MASSIVE DATA MINING (MDM) ON
DATA STREAMS USING
CLASSIFICATION ALGORITHMS
PROF.DR. P. K. SRIMANI*
Formar Director, R&D Division, Bangalore University, Dayananad Sagar Institutions, Bangalore, Karnataka, India,
MRS. MALINI M PATIL**
Assistant professor, Dept. of ISE
J.S.S. Academy of Technical Education, Bangalore, Karnataka, India Research Scholar, Bhartiyaar University,
Coimbatore, Tamilnadu, India, [email protected]
Abstract:
Data sets which continuously and rapidly grow over time are referred to as data streams. Few examples include network monitoring, sensor data, browsing world wide web, usage of credit cards. The advances in information technology have lead the large flows of data across IP networks. Mining of such data streams is referred to as massive data mining. Traditional data mining techniques are not suitable for mining data streams. In a data stream model the data arrive at a very high speed and the algorithm must process the data stream under very strict constraints of space and time. The data streams are massive in nature. Data streams can be mined only using sophisticated techniques. Massive Online Analysis (MOA) is a frame work used to mine data streams. The paper aims at comparing the classification algorithms on SEA data stream. Data stream classification is perhaps one of the important techniques which is most widely studied in the context of data stream mining methods.
Keywords: Data Mining, Data Streams, Massive data mining, Classification, Prequential, Heldout, Accuracy.
1. Introduction
Today’s era of technology has resulted in the massive increase of data generation. Data generation has become an automated process. This is mainly because of different mobile applications, sensor applications, measurements in network traffic monitoring and management, log records and click streams in search engines, web logs, emails, blogs, twitter posts etc. This kind of data generated can be considered as a streaming data since it is obtained from an interval of time. Thus a data stream is defined as an ordered sequence of items that arrive in timely order[Agarwal, 2007]. Data streams are different from data in traditional databases. They are continuous, unbounded, usually come in high speed and have a data distribution which often changes with time [Guha, 2000].
evolution of different techniques in the area of DM. New research findings resulted in new issues in each technique. To quote some; Association rule mining, Classification, Clustering. etc.
1.1 Data Stream Phenomenon
A data stream is a “Sequence of digitally encoded signals used to represent information in transmission”. To be more specific, data stream represents the input data that comes at a very high rate. There is a heavy stress on communication and computing infrastructure and hence it may be difficult to :
• transmit (T) the entire input to the program,
• compute (C) sophisticated functions on large pieces of the input at the rate it is presented, and
• store (S), capture temporarily or archive all
This structure of transmitting, computing and storing is referred as TCS infrastructure. There are two recent developments that have confluence to produce new challenges to the TCS infrastructure.viz.,
1. Ability to generate automatic, highly detailed data feeds comprising continuous updates. 2.Need to do sophisticated analyses of update streams in near-real time manner.
1.2 Massive Data Mining(MDM)
Mining a stream data is referred as data stream mining or Massive Data Mining (MDM). It is relatively a new field. Few important features of data streams are 1) huge in size. 2) continuous in nature. 3) fast changing and require fast response 4) Random access of data is not possible 5) storage of data streams is limited, only the summary of the data can be stored. 5) Mining such data needs sophisticated techniques.
Data streams can be classified into static(offline) streams and evolving (online) streams. Static streams are characterized by regular bulk arrivals. For example, web logs. Web logs are considered as Static data streams because most of the reports are generated in a certain period of time. Another best example of Static (offline) data streams is queries on data warehouses. Evolving data streams [Guha, 2000] are characterized by real time updated data that come one by one in time. Examples for evolving (online) data streams are, frequency estimation of internet packet streams, stock market data, and sensor data. Such data should be processed online. Another very important feature of online data streams is that they should be processed online with the rapid speed with which they arrive and should be discarded immediately after being processed. Yet another important feature is bulk data processing is not possible in evolving data streams where as it is possible in static data streams.
Tremendous and potentially infinite volumes of data streams are often generated by real-time surveillance systems, communication networks, Internet traffic, on-line transactions in the financial market or retail industry, electric power grids, industry production processes, scientific and engineering experiments, remote sensors, and other dynamic environments. Unlike traditional data sets, stream data flow in and out of a computer system continuously and with varying update rates. They are temporally ordered, fast changing, massive, and potentially infinite. It may be impossible to store an entire data stream or to scan through it multiple times due to its tremendous volume. Moreover, stream data tend to be of a rather low level of abstraction, whereas most analysts are interested in relatively high-level dynamic changes, such as trends and deviations. To discover knowledge or patterns from data streams, it is necessary to develop single-scan, on-line, multilevel, multidimensional stream processing and analysis methods. Such single-scan, on-line data analysis methodology should not be confined to only stream data. It is also critically important for processing non-stream data that are massive.
1.3 Methodologies for Massive Data Mining
The paper is organised as follows: Section 2 mainly discusses on the need and importance of the problem; Section 3 about the related work; Section 4 discusses about methodology; Experiments and results are presented in Section 5; Finally section 6 is about conclusions and future work.
2. Need and importance of the problem
The following important challenges presented below give the details pertaining to need and importance of the problem:
High speed Nature of data streams: High speed is one of the inherent characteristic of data streams. The algorithm developed must be capable of handling the high speed. The rate of building the data stream model must be faster than the data rate.
Unbounded Memory requirements: The classification technique needs that the data to be resided in the memory for building the model. The huge amounts of data streams generated needs unbounded memory.
Concept drifting : In the real world concepts are often not stable but change with time. Example include weather forecasting, credit card data etc. The data distribution will also change as well. Often these changes make the model built on old data inconsistent with the new data and regular updating of the model is necessary. This problem is known as concept drift. This complicates the task of learning a model from data and requires special sophisticated approaches.
Tradeoff between accuracy and efficiency: The main trade off in data stream mining algorithms is between the accuracy of the output with regard to the application and the time and space complexities. Sophisticated methods are essential to handle such tradesoffs.
Challenges in Distributed applications: A significant number of data stream applications run in mobile environments with limited bandwidth such as sensor networks and handheld devices. Thus knowledge structure representation is an important issue.
Visualization of Data stream mining results: Though visualization of traditional data mining results on a desktop has been a research issue for more than a decade. Visualization of data stream mining results also is equally challenging.
Modeling change of mining results over time : In some cases the user is not interested in mining data steam results, but is interested in knowing how these results are changing over a temporal basis. The classification changes could help in understanding the change in data streams.
Interactive mining environment to satisfy user results: Mining data streams is a highly application oriented field. For example. The User should be able to change the classification parameters to serve the special needs of the user under the current context. The fast nature of data streams often makes it more difficult to incorporate user interaction.
Integration of data stream management systems and data stream mining approaches: The integration among storage, querying, mining and reasoning of the incoming stream would realize robust streaming systems that could be used in different applications.
Technological issues : The technological issues of mining data streams is an important challenge.viz., How to represent the data in such an environment in a compressed way; Which platforms are best suited; What type of hardware is suitable; and How to handle the complex computations.
3. Related work
repository consisting of data related to technical educational systems. It has earned lot of scope in educational research. Edu-mining is carried out on all the three stake holders of TES. The results of the exhaustive research work [Srimani and Malini , 2012a,b] are highly effective in taking optimal decisions at the managerial level. Edu-data is evolved because of huge collection of data mainly from WWW, study material available in the internet, e-learning schemes, computerization of education systems, online registration schemes for admission process in the universities, student information system, examination evaluation systems etc. A model was proposed [Srimani and Malini, 2010] for the first time, using for medical data stream which is a static stream, with regard to Super Speciality Health Care Unit(SSHCU). The method of approach constitutes land mark window model and K-means clustering technique.[Bifet and Krenan, 2010] have presented a framework for stream classification and clustering on the basis of Massive Online Analysis. A comparative study of DM and MDM [Srimani and Malini, 2012] is proposed. The work mainly compares the traditional DM techniques and data stream mining technique. But no work with regard to the massive online analysis is available. Therefore, the present work is carried out to throw light on the qualitative as well as the quantitative aspects of the problem.
4. Methodology
This section mainly discusses the different steps of Data Mining (DM) and Massive Data Mining(MDM). It is a well known fact that data mining is an integral part of knowledge discovery in databases, which is the overall process of converting raw data into useful information. The process of knowledge discovery in databases consists of several steps as shown in fig 1.
Fig. 1. Phases of Knowledge Discovery Process
4.1 Data Mining(DM)
Knowledge Discovery in Databases, frequently abbreviated as KDD, typically encompasses more than data mining. The knowledge discovery process comprises of six phases:
Data selection, Data cleansing, Data Enrichment,
Data transformation or encoding, Data mining, &
The reporting & display of the discovered information.
4.2 Massive Data Mining (MDM)
Massive data mining is performed using Massive online analysis (MOA) framework [Bifet and Krenan, 2010]. It is a software environment for implementing algorithms and running experiments for online learning from evolving data streams. MOA is designed in such a way that it can handle the challenging problem of scaling up the implementation of state of the art algorithms to real world data sets. It consists of offline and online algorithms for classification and clustering. It also consists of tools for evaluation. Thus MOA is an open source frame work to handle massive, potentially infinite, evolving data streams. MOA mainly permits the evaluation of data stream learning algorithms on large streams under explicit memory limits. The method MDM mainly consists of the following steps.
Step1 : Select the task Step2: Select the learner
Step3 : Select the stream generator Step4 : select the evaluator
The model is configured with the above said steps. And results are noted.
4.2.1 Evaluation process in MOA
There are two options in the case of the evaluation process of MOA.Viz., Holdout and Prequential.
The first case is suitable when the division between train and test sets is predefined so that the results from different studies could be directly compared.
In the second case each individual example can be used to test the model before it is used for training and accordingly the accuracy can be incrementally updated.
4.2.2 A Classification model in MOA.
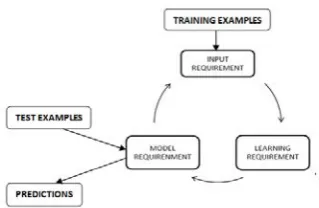
The classification model in MOA is based on the four basic requirements of MDM. A data stream environment has different requirements from the traditional batch learning setting. The model is shown in fig 2. The main requirements in mining data streams are summarized as follows:
The example has to be processed at a time, and inspected only once. Limited amount of memory can be used.
Work in a limited amount of time and Prediction can be made any time
Fig. 2. A Classification model in MOA
4.2.3 Data stream generator in MOA
There is a shortage of bench mark data sets for data stream classification. Our method uses SEA generator which is one of the popular generator available in MOA framework. SEA generator was proposed by [Street and Kim, 2001]. The data set has two decision classes with sudden concept drift. It is generated using three attributes, where only the two first attributes are relevant. All three attributes have values between 0 and 10. The points of the data set are divided into 4 blocks with different concepts. In each block, the classification is done using f1+f2 ≤Ɵ where f1 and f2 represents the first two attributes and Ɵ is a threshold value. For our experiments
a data stream of 10,000,000 instances with varying noise percentages (8%,10%,15% and 20%) are generated.
4.2.4 Algorithms used in the analysis
Naïve Bayes(NB)
Performs classic Bayesian prediction while making naive assumption that all inputs are independent. Naïve Bayes is a classifier algorithm known for its simplicity and low computational cost. Given nCdifferent classes, the trained Naïve Bayes classifier predicts for every unlabelled instance I the class C to which it belongs with high accuracy. The model works as follows: Let x1,. . . , xkbe k discrete attributes, and assume that xican take ni different values. Let C be the class attribute, which can take nCdifferent values. Upon receiving an unlabelled instance I = (x1 = v1, . . . , xk= vk), the Naïve Bayes classifier computes a “probability” of I being in class c as:
The values Pr[xi= vj ^C = c] and Pr[C = c] are estimated from the training data. Thus, the summary of the training data is simply a 3-dimensional table that stores for each triple (xi , vj, c) a count Ni, j,c of training instances with xi= vj, together with a 1-dimensional table for the counts of C = c. This algorithm is naturally incremental: upon receiving a new example (or a batch of new examples), simply increment the relevant counts. Predictions can be made at any time from the current counts.
NaiveBayesMultinomial(NBMN)
Multinomial Naive Bayes classifier. Performs text classic Bayesian prediction while making naive assumption that all inputs are independent. The core equation for this classifier:
where Ciis class i and D is a document.
5. Results and Discussions.
The results of the present investigation are presented in table 1.
The MOA is carried on the Data stream "Sea generator " consisting of 10,000,000 data instances. The classifiers used are Naive Bayes and Naive Bayes multinomial.
The methodology constitutes the evaluation procedures. viz., Prequential and held out methods
For each algorithm two classification performance evaluators are chosen.viz., Basic Classification Performance Evaluator(BCPE) and Window Classification Performance Evaluator.
The results were computed for four different values of noise percenatge.Viz.,8%,10%,15% and 20%.
The following Observations are made
1. For (noise % ) n = 8, it is found that the NBMN and NB perform equally well in the case of BCPE with ACC: 89.74%, 89.82%,89.71% respectively.
2. For (noise % ) n = 10, it is found that NB performs better than NBMN in the case of WCPE with ACC: 89.14%, 88.12% respectively.
3. For (noise % ) n = 15, it is found that NBMN and NB perform equally well in the case of BCPE with ACC: 83.99%, 83.98%, 88.91% respectively.
Further it's interesting to note that the behavior of MDM in the case of varying n is quite informative. In the sense that performance of heldout method is really amazing for WCPE in which case
classification accuracy happens to be 89.82%.
From this it can be concluded that NB is the best classifier among the two for the case of held out with n = 8%.
It is also observed that the increase in noise ratio decreases the accuracy and vise versa.
In
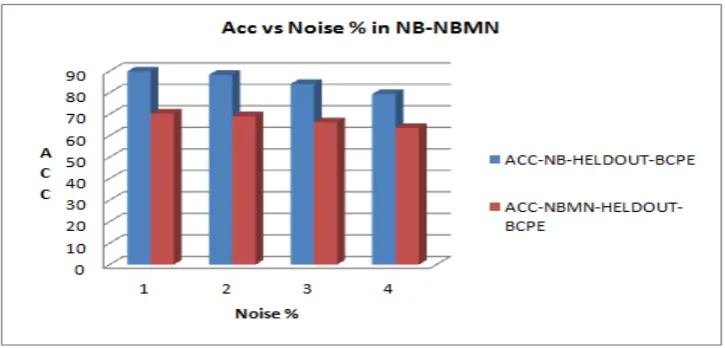
fig 3, the results of the present investigation predicting the accuracy of different classifiers and evaluators are presented graphically. The figure is self explanatoryFig 3(a). Graph of Acc vs. Noise% in PRE-BCPE
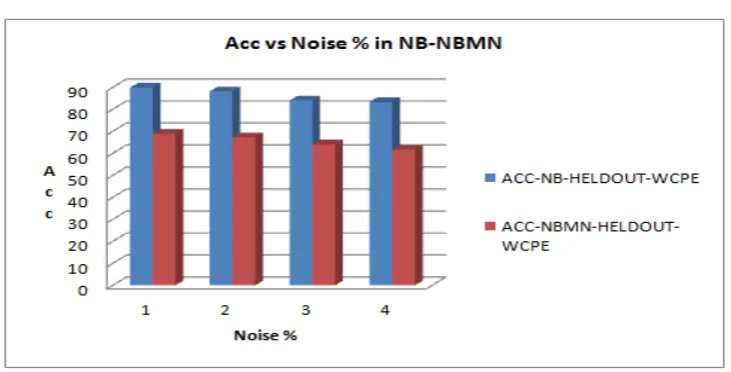
Fig. 3(c) Graph of Acc vs. Noise% in PRE-WCPE
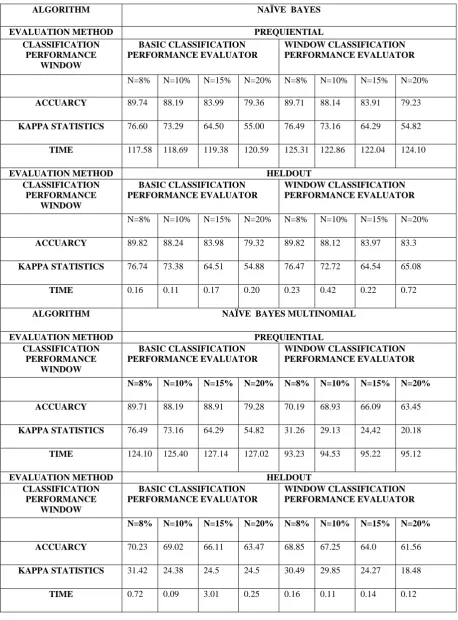
Table 1 . The Results of MDM Analysis
ALGORITHM NAÏVE BAYES
EVALUATION METHOD PREQUIENTIAL CLASSIFICATION
PERFORMANCE WINDOW
BASIC CLASSIFICATION PERFORMANCE EVALUATOR
WINDOW CLASSIFICATION PERFORMANCE EVALUATOR
N=8% N=10% N=15% N=20% N=8% N=10% N=15% N=20%
ACCUARCY 89.74 88.19 83.99 79.36 89.71 88.14 83.91 79.23
KAPPA STATISTICS 76.60 73.29 64.50 55.00 76.49 73.16 64.29 54.82
TIME 117.58 118.69 119.38 120.59 125.31 122.86 122.04 124.10
EVALUATION METHOD HELDOUT
CLASSIFICATION PERFORMANCE
WINDOW
BASIC CLASSIFICATION PERFORMANCE EVALUATOR
WINDOW CLASSIFICATION PERFORMANCE EVALUATOR
N=8% N=10% N=15% N=20% N=8% N=10% N=15% N=20%
ACCUARCY 89.82 88.24 83.98 79.32 89.82 88.12 83.97 83.3
KAPPA STATISTICS 76.74 73.38 64.51 54.88 76.47 72.72 64.54 65.08
TIME 0.16 0.11 0.17 0.20 0.23 0.42 0.22 0.72
ALGORITHM NAÏVE BAYES MULTINOMIAL
EVALUATION METHOD PREQUIENTIAL CLASSIFICATION
PERFORMANCE WINDOW
BASIC CLASSIFICATION PERFORMANCE EVALUATOR
WINDOW CLASSIFICATION PERFORMANCE EVALUATOR
N=8% N=10% N=15% N=20% N=8% N=10% N=15% N=20%
ACCUARCY 89.71 88.19 88.91 79.28 70.19 68.93 66.09 63.45
KAPPA STATISTICS 76.49 73.16 64.29 54.82 31.26 29.13 24,42 20.18
TIME 124.10 125.40 127.14 127.02 93.23 94.53 95.22 95.12
EVALUATION METHOD HELDOUT
CLASSIFICATION PERFORMANCE
WINDOW
BASIC CLASSIFICATION PERFORMANCE EVALUATOR
WINDOW CLASSIFICATION PERFORMANCE EVALUATOR
N=8% N=10% N=15% N=20% N=8% N=10% N=15% N=20%
ACCUARCY 70.23 69.02 66.11 63.47 68.85 67.25 64.0 61.56
KAPPA STATISTICS 31.42 24.38 24.5 24.5 30.49 29.85 24.27 18.48
6. Conclusions and Future Work
The present work focuses on the comparative study of classifiers of MDM techniques. In the case of sea data stream the number of instances are 10,000,000. In the first case 2 classifiers are considered and the analysis is carried out in great detail. The final results are presented for ready reference. In this case the learning model is evaluated by using two evaluation methods Viz. prequential and heldout methods respectively. Of the two methods it is found that Naïve Bayes performs better with WCPE with Accuracy 89.82% in the case of held out method. The results of the present study provide a strong platform for enhancing the accuracy of the method effectively. Further, it is concluded that for massive data MDM technique is best suited and it has lot of scope for future research.
Acknowledgements
One of the authors Mrs. Malini M Patil acknowledges J.S.S Academy of Technical Education, Bangalore, Karnataka and Bhartiyaar University, Coimbatore, Tamilnadu, India for providing the facilities for carrying out the research work.
References
[1] C. Aggarwal, Book(2007): "Data streams: Models and Algorithms", Charu Aggarwal Ed. Springer.
[2] Sudipto Guha, Nick K Koudas and Kkyuseok Shim.(2001) “Data Streams and Histograms", ACM Symposium on Theory of Computing.
[3] Srimani P.K and Malini M Patil.(2011) “ Edu-Mining : A Machine learning approach”, ICM2ST-2011, Jaipur, Rajasthan, AIP [4] proceedings.
[5] Srimani P.K and Malini M Patil(2012) “ A Classification Model for Edu-Mining", PSRC, ICICS-2012, Dubai, UAE.
[6] Srimani P.K and Malini M Patil(2012) ” A Comparative Study of Classifiers for Student Module in Technical Education System(TES)”, International Journal of Current Research, Vol 4, Issue, 01, pp.249-254, January.
[7] Srimani P.K and Malini M Patil.(2012) ” Performance Evaluation of Classifiers for Edu-data: An integrated approach”, International Journal of Current Research, Vol 4, Issue, 02, pp.183-190, February.
[8] J. Han and M. Kamber: Book(2009): "Data Mining , Concepts and Techniques" , Jiawei Han and Micheline Kamber Ed. Elsevier [9] Albert Bifet and Philip Kranen (2010) " MOA: Massive Online Analysis, a Framework for Stream Classification and Clustering",