieve same or improved detection rate.
4. Proposed Algorithm
As discussed in section 3, we can achieve good detection rate with less number of relevant network traffic features. Thus, proposed algorithm uses only 10 relevant features to detect DoS attacks. These are dst_bytes, src_bytes, service, flag, Count, srv_count, srv_diff_host_rate, src_bytes,dst_bytes, hot, num_compromised, Wrong_fragment. These features are most relevant for detecting DoS attack. If we want to use all 10 features to discover association rules, then we should find frequent item sets of size-10. If we know that we have to find frequent item sets of size 10 then instead of starting the process from large item sets of size-1 and end with large item sets with size-10. We can directly find large item sets of size-10 using algorithm described below.
Nested Hash Table structure is used for Association rule detection. Key for outer Hash Table is concatenation of values of all 10 features described above. This key is a ‘Pattern’ present in network traffic database. Data part of the outer Hash Table contains a structure described below.
Structure Association {
Integer Count;
HashTable AttackType;
}
Integer variable ‘Count’ is used to hold the frequency of particular Pattern of selected features (i.e. occurrences of X). It is possible that single pattern can belong to more than one attacks. Thus Inner HashTable is used to keep track of possible attacks which can follow that pattern. Key used for inner Hash Table is ‘Attack type’ field of database record. Data part of Inner Hash Table contains one Integer variable ‘AttackTypeCount’. This is used to count number of occurrences in database for particular attack type with Pattern of outer HashTable key (i.e. Occurances of X and Y).
Input: Network Traffic Database Output: Association Rules Steps:
(1) For every record in Database
(i) ‘OuterHashKey’ = Concatenation of values of 10 selected features from Database (ii) If entry for OuterHashKey is present in Outer HashTable Then
i. Increment Pattern Counter (Association.Count) by one Else
i. Create entry for Outer Hash key in outer Hash Table ii. Initialize Pattern Counter '(Association.Count) to one (iii)‘InnerHashKey’ = Value of Attack Type field of that record (iv)If entry for InnerHashKey is present in Inner Hash Table Then
i. Increment Association.AttackType.Atta-ckTypeCounter by one (v) Else
i. Create an entry for Attack Type in Inner Hash
ii. Initialize Association.AttackType.Atta-ckTypeCounter to one (2) For Every Entry in Outer Hash Table
i. Confidence = Association.AttackType.Atta-ckTypeCounter/ Association.Count ii. If (Confidence and Support are above Threshold)
1. Generate Association rule Incremental Association rule generation Process
Maintain a copy of Hash Table created using algorithm described above either in main memory or serialize it in Hard disk. After new records are added to the database, retrieve stored copy of Hash Table and use it to follow algorithm described above. But this time apply this algorithm only on newly added records and we will get new Association rules.
5. Experimental Results
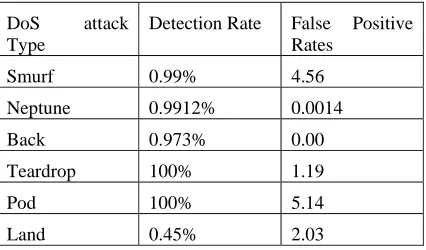
Experiment is performed on laptop with Intel Core 2 Duo CPU T5470 @ 1.60 GHz and 1 MB Ram. Operating system installed was Windows server 2003. Algorithm was implemented using Java language. KDD 99 dataset is used to perform experimental tests. KDD 10% training data is used for finding Association rules to detect DoS attacks. Then KDD test data with corrected labels is used to test the accuracy of generated Association rules. Experimental result obtained is presented in table 1.
Table 1. Experimental Result
DoS attack Type
Detection Rate False Positive Rates
Smurf 0.99% 4.56 Neptune 0.9912% 0.0014
Back 0.973% 0.00
Teardrop 100% 1.19
Pod 100% 5.14
Land 0.45% 2.03
As shown in the table, detection rate achieved using Association rules generated by proposed algorithm is very high. False positive rate for Smurf and Pod is bit higher, thus some work should be done to improve it,
6. Comparison With Other Algorithms
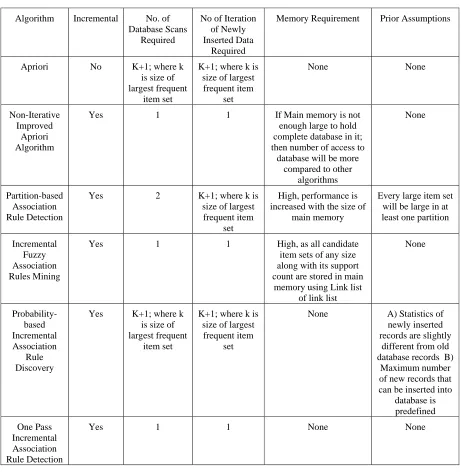
Comparison of proposed algorithm with other algorithms is summarized in Table 2. Number of Large item-sets generated by proposed algorithm is much lesser compared to large item-sets generated by Non-Iterative Improved Apriori Algorithm and Incremental Fuzzy Association Rules Mining algorithm. Many large item sets generated by [4, 6] contains less number of features. For IDS large item sets with less number of features are almost of no use, thus many large item sets generated by these two algorithm degrades the performance as argued by [8, 9, 10,11].
7. Conclusion
Table 2. Comparision Of Proposed Algorithm With Other Algorithms
Algorithm Incremental No. of Database Scans
Required
No of Iteration of Newly Inserted Data
Required
Memory Requirement Prior Assumptions
Apriori No K+1; where k
is size of largest frequent
item set
K+1; where k is size of largest
frequent item set None None Non-Iterative Improved Apriori Algorithm
Yes 1 1 If Main memory is not
enough large to hold complete database in it; then number of access to
database will be more compared to other
algorithms
None
Partition-based Association Rule Detection
Yes 2 K+1; where k is
size of largest frequent item
set
High, performance is increased with the size of
main memory
Every large item set will be large in at least one partition
Incremental Fuzzy Association Rules Mining
Yes 1 1 High, as all candidate
item sets of any size along with its support count are stored in main
memory using Link list of link list
None Probability-based Incremental Association Rule Discovery
Yes K+1; where k is size of
largest frequent item set
K+1; where k is size of largest
frequent item set
None A) Statistics of newly inserted records are slightly
different from old database records B)
Maximum number of new records that can be inserted into
database is predefined One Pass Incremental Association Rule Detection
Yes 1 1 None None
References
[1] Piatetsky-Shapiro, Gregory, “Discovery, analysis, and presentation of strong rules”, Knowledge Discovery in Databases, AAAI/MIT Press, Cambridge, MA, 1991
[2] Rakesh Agarwal, Tomasz Imielinski, Arun Swami, “Mining Association Rules Between Sets of Items in Large Databases”, Proceedings of the 1993 ACM SIGMOD Conference, Washington DC, USA, May 1993
[3] Lei Li, De-Zhang Yang, Fang-Cheng Shen, “A Novel Rule-based Intrusion Detection System Using Data Mining”, 978-1-4244-5540-9/10, IEEE 2010, pp. 169 - 172
[4] Wang Taihua, Guo Fan, “Associating IDS Alerts by an Improved Apriori Algorithm”, Third International Symposium on Intelligent Information Technology and Security Informatics, 978-0-7695-4020-7/10, 2010 IEEE, pp. 478 - 482
[5] Zhang yanyan,Yao Yuan, “Study of Database Intrusion Detection Based on Improved Association Rule Agorithm”,978-1-4244-5540-9/10, 2010 IEEE, pp. 673 - 676
[6] Ming-Yang Su, Kai-Chi Chang, Hua-Fu Wei, Chun-Yuen Lin, “A Real-time Network Intrusion Detection System Based on
Incremental Mining Approach”, 1-4244-2415-3/08, 2008 IEEE, pp. 179 - 184
[8] Adetunmbi A. Olusola, Adeola S. Oladele, Daramola O.Abosede, “Analysis of KDD ’99 Intrusion Detection Dataset for Selection of Relevance Features”, Proceedings of the World Congress on Engineering and Computer Science 2010 Vol I, IEEE 2010
[9] Neveen I. Ghali, “Feature Selection for Effective Anomaly-Based Intrusion Detection”, International Journal of Computer Science and Network Security, VOL.9 No.3, March 2009, pp. 285-289
[10] H. Güneş Kayacık, A. Nur Zincir-Heywood, Malcolm I. Heywood, “Selecting Features for Intrusion Detection: A Feature Relevance Analysis on KDD 99 Intrusion Detection Datasets”, Proceedings of the Third Annual Conference on Privacy, Security and Trust, October 2005, St. Andrews, Canada